
Einleitung
Künstliche Intelligenz (KI) hat in verschiedenen Branchen erhebliche Fortschritte gemacht, und das Gesundheitswesen bildet da keine Ausnahme. Einer der vielversprechendsten Bereiche der KI im Gesundheitswesen ist die Verarbeitung natürlicher Sprache (Natural Language Processing, NLP), die das Potenzial hat, die Patientenversorgung zu revolutionieren, indem sie eine effizientere und genauere Datenanalyse und Kommunikation ermöglicht.
NLP hat sich im Gesundheitswesen als Game Changer erwiesen. NLP verändert die Art und Weise, wie Gesundheitsdienstleister ihre Patienten versorgen. Vom Bevölkerungsgesundheitsmanagement bis zur Krankheitserkennung unterstützt NLP medizinisches Fachpersonal dabei, fundierte Entscheidungen zu treffen und bessere Behandlungsergebnisse zu erzielen.
Lernziele
- Den Einsatz von NLP und KI im Gesundheitswesen verstehen und analysieren
- Die Grundlagen des NLP in den Griff bekommen
- Lernen Sie einige häufig verwendete NLP-Bibliotheken im Gesundheitswesen kennen
- Erfahren Sie mehr über die Anwendungsfälle von NLP im Gesundheitswesen
Dieser Artikel wurde als Teil des veröffentlicht Data-Science-Blogathon.
Inhaltsverzeichnis
- Die Motivation für den Einsatz von KI und NLP im Gesundheitswesen
- Was ist die Verarbeitung natürlicher Sprache?
- Verschiedene Techniken, die im NLP verwendet werden
3.1 Regelbasierte Techniken
3.2 Statistische Techniken unter Verwendung von Modellen des maschinellen Lernens
3.3 Lernen übertragen - Verschiedene NLP-Bibliotheken und ihre Frameworks
- Was sind Large Language Models (LLM)?
- NLP im klinischen Text – Die Notwendigkeit eines anderen Ansatzes
- Einige NLP-Bibliotheken werden im Gesundheitswesen verwendet
- Die klinischen Datensätze verstehen
- Was sind verschiedene Arten klinischer Daten?
- Anwendungsfälle und Anwendungen von NLP in der Gesundheitsbranche
- Wie baut man eine NLP-Pipeline mit klinischem Text auf?
11.1 Lösungsdesign
11.2 Schritt-für-Schritt-Code - Zusammenfassung
Die Motivation für den Einsatz von KI und NLP im Gesundheitswesen
Die Motivation zur Nutzung AI und NLP im Gesundheitswesen basiert auf der Verbesserung der Patientenversorgung und der Behandlungsergebnisse bei gleichzeitiger Senkung der Gesundheitskosten. Die Gesundheitsbranche generiert riesige Datenmengen, darunter EMRs, klinische Notizen und gesundheitsbezogene Social-Media-Beiträge, die wertvolle Einblicke in die Gesundheit von Patienten und Behandlungsergebnisse liefern können. Allerdings sind viele dieser Daten unstrukturiert und schwer manuell zu analysieren.
Darüber hinaus steht die Gesundheitsbranche vor mehreren Herausforderungen, wie etwa einer alternden Bevölkerung, steigenden Raten chronischer Krankheiten und einem Mangel an medizinischem Fachpersonal.
Diese Herausforderungen haben zu einem wachsenden Bedarf an einer effizienteren und effektiveren Gesundheitsversorgung geführt.
Durch die Bereitstellung wertvoller Erkenntnisse aus unstrukturierten medizinischen Daten kann NLP dazu beitragen, die Patientenversorgung und Behandlungsergebnisse zu verbessern und medizinisches Fachpersonal dabei zu unterstützen, fundiertere klinische Entscheidungen zu treffen.
Was ist die Verarbeitung natürlicher Sprache?
Natural Language Processing (NLP) ist ein Teilgebiet der Künstlichen Intelligenz (KI), das sich mit der Interaktion zwischen Computern und menschlichen Sprachen befasst. Es nutzt Computertechniken, um menschliche Sprache zu analysieren, zu verstehen und zu generieren. NLP wird in vielen Anwendungen eingesetzt, darunter Spracherkennung, maschinelle Übersetzung, Stimmungsanalyse und Textzusammenfassung.
Wir werden nun die verschiedenen NLP-Techniken, Bibliotheken und Frameworks erkunden.
Verschiedene Techniken, die im NLP verwendet werden
Es gibt zwei häufig verwendete Techniken in der NLP-Branche.
