
ভূমিকা
মেশিন লার্নিং (এমএল) হল অধ্যয়নের একটি ক্ষেত্র যা ডেটা থেকে স্বয়ংক্রিয়ভাবে শেখার জন্য অ্যালগরিদম তৈরি করার উপর দৃষ্টি নিবদ্ধ করে, ভবিষ্যদ্বাণী করা এবং প্যাটার্ন অনুমান করা স্পষ্টভাবে বলা না হয়ে কিভাবে এটি করতে হয়। এটির লক্ষ্য এমন সিস্টেম তৈরি করা যা স্বয়ংক্রিয়ভাবে অভিজ্ঞতা এবং ডেটার সাথে উন্নত হয়।
এটি তত্ত্বাবধানে শিক্ষার মাধ্যমে অর্জন করা যেতে পারে, যেখানে মডেলটিকে লেবেলযুক্ত ডেটা ব্যবহার করে ভবিষ্যদ্বাণী করার জন্য প্রশিক্ষিত করা হয়, অথবা তত্ত্বাবধানহীন শিক্ষার মাধ্যমে, যেখানে মডেলটি নির্দিষ্ট লক্ষ্যমাত্রা আউটপুট ছাড়াই ডেটার মধ্যে প্যাটার্ন বা পারস্পরিক সম্পর্ক উন্মোচন করতে চায়।
ML কম্পিউটার বিজ্ঞান, জীববিজ্ঞান, অর্থ এবং বিপণন সহ বিভিন্ন শাখায় একটি অপরিহার্য এবং ব্যাপকভাবে নিযুক্ত সরঞ্জাম হিসাবে আবির্ভূত হয়েছে। এটি চিত্র শ্রেণীবিভাগ, প্রাকৃতিক ভাষা প্রক্রিয়াকরণ, এবং জালিয়াতি সনাক্তকরণের মতো বিভিন্ন অ্যাপ্লিকেশনগুলিতে এর উপযোগিতা প্রমাণ করেছে।
মেশিন লার্নিং টাস্ক
মেশিন লার্নিংকে বিস্তৃতভাবে তিনটি প্রধান কাজের মধ্যে শ্রেণীবদ্ধ করা যেতে পারে:
- তত্ত্বাবধান শেখা
- নিরীক্ষণশিক্ষা
- শক্তিবৃদ্ধি শেখা
এখানে, আমরা প্রথম দুটি ক্ষেত্রে ফোকাস করব।
তত্ত্বাবধানে শেখার
তত্ত্বাবধানে শিক্ষার মধ্যে লেবেলযুক্ত ডেটার উপর একটি মডেলকে প্রশিক্ষণ দেওয়া জড়িত, যেখানে ইনপুট ডেটা সংশ্লিষ্ট আউটপুট বা লক্ষ্য পরিবর্তনশীলের সাথে যুক্ত করা হয়। লক্ষ্য হল এমন একটি ফাংশন শেখা যা সঠিক আউটপুটে ইনপুট ডেটা ম্যাপ করতে পারে। সাধারণ তত্ত্বাবধানে শেখার অ্যালগরিদমের মধ্যে রয়েছে রৈখিক রিগ্রেশন, লজিস্টিক রিগ্রেশন, ডিসিশন ট্রি এবং সাপোর্ট ভেক্টর মেশিন।
