
Einleitung
Maschinelles Lernen (ML) ist ein Forschungsgebiet, das sich auf die Entwicklung von Algorithmen konzentriert, um automatisch aus Daten zu lernen, Vorhersagen zu treffen und Muster abzuleiten, ohne dass explizit erklärt wird, wie es geht. Ziel ist es, Systeme zu schaffen, die sich mit Erfahrung und Daten automatisch verbessern.
Dies kann durch überwachtes Lernen erreicht werden, bei dem das Modell anhand gekennzeichneter Daten trainiert wird, um Vorhersagen zu treffen, oder durch unüberwachtes Lernen, bei dem das Modell versucht, Muster oder Korrelationen innerhalb der Daten aufzudecken, ohne dass bestimmte Zielausgaben vorhergesehen werden müssen.
ML hat sich in verschiedenen Disziplinen, darunter Informatik, Biologie, Finanzen und Marketing, zu einem unverzichtbaren und weit verbreiteten Werkzeug entwickelt. Es hat seinen Nutzen in verschiedenen Anwendungen wie der Bildklassifizierung, der Verarbeitung natürlicher Sprache und der Betrugserkennung unter Beweis gestellt.
Aufgaben des maschinellen Lernens
Maschinelles Lernen lässt sich grob in drei Hauptaufgaben einteilen:
- Überwachtes Lernen
- Unbeaufsichtigtes Lernen
- Verstärkung lernen
Hier konzentrieren wir uns auf die ersten beiden Fälle.
Überwachtes Lernen
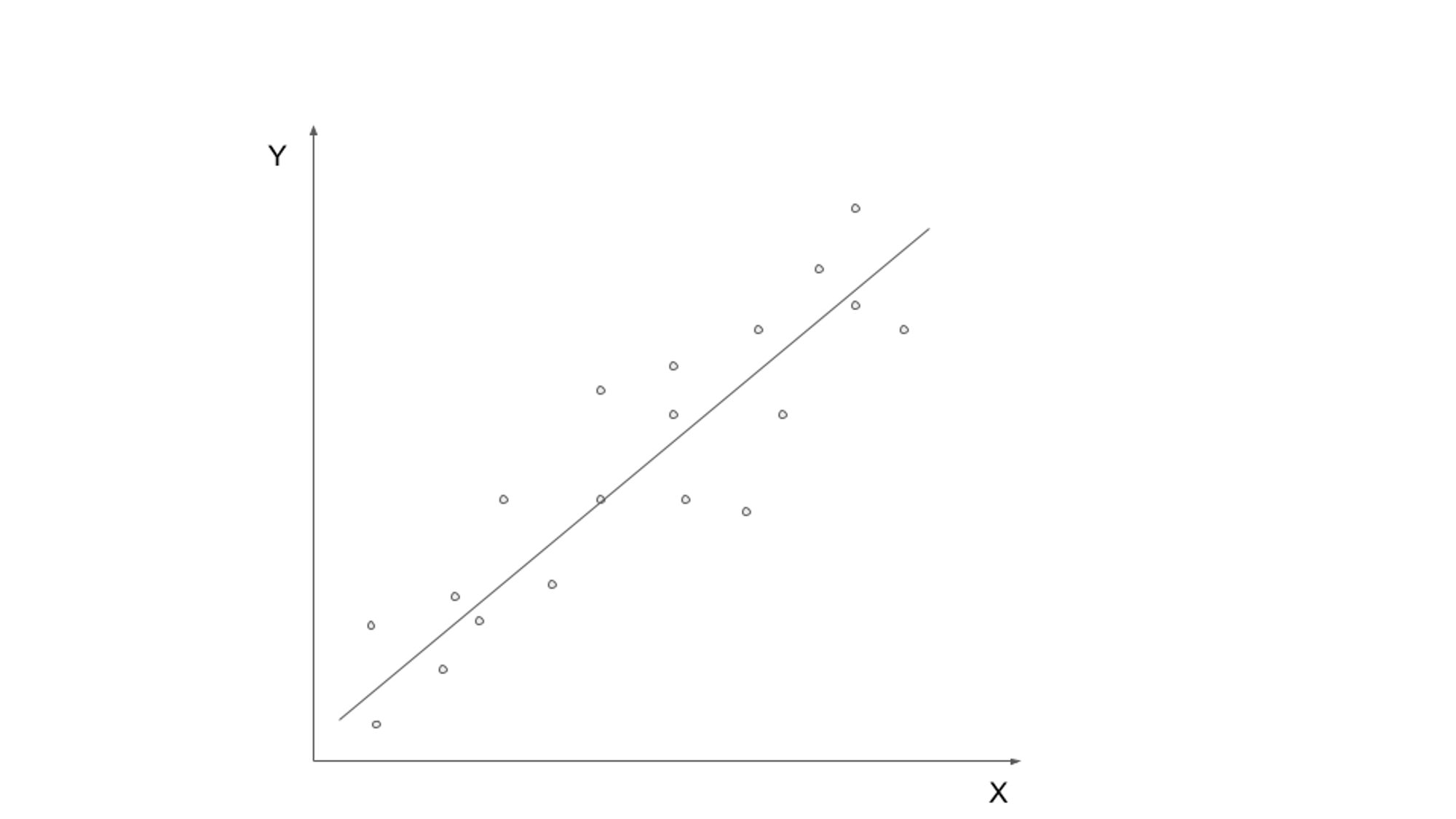
Beim überwachten Lernen wird ein Modell anhand gekennzeichneter Daten trainiert, wobei die Eingabedaten mit der entsprechenden Ausgabe- oder Zielvariablen gepaart werden. Ziel ist es, eine Funktion zu erlernen, die Eingabedaten der richtigen Ausgabe zuordnen kann. Zu den gängigen Algorithmen für überwachtes Lernen gehören lineare Regression, logistische Regression, Entscheidungsbäume und Support-Vektor-Maschinen.