1. Regelbasierte Techniken: Verlassen Sie sich auf vordefinierte Grammatikregeln und Wörterbücher
2. Statistische Techniken: Verwenden Sie Algorithmen für maschinelles Lernen, um Sprache zu analysieren und zu verstehen
3. Verwendung eines großen Sprachmodells Lernen übertragen
Hier ist eine Standard-NLP-Pipeline mit verschiedenen NLP-Aufgaben
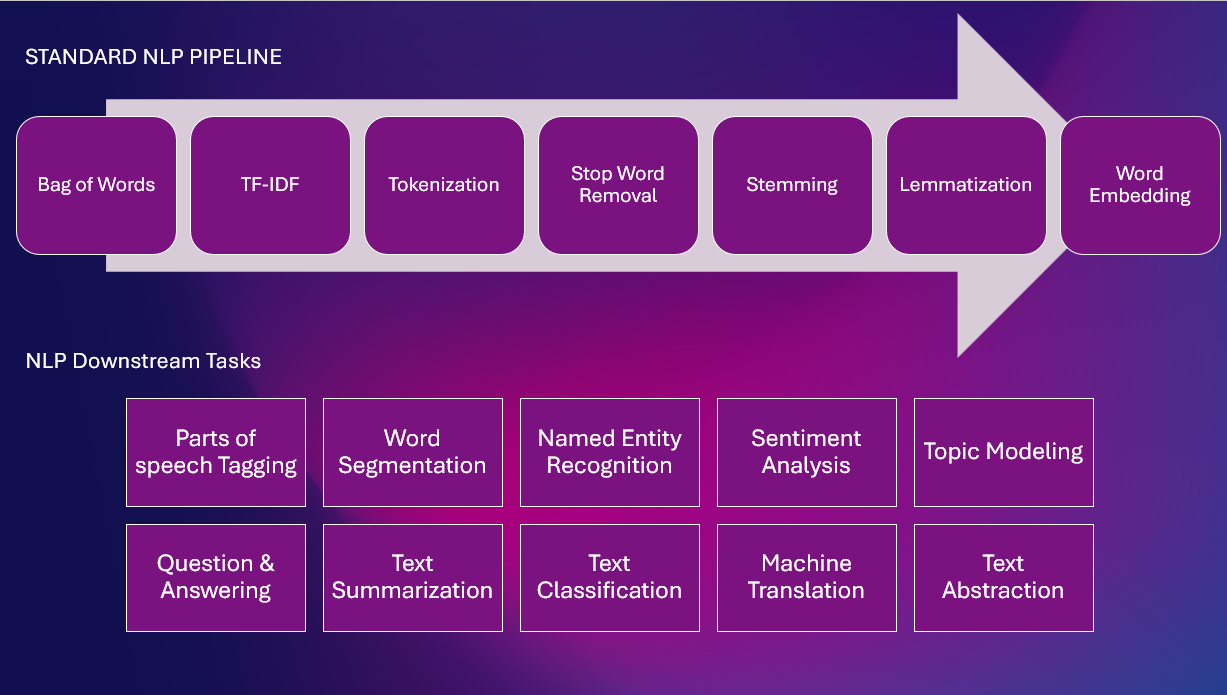
Regelbasierte Techniken
Bei diesen Techniken wird eine Reihe handgefertigter Regeln oder Muster erstellt, um aussagekräftige Informationen aus Texten zu extrahieren. Regelbasierte Systeme funktionieren in der Regel dadurch, dass sie bestimmte Muster definieren, die mit den Zielinformationen übereinstimmen, z. B. benannte Entitäten oder bestimmte Schlüsselwörter, und diese Informationen dann basierend auf diesen Mustern extrahieren. Regelbasierte Systeme sind schnell, zuverlässig und unkompliziert, sind jedoch durch die Qualität und Anzahl der definierten Regeln begrenzt und können schwierig zu warten und zu aktualisieren sein.
Beispielsweise könnte ein regelbasiertes System zur Erkennung benannter Entitäten entworfen werden, um Eigennamen im Text zu identifizieren und sie in vordefinierte Entitätstypen wie eine Person, einen Ort, eine Organisation, eine Krankheit, Medikamente usw. zu kategorisieren. Das System würde eine Reihe verwenden von Regeln zur Identifizierung von Mustern im Text, die den Kriterien für jeden Entitätstyp entsprechen, z. B. Groß- und Kleinschreibung für Personennamen oder bestimmte Schlüsselwörter für Organisationen.
Statistische Techniken unter Verwendung von Modellen des maschinellen Lernens
Diese Techniken nutzen statistische Algorithmen, um Muster in den Daten zu lernen und auf der Grundlage dieser Muster Vorhersagen zu treffen. Modelle für maschinelles Lernen können auf großen Mengen annotierter Daten trainiert werden, wodurch sie flexibler und skalierbarer sind als regelbasierte Systeme. Im NLP werden verschiedene Arten von Modellen für maschinelles Lernen verwendet, darunter Entscheidungsbäume, zufällige Wälder, Support-Vektor-Maschinen und Neuronale Netze.
Beispielsweise könnte ein maschinelles Lernmodell für die Stimmungsanalyse auf einem großen Korpus annotierter Texte trainiert werden, wobei jeder Text als positiv, negativ oder neutral gekennzeichnet wird. Das Modell würde die statistischen Muster in den Daten lernen, die zwischen positivem und negativem Text unterscheiden, und diese Muster dann verwenden, um Vorhersagen über neuen, unsichtbaren Text zu treffen. Der Vorteil dieses Ansatzes besteht darin, dass das Modell lernen kann, Stimmungsmuster zu identifizieren, die nicht explizit in den Regeln definiert sind.
Lernen übertragen
Bei diesen Techniken handelt es sich um einen hybriden Ansatz, der die Stärken regelbasierter und maschineller Lernmodelle kombiniert. Beim Transferlernen wird ein vorab trainiertes maschinelles Lernmodell, beispielsweise ein auf einem großen Textkorpus trainiertes Sprachmodell, als Ausgangspunkt für die Feinabstimmung einer bestimmten Aufgabe oder Domäne verwendet. Dieser Ansatz nutzt das allgemeine Wissen, das aus dem vorab trainierten Modell gelernt wurde, reduziert die Menge der für das Training erforderlichen gekennzeichneten Daten und ermöglicht schnellere und genauere Vorhersagen für eine bestimmte Aufgabe.
Beispielsweise könnte ein Transfer-Learning-Ansatz zur Erkennung benannter Entitäten ein vorab trainiertes Sprachmodell anhand eines kleineren Korpus annotierter medizinischer Texte verfeinern. Das Modell würde mit dem allgemeinen Wissen beginnen, das aus dem vorab trainierten Modell gelernt wurde, und dann seine Gewichte anpassen, um besser zu den Mustern des medizinischen Textes zu passen. Dieser Ansatz würde die Menge der für das Training erforderlichen gekennzeichneten Daten reduzieren und zu einem genaueren Modell für die Erkennung benannter Entitäten im medizinischen Bereich führen.