পাইথন ব্যবহার করে তত্ত্বাবধান করা শেখার কোডের উদাহরণ:
from sklearn.linear_model import LinearRegression model = LinearRegression() model.fit(X_train, y_train) predictions = model.predict(X_test)
এই সহজ কোড উদাহরণ, আমরা প্রশিক্ষণ LinearRegression আমাদের প্রশিক্ষণ ডেটার উপর scikit-learn থেকে অ্যালগরিদম, এবং তারপর আমাদের পরীক্ষার ডেটার পূর্বাভাস পেতে এটি প্রয়োগ করুন।
তত্ত্বাবধানে শিক্ষার একটি বাস্তব-বিশ্ব ব্যবহারের ক্ষেত্রে ইমেল স্প্যাম শ্রেণীবিভাগ। ইমেল যোগাযোগের সূচকীয় বৃদ্ধির সাথে, স্প্যাম ইমেলগুলি সনাক্ত করা এবং ফিল্টার করা গুরুত্বপূর্ণ হয়ে উঠেছে। তত্ত্বাবধানে শেখার অ্যালগরিদম ব্যবহার করে, লেবেলযুক্ত ডেটার উপর ভিত্তি করে বৈধ ইমেল এবং স্প্যামের মধ্যে পার্থক্য করার জন্য একটি মডেলকে প্রশিক্ষণ দেওয়া সম্ভব।
তত্ত্বাবধানে শেখার মডেলটিকে "স্প্যাম" বা "স্প্যাম নয়" হিসাবে লেবেলযুক্ত ইমেল ধারণকারী একটি ডেটাসেটে প্রশিক্ষণ দেওয়া যেতে পারে। মডেলটি লেবেলযুক্ত ডেটা থেকে প্যাটার্ন এবং বৈশিষ্ট্যগুলি শিখে, যেমন নির্দিষ্ট কীওয়ার্ডের উপস্থিতি, ইমেল গঠন বা ইমেল প্রেরকের তথ্য। মডেলটি প্রশিক্ষিত হয়ে গেলে, এটি স্বয়ংক্রিয়ভাবে আগত ইমেলগুলিকে স্প্যাম বা নন-স্প্যাম হিসাবে শ্রেণীবদ্ধ করতে ব্যবহার করা যেতে পারে, দক্ষতার সাথে অবাঞ্ছিত বার্তাগুলি ফিল্টার করে৷
