
Dette indlæg er skrevet af Goktug Cinar, Michael Binder og Adrian Horvath fra Bosch Center for Artificial Intelligence (BCAI).
Indtægtsprognose er en udfordrende, men alligevel afgørende opgave for strategiske forretningsbeslutninger og finanspolitisk planlægning i de fleste organisationer. Ofte udføres indtægtsprognose manuelt af finansanalytikere og er både tidskrævende og subjektivt. Sådanne manuelle indsatser er især udfordrende for store, multinationale virksomhedsorganisationer, der kræver indtægtsprognoser på tværs af en bred vifte af produktgrupper og geografiske områder på flere niveauer af granularitet. Dette kræver ikke kun nøjagtighed, men også hierarkisk sammenhæng i prognoserne.
Bosch er et multinationalt selskab med enheder, der opererer i flere sektorer, herunder bilindustrien, industrielle løsninger og forbrugsvarer. I betragtning af virkningen af nøjagtige og sammenhængende indtægtsprognoser på sunde forretningsaktiviteter, Bosch Center for Kunstig Intelligens (BCAI) har investeret kraftigt i brugen af maskinlæring (ML) for at forbedre effektiviteten og nøjagtigheden af økonomiske planlægningsprocesser. Målet er at afhjælpe de manuelle processer ved at levere rimelige basislinjeindtægtsprognoser via ML, med kun lejlighedsvise justeringer, der er nødvendige af finansanalytikere, der bruger deres branche- og domænekendskab.
For at nå dette mål har BCAI udviklet en intern prognoseramme, der er i stand til at levere hierarkiske prognoser i stor skala via tilpassede ensembler af en bred vifte af basismodeller. En meta-lærer vælger de bedst ydende modeller baseret på funktioner udtrukket fra hver tidsserie. Prognoserne fra de udvalgte modeller er derefter gennemsnittet for at opnå den aggregerede prognose. Det arkitektoniske design er modulopbygget og kan udvides gennem implementeringen af en REST-stil interface, som tillader kontinuerlig forbedring af ydeevnen via inklusion af yderligere modeller.
BCAI samarbejdede med Amazon ML Solutions Lab (MLSL) for at inkorporere de seneste fremskridt inden for deep neural network (DNN)-baserede modeller til indtægtsprognose. Nylige fremskridt inden for neurale prognosere har demonstreret state-of-the-art ydeevne for mange praktiske prognoseproblemer. Sammenlignet med traditionelle prognosemodeller kan mange neurale prognosemænd inkorporere yderligere kovariater eller metadata fra tidsserien. Vi inkluderer CNN-QR og DeepAR+, to hyldemodeller i Amazon prognose, samt en tilpasset Transformer model trænet vha Amazon SageMaker. De tre modeller dækker et repræsentativt sæt af encoder-rygraden, der ofte bruges i neurale prognosere: konvolutionelt neuralt netværk (CNN), sekventielt tilbagevendende neuralt netværk (RNN) og transformer-baserede indkodere.
En af de vigtigste udfordringer for BCAI-MLSL-partnerskabet var at levere robuste og rimelige prognoser under påvirkningen af COVID-19, en hidtil uset global begivenhed, der forårsager stor volatilitet i globale virksomheders økonomiske resultater. Fordi neurale prognosere er trænet på historiske data, kan de prognoser, der genereres baseret på out-of-distribution data fra de mere volatile perioder, være unøjagtige og upålidelige. Derfor foreslog vi tilføjelsen af en maskeret opmærksomhedsmekanisme i Transformer-arkitekturen for at løse dette problem.
De neurale prognoseprogrammer kan samles som en enkelt ensemblemodel eller integreres individuelt i Boschs modelunivers og let tilgås via REST API-endepunkter. Vi foreslår en tilgang til ensemble af neurale prognosere gennem backtest-resultater, som giver konkurrencedygtig og robust ydeevne over tid. Derudover undersøgte og evaluerede vi en række klassiske hierarkiske afstemningsteknikker for at sikre, at prognoser aggregeres sammenhængende på tværs af produktgrupper, geografier og forretningsorganisationer.
I dette indlæg demonstrerer vi følgende:
- Sådan anvender du Forecast og SageMaker tilpassede modeltræning til hierarkiske, storstilede tidsserieprognoser
- Sådan samler du tilpassede modeller med hyldemodeller fra Forecast
- Hvordan man reducerer virkningen af forstyrrende begivenheder såsom COVID-19 på prognoseproblemer
- Hvordan man opbygger en end-to-end prognose arbejdsgang på AWS
Udfordringer
Vi adresserede to udfordringer: at skabe hierarkisk, storstilet indtægtsprognose og virkningen af COVID-19-pandemien på langsigtede prognoser.