Verschiedene NLP-Bibliotheken und ihre Frameworks
Verschiedene Bibliotheken stellen ein breites Spektrum an NLP-Funktionalitäten bereit. Wie zum Beispiel :

Bibliotheken und Frameworks für die Verarbeitung natürlicher Sprache (Natural Language Processing) sind Softwaretools, die bei der Entwicklung und Bereitstellung von NLP-Anwendungen helfen. Es stehen mehrere NLP-Bibliotheken und Frameworks zur Verfügung, jede mit Stärken, Schwächen und Schwerpunktbereichen.
Diese Tools unterscheiden sich hinsichtlich der Komplexität der von ihnen unterstützten Algorithmen, der Größe der Modelle, die sie verarbeiten können, der Benutzerfreundlichkeit und dem Grad der Anpassung, die sie ermöglichen.
Was sind Large Language Models (LLM)?
Große Sprachmodelle werden auf riesigen Datenmengen trainiert. Kann menschenähnlichen Text generieren und eine Vielzahl von NLP-Aufgaben mit hoher Genauigkeit ausführen.
Hier sind einige Beispiele großer Sprachmodelle und jeweils eine kurze Beschreibung:
GPT-3 (Generativer vortrainierter Transformator 3): GPT-3 wurde von OpenAI entwickelt und ist ein großes transformatorbasiertes Sprachmodell, das Deep-Learning-Algorithmen verwendet, um menschenähnlichen Text zu generieren. Es wurde auf einem riesigen Korpus von Textdaten trainiert, was es ihm ermöglicht, auf der Grundlage einer Eingabeaufforderung kohärente und kontextbezogene Textantworten zu generieren.
BERT (Bidirektionale Encoder-Darstellungen von Transformatoren): BERT wurde von Google entwickelt und ist ein transformatorbasiertes Sprachmodell, das anhand einer großen Menge an Textdaten vorab trainiert wurde. Es ist darauf ausgelegt, bei einem breiten Spektrum von NLP-Aufgaben gute Ergebnisse zu erzielen, wie z. B. der Erkennung benannter Entitäten, der Beantwortung von Fragen und der Textklassifizierung, indem der Kontext und die Beziehungen zwischen Wörtern in einem Satz kodiert werden.
Roberta (Robust optimierter BERT-Ansatz): RoBERTa wurde von Facebook AI entwickelt und ist eine Variante von BERT, die für NLP-Aufgaben fein abgestimmt und optimiert wurde. Es wurde auf einem größeren Korpus von Textdaten trainiert und verwendet eine andere Trainingsstrategie als BERT, was zu einer verbesserten Leistung bei NLP-Benchmarks führt.
ELMo (Einbettungen aus Sprachmodellen): ELMo wurde vom Allen Institute for AI entwickelt und ist ein tief kontextualisiertes Wortdarstellungsmodell, das ein bidirektionales LSTM-Netzwerk (Long Short-Term Memory) verwendet, um Sprachdarstellungen aus einem großen Korpus von Textdaten zu lernen. ELMo kann für bestimmte NLP-Aufgaben optimiert oder als Feature-Extraktor für andere Modelle des maschinellen Lernens verwendet werden.
ULMFiT (Universal Language Model Fine-Tuning): ULMFiT wurde von FastAI entwickelt und ist eine Transfer-Lernmethode, die ein vorab trainiertes Sprachmodell anhand einer kleinen Menge aufgabenspezifischer annotierter Daten auf eine bestimmte NLP-Aufgabe abstimmt. ULMFiT hat bei einer Vielzahl von NLP-Benchmarks Spitzenleistungen erzielt und gilt als führendes Beispiel für Transferlernen im NLP.
NLP im klinischen Text: Die Notwendigkeit eines anderen Ansatzes
Klinischer Text ist oft unstrukturiert und enthält viel medizinischen Fachjargon und Akronyme, was es für traditionelle NLP-Modelle schwierig macht, ihn zu verstehen und zu verarbeiten. Darüber hinaus enthalten klinische Texte oft wichtige Informationen wie Krankheiten, Medikamente, Patienteninformationen, Diagnosen und Behandlungspläne, die spezielle NLP-Modelle erfordern, die diese medizinischen Informationen genau extrahieren und verstehen können.
Ein weiterer Grund dafür, dass für klinische Texte unterschiedliche NLP-Modelle erforderlich sind, besteht darin, dass sie eine große Menge an Daten enthalten, die über verschiedene Quellen verteilt sind, wie z. B. EHRs, klinische Notizen und radiologische Berichte, die integriert werden müssen. Dafür sind Modelle erforderlich, die den Text verarbeiten und verstehen, die Daten über verschiedene Quellen hinweg verknüpfen und integrieren und klinisch akzeptable Beziehungen herstellen können.
Schließlich enthalten klinische Texte oft sensible Patienteninformationen und müssen durch strenge Vorschriften wie HIPAA geschützt werden. NLP-Modelle, die zur Verarbeitung klinischer Texte verwendet werden, müssen in der Lage sein, sensible Patienteninformationen zu identifizieren und zu schützen und gleichzeitig nützliche Erkenntnisse zu liefern.
Einige NLP-Bibliotheken werden im Gesundheitswesen verwendet
Die Textdaten in der Medizin erfordern ein spezielles NLP-System (Natural Language Processing), das in der Lage ist, medizinische Informationen aus verschiedenen Quellen wie klinischen Texten und anderen medizinischen Dokumenten zu extrahieren.
