
Introduktion
Kunstig intelligens (AI) har gjort betydelige fremskridt i forskellige industrier, og sundhedspleje er ingen undtagelse. Et af de mest lovende områder inden for AI i sundhedsvæsenet er Natural Language Processing (NLP), som har potentialet til at revolutionere patientbehandlingen ved at facilitere mere effektiv og præcis dataanalyse og kommunikation.
NLP har vist sig at være en game changer inden for sundhedsområdet. NLP transformerer den måde, sundhedsudbydere leverer patientpleje på. Fra befolkningssundhedsstyring til sygdomsdetektion hjælper NLP sundhedspersonale med at træffe informerede beslutninger og give bedre behandlingsresultater.
Læringsmål
- Forståelse og analyse af brugen af NLP og AI i sundhedsvæsenet
- Få styr på det grundlæggende i NLP
- Få at vide om nogle almindeligt anvendte NLP-biblioteker i sundhedsvæsenet
- Lær om anvendelsesmulighederne for NLP i sundhedsvæsenet
Denne artikel blev offentliggjort som en del af Data Science Blogathon.
Indholdsfortegnelse
- Motivationen for at bruge AI og NLP i sundhedsvæsenet
- Hvad er naturlig sprogbehandling?
- Forskellige teknikker brugt i NLP
3.1 Regelbaserede teknikker
3.2 Statistiske teknikker ved hjælp af maskinlæringsmodeller
3.3 Overfør læring - Forskellige NLP-biblioteker og deres rammer
- Hvad er store sprogmodeller (LLM)?
- NLP i klinisk tekst – Behovet for en anden tilgang
- Nogle NLP-biblioteker, der bruges i sundhedssektoren
- Forståelse af de kliniske datasæt
- Hvad er de forskellige typer kliniske data?
- Anvendelsestilfælde og anvendelser af NLP i sundhedssektoren
- Hvordan bygger man NLP-pipeline med klinisk tekst?
11.1 Løsningsdesign
11.2 Trin-for-trin kode - Konklusion
Motivationen for at bruge AI og NLP i sundhedsvæsenet
Motivationen for at bruge AI og NLP i sundhedsvæsenet er forankret i at forbedre patientpleje og behandlingsresultater og samtidig reducere sundhedsomkostningerne. Sundhedsindustrien genererer enorme mængder data, herunder EMR'er, kliniske noter og sundhedsrelaterede indlæg på sociale medier, som kan give værdifuld indsigt i patienters helbred og behandlingsresultater. Men meget af disse data er ustrukturerede og vanskelige at analysere manuelt.
Derudover står sundhedsindustrien over for flere udfordringer, såsom en aldrende befolkning, stigende forekomst af kroniske sygdomme og mangel på sundhedspersonale.
Disse udfordringer har ført til et stigende behov for mere effektiv og effektiv levering af sundhedsydelser.
Ved at give værdifuld indsigt fra ustrukturerede medicinske data kan NLP hjælpe med at forbedre patientpleje og behandlingsresultater og støtte sundhedspersonale i at træffe mere informerede kliniske beslutninger.
Hvad er naturlig sprogbehandling?
Natural Language Processing (NLP) er et underområde af kunstig intelligens (AI), der beskæftiger sig med interaktionen mellem computere og menneskelige sprog. Det bruger beregningsteknikker til at analysere, forstå og generere menneskeligt sprog. NLP bruges i mange applikationer, herunder talegenkendelse, maskinoversættelse, sentimentanalyse og tekstresumé.
Vi vil nu udforske de forskellige NLP-teknikker, biblioteker og rammer.
Forskellige teknikker brugt i NLP
Der er to almindeligt anvendte teknikker, der bruges i NLP-industrien.