Beispiel für überwachten Lerncode mit Python:
from sklearn.linear_model import LinearRegression model = LinearRegression() model.fit(X_train, y_train) predictions = model.predict(X_test)
In diesem einfachen Codebeispiel trainieren wir das LinearRegression Algorithmus von scikit-learn auf unseren Trainingsdaten und wenden Sie ihn dann an, um Vorhersagen für unsere Testdaten zu erhalten.
Ein realer Anwendungsfall des überwachten Lernens ist die Klassifizierung von E-Mail-Spam. Angesichts des exponentiellen Wachstums der E-Mail-Kommunikation ist die Identifizierung und Filterung von Spam-E-Mails von entscheidender Bedeutung geworden. Durch den Einsatz überwachter Lernalgorithmen ist es möglich, ein Modell zu trainieren, um anhand gekennzeichneter Daten zwischen legitimen E-Mails und Spam zu unterscheiden.
Das überwachte Lernmodell kann anhand eines Datensatzes trainiert werden, der E-Mails enthält, die entweder als „Spam“ oder „kein Spam“ gekennzeichnet sind. Das Modell lernt Muster und Merkmale aus den gekennzeichneten Daten, beispielsweise das Vorhandensein bestimmter Schlüsselwörter, die E-Mail-Struktur oder Informationen zum E-Mail-Absender. Sobald das Modell trainiert ist, kann es verwendet werden, um eingehende E-Mails automatisch als Spam oder Nicht-Spam zu klassifizieren und so unerwünschte Nachrichten effizient zu filtern.