Hierarkisk, storstilet indtægtsprognose
Finansanalytikere har til opgave at forudsige finansielle nøgletal, herunder indtægter, driftsomkostninger og F&U-udgifter. Disse målinger giver indsigt i forretningsplanlægning på forskellige aggregeringsniveauer og muliggør datadrevet beslutningstagning. Enhver automatiseret prognoseløsning skal levere prognoser på ethvert vilkårligt niveau af forretningslinjeaggregering. Hos Bosch kan aggregeringerne forestilles som grupperede tidsserier som en mere generel form for hierarkisk struktur. Følgende figur viser et forenklet eksempel med en struktur på to niveauer, som efterligner den hierarkiske struktur for indtægtsprognoser hos Bosch. Den samlede omsætning er opdelt i flere aggregeringsniveauer baseret på produkt og region.
Det samlede antal tidsserier, der skal forudses hos Bosch, er på størrelsesordenen millioner. Bemærk, at tidsserien på øverste niveau kan opdeles efter enten produkter eller regioner, hvilket skaber flere stier til prognoser på nederste niveau. Omsætningen skal prognosticeres ved hver node i hierarkiet med en prognosehorisont på 12 måneder ud i fremtiden. Månedlige historiske data er tilgængelige.
Den hierarkiske struktur kan repræsenteres ved hjælp af følgende form med notationen af en summeringsmatrix S (Hyndman og Athanasopoulos):
![]()
I denne ligning, Y er lig med følgende:

Her, b repræsenterer bundniveauets tidsserie på et tidspunkt t.
Virkningerne af COVID-19-pandemien
COVID-19-pandemien medførte betydelige udfordringer for prognoser på grund af dens forstyrrende og hidtil usete virkninger på næsten alle aspekter af arbejds- og socialliv. For langsigtede indtægtsprognoser medførte forstyrrelsen også uventede nedstrømspåvirkninger. For at illustrere dette problem viser den følgende figur et eksempel på en tidsserie, hvor produktomsætningen oplevede et betydeligt fald i begyndelsen af pandemien og gradvist kom sig tilbage bagefter. En typisk neural prognosemodel vil tage indtægtsdata, herunder COVID-perioden uden for distribution (OOD) som det historiske kontekstinput, såvel som grundsandheden for modeltræning. Som følge heraf er de producerede prognoser ikke længere pålidelige.

Modelleringstilgange
I dette afsnit diskuterer vi vores forskellige modelleringstilgange.
Amazon prognose
Forecast er en fuldt administreret AI/ML-tjeneste fra AWS, der leverer forudkonfigurerede, avancerede tidsserieprognosemodeller. Det kombinerer disse tilbud med dets interne muligheder for automatiseret hyperparameteroptimering, ensemblemodellering (for modellerne leveret af Forecast) og probabilistisk prognosegenerering. Dette giver dig mulighed for nemt at indtage tilpassede datasæt, forbehandle data, træne prognosemodeller og generere robuste prognoser. Tjenestens modulære design gør os yderligere i stand til nemt at forespørge og kombinere forudsigelser fra yderligere tilpassede modeller udviklet parallelt.
Vi inkorporerer to neurale prognosere fra Forecast: CNN-QR og DeepAR+. Begge er superviserede deep learning-metoder, der træner en global model for hele tidsseriedatasættet. Både CNNQR- og DeepAR+-modeller kan indtage statiske metadataoplysninger om hver tidsserie, som er det tilsvarende produkt, region og forretningsorganisation i vores tilfælde. De tilføjer også automatisk tidsmæssige funktioner såsom måned i året som en del af input til modellen.
Transformer med opmærksomhedsmasker til COVID
Transformer-arkitekturen (Vaswani et al.), oprindeligt designet til naturlig sprogbehandling (NLP), opstod for nylig som et populært arkitektonisk valg til tidsserieprognoser. Her brugte vi Transformer-arkitekturen beskrevet i Zhou et al. uden probabilistisk log sparsom opmærksomhed. Modellen bruger et typisk arkitekturdesign ved at kombinere en koder og en dekoder. Til indtægtsprognose konfigurerer vi dekoderen til direkte at udlæse prognosen for 12-måneders horisonten i stedet for at generere prognosen måned for måned på en autoregressiv måde. Baseret på frekvensen af tidsserien tilføjes yderligere tidsrelaterede funktioner såsom måned i året som inputvariabel. Yderligere kategoriske variabler, der beskriver metainformationen (produkt, region, virksomhedsorganisation) føres ind i netværket via et indlejringslag, der kan trænes.