Hier ist eine Liste von NLP-Bibliotheken und -Modellen speziell für den medizinischen Bereich:
spaCy: Es handelt sich um eine Open-Source-NLP-Bibliothek, die sofort einsatzbereite Modelle für verschiedene Bereiche, einschließlich des medizinischen Bereichs, bereitstellt.
ScispaCy: Eine spezielle Version von spaCy, die speziell auf wissenschaftliche und biomedizinische Texte ausgerichtet ist und sich daher ideal für die Verarbeitung medizinischer Texte eignet.
BioBERT: Ein vorab trainiertes transformatorbasiertes Modell, das speziell für den biomedizinischen Bereich entwickelt wurde. Es ist mit Wiki + Büchern + PubMed + PMC vorab trainiert.
ClinicalBERT: Ein weiteres vorab trainiertes Modell zur Verarbeitung klinischer Notizen und Entlassungszusammenfassungen aus der MIMIC-III-Datenbank.
Med7: Ein transformatorbasiertes Modell, das auf elektronischen Gesundheitsakten (EHR) trainiert wurde, um sieben wichtige klinische Konzepte zu extrahieren, darunter Diagnose, Medikation und Labortests.
DisMod-ML: Ein probabilistisches Modellierungsframework für die Krankheitsmodellierung, das NLP-Techniken zur Verarbeitung medizinischer Texte verwendet.
MEDIZIN: Ein regelbasiertes NLP-System zum Extrahieren medizinischer Informationen aus Text.
Dies sind einige der beliebten NLP-Bibliotheken und -Modelle, die speziell für den medizinischen Bereich entwickelt wurden. Sie bieten eine Reihe von Funktionen, von vorab trainierten Modellen bis hin zu regelbasierten Systemen, und können Gesundheitsorganisationen dabei helfen, medizinische Texte effektiv zu verarbeiten.
In unserem NER-Modell werden wir spaCy und Scispacy verwenden. Diese Bibliotheken lassen sich vergleichsweise einfach auf Google Colab oder einer lokalen Infrastruktur ausführen.
Die ressourcenintensiven großen Sprachmodelle BioBERT und ClinicalBERT benötigen GPUs und eine höhere Infrastruktur.
Die klinischen Datensätze verstehen
Medizinische Textdaten können aus verschiedenen Quellen bezogen werden, beispielsweise aus elektronischen Gesundheitsakten (EHRs), medizinischen Fachzeitschriften, klinischen Notizen, medizinischen Websites und Datenbanken. Einige dieser Quellen stellen öffentlich verfügbare Datensätze bereit, die zum Trainieren von NLP-Modellen verwendet werden können, während andere möglicherweise eine Genehmigung und ethische Überlegungen erfordern, bevor auf die Daten zugegriffen werden kann. Zu den Quellen medizinischer Textdaten gehören:
1. Open-Source-Medizinkorpora wie die MIMIC-III-Datenbank ist eine große, offen zugängliche Datenbank für elektronische Gesundheitsakten (EHRs) von Patienten, die zwischen 2001 und 2012 am Beth Israel Deaconess Medical Center behandelt wurden. Die Datenbank enthält Informationen wie Patientendaten, Vitalfunktionen, Labortests, Medikamente, Verfahren usw Notizen von medizinischem Fachpersonal wie Krankenschwestern und Ärzten. Darüber hinaus enthält die Datenbank Informationen zu den Intensivaufenthalten der Patienten, einschließlich der Art der Intensivstation, der Aufenthaltsdauer und den Ergebnissen. Die Daten in MIMIC-III sind anonymisiert und können für Forschungszwecke verwendet werden, um die Entwicklung von Vorhersagemodellen und klinischen Entscheidungsunterstützungssystemen zu unterstützen.
2. Die National Library of Medicine ClinicalTrials.gov Auf der Website finden Sie Daten zu klinischen Studien und zur Krankheitsüberwachung.
3. National Library of Medicine der National Institutes of Health, National Centers for Biotechnology Information (NCBI) und der Weltgesundheitsorganisation (WHO)
4. Gesundheitseinrichtungen und -organisationen wie Krankenhäuser, Kliniken und Pharmaunternehmen generieren große Mengen medizinischer Textdaten durch elektronische Gesundheitsakten, klinische Notizen, medizinische Transkriptionen und medizinische Berichte.
5. Medizinische Forschungszeitschriften und Datenbanken wie PubMed und CINAHL enthalten große Mengen veröffentlichter medizinischer Forschungsartikel und Abstracts.
6. Social-Media-Plattformen wie Twitter können Echtzeit-Einblicke in Patientenperspektiven, Arzneimittelbewertungen und Erfahrungen bieten.
Um NLP-Modelle mithilfe medizinischer Textdaten zu trainieren, ist es wichtig, die Qualität und Relevanz der Daten zu berücksichtigen und sicherzustellen, dass sie ordnungsgemäß vorverarbeitet und formatiert werden. Darüber hinaus ist es wichtig, bei der Arbeit mit sensiblen medizinischen Informationen ethische und rechtliche Überlegungen einzuhalten.
Was sind verschiedene Arten klinischer Daten?
Im Gesundheitswesen werden häufig verschiedene Arten klinischer Daten verwendet:

Klinische Daten beziehen sich auf Informationen über die Gesundheitsversorgung von Einzelpersonen, einschließlich Krankengeschichte, Diagnosen, Behandlungen, Laborergebnissen, Bildgebungsstudien und anderen relevanten Gesundheitsinformationen des Patienten.
EHR/EMR-Daten sind mit demografischen Daten verknüpft (dazu gehören personenbezogene Daten wie Alter, Geschlecht, ethnische Zugehörigkeit und Kontaktinformationen). Patientengenerierte Daten (Diese Art von Daten werden von Patienten selbst generiert, einschließlich Informationen, die durch patientenberichtete Ergebnismessungen und Patientendaten gesammelt wurden -generierte Gesundheitsdaten.)