1. Regelbaserede teknikker: stol på foruddefinerede grammatikregler og ordbøger
2. Statistiske teknikker: brug maskinlæringsalgoritmer til at analysere og forstå sprog
3. Stor sprogmodel ved hjælp af Overfør læring
Her er en standard NLP Pipeline med forskellige NLP opgaver
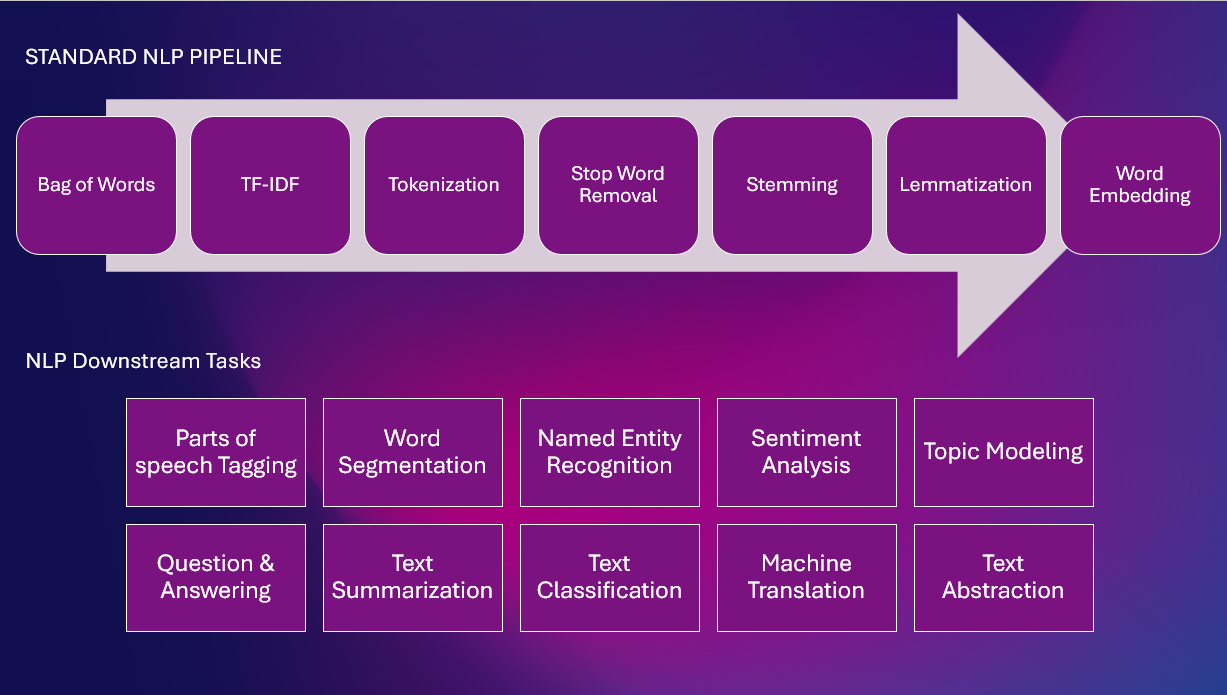
Regelbaserede teknikker
Disse teknikker involverer at skabe et sæt håndlavede regler eller mønstre for at udtrække meningsfuld information fra tekst. Regelbaserede systemer fungerer typisk ved at definere specifikke mønstre, der matcher målinformationen, såsom navngivne enheder eller specifikke søgeord, og derefter udtrække disse oplysninger baseret på disse mønstre. Regelbaserede systemer er hurtige, pålidelige og ligetil, men de er begrænset af kvaliteten og antallet af definerede regler, og de kan være svære at vedligeholde og opdatere.
For eksempel kunne et regelbaseret system til navngivne enhedsgenkendelse designes til at identificere egennavne i tekst og kategorisere dem i foruddefinerede enhedstyper, såsom en person, lokation, organisation, sygdom, stoffer osv. Systemet ville bruge en serie af regler for at identificere mønstre i teksten, der matcher kriterierne for hver enhedstype, såsom brug af store bogstaver for personnavne eller specifikke søgeord for organisationer.
Statistiske teknikker ved hjælp af maskinlæringsmodeller
Disse teknikker bruger statistiske algoritmer til at lære mønstre i dataene og lave forudsigelser baseret på disse mønstre. Maskinlæringsmodeller kan trænes på store mængder annoterede data, hvilket gør dem mere fleksible og skalerbare end regelbaserede systemer. Der bruges flere typer maskinlæringsmodeller i NLP, bl.a beslutning træer, tilfældige skove, understøtte vektormaskinerog neurale netværk.
For eksempel kunne en maskinlæringsmodel til sentimentanalyse trænes på et stort korpus af kommenteret tekst, hvor hver tekst er mærket som positiv, negativ eller neutral. Modellen vil lære de statistiske mønstre i dataene, der skelner mellem positiv og negativ tekst, og derefter bruge disse mønstre til at lave forudsigelser om ny, uset tekst. Fordelen ved denne tilgang er, at modellen kan lære at identificere følelsesmønstre, som ikke er eksplicit defineret i reglerne.
Overfør læring
Disse teknikker er en hybrid tilgang, der kombinerer styrkerne ved regelbaserede og maskinlæringsmodeller. Transfer learning bruger en forudtrænet maskinlæringsmodel, såsom en sprogmodel trænet på et stort korpus af tekst, som udgangspunkt for at finjustere en specifik opgave eller domæne. Denne tilgang udnytter den generelle viden lært fra den præ-trænede model, reducerer mængden af mærkede data, der kræves til træning, og giver mulighed for hurtigere og mere præcise forudsigelser på en specifik opgave.
For eksempel kunne en overførselsindlæringstilgang til anerkendelse af navngivne enheder finjustere en fortrænet sprogmodel på et mindre korpus af kommenteret medicinsk tekst. Modellen ville starte med den generelle viden lært fra den fortrænede model og derefter justere dens vægte for at matche den medicinske teksts mønstre bedre. Denne tilgang ville reducere mængden af mærkede data, der kræves til træning, og resultere i en mere nøjagtig model for navngivne entitetsgenkendelse i det medicinske domæne.
