

الصورة التي أنشأها المؤلف باستخدام Midjourney
مقدمة إلى RAG
في عالم نماذج اللغة الذي يتطور باستمرار، إحدى المنهجيات الثابتة ذات الأهمية الخاصة هي الجيل المعزز للاسترجاع (RAG)، وهو إجراء يتضمن عناصر استرجاع المعلومات (IR) في إطار نموذج لغة توليد النص من أجل توليد نماذج شبيهة بالإنسان. نص بهدف أن يكون أكثر فائدة ودقة من ذلك الذي سيتم إنشاؤه بواسطة نموذج اللغة الافتراضي وحده. سنقدم المفاهيم الأولية لـ RAG في هذا المنشور، مع التركيز على بناء بعض أنظمة RAG في المنشورات اللاحقة.
نظرة عامة على RAG
نقوم بإنشاء نماذج لغوية باستخدام مجموعات بيانات واسعة وعامة غير مصممة خصيصًا لبياناتك الشخصية أو المخصصة. وللتعامل مع هذا الواقع، يمكن لـ RAG دمج بياناتك الخاصة مع "المعرفة" الحالية لنموذج اللغة. لتسهيل ذلك، ما يجب فعله وما يفعله RAG هو فهرسة بياناتك لجعلها قابلة للبحث. عند تنفيذ بحث مكون من بياناتك، يتم استخراج المعلومات ذات الصلة والمهمة من البيانات المفهرسة، ويمكن استخدامها ضمن استعلام مقابل نموذج لغة لإرجاع استجابة ذات صلة ومفيدة قدمها النموذج. أي مهندس ذكاء اصطناعي، أو عالم بيانات، أو مطور مهتم ببناء روبوتات الدردشة، أو أنظمة استرجاع المعلومات الحديثة، أو أنواع أخرى من المساعدين الشخصيين، فإن فهم RAG، ومعرفة كيفية الاستفادة من بياناتك الخاصة، أمر في غاية الأهمية.
ببساطة، RAG هي تقنية جديدة تعمل على إثراء نماذج اللغة بوظيفة استرجاع المدخلات، مما يعزز نماذج اللغة من خلال دمج آليات الأشعة تحت الحمراء في عملية التوليد، وهي آليات يمكنها تخصيص (زيادة) "المعرفة" المتأصلة في النموذج المستخدمة للأغراض التوليدية.
لتلخيص ذلك، يتضمن RAG الخطوات عالية المستوى التالية:
- استرجاع المعلومات من مصادر البيانات المخصصة الخاصة بك
- أضف هذه البيانات إلى الموجه الخاص بك كسياق إضافي
- اطلب من LLM إنشاء استجابة بناءً على المطالبة المعززة
توفر RAG هذه المزايا مقارنة ببديل الضبط الدقيق للنموذج:
- لا يتم إجراء أي تدريب باستخدام RAG، لذلك لا توجد تكلفة أو وقت للضبط الدقيق
- تكون البيانات المخصصة حديثة بقدر ما تصنعها، ومن ثم يمكن أن يظل النموذج محدثًا بشكل فعال