Weitere Datensätze sind:
Genomische Daten: Dieser Typ bezieht sich auf die genetischen Informationen einer Person, einschließlich DNA-Sequenzen und Markern.
Tragbare Gerätedaten: Zu diesen Daten gehören Informationen, die von tragbaren Geräten wie Fitness-Trackern und Herzmonitoren gesammelt werden.
Jede Art klinischer Daten spielt eine einzigartige Rolle bei der Bereitstellung eines umfassenden Überblicks über die Gesundheit eines Patienten und wird von Gesundheitsdienstleistern und Forschern auf unterschiedliche Weise verwendet, um die Patientenversorgung zu verbessern und Behandlungsentscheidungen zu treffen.
Anwendungsfälle und Anwendungen von NLP in der Gesundheitsbranche
Die Verarbeitung natürlicher Sprache (Natural Language Processing, NLP) ist in der Gesundheitsbranche weit verbreitet und hat mehrere Anwendungsfälle. Zu den bekanntesten gehören:
Bevölkerung Gesundheit: NLP kann verwendet werden, um große Mengen unstrukturierter medizinischer Daten wie Krankenakten, Umfragen und Schadensdaten zu verarbeiten, um Muster, Korrelationen und Erkenntnisse zu identifizieren. Dies hilft bei der Überwachung der Bevölkerungsgesundheit und der Früherkennung von Krankheiten.
Patientenversorgung: Mithilfe von NLP können elektronische Gesundheitsakten (EHRs) von Patienten verarbeitet werden, um wichtige Informationen wie Diagnose, Medikamente und Symptome zu extrahieren. Diese Informationen können genutzt werden, um die Patientenversorgung zu verbessern und eine personalisierte Behandlung anzubieten.
Krankheitserkennung: NLP kann zur Verarbeitung großer Textdatenmengen wie wissenschaftlicher Artikel, Nachrichtenartikel und Social-Media-Beiträge verwendet werden, um Ausbrüche von Infektionskrankheiten zu erkennen.
Klinisches Entscheidungsunterstützungssystem (CDSS): Mit NLP können die elektronischen Gesundheitsakten von Patienten analysiert werden, um Gesundheitsdienstleistern Echtzeit-Entscheidungsunterstützung zu bieten. Dies trägt dazu bei, die bestmöglichen Behandlungsmöglichkeiten bereitzustellen und die Gesamtqualität der Pflege zu verbessern.
Klinische Studie: NLP kann Daten aus klinischen Studien verarbeiten, um Zusammenhänge und potenzielle neue Behandlungen zu identifizieren.
Nebenwirkungen von Arzneimitteln: Mit NLP können große Mengen an Arzneimittelsicherheitsdaten verarbeitet werden, um unerwünschte Ereignisse und Arzneimittelwechselwirkungen zu identifizieren.
Präzisionsgesundheit: Mit NLP können Genomdaten und Krankenakten verarbeitet werden, um personalisierte Behandlungsmöglichkeiten für einzelne Patienten zu ermitteln.
Effizienzsteigerung des medizinischen Fachpersonals: NLP kann Routineaufgaben wie medizinische Kodierung, Dateneingabe und Schadensbearbeitung automatisieren, sodass sich medizinische Fachkräfte auf die Bereitstellung einer besseren Patientenversorgung konzentrieren können.
Dies sind nur einige Beispiele dafür, wie NLP die Gesundheitsbranche revolutioniert. Da die NLP-Technologie weiter voranschreitet, können wir davon ausgehen, dass NLP in Zukunft im Gesundheitswesen noch innovativer eingesetzt werden wird.
Wie baut man eine NLP-Pipeline mit klinischem Text auf?
Wir werden eine schrittweise Spacy-Pipeline unter Verwendung des SciSpacy NER-Modells für klinischen Text entwickeln.
Ziel: Dieses Projekt zielt darauf ab, eine NLP-Pipeline zu erstellen, die SciSpacy nutzt, um eine benutzerdefinierte Erkennung benannter Entitäten für klinische Texte durchzuführen.
Ergebnis: Das Ergebnis wird darin bestehen, Informationen zu Krankheiten, Arzneimitteln und Arzneimitteldosen aus klinischen Texten zu extrahieren, die dann in verschiedenen nachgelagerten NLP-Anwendungen verwendet werden können.
Lösungsdesign:
Hier ist die High-Level-Lösung zum Extrahieren von Entitätsinformationen aus Clinical Text. Die NER-Extraktion ist eine wichtige NLP-Aufgabe, die in den meisten NLP-Pipelines verwendet wird.