অশিক্ষিত শিক্ষা
তত্ত্বাবধানহীন শিক্ষায়, ইনপুট ডেটা লেবেলবিহীন থাকে এবং লক্ষ্য হল ডেটার মধ্যে প্যাটার্ন বা কাঠামো আবিষ্কার করা। তত্ত্বাবধানহীন লার্নিং অ্যালগরিদমগুলির লক্ষ্য ডেটাতে অর্থপূর্ণ উপস্থাপনা বা ক্লাস্টারগুলি খুঁজে পাওয়া।
তত্ত্বাবধানহীন শেখার অ্যালগরিদমের উদাহরণ অন্তর্ভুক্ত k- মানে ক্লাস্টারিং, অনুক্রমিক ক্লাস্টারিং, এবং প্রধান উপাদান বিশ্লেষণ (PCA).
তত্ত্বাবধানহীন শেখার কোডের উদাহরণ:
from sklearn.cluster import KMeans model = KMeans(n_clusters=3) model.fit(X) predictions = model.predict(X_new)
এই সহজ কোড উদাহরণ, আমরা প্রশিক্ষণ KMeans আমাদের ডেটাতে তিনটি ক্লাস্টার সনাক্ত করতে scikit-learn থেকে অ্যালগরিদম এবং তারপর সেই ক্লাস্টারগুলিতে নতুন ডেটা ফিট করা।
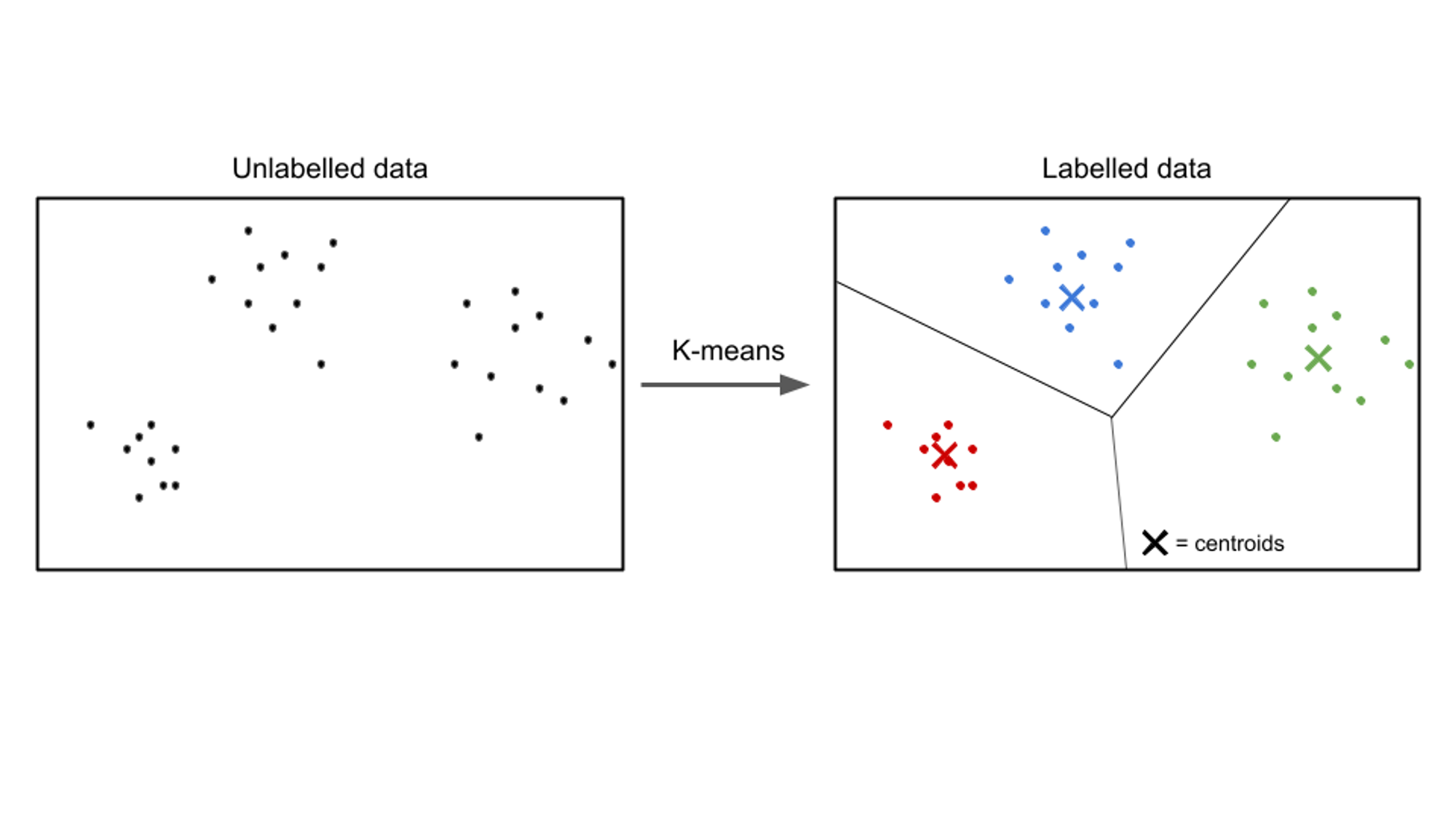
একটি unsupervised লার্নিং ব্যবহারের ক্ষেত্রে একটি উদাহরণ হল গ্রাহক বিভাজন. বিভিন্ন শিল্পে, ব্যবসাগুলি তাদের বিপণন কৌশলগুলিকে উপযোগী করতে, তাদের অফারগুলিকে ব্যক্তিগতকৃত করতে এবং গ্রাহকের অভিজ্ঞতাকে অপ্টিমাইজ করার জন্য তাদের গ্রাহক বেসকে আরও ভালভাবে বোঝার লক্ষ্য রাখে। গ্রাহকদের তাদের ভাগ করা বৈশিষ্ট্য এবং আচরণের উপর ভিত্তি করে স্বতন্ত্র গোষ্ঠীতে ভাগ করার জন্য তত্ত্বাবধানহীন লার্নিং অ্যালগরিদম ব্যবহার করা যেতে পারে।
সেরা-অভ্যাস, শিল্প-স্বীকৃত মান এবং অন্তর্ভুক্ত চিট শীট সহ গিট শেখার জন্য আমাদের হ্যান্ডস-অন, ব্যবহারিক গাইড দেখুন। গুগলিং গিট কমান্ড এবং আসলে বন্ধ করুন শেখা এটা!