- يمكن الاستشهاد بمستندات البيانات المخصصة المحددة أثناء (أو بعد) العملية، وبالتالي يصبح النظام أكثر قابلية للتحقق وجديرة بالثقة
نظرة فاحصة
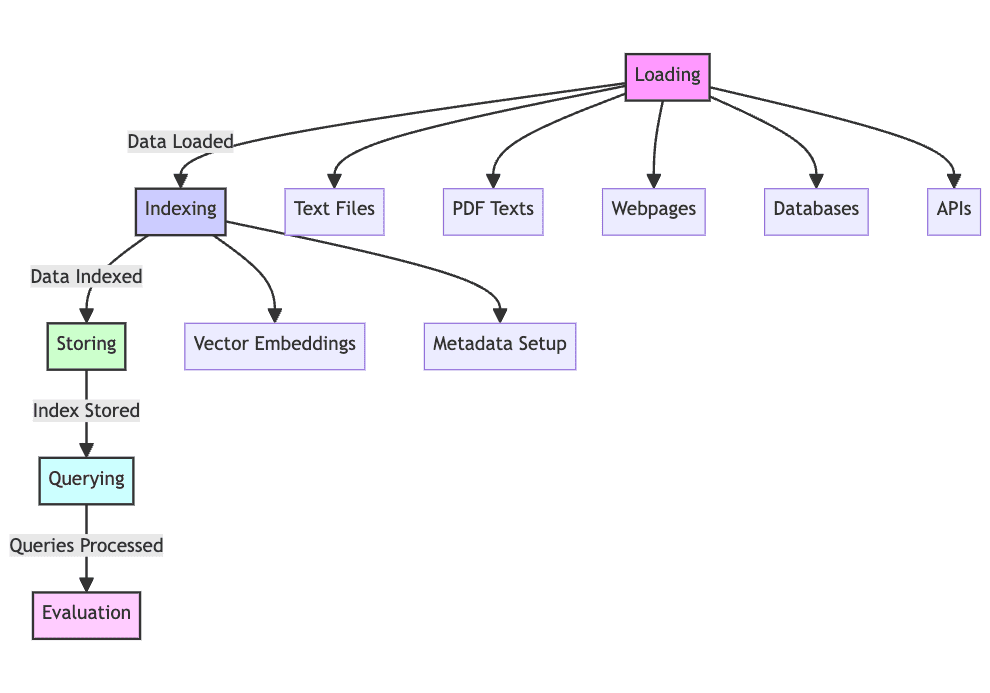
بعد إجراء فحص أكثر تفصيلاً، يمكننا القول أن نظام RAG سوف يتقدم خلال 5 مراحل من التشغيل.
1. تحميل: يعد جمع البيانات النصية الأولية - من الملفات النصية وملفات PDF وصفحات الويب وقواعد البيانات والمزيد - الخطوة الأولى من بين العديد من الخطوات، حيث يتم وضع البيانات النصية في مسار المعالجة، مما يجعل هذه خطوة ضرورية في العملية. وبدون تحميل البيانات، لا يمكن لـ RAG أن يعمل ببساطة.
2. الفهرس: يجب تنظيم البيانات الموجودة لديك الآن والحفاظ عليها من أجل استرجاعها والبحث عنها والاستعلام عنها. ستستخدم نماذج اللغة التضمينات المتجهة التي تم إنشاؤها من المحتوى لتوفير تمثيلات رقمية للبيانات، بالإضافة إلى استخدام بيانات وصفية معينة للسماح بنتائج بحث ناجحة.
3. المتجر: بعد إنشائه، يجب حفظ الفهرس جنبًا إلى جنب مع البيانات الوصفية، مما يضمن عدم الحاجة إلى تكرار هذه الخطوة بانتظام، مما يسمح بتوسيع نطاق نظام RAG بشكل أسهل.
4. استعلام: مع وجود هذا الفهرس، يمكن اجتياز المحتوى باستخدام المفهرس ونموذج اللغة لمعالجة مجموعة البيانات وفقًا لاستعلامات مختلفة.
5. تقييم: يعد تقييم الأداء مقابل الخطوات التوليدية المحتملة الأخرى مفيدًا، سواء عند تغيير العمليات الحالية أو عند اختبار الكمون المتأصل ودقة الأنظمة من هذا النوع.
الصورة التي أنشأها المؤلف
مثال قصير
خذ بعين الاعتبار تنفيذ RAG البسيط التالي. تخيل أن هذا نظام تم إنشاؤه لتلقي استفسارات العملاء حول متجر وهمي عبر الإنترنت.
1. جار التحميل: سينشأ المحتوى من وثائق المنتج، ومراجعات المستخدمين، ومدخلات العملاء، المخزنة بتنسيقات متعددة مثل لوحات الرسائل وقواعد البيانات وواجهات برمجة التطبيقات.
2. الفهرسة: ستقوم بإنتاج تضمينات متجهة لتوثيق المنتج ومراجعات المستخدم، وما إلى ذلك، جنبًا إلى جنب مع فهرسة البيانات الوصفية المخصصة لكل نقطة بيانات، مثل فئة المنتج أو تقييم العميل.