Forskellige NLP-biblioteker og deres rammer
Forskellige biblioteker tilbyder en bred vifte af NLP-funktioner. Såsom :

Natural Language Processing (NLP) biblioteker og rammer er softwareværktøjer, der hjælper med at udvikle og implementere NLP-applikationer. Adskillige NLP biblioteker og rammer er tilgængelige, hver med styrker, svagheder og fokusområder.
Disse værktøjer varierer med hensyn til kompleksiteten af de algoritmer, de understøtter, størrelsen af de modeller, de kan håndtere, brugervenligheden og graden af tilpasning, de tillader.
Hvad er store sprogmodeller (LLM)?
Store sprogmodeller trænes på enorme mængder data. Kan generere menneskelignende tekst og udføre en lang række NLP-opgaver med høj nøjagtighed.
Her er nogle eksempler på store sprogmodeller og en kort beskrivelse af hver:
GPT-3 (Generative Pretrained Transformer 3): Udviklet af OpenAI, GPT-3 er en stor transformator-baseret sprogmodel, der bruger dyb læringsalgoritmer til at generere menneskelignende tekst. Det er blevet trænet på et massivt korpus af tekstdata, hvilket gør det muligt at generere sammenhængende og kontekstuelt passende tekstsvar baseret på en prompt.
BERTI (Tovejs indkoderrepræsentationer fra transformere): BERT er udviklet af Google og er en transformatorbaseret sprogmodel, der er blevet fortrænet på et stort korpus af tekstdata. Det er designet til at fungere godt på en bred vifte af NLP-opgaver, såsom navngivne entitetsgenkendelse, besvarelse af spørgsmål og tekstklassificering, ved at indkode konteksten og relationerne mellem ord i en sætning.
ROBERTA (Robust optimeret BERT-tilgang): RoBERTa er udviklet af Facebook AI og er en variant af BERT, der er blevet finjusteret og optimeret til NLP-opgaver. Det er blevet trænet på et større korpus af tekstdata og bruger en anden træningsstrategi end BERT, hvilket fører til forbedret ydeevne på NLP-benchmarks.
ELMo (indlejringer fra sprogmodeller): Udviklet af Allen Institute for AI, ELMo er en dyb kontekstualiseret ordrepræsentationsmodel, der bruger et tovejs LSTM (Long Short-Term Memory) netværk til at lære sprogrepræsentationer fra et stort korpus af tekstdata. ELMo kan finjusteres til specifikke NLP-opgaver eller bruges som funktionsudtræk til andre maskinlæringsmodeller.
ULMFiT (Universal Language Model Fine-Tuning): ULMFiT er udviklet af FastAI og er en overførselsindlæringsmetode, der finjusterer en forudtrænet sprogmodel på en specifik NLP-opgave ved hjælp af en lille mængde opgavespecifikke kommenterede data. ULMFiT har opnået state-of-the-art ydeevne på en bred vifte af NLP-benchmarks og betragtes som et førende eksempel på overførselslæring i NLP.
NLP i klinisk tekst: Behovet for anderledes tilgang
Klinisk tekst er ofte ustruktureret og indeholder en masse medicinsk jargon og akronymer, hvilket gør det vanskeligt for traditionelle NLP-modeller at forstå og behandle. Derudover inkluderer klinisk tekst ofte vigtig information såsom sygdom, lægemidler, patientoplysninger, diagnoser og behandlingsplaner, som kræver specialiserede NLP-modeller, der nøjagtigt kan udtrække og forstå denne medicinske information.
En anden grund til, at klinisk tekst har brug for forskellige NLP-modeller, er, at den indeholder en stor mængde data spredt på tværs af forskellige kilder, såsom EPJ'er, kliniske noter og radiologirapporter, som skal integreres. Dette kræver modeller, der kan behandle og forstå teksten og linke og integrere data på tværs af forskellige kilder og etablere klinisk acceptable relationer.
Endelig indeholder klinisk tekst ofte følsomme patientoplysninger og skal beskyttes af strenge regler såsom HIPAA. NLP-modeller, der bruges til at behandle klinisk tekst, skal være i stand til at identificere og beskytte følsom patientinformation, mens de stadig giver nyttig indsigt.
Nogle NLP-biblioteker, der bruges i sundhedssektoren
Tekstdata inden for medicin kræver et specialiseret Natural Language Processing (NLP) system, der er i stand til at udtrække medicinsk information fra forskellige kilder såsom kliniske tekster og andre medicinske dokumenter.
Her er en liste over NLP-biblioteker og modeller, der er specifikke for det medicinske domæne:
rum: Det er et open source NLP-bibliotek, der leverer out-of-the-box-modeller til forskellige domæner, herunder det medicinske domæne.
ScispaCy: En specialiseret version af spaCy, der er trænet specifikt i videnskabelig og biomedicinsk tekst, hvilket gør den ideel til behandling af medicinsk tekst.