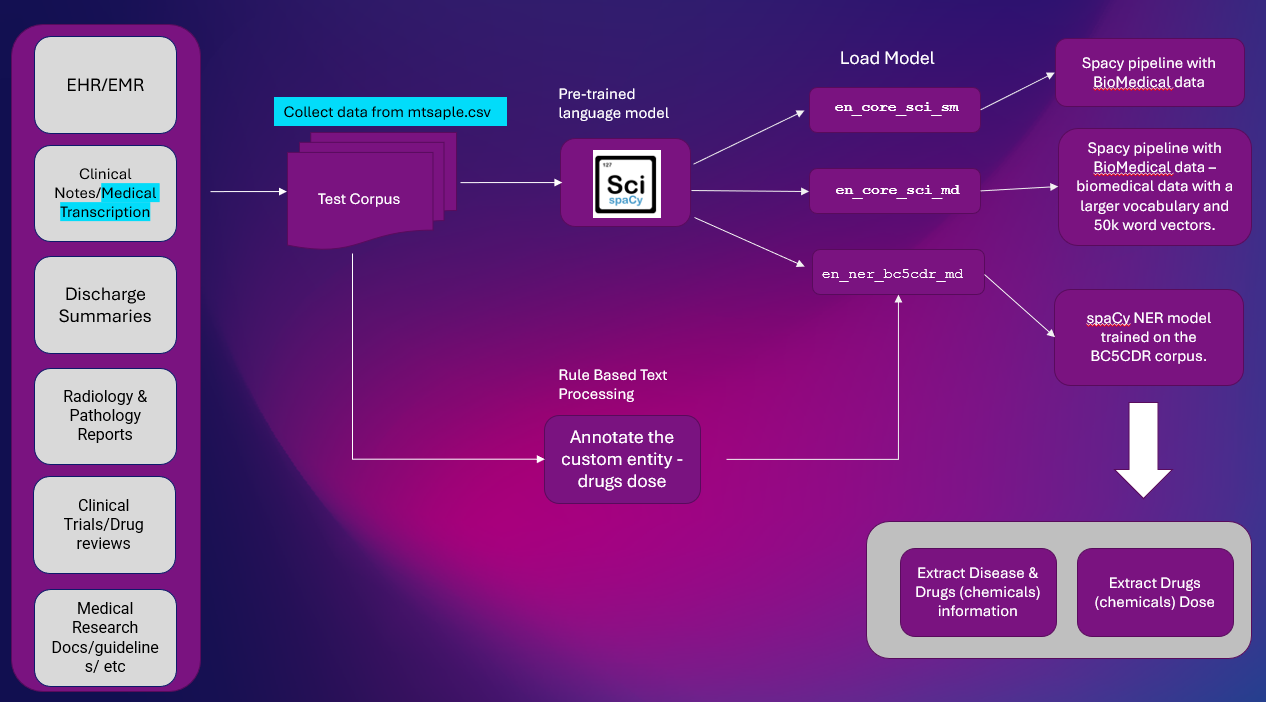
Plattform: Google Colab
NLP-Bibliotheken: spaCy & SciSpacy
Datensatz: mtsample.csv (verschrottete Daten von mtsample).
Wir haben benutzt ScispaCy vorab trainiertes NER-Modell en_ner_bc5cdr_md-0.5.1 um Krankheiten und Medikamente zu extrahieren. Drogen werden als Chemikalien gewonnen.
en_ner_bc5cdr_md-0.5.1 ist ein spaCy-Modell für die Erkennung benannter Entitäten (NER) im biomedizinischen Bereich.
„bc5cdr“ bezieht sich auf die BC5CDR Corpus, ein biomedizinischer Textkorpus, der zum Trainieren des Modells verwendet wird. Das „md“ im Namen bezieht sich auf den biomedizinischen Bereich. Das „0.5.1“ im Namen bezieht sich auf die Version des Modells.
Wir werden den Beispieltext „Transkription“ aus mtsample.csv verwenden und ihn mithilfe eines regelbasierten Musters annotieren, um Medikamentendosen zu extrahieren.
Schritt-für-Schritt-Code:
Installieren Sie Spacy- und Scispacy-Pakete. spaCy-Modelle sind für die Ausführung spezifischer NLP-Aufgaben konzipiert, wie z. B. Tokenisierung, Wortartkennzeichnung und Erkennung benannter Entitäten.
!pip install -U spacy !pip install scispacy
Installieren Sie Scispacy-Basismodelle und NER-Modelle
Das Modell en_ner_bc5cdr_md-0.5.1 ist speziell darauf ausgelegt, benannte Entitäten in biomedizinischen Texten wie Krankheiten, Gene und Medikamente als Chemikalien zu erkennen.
Dieses Modell kann für NLP-Aufgaben im biomedizinischen Bereich nützlich sein, z. B. Informationsextraktion, Textklassifizierung und Beantwortung von Fragen.
!pip install https://s3-us-west-2.amazonaws.com/ai2-s2-scispacy/releases/v0.5.1/en_core_sci_sm-0.5.1.tar.gz !pip install https://s3-us-west-2.amazonaws.com/ai2-s2-scispacy/releases/v0.5.1/en_core_sci_md-0.5.1.tar.gz !pip install https://s3-us-west-2.amazonaws.com/ai2-s2-scispacy/releases/v0.5.1/en_ner_bc5cdr_md-0.5.1.tar.gz
Installieren Sie andere Pakete
pip install render
Pakete importieren
import scispacy import spacy #Core models import en_core_sci_sm import en_core_sci_md
#NER-spezifische Modelle importieren en_ner_bc5cdr_md #Tools zum Extrahieren und Anzeigen von Daten aus Spacy Import Displacy Import Pandas als PD
Python-Code:
Testen Sie die Modelle mit Beispieldaten
# Wählen Sie die zu verwendende spezifische Transkription aus (Zeile 3, Spalte „Transkription“) und testen Sie das Scispacy-NER-Modell text = mtsample_df.loc[10, „Transkription“]

Laden Sie das spezifische Modell: en_core_sci_sm und leiten Sie den Text weiter
nlp_sm = en_core_sci_sm.load() doc = nlp_sm(text)
#Ergebnis anzeigen
Entitätsextraktion displacy_image = displacy.render(doc, jupyter=True,style='ent')

Beachten Sie, dass die Entität hier markiert ist. Hauptsächlich medizinische Begriffe. Allerdings handelt es sich hierbei um generische Einheiten.
Laden Sie nun das spezifische Modell: en_core_sci_md und leiten Sie den Text weiter
nlp_md = en_core_sci_md.load() doc = nlp_md(text)
#Zeigen Sie die resultierende Entitätsextraktion an
displacy_image = displacy.render(doc, jupyter=True,style='ent')

Diesmal werden die Zahlen auch von en_core_sci_md als Entitäten markiert.