Unbeaufsichtigtes Lernen
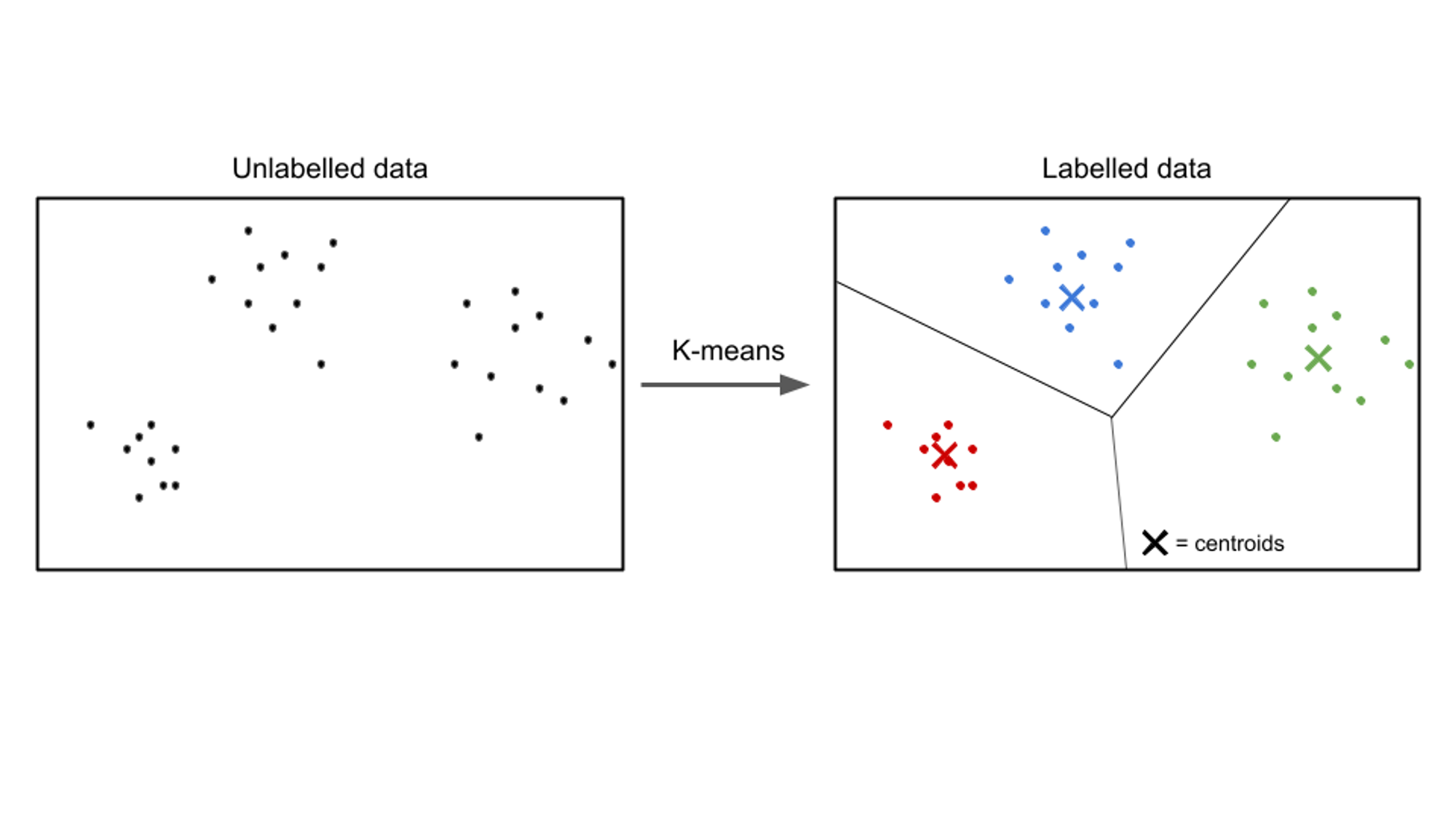
Beim unbeaufsichtigten Lernen sind die Eingabedaten unbeschriftet und das Ziel besteht darin, Muster oder Strukturen innerhalb der Daten zu entdecken. Unüberwachte Lernalgorithmen zielen darauf ab, sinnvolle Darstellungen oder Cluster in den Daten zu finden.
Beispiele für unbeaufsichtigte Lernalgorithmen sind: k-bedeutet Clustering, hierarchisches Clustering und Hauptkomponentenanalyse (PCA).
Beispiel für unbeaufsichtigten Lerncode:
from sklearn.cluster import KMeans model = KMeans(n_clusters=3) model.fit(X) predictions = model.predict(X_new)
In diesem einfachen Codebeispiel trainieren wir das KMeans Algorithmus von scikit-learn, um drei Cluster in unseren Daten zu identifizieren und dann neue Daten in diese Cluster einzupassen.
Ein Beispiel für einen Anwendungsfall des unüberwachten Lernens ist die Kundensegmentierung. In verschiedenen Branchen streben Unternehmen danach, ihren Kundenstamm besser zu verstehen, um ihre Marketingstrategien anzupassen, ihre Angebote zu personalisieren und das Kundenerlebnis zu optimieren. Unüberwachte Lernalgorithmen können eingesetzt werden, um Kunden anhand ihrer gemeinsamen Merkmale und Verhaltensweisen in verschiedene Gruppen einzuteilen.
Sehen Sie sich unseren praxisnahen, praktischen Leitfaden zum Erlernen von Git an, mit Best Practices, branchenweit akzeptierten Standards und einem mitgelieferten Spickzettel. Hören Sie auf, Git-Befehle zu googeln und tatsächlich in Verbindung, um es!