BioBERT: En præ-trænet transformer-baseret model specielt designet til det biomedicinske domæne. Det er fortrænet med Wiki + Books + PubMed + PMC.
ClinicalBERT: En anden præ-trænet model designet til at behandle kliniske noter og udskrivningsresuméer fra MIMIC-III-databasen.
Med7: En transformator-baseret model, der blev trænet i elektroniske sundhedsjournaler (EPJ) til at udtrække syv centrale kliniske koncepter, herunder diagnose, medicin og laboratorietests.
DisMod-ML: En probabilistisk modelleringsramme for sygdomsmodellering, der bruger NLP-teknikker til at behandle medicinsk tekst.
LÆGE: Et regelbaseret NLP-system til at udtrække medicinsk information fra tekst.
Dette er nogle af de populære NLP-biblioteker og -modeller, der er specielt designet til det medicinske domæne. De tilbyder en række funktioner, fra forudtrænede modeller til regelbaserede systemer og kan hjælpe sundhedsorganisationer med at behandle medicinsk tekst effektivt.
I vores NER-model vil vi bruge spaCy og Scispacy. Disse biblioteker er forholdsvis nemme at køre på Google colab eller lokal infrastruktur.
BioBERT og ClinicalBERT ressourcekrævende store sprogmodeller har brug for GPU'er og højere infrastruktur.
Forståelse af de kliniske datasæt
Medicinske tekstdata kan fås fra forskellige kilder, såsom elektroniske sundhedsjournaler (EPJ'er), medicinske tidsskrifter, kliniske noter, medicinske websteder og databaser. Nogle af disse kilder leverer offentligt tilgængelige datasæt, der kan bruges til træning af NLP-modeller, mens andre kan kræve godkendelse og etiske overvejelser, før de får adgang til dataene. Kilderne til medicinske tekstdata omfatter:
1. Open source medicinske korpora som f.eks MIMIC-III database er en stor, åbent tilgængelig elektronisk sundhedsjournal (EPJ)-database fra patienter, der modtog pleje på Beth Israel Deaconess Medical Center mellem 2001 og 2012. Databasen indeholder information såsom patientdemografi, vitale tegn, laboratorietest, medicin, procedurer og notater fra sundhedspersonale, såsom sygeplejersker og læger. Derudover indeholder databasen information om patienters intensivophold, herunder typen af intensivafdeling, liggetid og udfald. Dataene i MIMIC-III er afidentificeret og kan bruges til forskningsformål til at understøtte udviklingen af prædiktive modeller og kliniske beslutningsstøttesystemer.
2. Nationalbiblioteket for Medicin ClinicalTrials.gov webstedet har data om kliniske forsøg og sygdomsovervågningsdata.
3. National Institutes of Health's National Library of Medicine, National Centres for Biotechnology Information (NCBI), og Verdenssundhedsorganisationen (WHO)
4. Sundhedsinstitutioner og -organisationer såsom hospitaler, klinikker og medicinalvirksomheder genererer store mængder medicinsk tekstdata gennem elektroniske sundhedsjournaler, kliniske notater, medicinsk transskription og medicinske rapporter.
5. Medicinske forskningstidsskrifter og databaser, såsom PubMed og CINAHL, indeholder enorme mængder af publicerede medicinske forskningsartikler og abstracts.
6. Sociale medieplatforme som Twitter kan give realtidsindsigt i patientperspektiver, lægemiddelanmeldelser og oplevelser.
For at træne NLP-modeller ved hjælp af medicinsk tekstdata er det vigtigt at overveje dataens kvalitet og relevans og sikre, at de er korrekt forbehandlet og formateret. Derudover er det vigtigt at overholde etiske og juridiske overvejelser, når man arbejder med følsomme medicinske oplysninger.
Hvad er de forskellige typer kliniske data?
Flere typer af kliniske data er almindeligt anvendt i sundhedsvæsenet:

Kliniske data refererer til oplysninger om individers sundhedspleje, herunder patientens sygehistorie, diagnoser, behandlinger, laboratorieresultater, billeddiagnostiske undersøgelser og andre relevante helbredsoplysninger.
EPJ/EMR data er knyttet til demografiske data (dette inkluderer personlige oplysninger såsom alder, køn, etnicitet og kontaktoplysninger.), Patientgenererede data (Denne type data genereres af patienterne selv, herunder oplysninger indsamlet gennem patientrapporterede resultatmål og patient -genererede sundhedsdata.)
Andre sæt data er:
Genomiske data: Denne type vedrører en persons genetiske information, herunder DNA-sekvenser og markører.
Data til bærbare enheder: Disse data omfatter oplysninger indsamlet fra bærbare enheder såsom fitness-trackere og hjertemonitorer.
Hver type kliniske data spiller en unik rolle i at give et omfattende overblik over en patients helbred og bruges på forskellige måder af sundhedsudbydere og forskere til at forbedre patientbehandlingen og informere behandlingsbeslutninger.