ক্লাস্টারিং-এর মতো তত্ত্বাবধানহীন শেখার কৌশলগুলি প্রয়োগ করে, ব্যবসাগুলি তাদের গ্রাহক ডেটার মধ্যে অর্থপূর্ণ নিদর্শন এবং গোষ্ঠীগুলি উন্মোচন করতে পারে। উদাহরণস্বরূপ, ক্লাস্টারিং অ্যালগরিদম অনুরূপ ক্রয় অভ্যাস, জনসংখ্যা বা পছন্দগুলির সাথে গ্রাহকদের গোষ্ঠী সনাক্ত করতে পারে। লক্ষ্যযুক্ত বিপণন প্রচারাভিযান তৈরি করতে, পণ্যের সুপারিশ অপ্টিমাইজ করতে এবং গ্রাহকের সন্তুষ্টি উন্নত করতে এই তথ্যটি ব্যবহার করা যেতে পারে।
প্রধান অ্যালগরিদম ক্লাস
তত্ত্বাবধান করা শেখার অ্যালগরিদম
-
লিনিয়ার মডেল: বৈশিষ্ট্য এবং লক্ষ্য ভেরিয়েবলের মধ্যে রৈখিক সম্পর্কের উপর ভিত্তি করে ক্রমাগত ভেরিয়েবলের পূর্বাভাস দেওয়ার জন্য ব্যবহৃত হয়।
-
ট্রি-ভিত্তিক মডেল: ভবিষ্যদ্বাণী বা শ্রেণীবিভাগ করার জন্য বাইনারি সিদ্ধান্তের একটি সিরিজ ব্যবহার করে নির্মিত।
-
এনসেম্বল মডেল: পদ্ধতি যা একাধিক মডেলকে একত্রিত করে (বৃক্ষ-ভিত্তিক বা রৈখিক) আরও সঠিক ভবিষ্যদ্বাণী করতে।
-
নিউরাল নেটওয়ার্ক মডেল: পদ্ধতিগুলি আলগাভাবে মানুষের মস্তিষ্কের উপর ভিত্তি করে, যেখানে একাধিক ফাংশন একটি নেটওয়ার্কের নোড হিসাবে কাজ করে।
তত্ত্বাবধানহীন লার্নিং অ্যালগরিদম
-
শ্রেণিবিন্যাস ক্লাস্টারিং: পুনরাবৃত্তভাবে একত্রিত বা বিভক্ত করে ক্লাস্টারগুলির একটি শ্রেণিবিন্যাস তৈরি করে।
-
নন-হাইরার্কিক্যাল ক্লাস্টারিং: সাদৃশ্যের ভিত্তিতে ডেটাকে আলাদা ক্লাস্টারে ভাগ করে।
-
মাত্রিকতা হ্রাস: সবচেয়ে গুরুত্বপূর্ণ তথ্য সংরক্ষণ করার সময় ডেটার মাত্রা হ্রাস করে।
মডেল মূল্যায়ন
তত্ত্বাবধানে শেখার
তত্ত্বাবধানে থাকা শেখার মডেলগুলির কার্যকারিতা মূল্যায়ন করতে, নির্ভুলতা, নির্ভুলতা, প্রত্যাহার, F1 স্কোর এবং ROC-AUC সহ বিভিন্ন মেট্রিক্স ব্যবহার করা হয়। ক্রস-ভ্যালিডেশন কৌশল, যেমন কে-ফোল্ড ক্রস-ভ্যালিডেশন, মডেলের সাধারণীকরণ কর্মক্ষমতা অনুমান করতে সাহায্য করতে পারে।
অশিক্ষিত শিক্ষা
