
Introduktion
Machine Learning (ML) er et studieområde, der fokuserer på at udvikle algoritmer til at lære automatisk fra data, lave forudsigelser og udlede mønstre uden at blive eksplicit fortalt, hvordan det skal gøres. Det har til formål at skabe systemer, der automatisk forbedres med erfaring og data.
Dette kan opnås gennem superviseret læring, hvor modellen trænes ved at bruge mærkede data til at lave forudsigelser, eller gennem uovervåget læring, hvor modellen søger at afdække mønstre eller sammenhænge i dataene uden specifikke måloutput at forudse.
ML er opstået som et uundværligt og bredt anvendt værktøj på tværs af forskellige discipliner, herunder datalogi, biologi, finans og marketing. Det har bevist sin anvendelighed i forskellige applikationer såsom billedklassificering, naturlig sprogbehandling og svindeldetektion.
Maskinlæringsopgaver
Maskinlæring kan bredt klassificeres i tre hovedopgaver:
- Overvåget læring
- Uovervåget læring
- Forstærkning læring
Her vil vi fokusere på de to første cases.
Overvåget læring
Superviseret læring involverer træning af en model på mærkede data, hvor inputdata er parret med den tilsvarende output- eller målvariabel. Målet er at lære en funktion, der kan kortlægge inputdata til det korrekte output. Almindelige overvågede læringsalgoritmer omfatter lineær regression, logistisk regression, beslutningstræer og støttevektormaskiner.
Eksempel på overvåget læringskode ved hjælp af Python:
from sklearn.linear_model import LinearRegression model = LinearRegression() model.fit(X_train, y_train) predictions = model.predict(X_test)
I dette simple kodeeksempel træner vi LinearRegression algoritme fra scikit-learn på vores træningsdata, og anvende den derefter for at få forudsigelser for vores testdata.
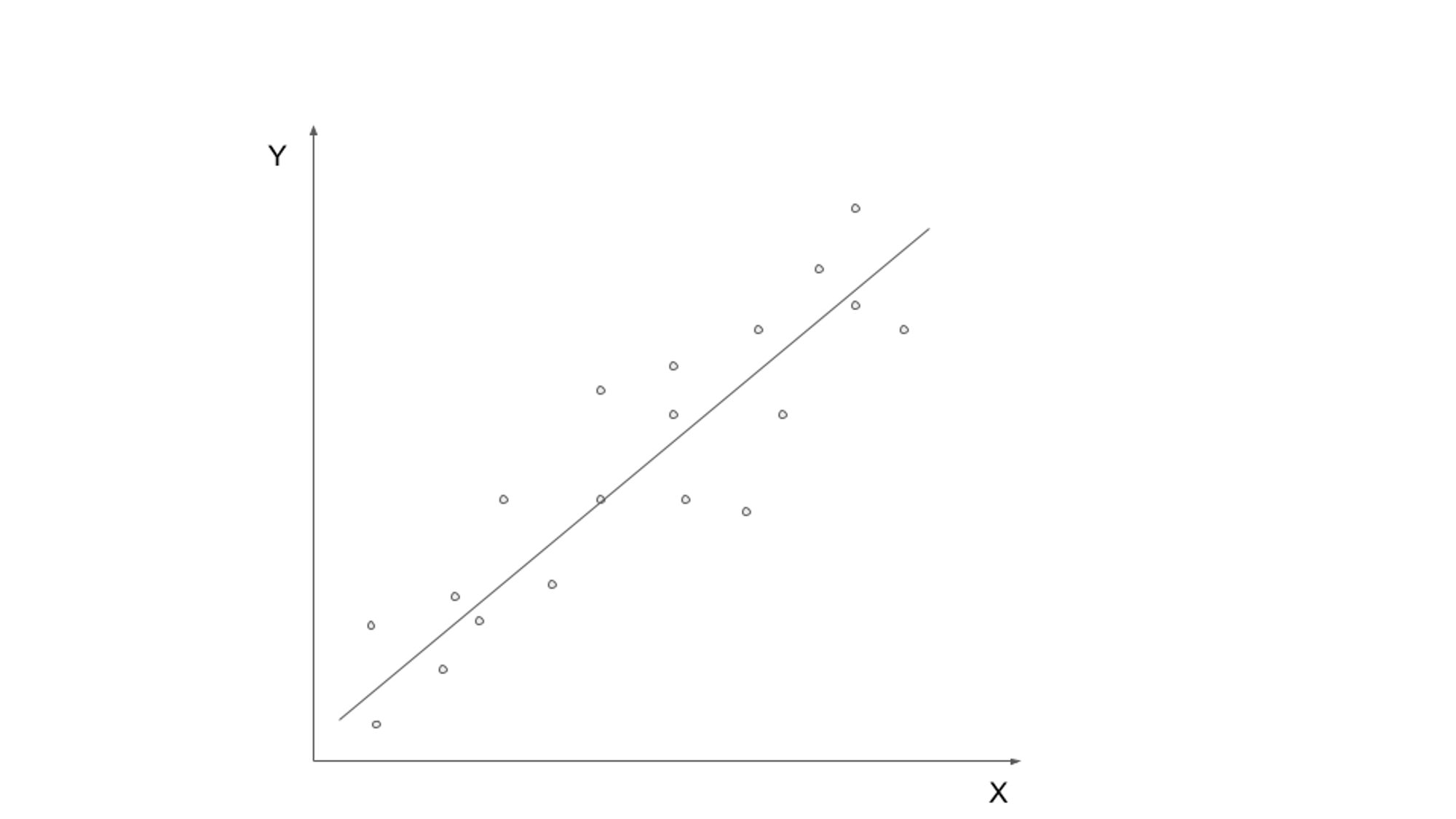
Et tilfælde i den virkelige verden af overvåget læring er e-mail-spamklassificering. Med den eksponentielle vækst i e-mail-kommunikation er det blevet afgørende at identificere og filtrere spam-e-mails. Ved at bruge overvågede læringsalgoritmer er det muligt at træne en model til at skelne mellem legitime e-mails og spam baseret på mærkede data.