Følgende diagram illustrerer transformatorarkitekturen og opmærksomhedsmaskeringsmekanismen. Opmærksomhedsmaskering anvendes i alle koder- og dekoderlagene, som fremhævet med orange, for at forhindre OOD-data i at påvirke prognoserne.

Vi afbøder virkningen af OOD-kontekstvinduer ved at tilføje opmærksomhedsmasker. Modellen er trænet til at have meget lidt opmærksomhed på COVID-perioden, der indeholder outliers via maskering, og udfører prognoser med maskeret information. Opmærksomhedsmasken påføres gennem hvert lag af dekoder- og enkoderarkitekturen. Det maskerede vindue kan enten specificeres manuelt eller gennem en afvigende detekteringsalgoritme. Derudover, når du bruger et tidsvindue, der indeholder outliers som træningsetiketter, forplantes tabene ikke tilbage. Denne opmærksomhedsmaskeringsbaserede metode kan anvendes til at håndtere forstyrrelser og OOD-sager forårsaget af andre sjældne hændelser og forbedre robustheden af prognoserne.
Model ensemble
Modelensemble udkonkurrerer ofte enkelte modeller til prognoser - det forbedrer modellens generaliserbarhed og er bedre til at håndtere tidsseriedata med varierende karakteristika i periodicitet og intermittens. Vi inkorporerer en række modelensemblestrategier for at forbedre modelydelsen og robustheden af prognoser. En almindelig form for deep learning model-ensemble er at samle resultater fra modelkørsler med forskellige tilfældige vægtinitialiseringer eller fra forskellige træningsepoker. Vi bruger denne strategi til at opnå prognoser for Transformer-modellen.
For yderligere at bygge et ensemble oven på forskellige modelarkitekturer, såsom Transformer, CNNQR og DeepAR+, bruger vi en pan-model ensemblestrategi, der udvælger de top-k bedst ydende modeller for hver tidsserie baseret på backtest-resultaterne og opnår deres gennemsnit. Fordi backtest-resultater kan eksporteres direkte fra trænede Forecast-modeller, giver denne strategi os mulighed for at drage fordel af nøglefærdige tjenester som Forecast med forbedringer opnået fra brugerdefinerede modeller såsom Transformer. En sådan ende-til-ende modelensembletilgang kræver ikke træning af en meta-lærer eller beregning af tidsseriefunktioner til modelvalg.
Hierarkisk forsoning
Rammen er adaptiv til at inkorporere en bred vifte af teknikker som efterbehandlingstrin til hierarkisk prognoseafstemning, herunder bottom-up (BU), top-down afstemning med prognoseproportioner (TDFP), ordinært mindste kvadrat (OLS) og vægtet mindste kvadrat ( WLS). Alle eksperimentelle resultater i dette indlæg er rapporteret ved hjælp af top-down afstemning med prognoseproportioner.
Arkitektur oversigt
Vi udviklede et automatiseret end-to-end workflow på AWS for at generere indtægtsprognoser ved at bruge tjenester, herunder Forecast, SageMaker, Amazon Simple Storage Service (Amazon S3), AWS Lambda, AWS-trinfunktionerog AWS Cloud Development Kit (AWS CDK). Den implementerede løsning giver individuelle tidsserieprognoser gennem en REST API ved hjælp af Amazon API Gateway, ved at returnere resultaterne i foruddefineret JSON-format.
Følgende diagram illustrerer ende-til-ende prognose arbejdsgangen.

Nøgle designovervejelser for arkitekturen er alsidighed, ydeevne og brugervenlighed. Systemet bør være tilstrækkeligt alsidigt til at inkorporere et mangfoldigt sæt af algoritmer under udvikling og implementering med minimale nødvendige ændringer og kan nemt udvides, når der tilføjes nye algoritmer i fremtiden. Systemet bør også tilføje minimum overhead og understøtte paralleliseret træning for både Forecast og SageMaker for at reducere træningstiden og opnå den seneste prognose hurtigere. Endelig skal systemet være enkelt at bruge til eksperimenterende formål.