তত্ত্বাবধানহীন শেখার অ্যালগরিদমগুলি মূল্যায়ন করা প্রায়শই আরও চ্যালেঞ্জিং কারণ কোনও গ্রাউন্ড ট্রুথ নেই৷ ক্লাস্টারিং ফলাফলের গুণমান মূল্যায়ন করতে সিলুয়েট স্কোর বা জড়তার মতো মেট্রিক্স ব্যবহার করা যেতে পারে। ভিজ্যুয়ালাইজেশন কৌশলগুলি ক্লাস্টারগুলির কাঠামোর অন্তর্দৃষ্টিও প্রদান করতে পারে।
কৌশল
তত্ত্বাবধানে শেখার
- মডেল কর্মক্ষমতা উন্নত করতে ইনপুট ডেটা প্রিপ্রসেস এবং স্বাভাবিক করুন।
- অনুপস্থিত মান যথাযথভাবে পরিচালনা করুন, হয় অভিযুক্ত বা অপসারণের মাধ্যমে।
- ফিচার ইঞ্জিনিয়ারিং মডেলের প্রাসঙ্গিক প্যাটার্ন ক্যাপচার করার ক্ষমতা বাড়াতে পারে।
অশিক্ষিত শিক্ষা
- ডোমেন জ্ঞানের উপর ভিত্তি করে বা কনুই পদ্ধতির মত কৌশল ব্যবহার করে উপযুক্ত সংখ্যক ক্লাস্টার বেছে নিন।
- ডেটা পয়েন্টের মধ্যে সাদৃশ্য পরিমাপ করতে বিভিন্ন দূরত্বের মেট্রিক্স বিবেচনা করুন।
- ওভারফিটিং এড়াতে ক্লাস্টারিং প্রক্রিয়া নিয়মিত করুন।
সংক্ষেপে, মেশিন লার্নিং-এ অনেকগুলি কাজ, কৌশল, অ্যালগরিদম, মডেল মূল্যায়ন পদ্ধতি এবং সহায়ক ইঙ্গিত জড়িত। এই দিকগুলি বোঝার মাধ্যমে, অনুশীলনকারীরা বাস্তব-বিশ্বের সমস্যাগুলিতে দক্ষতার সাথে মেশিন লার্নিং প্রয়োগ করতে পারে এবং ডেটা থেকে উল্লেখযোগ্য অন্তর্দৃষ্টি অর্জন করতে পারে। প্রদত্ত কোড উদাহরণগুলি তত্ত্বাবধানে থাকা এবং তত্ত্বাবধানহীন শেখার অ্যালগরিদমগুলির ব্যবহার প্রদর্শন করে, তাদের ব্যবহারিক বাস্তবায়নকে হাইলাইট করে।
- এসইও চালিত বিষয়বস্তু এবং পিআর বিতরণ। আজই পরিবর্ধিত পান।
- ইভিএম ফাইন্যান্স। বিকেন্দ্রীভূত অর্থের জন্য ইউনিফাইড ইন্টারফেস। এখানে প্রবেশ করুন.
- কোয়ান্টাম মিডিয়া গ্রুপ। IR/PR প্রশস্ত। এখানে প্রবেশ করুন.
- প্লেটোএআইস্ট্রিম। Web3 ডেটা ইন্টেলিজেন্স। জ্ঞান প্রসারিত. এখানে প্রবেশ করুন.
- উত্স: https://stackabuse.com/supervised-learning-vs-unsupervised-learning-algorithms/