3. التخزين: سيتم حفظ الفهرس الذي تم تطويره على هذا النحو في مخزن المتجهات، وهي قاعدة بيانات متخصصة للتخزين والاسترجاع الأمثل للمتجهات، وهو ما يتم تخزين التضمينات عليه.
4. الاستعلام: عند وصول استعلام العميل، سيتم إجراء بحث في قواعد بيانات مخزن المتجهات استنادًا إلى نص السؤال، ثم يتم استخدام نماذج اللغة لإنشاء استجابات باستخدام أصول هذه البيانات الأولية كسياق.
5. تقييم: سيتم تقييم أداء النظام من خلال مقارنة أدائه بالخيارات الأخرى، مثل استرجاع نموذج اللغة التقليدية، وقياس المقاييس مثل صحة الإجابة، وزمن الاستجابة، ورضا المستخدم بشكل عام، لضمان إمكانية تعديل نظام RAG وصقله لتقديم أداء متفوق نتائج.
يجب أن يمنحك هذا المثال التوضيحي فكرة عن المنهجية الكامنة وراء RAG واستخدامه لنقل القدرة على استرجاع المعلومات على نموذج اللغة.
وفي الختام
كان موضوع هذه المقالة هو تقديم الجيل المعزز للاسترجاع، والذي يجمع بين إنشاء النص واسترجاع المعلومات من أجل تحسين الدقة والاتساق السياقي لمخرجات نموذج اللغة. تسمح هذه الطريقة باستخراج وزيادة البيانات المخزنة في المصادر المفهرسة ليتم دمجها في المخرجات الناتجة لنماذج اللغة. يمكن لنظام RAG هذا توفير قيمة محسنة عبر مجرد الضبط الدقيق لنموذج اللغة.
ستتألف الخطوات التالية من رحلة RAG الخاصة بنا من تعلم أدوات التجارة من أجل تنفيذ بعض أنظمة RAG الخاصة بنا. سنركز أولاً على استخدام الأدوات من LlamaIndex مثل موصلات البيانات والمحركات وموصلات التطبيقات لتسهيل تكامل RAG وتوسيع نطاقه. لكننا نحفظ هذا للمقال التالي.
في المشاريع القادمة، سنقوم ببناء أنظمة RAG معقدة ونلقي نظرة على الاستخدامات والتحسينات المحتملة لتقنية RAG. ويكمن الأمل في الكشف عن العديد من الإمكانيات الجديدة في مجال الذكاء الاصطناعي، واستخدام مصادر البيانات المتنوعة هذه لبناء أنظمة أكثر ذكاءً وتوافقًا مع السياق.
ماثيو مايو (@ mtmayo13) حاصل على درجة الماجستير في علوم الكمبيوتر ودبلوم الدراسات العليا في استخراج البيانات. بصفته مدير التحرير، يهدف ماثيو إلى تسهيل الوصول إلى مفاهيم علم البيانات المعقدة. تشمل اهتماماته المهنية معالجة اللغات الطبيعية وخوارزميات التعلم الآلي واستكشاف الذكاء الاصطناعي الناشئ. إنه مدفوع بمهمة إضفاء الطابع الديمقراطي على المعرفة في مجتمع علوم البيانات. كان ماثيو يبرمج منذ أن كان عمره 6 سنوات.
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- PlatoData.Network Vertical Generative Ai. تمكين نفسك. الوصول هنا.
- أفلاطونايستريم. ذكاء Web3. تضخيم المعرفة. الوصول هنا.
- أفلاطون كربون، كلينتك ، الطاقة، بيئة، شمسي، إدارة المخلفات. الوصول هنا.
- أفلاطون هيلث. التكنولوجيا الحيوية وذكاء التجارب السريرية. الوصول هنا.
- المصدر https://www.kdnuggets.com/retrieval-augmented-generation-where-information-retrieval-meets-text-generation?utm_source=rss&utm_medium=rss&utm_campaign=retrieval-augmented-generation-where-information-retrieval-meets-text-generation