End-to-end workflowet kører sekventielt gennem følgende moduler:
- Et forbehandlingsmodul til omformatering og transformation af data
- Et modeltræningsmodul, der inkorporerer både Forecast-modellen og brugerdefineret model på SageMaker (begge kører parallelt)
- Et efterbehandlingsmodul, der understøtter modelensemble, hierarkisk afstemning, metrikker og rapportgenerering
Step Functions organiserer og orkestrerer arbejdsgangen fra ende til anden som en tilstandsmaskine. Kørslen til tilstandsmaskinen er konfigureret med en JSON-fil, der indeholder alle nødvendige oplysninger, inklusive placeringen af de historiske indtægts-CSV-filer i Amazon S3, prognosens starttidspunkt og modelhyperparameterindstillinger for at køre end-to-end workflowet. Asynkrone opkald oprettes for at parallelisere modeltræning i tilstandsmaskinen ved hjælp af Lambda-funktioner. Alle de historiske data, konfigurationsfiler, prognoseresultater samt mellemresultater såsom backtesting-resultater gemmes i Amazon S3. REST API er bygget oven på Amazon S3 for at give en forespørgselsgrænseflade til forespørgsel om prognoseresultater. Systemet kan udvides til at inkorporere nye prognosemodeller og understøttende funktioner såsom generering af prognosevisualiseringsrapporter.
Evaluering
I dette afsnit beskriver vi eksperimentets opsætning. Nøglekomponenter omfatter datasættet, evalueringsmetrikker, backtest-vinduer og modelopsætning og træning.
datasæt
For at beskytte Boschs økonomiske privatliv, mens vi brugte et meningsfuldt datasæt, brugte vi et syntetisk datasæt, der har lignende statistiske karakteristika som et virkeligt indtægtsdatasæt fra én forretningsenhed hos Bosch. Datasættet indeholder i alt 1,216 tidsserier med omsætning registreret i en månedlig frekvens, der dækker januar 2016 til april 2022. Datasættet leveres med 877 tidsserier på det mest granulære niveau (nederste tidsserie), med en tilsvarende grupperet tidsseriestruktur repræsenteret som en summeringsmatrix S. Hver tidsserie er knyttet til tre statiske kategoriske attributter, som svarer til produktkategori, region og organisatorisk enhed i det reelle datasæt (anonymiseret i de syntetiske data).
Evalueringsmålinger
Vi bruger median-middelværdi af Arctangent Absolute Percentage Error (median-MAAPE) og vægtet-MAAPE til at evaluere modellens ydeevne og udføre sammenlignende analyse, som er standardmålingerne, der bruges hos Bosch. MAAPE adresserer manglerne ved MAP-metrikken (Mean Absolute Percentage Error), der almindeligvis bruges i forretningssammenhæng. Median-MAAPE giver et overblik over modellens ydeevne ved at beregne medianen af MAAPE'erne beregnet individuelt på hver tidsserie. Vægtet-MAAPE rapporterer en vægtet kombination af de individuelle MAAPE'er. Vægtene er andelen af omsætningen for hver tidsserie sammenlignet med den aggregerede omsætning for hele datasættet. Vægtet-MAAPE afspejler bedre nedstrøms forretningspåvirkninger af prognosenøjagtigheden. Begge metrics er rapporteret på hele datasættet på 1,216 tidsserier.
Backtest vinduer
Vi bruger rullende 12-måneders backtest-vinduer til at sammenligne modellens ydeevne. Følgende figur illustrerer backtest-vinduerne, der blev brugt i eksperimenterne, og fremhæver de tilsvarende data, der bruges til træning og hyperparameteroptimering (HPO). For backtest-vinduer efter COVID-19-start er resultatet påvirket af OOD-input fra april til maj 2020, baseret på det, vi observerede fra omsætningstidsserien.

Modelopsætning og træning
Til transformertræning brugte vi kvantiltab og skalerede hver tidsserie ved hjælp af dens historiske middelværdi, før vi indførte den i Transformer og beregnede træningstabet. De endelige prognoser skaleres tilbage for at beregne nøjagtighedsmålingerne ved hjælp af MeanScaler implementeret i GluonTS. Vi bruger et kontekstvindue med månedlige omsætningsdata fra de seneste 18 måneder, valgt via HPO i backtest-vinduet fra juli 2018 til juni 2019. Yderligere metadata om hver tidsserie i form af statiske kategoriske variabler fødes ind i modellen via en indlejring lag, før det føres til transformerlagene. Vi træner transformatoren med fem forskellige tilfældige vægtinitialiseringer og gennemsnit prognoseresultaterne fra de sidste tre epoker for hver kørsel, i alt i gennemsnit 15 modeller. De fem modeltræningsløb kan paralleliseres for at reducere træningstiden. For den maskerede Transformer angiver vi månederne fra april til maj 2020 som outliers.