Den overvågede læringsmodel kan trænes på et datasæt, der indeholder e-mails mærket som enten "spam" eller "ikke spam". Modellen lærer mønstre og funktioner fra de mærkede data, såsom tilstedeværelsen af bestemte søgeord, e-mail-struktur eller e-mail-afsenderoplysninger. Når modellen er trænet, kan den bruges til automatisk at klassificere indgående e-mails som spam eller ikke-spam, og effektivt filtrere uønskede meddelelser.
Uovervåget læring
I uovervåget læring er inputdata umærkede, og målet er at opdage mønstre eller strukturer i dataene. Uovervågede læringsalgoritmer har til formål at finde meningsfulde repræsentationer eller klynger i dataene.
Eksempler på uovervågede læringsalgoritmer omfatter k-betyder klyngedannelse, hierarkisk klyngedannelseog hovedkomponentanalyse (PCA).
Eksempel på uovervåget læringskode:
from sklearn.cluster import KMeans model = KMeans(n_clusters=3) model.fit(X) predictions = model.predict(X_new)
I dette simple kodeeksempel træner vi KMeans algoritme fra scikit-learn til at identificere tre klynger i vores data og derefter passe nye data ind i disse klynger.
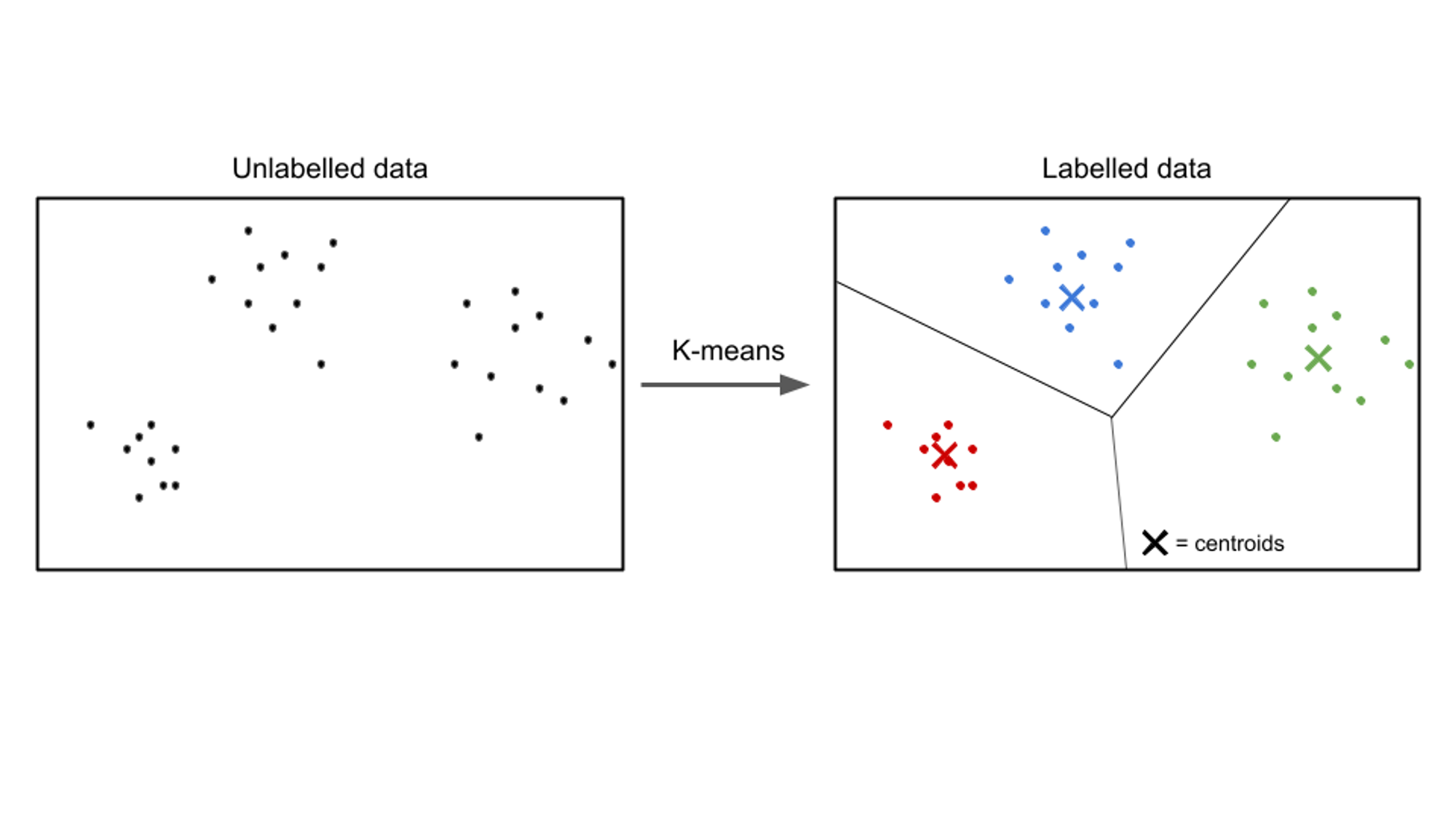
Et eksempel på en usecase for uovervåget læring er kundesegmentering. I forskellige brancher tilstræber virksomheder at forstå deres kundebase bedre for at skræddersy deres marketingstrategier, personliggøre deres tilbud og optimere kundeoplevelser. Uovervågede læringsalgoritmer kan bruges til at segmentere kunder i forskellige grupper baseret på deres fælles karakteristika og adfærd.