Anvendelsestilfælde og anvendelser af NLP i sundhedssektoren
Natural Language Processing (NLP) er blevet bredt udbredt i sundhedssektoren og har flere use cases. Nogle af de fremtrædende inkluderer:
Befolkning Sundhed: NLP kan bruges til at behandle store mængder ustrukturerede medicinske data såsom lægejournaler, undersøgelser og kravdata til at identificere mønstre, sammenhænge og indsigter. Dette hjælper med at overvåge befolkningens sundhed og tidlig opdagelse af sygdomme.
Patientpleje: NLP kan bruges til at behandle patienters elektroniske sundhedsjournaler (EPJ'er) for at udtrække vital information såsom diagnose, medicin og symptomer. Disse oplysninger kan bruges til at forbedre patientbehandlingen og give personlig behandling.
Påvisning af sygdom: NLP kan bruges til at behandle store mængder tekstdata, såsom videnskabelige artikler, nyhedsartikler og indlæg på sociale medier, for at opdage udbrud af infektionssygdomme.
Clinical Decision Support System (CDSS): NLP kan bruges til at analysere patienters elektroniske sundhedsjournaler for at yde beslutningsstøtte i realtid til sundhedsudbydere. Dette hjælper med at give de bedst mulige behandlingsmuligheder og forbedre den overordnede plejekvalitet.
Klinisk forsøg: NLP kan behandle data fra kliniske forsøg for at identificere sammenhænge og potentielle nye behandlinger.
Narkotikabivirkninger: NLP kan bruges til at behandle store mængder lægemiddelsikkerhedsdata for at identificere uønskede hændelser og lægemiddelinteraktioner.
Præcisionssundhed: NLP kan bruges til at behandle genomiske data og medicinske journaler for at identificere personlige behandlingsmuligheder for individuelle patienter.
Lægernes effektivitetsforbedring: NLP kan automatisere rutineopgaver såsom medicinsk kodning, dataindtastning og behandling af krav, hvilket frigør læger til at fokusere på at yde bedre patientpleje.
Dette er blot nogle få eksempler på, hvordan NLP revolutionerer sundhedsindustrien. Efterhånden som NLP-teknologien fortsætter med at udvikle sig, kan vi forvente at se flere innovative anvendelser af NLP i sundhedsvæsenet i fremtiden.
Hvordan bygger man NLP-pipeline med klinisk tekst?
Vi vil udvikle en trin-for-trin Spacy-pipeline ved hjælp af SciSpacy NER Model for Clinical Text.
Objektiv: Dette projekt har til formål at konstruere en NLP-pipeline ved hjælp af SciSpacy til at udføre tilpasset navngiven enhedsgenkendelse på kliniske tekster.
Resultat: Resultatet vil være at udtrække information vedrørende sygdomme, lægemidler og lægemiddeldoser fra klinisk tekst, som derefter kan bruges i forskellige NLP-downstream-applikationer.
Løsningsdesign:
Her er løsningen på højt niveau til at udtrække enhedsoplysninger fra klinisk tekst. NER-ekstraktion er en vigtig NLP-opgave, der bruges i de fleste af NLP-rørledningerne.
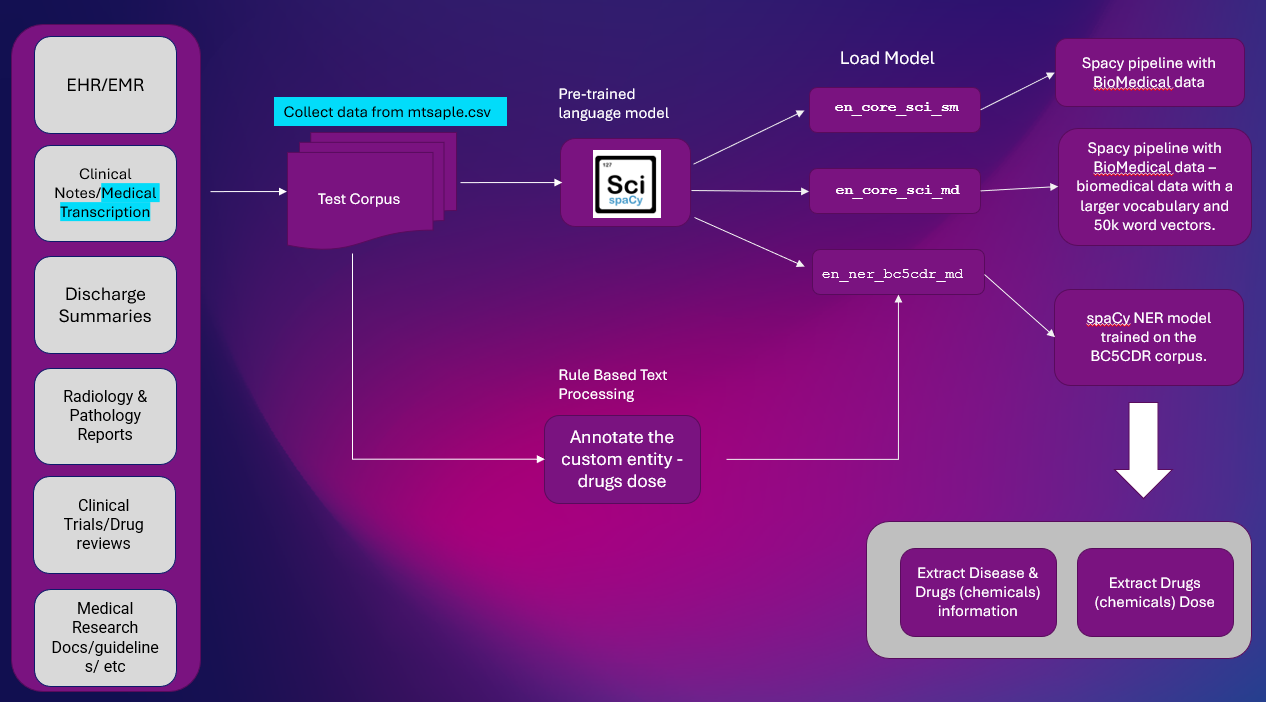
Platform: google colab
NLP biblioteker: spaCy & SciSpacy
datasæt: mtsample.csv (skrotede data fra mtsample).