For al Forecast-modeltræning aktiverede vi automatisk HPO, som kan vælge model og træningsparametre baseret på en brugerspecificeret backtest-periode, som er sat til de sidste 12 måneder i datavinduet, der bruges til træning og HPO.
Eksperimentresultater
Vi træner maskerede og afmaskede Transformers ved hjælp af det samme sæt hyperparametre og sammenlignede deres ydeevne for backtest-vinduer umiddelbart efter COVID-19-chok. I den maskerede Transformer er de to maskerede måneder april og maj 2020. Følgende tabel viser resultaterne fra en række backtest-perioder med 12-måneders prognosevinduer startende fra juni 2020. Vi kan observere, at den maskerede Transformer konsekvent klarer sig bedre end den umaskerede version .

Vi udførte yderligere evaluering på modelensemblestrategien baseret på backtest-resultater. Især sammenligner vi de to tilfælde, hvor kun den bedst præsterende model er valgt i forhold til når de to bedst præsterende modeller er valgt, og modelgennemsnittet udføres ved at beregne middelværdien af prognoserne. Vi sammenligner ydelsen af basismodellerne og ensemblemodellerne i de følgende figurer. Bemærk, at ingen af neurale prognosere konsekvent udkonkurrerer andre for de rullende tilbagetestvinduer.


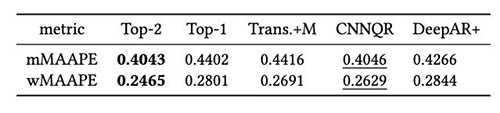
Følgende tabel viser, at ensemblemodellering af de to øverste modeller i gennemsnit giver den bedste ydeevne. CNNQR giver det næstbedste resultat.
Konklusion
Dette indlæg demonstrerede, hvordan man bygger en end-to-end ML-løsning til storskala prognoseproblemer ved at kombinere Forecast og en tilpasset model trænet på SageMaker. Afhængigt af dine forretningsbehov og ML-viden kan du bruge en fuldt administreret tjeneste såsom Forecast til at aflaste opbygnings-, oplærings- og implementeringsprocessen for en prognosemodel; byg din brugerdefinerede model med specifikke tuning-mekanismer med SageMaker; eller udføre modelensembling ved at kombinere de to tjenester.
Hvis du gerne vil have hjælp til at fremskynde brugen af ML i dine produkter og tjenester, så kontakt venligst Amazon ML Solutions Lab program.
Referencer
Hyndman RJ, Athanasopoulos G. Forecasting: principper og praksis. Otekster; 2018. maj 8.
Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez AN, Kaiser Ł, Polosukhin I. Opmærksomhed er alt hvad du behøver. Fremskridt inden for neurale informationsbehandlingssystemer. 2017;30.
Zhou H, Zhang S, Peng J, Zhang S, Li J, Xiong H, Zhang W. Informer: Beyond effektiv transformer til lang sekvens tidsserie prognoser. InProceedings af AAAI 2021 2. februar.
Om forfatterne
 Goktug Cinar er en ledende ML-forsker og den tekniske leder af ML og statistik-baserede prognoser hos Robert Bosch LLC og Bosch Center for Artificial Intelligence. Han leder forskningen i prognosemodellerne, hierarkisk konsolidering og modelkombinationsteknikker samt softwareudviklingsteamet, som skalerer disse modeller og tjener dem som en del af den interne end-to-end finansiel prognosesoftware.
Goktug Cinar er en ledende ML-forsker og den tekniske leder af ML og statistik-baserede prognoser hos Robert Bosch LLC og Bosch Center for Artificial Intelligence. Han leder forskningen i prognosemodellerne, hierarkisk konsolidering og modelkombinationsteknikker samt softwareudviklingsteamet, som skalerer disse modeller og tjener dem som en del af den interne end-to-end finansiel prognosesoftware.
 Michael Binder er produktejer hos Bosch Global Services, hvor han koordinerer udviklingen, implementeringen og implementeringen af den virksomhedsdækkende prædiktive analyseapplikation til storstilet automatiseret datadrevet prognose af finansielle nøgletal.
Michael Binder er produktejer hos Bosch Global Services, hvor han koordinerer udviklingen, implementeringen og implementeringen af den virksomhedsdækkende prædiktive analyseapplikation til storstilet automatiseret datadrevet prognose af finansielle nøgletal.