Laden Sie nun ein bestimmtes Modell: Importieren Sie en_ner_bc5cdr_md und leiten Sie den Text weiter
nlp_bc = en_ner_bc5cdr_md.load() doc = nlp_bc(text) #Anzeige der resultierenden Entitätsextraktion displacy_image = displacy.render(doc, jupyter=True,style='ent')

Jetzt werden zwei medizinische Einheiten getaggt: Krankheit und Chemikalie (Arzneimittel).
Zeigen Sie die Entität an
print("TEXT", "START", "END", "ENTITY TYPE") für ent in doc.ents: print(ent.text, ent.start_char, ent.end_char, ent.label_)
TEXT START ENDE ENTITÄTSTYP
Krankhafte Fettleibigkeit 26 40 KRANKHEIT
Krankhafte Fettleibigkeit 70 84 KRANKHEIT
Gewichtsverlust 400 411 KRANKHEIT
Marcaine 1256 1264 CHEMISCH
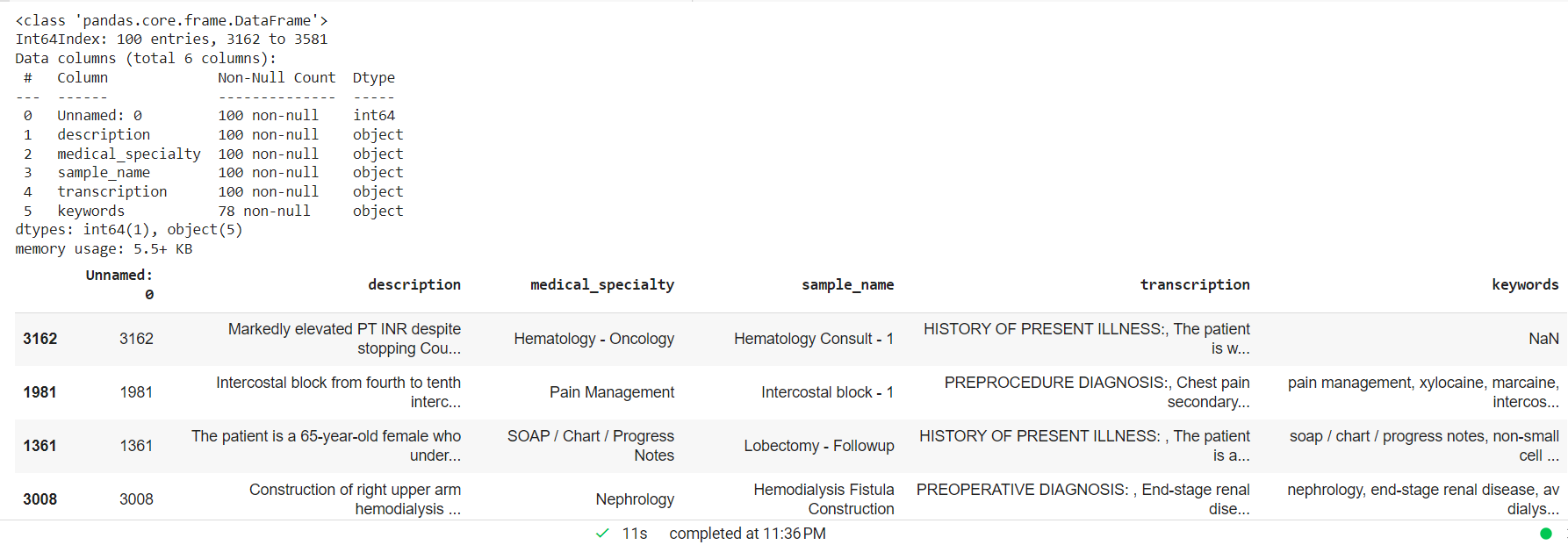
Verarbeiten Sie den klinischen Text, indem Sie NAN-Werte entfernen und eine zufällige kleinere Stichprobe für das benutzerdefinierte Entitätsmodell erstellen.
mtsample_df.dropna(subset=['transcription'], inplace=True) mtsample_df_subset = mtsample_df.sample(n=100, replace=False, random_state=42) mtsample_df_subset.info() mtsample_df_subset.head()
spaCy Matcher – Der regelbasierte Abgleich ähnelt der Verwendung regulärer Ausdrücke, spaCy bietet jedoch zusätzliche Funktionen. Durch die Verwendung der Token und Beziehungen innerhalb eines Dokuments können Sie mithilfe von NER-Modellen Muster identifizieren, die Entitäten enthalten. Ziel ist es, Arzneimittelnamen und deren Dosierungen aus dem Text zu ermitteln, was durch den Vergleich mit Standards und Richtlinien dabei helfen könnte, Medikationsfehler zu erkennen.
Ziel ist es, Arzneimittelnamen und deren Dosierungen aus dem Text zu ermitteln, was durch den Vergleich mit Standards und Richtlinien dabei helfen könnte, Medikationsfehler zu erkennen.
aus spacy.matcher Matcher importieren
Muster = [{'ENT_TYPE':'CHEMICAL'}, {'LIKE_NUM': True}, {'IS_ASCII': True}] matcher = Matcher(nlp_bc.vocab) matcher.add("DRUG_DOSE", [Muster])
für die Transkription in mtsample_df_subset['transcription']: doc = nlp_bc(transcription) matches = matcher(doc) für match_id, Start, Ende in Übereinstimmungen: string_id = nlp_bc.vocab.strings[match_id] # String-Darstellung abrufen span = doc[start :end] # die übereinstimmende Spanne zum Hinzufügen von Medikamentendosen print(span.text, start, end, string_id,) #Krankheit und Medikamente für ent in doc.ents hinzufügen: print(ent.text, ent.start_char, ent.end_char, ent .Etikett_)
In der Ausgabe werden die aus dem klinischen Textbeispiel extrahierten Entitäten angezeigt.