Vi har brugt ScispaCy præ-trænet NER model en_ner_bc5cdr_md-0.5.1 at udvinde sygdom og medicin. Lægemidler udvindes som kemikalier.
en_ner_bc5cdr_md-0.5.1 er en spaCy-model for navngivne entitetsgenkendelse (NER) i det biomedicinske domæne.
"bc5cdr" refererer til BC5CDR corpus, et biomedicinsk tekstkorpus, der bruges til at træne modellen. "md" i navnet refererer til det biomedicinske domæne. "0.5.1" i navnet refererer til modellens version.
Vi vil bruge prøven "transkription"-teksten fra mtsample.csv og annotere ved hjælp af et regelbaseret mønster til at udtrække lægemiddeldoser.
Trin-for-trin kode:
Installer spacy & scispacy-pakker. spaCy-modeller er designet til at udføre specifikke NLP-opgaver, såsom tokenisering, ordstemmende tagging og navngivne entitetsgenkendelse.
!pip install -U spacy !pip install scispacy
Installer scispacy-basemodeller og NER-modeller
En_ner_bc5cdr_md-0.5.1-modellen er specifikt designet til at genkende navngivne enheder i biomedicinsk tekst, såsom sygdomme, gener og lægemidler, som kemikalier.
Denne model kan være nyttig til NLP-opgaver i det biomedicinske domæne, såsom informationsudtrækning, tekstklassificering og besvarelse af spørgsmål.
!pip install https://s3-us-west-2.amazonaws.com/ai2-s2-scispacy/releases/v0.5.1/en_core_sci_sm-0.5.1.tar.gz !pip install https://s3-us-west-2.amazonaws.com/ai2-s2-scispacy/releases/v0.5.1/en_core_sci_md-0.5.1.tar.gz !pip install https://s3-us-west-2.amazonaws.com/ai2-s2-scispacy/releases/v0.5.1/en_ner_bc5cdr_md-0.5.1.tar.gz
Installer andre pakker
pip install render
Importer pakker
import scispacy import spacy #Kernemodeller import en_core_sci_sm import en_core_sci_md
#NER specifikke modeller import en_ner_bc5cdr_md #Værktøjer til at udtrække og vise data fra spacy import displacy import pandaer som pd
Python kode:
Test modellerne med eksempeldata
# Vælg specifik transkription til brug (række 3, kolonne "transcription") og test scispacy NER-modellens tekst = mtsample_df.loc[10, "transcription"]

Indlæs specifik model: en_core_sci_sm og send tekst igennem
nlp_sm = en_core_sci_sm.load() doc = nlp_sm(tekst)
#Visning resulterer
enhedsudtrækning displacy_image = displacy.render(doc, jupyter=True,style='ent')

Bemærk, at enheden er tagget her. Mest medicinske termer. Disse er dog generiske enheder.
Indlæs nu den specifikke model: en_core_sci_md og send tekst igennem
nlp_md = en_core_sci_md.load() doc = nlp_md(tekst)
#Vis resulterende enhedsudtrækning
displacy_image = displacy.render(doc, jupyter=True,style='ent')

Denne gang er tallene også tagget som enheder af en_core_sci_md.
Indlæs nu specifik model: importer en_ner_bc5cdr_md og send tekst igennem
nlp_bc = en_ner_bc5cdr_md.load() doc = nlp_bc(tekst) #Display resulterende enhedsudtrækning displacy_image = displacy.render(doc, jupyter=True,style='ent')

Nu er to medicinske enheder mærket: sygdom og kemikalie(stoffer).