 Adrian Horvath er softwareudvikler hos Bosch Center for Artificial Intelligence, hvor han udvikler og vedligeholder systemer til at skabe forudsigelser baseret på forskellige prognosemodeller.
Adrian Horvath er softwareudvikler hos Bosch Center for Artificial Intelligence, hvor han udvikler og vedligeholder systemer til at skabe forudsigelser baseret på forskellige prognosemodeller.
 Panpan Xu er Senior Applied Scientist og Manager hos Amazon ML Solutions Lab hos AWS. Hun arbejder på forskning og udvikling af Machine Learning-algoritmer til højtydende kundeapplikationer i en række industrielle vertikaler for at accelerere deres AI og cloud-adoption. Hendes forskningsinteresse omfatter modelfortolkning, kausal analyse, human-in-the-loop AI og interaktiv datavisualisering.
Panpan Xu er Senior Applied Scientist og Manager hos Amazon ML Solutions Lab hos AWS. Hun arbejder på forskning og udvikling af Machine Learning-algoritmer til højtydende kundeapplikationer i en række industrielle vertikaler for at accelerere deres AI og cloud-adoption. Hendes forskningsinteresse omfatter modelfortolkning, kausal analyse, human-in-the-loop AI og interaktiv datavisualisering.
 Jasleen Grewal er en Applied Scientist hos Amazon Web Services, hvor hun arbejder med AWS-kunder for at løse problemer i den virkelige verden ved hjælp af maskinlæring, med særligt fokus på præcisionsmedicin og genomik. Hun har en stærk baggrund inden for bioinformatik, onkologi og klinisk genomik. Hun brænder for at bruge AI/ML og cloud-tjenester til at forbedre patientbehandlingen.
Jasleen Grewal er en Applied Scientist hos Amazon Web Services, hvor hun arbejder med AWS-kunder for at løse problemer i den virkelige verden ved hjælp af maskinlæring, med særligt fokus på præcisionsmedicin og genomik. Hun har en stærk baggrund inden for bioinformatik, onkologi og klinisk genomik. Hun brænder for at bruge AI/ML og cloud-tjenester til at forbedre patientbehandlingen.
 Selvan Senthivel er en Senior ML Engineer hos Amazon ML Solutions Lab hos AWS, med fokus på at hjælpe kunder med maskinlæring, deep learning-problemer og end-to-end ML-løsninger. Han var grundlægger af Amazon Comprehend Medical og bidrog til design og arkitektur af flere AWS AI-tjenester.
Selvan Senthivel er en Senior ML Engineer hos Amazon ML Solutions Lab hos AWS, med fokus på at hjælpe kunder med maskinlæring, deep learning-problemer og end-to-end ML-løsninger. Han var grundlægger af Amazon Comprehend Medical og bidrog til design og arkitektur af flere AWS AI-tjenester.
 Ruilin Zhang er en SDE med Amazon ML Solutions Lab hos AWS. Han hjælper kunder med at adoptere AWS AI-tjenester ved at bygge løsninger til at løse almindelige forretningsproblemer.
Ruilin Zhang er en SDE med Amazon ML Solutions Lab hos AWS. Han hjælper kunder med at adoptere AWS AI-tjenester ved at bygge løsninger til at løse almindelige forretningsproblemer.
 Shane Rai er Sr. ML-strateg hos Amazon ML Solutions Lab hos AWS. Han arbejder med kunder på tværs af et bredt spektrum af industrier for at løse deres mest presserende og innovative forretningsbehov ved at bruge AWS's bredde af cloud-baserede AI/ML-tjenester.
Shane Rai er Sr. ML-strateg hos Amazon ML Solutions Lab hos AWS. Han arbejder med kunder på tværs af et bredt spektrum af industrier for at løse deres mest presserende og innovative forretningsbehov ved at bruge AWS's bredde af cloud-baserede AI/ML-tjenester.
 Lin Lee Cheong er en Applied Science Manager hos Amazon ML Solutions Lab-teamet hos AWS. Hun arbejder med strategiske AWS-kunder for at udforske og anvende kunstig intelligens og maskinlæring for at opdage ny indsigt og løse komplekse problemer.
Lin Lee Cheong er en Applied Science Manager hos Amazon ML Solutions Lab-teamet hos AWS. Hun arbejder med strategiske AWS-kunder for at udforske og anvende kunstig intelligens og maskinlæring for at opdage ny indsigt og løse komplekse problemer.