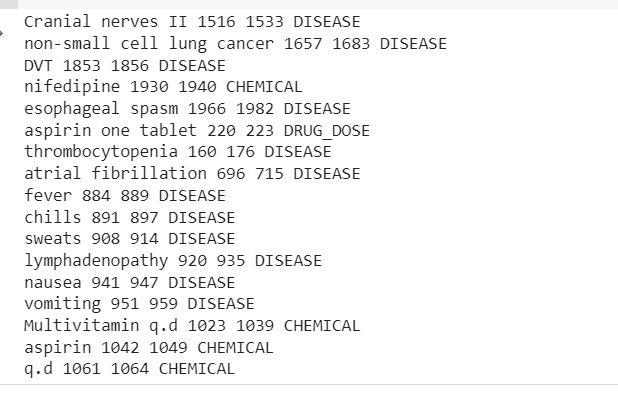
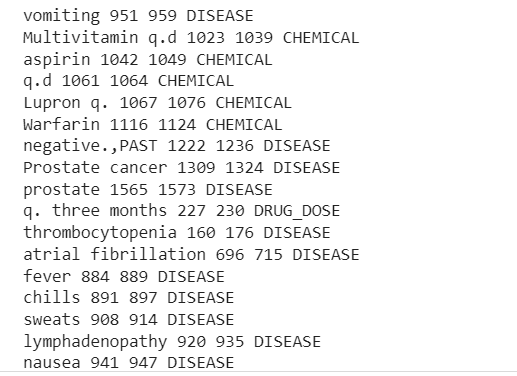
Jetzt können wir sehen, wie die Pipeline extrahiert wird Krankheiten, Medikamente (Chemikalien) und Medikamentendosen Informationen aus dem Kliniktext.
Es liegt eine gewisse Fehlklassifizierung vor, aber wir können die Leistung des Modells mithilfe von mehr Daten steigern.
Wir können diese medizinischen Einheiten nun für verschiedene Aufgaben wie Krankheitserkennung, prädiktive Analyse, klinische Entscheidungsunterstützungssysteme, medizinische Textklassifizierung, Zusammenfassung, Beantwortung von Fragen und vieles mehr verwenden.
Zusammenfassung
1. In diesem Artikel haben wir einige der wichtigsten Funktionen von NLP im Gesundheitswesen untersucht, die zum Verständnis der komplexen Textdaten im Gesundheitswesen beitragen werden.
Wir haben auch scispaCy und spaCy implementiert und mithilfe eines vorab trainierten NER-Modells und eines regelbasierten Matchers ein einfaches benutzerdefiniertes NER-Modell erstellt. Während wir nur ein NER-Modell behandelt haben, sind zahlreiche andere verfügbar und es gibt eine Vielzahl zusätzlicher Funktionen zu entdecken.
2. Innerhalb des ScispaCy-Frameworks gibt es zahlreiche zusätzliche Techniken zu erkunden, darunter Methoden zum Erkennen von Abkürzungen, zum Durchführen von Abhängigkeitsanalysen und zum Identifizieren einzelner Sätze.
3. Zu den neuesten Trends im NLP für das Gesundheitswesen gehören die Entwicklung domänenspezifischer Modelle wie BioBERT und ClinicalBert sowie die Verwendung großer Sprachmodelle wie GPT-3. Diese Modelle bieten ein hohes Maß an Genauigkeit und Effizienz, ihre Verwendung wirft jedoch auch Bedenken hinsichtlich Voreingenommenheit, Datenschutz und Kontrolle über Daten auf.
ChatGPT (ein fortschrittliches Konversations-KI-Modell, das von OpenAI entwickelt wurde) hat bereits große Auswirkungen auf die NLP-Welt. Das Modell wird auf einer riesigen Menge an Textdaten aus dem Internet trainiert und ist in der Lage, auf der Grundlage der empfangenen Eingaben menschenähnliche Textantworten zu generieren. Es kann für verschiedene Aufgaben wie die Beantwortung von Fragen, Zusammenfassungen, Übersetzungen und mehr verwendet werden. Das Modell ist außerdem auf bestimmte Anwendungsfälle abgestimmt, etwa das Generieren von Code oder das Schreiben von Artikeln, um seine Leistung in diesen spezifischen Bereichen zu verbessern.
5. Trotz seiner zahlreichen Vorteile ist NLP im Gesundheitswesen jedoch nicht ohne Herausforderungen. Die Gewährleistung der Genauigkeit und Fairness von NLP-Modellen und die Überwindung von Datenschutzbedenken sind einige der Herausforderungen, die angegangen werden müssen, um das Potenzial von NLP im Gesundheitswesen voll auszuschöpfen.
6. Aufgrund seiner vielen Vorteile ist es für medizinische Fachkräfte von entscheidender Bedeutung, NLP zu nutzen und in ihre Arbeitsabläufe zu integrieren. Obwohl viele Herausforderungen zu bewältigen sind, ist NLP im Gesundheitswesen sicherlich ein Trend, den man beobachten und in den man investieren sollte.
Die in diesem Artikel gezeigten Medien sind nicht Eigentum von Analytics Vidhya und werden nach Ermessen des Autors verwendet.
Verbunden
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- Platoblockkette. Web3-Metaverse-Intelligenz. Wissen verstärkt. Hier zugreifen.
- Quelle: https://www.analyticsvidhya.com/blog/2023/02/extracting-medical-information-from-clinical-text-with-nlp/