Durch die Anwendung unbeaufsichtigter Lerntechniken wie Clustering können Unternehmen aussagekräftige Muster und Gruppen in ihren Kundendaten aufdecken. Clustering-Algorithmen können beispielsweise Kundengruppen mit ähnlichen Kaufgewohnheiten, demografischen Merkmalen oder Vorlieben identifizieren. Diese Informationen können genutzt werden, um gezielte Marketingkampagnen zu erstellen, Produktempfehlungen zu optimieren und die Kundenzufriedenheit zu verbessern.
Hauptalgorithmusklassen
Überwachte Lernalgorithmen
-
Lineare Modelle: Werden zur Vorhersage kontinuierlicher Variablen basierend auf linearen Beziehungen zwischen Features und der Zielvariablen verwendet.
-
Baumbasierte Modelle: Konstruiert unter Verwendung einer Reihe binärer Entscheidungen, um Vorhersagen oder Klassifizierungen zu treffen.
-
Ensemble-Modelle: Methode, die mehrere Modelle (baumbasiert oder linear) kombiniert, um genauere Vorhersagen zu treffen.
-
Modelle neuronaler Netzwerke: Methoden, die lose auf dem menschlichen Gehirn basieren und bei denen mehrere Funktionen als Knoten eines Netzwerks fungieren.
Unüberwachte Lernalgorithmen
-
Hierarchisches Clustering: Erstellt eine Hierarchie von Clustern durch iteratives Zusammenführen oder Teilen.
-
Nicht-hierarchisches Clustering: Unterteilt Daten basierend auf ihrer Ähnlichkeit in verschiedene Cluster.
-
Dimensionsreduktion: Reduziert die Dimensionalität von Daten und behält gleichzeitig die wichtigsten Informationen bei.
Modellbewertung
Überwachtes Lernen
Um die Leistung überwachter Lernmodelle zu bewerten, werden verschiedene Metriken verwendet, darunter Genauigkeit, Präzision, Rückruf, F1-Score und ROC-AUC. Kreuzvalidierungstechniken wie die k-fache Kreuzvalidierung können dabei helfen, die Generalisierungsleistung des Modells abzuschätzen.
Unbeaufsichtigtes Lernen
Die Bewertung unbeaufsichtigter Lernalgorithmen ist oft eine größere Herausforderung, da es keine Grundwahrheit gibt. Zur Beurteilung der Qualität der Clustering-Ergebnisse können Metriken wie der Silhouetten-Score oder die Trägheit herangezogen werden. Auch Visualisierungstechniken können Einblicke in die Struktur von Clustern liefern.
Tipps und Tricks
Überwachtes Lernen
- Verarbeiten und normalisieren Sie Eingabedaten, um die Modellleistung zu verbessern.
- Behandeln Sie fehlende Werte angemessen, entweder durch Imputation oder Entfernung.
- Feature Engineering kann die Fähigkeit des Modells verbessern, relevante Muster zu erfassen.
Unbeaufsichtigtes Lernen
- Wählen Sie die entsprechende Anzahl von Clustern basierend auf Domänenkenntnissen oder mithilfe von Techniken wie der Ellbogenmethode.
- Berücksichtigen Sie verschiedene Distanzmetriken, um die Ähnlichkeit zwischen Datenpunkten zu messen.
- Regularisieren Sie den Clustering-Prozess, um eine Überanpassung zu vermeiden.
Zusammenfassend lässt sich sagen, dass maschinelles Lernen zahlreiche Aufgaben, Techniken, Algorithmen, Modellbewertungsmethoden und hilfreiche Hinweise umfasst. Durch das Verständnis dieser Aspekte können Praktiker maschinelles Lernen effizient auf reale Probleme anwenden und aus Daten wichtige Erkenntnisse gewinnen. Die angegebenen Codebeispiele veranschaulichen den Einsatz überwachter und unüberwachter Lernalgorithmen und verdeutlichen deren praktische Umsetzung.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- EVM-Finanzen. Einheitliche Schnittstelle für dezentrale Finanzen. Hier zugreifen.
- Quantum Media Group. IR/PR verstärkt. Hier zugreifen.
- PlatoAiStream. Web3-Datenintelligenz. Wissen verstärkt. Hier zugreifen.
- Quelle: https://stackabuse.com/supervised-learning-vs-unsupervised-learning-algorithms/