Vis enheden
print("TEXT", "START", "END", "ENTITY TYPE") for indgang i doc.ents: print(ent.text, ent.start_char, ent.end_char, ent.label_)
TEKST START SLUT ENHEDSTYPE
Sygelig fedme 26 40 SYGDOM
Sygelig fedme 70 84 SYGDOM
vægttab 400 411 SYGDOM
Marcaine 1256 1264 KEMISK
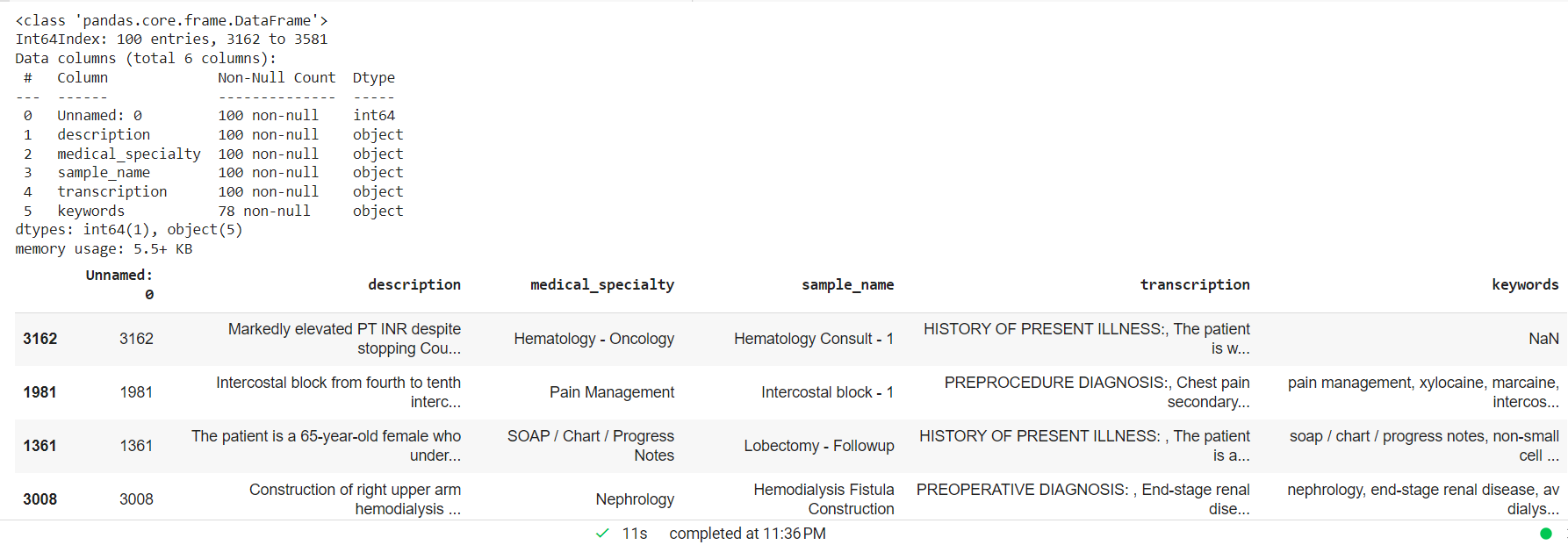
Bearbejd den kliniske tekst ved at droppe NAN-værdier og oprette en tilfældig mindre prøve til den tilpassede enhedsmodel.
mtsample_df.dropna(subset=['transcription'], inplace=True) mtsample_df_subset = mtsample_df.sample(n=100, replace=False, random_state=42) mtsample_df_subset.info() mtsample.head()_subset
spaCy matcher – Den regelbaserede matchning ligner brugen af regulære udtryk, men spaCy giver yderligere muligheder. Brug af tokens og relationer i et dokument gør det muligt for dig at identificere mønstre, der inkluderer entiteter ved hjælp af NER-modeller. Målet er at finde lægemiddelnavne og deres doseringer fra teksten, hvilket kan hjælpe med at opdage medicineringsfejl ved at sammenligne dem med standarder og retningslinjer.
Målet er at finde lægemiddelnavne og deres doseringer fra teksten, hvilket kan hjælpe med at opdage medicineringsfejl ved at sammenligne dem med standarder og retningslinjer.
fra spacy.matcher import Matcher
mønster = [{'ENT_TYPE':'CHEMICAL'}, {'LIKE_NUM': True}, {'IS_ASCII': True}] matcher = Matcher(nlp_bc.vocab) matcher.add("DRUG_DOSE", [mønster])
for transskription i mtsample_df_subset['transcription']: doc = nlp_bc(transcription) matches = matcher(doc) for match_id, start, end in matches: string_id = nlp_bc.vocab.strings[match_id] # get string repræsentation span = doc[start :end] # den matchede span tilføjelse af lægemidler doser print(span.text, start, end, string_id,) #Tilføj sygdom og lægemidler til indtastning i doc.ents: print(ent.text, ent.start_char, ent.end_char, ent .etiket_)
Outputtet vil vise de enheder, der er udtrukket fra den kliniske tekstprøve.