Tjek vores praktiske, praktiske guide til at lære Git, med bedste praksis, brancheaccepterede standarder og inkluderet snydeark. Stop med at google Git-kommandoer og faktisk lærer det!
Ved at anvende uovervågede læringsteknikker, såsom clustering, kan virksomheder afdække meningsfulde mønstre og grupper i deres kundedata. For eksempel kan klyngealgoritmer identificere grupper af kunder med lignende købsvaner, demografi eller præferencer. Denne information kan udnyttes til at skabe målrettede marketingkampagner, optimere produktanbefalinger og forbedre kundetilfredsheden.
Hovedalgoritmeklasser
Overvågede læringsalgoritmer
-
Lineære modeller: Bruges til at forudsige kontinuerte variable baseret på lineære forhold mellem funktioner og målvariablen.
-
Træbaserede modeller: Konstrueret ved hjælp af en række binære beslutninger til at lave forudsigelser eller klassifikationer.
-
Ensemblemodeller: Metode, der kombinerer flere modeller (træbaserede eller lineære) for at lave mere præcise forudsigelser.
-
Neurale netværksmodeller: Metoder løst baseret på den menneskelige hjerne, hvor flere funktioner fungerer som knudepunkter i et netværk.
Uovervågede læringsalgoritmer
-
Hierarkisk klynger: Opbygger et hierarki af klynger ved iterativt at flette eller opdele dem.
-
Ikke-hierarkisk klynger: Opdeler data i forskellige klynger baseret på lighed.
-
Dimensionalitetsreduktion: Reducerer dimensionaliteten af data, samtidig med at den vigtigste information bevares.
Modelvurdering
Overvåget læring
For at evaluere ydeevnen af overvågede læringsmodeller bruges forskellige metrics, herunder nøjagtighed, præcision, genkaldelse, F1-score og ROC-AUC. Krydsvalideringsteknikker, såsom k-fold krydsvalidering, kan hjælpe med at estimere modellens generaliseringsydelse.
Uovervåget læring
Evaluering af uovervågede læringsalgoritmer er ofte mere udfordrende, da der ikke er nogen sandhed. Målinger såsom silhouette score eller inerti kan bruges til at vurdere kvaliteten af klyngeresultater. Visualiseringsteknikker kan også give indsigt i klyngernes struktur.
Tips og tricks
Overvåget læring
- Forbehandl og normaliser inputdata for at forbedre modellens ydeevne.
- Håndter manglende værdier korrekt, enten ved imputation eller fjernelse.
- Feature engineering kan forbedre modellens evne til at fange relevante mønstre.
Uovervåget læring
- Vælg det passende antal klynger baseret på domæneviden eller brug af teknikker som albuemetoden.
- Overvej forskellige afstandsmålinger for at måle ligheden mellem datapunkter.
- Reguler klyngeprocessen for at undgå overpasning.
Sammenfattende involverer maskinlæring adskillige opgaver, teknikker, algoritmer, modelevalueringsmetoder og nyttige tip. Ved at forstå disse aspekter kan praktikere effektivt anvende maskinlæring på problemer i den virkelige verden og udlede betydelig indsigt fra data. De givne kodeeksempler viser brugen af overvågede og ikke-overvågede læringsalgoritmer, hvilket fremhæver deres praktiske implementering.
- SEO Powered Content & PR Distribution. Bliv forstærket i dag.
- EVM Finans. Unified Interface for Decentralized Finance. Adgang her.
- Quantum Media Group. IR/PR forstærket. Adgang her.
- PlatoAiStream. Web3 Data Intelligence. Viden forstærket. Adgang her.
- Kilde: https://stackabuse.com/supervised-learning-vs-unsupervised-learning-algorithms/