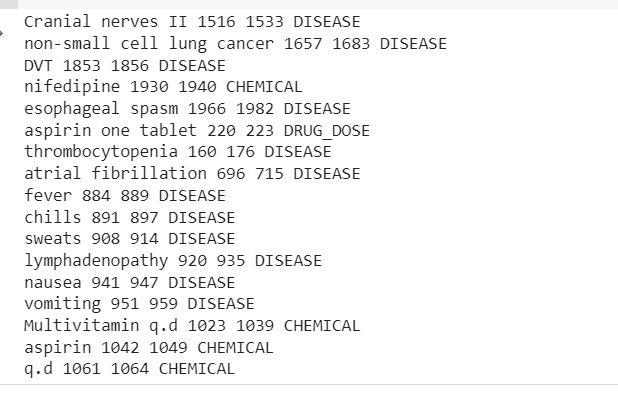
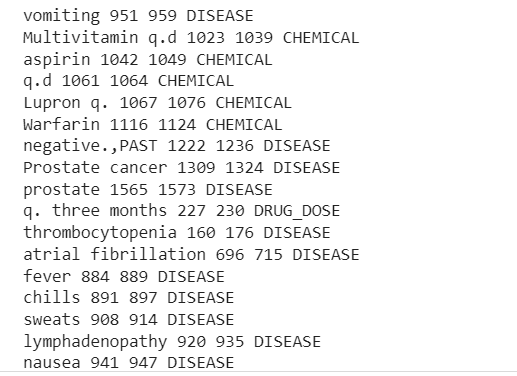
Nu kan vi se rørledningen udvundet Sygdom, lægemidler (kemikalier) og lægemidler-doser information fra den kliniske tekst.
Der er en vis fejlklassificering, men vi kan øge modellens ydeevne ved at bruge flere data.
Vi kan nu bruge disse medicinske enheder i forskellige opgaver som sygdomsdetektion, prædiktiv analyse, klinisk beslutningsstøttesystem, medicinsk tekstklassificering, opsummering, spørgsmål-besvarelse og mange flere.
Konklusion
1. I denne artikel har vi udforsket nogle af nøglefunktionerne ved NLP i sundhedsvæsenet, som vil hjælpe med at forstå de komplekse sundhedstekstdata.
Vi implementerede også scispaCy og spaCy og konstruerede en simpel brugerdefineret NER-model gennem en forudtrænet NER-model og regelbaseret matcher. Selvom vi kun har dækket én NER-model, er adskillige andre tilgængelige og en stor mængde ekstra funktionalitet at opdage.
2. Inden for scispaCy-rammen er der adskillige yderligere teknikker at udforske, herunder metoder til at detektere forkortelser, udføre afhængighedsparsing og identificere individuelle sætninger.
3. De seneste tendenser inden for NLP til sundhedspleje omfatter udviklingen af domænespecifikke modeller som BioBERT og ClinicalBert og brug af store sprogmodeller som GPT-3. Disse modeller tilbyder et højt niveau af nøjagtighed og effektivitet, men deres brug rejser også bekymringer om bias, privatliv og kontrol over data.
ChatGPT (en avanceret konversations-AI-model udviklet af OpenAI) gør allerede en enorm indflydelse i NLP-verdenen. Modellen er trænet på en massiv mængde tekstdata fra internettet og har evnen til at generere menneskelignende tekstsvar baseret på det input, den modtager. Det kan bruges til forskellige opgaver såsom besvarelse af spørgsmål, opsummering, oversættelse og meget mere. Modellen er også finjusteret til specifikke brugstilfælde, såsom generering af kode eller skrivning af artikler, for at forbedre dens ydeevne på de specifikke områder.
5. På trods af de mange fordele er NLP i sundhedsvæsenet dog ikke uden udfordringer. At sikre nøjagtigheden og retfærdigheden af NLP-modeller og overvinde bekymringer om databeskyttelse er nogle af de udfordringer, der skal løses for fuldt ud at realisere potentialet i NLP i sundhedsvæsenet.
6. Med sine mange fordele er det essentielt for sundhedspersonale at omfavne og inkorporere NLP i deres arbejdsgange. Selvom der er mange udfordringer at overvinde, er NLP i sundhedsvæsenet bestemt en trend, der er værd at se og investere i.
Mediet vist i denne artikel ejes ikke af Analytics Vidhya og bruges efter forfatterens skøn.
Relaterede
- SEO Powered Content & PR Distribution. Bliv forstærket i dag.
- Platoblokkæde. Web3 Metaverse Intelligence. Viden forstærket. Adgang her.
- Kilde: https://www.analyticsvidhya.com/blog/2023/02/extracting-medical-information-from-clinical-text-with-nlp/