
Bild vom Herausgeber
Wir haben gesehen, wie jede Woche große Sprachmodelle (LLMs) ausspuckten und immer mehr Chatbots für uns zur Verfügung standen. Es kann jedoch schwierig sein, herauszufinden, welches das Beste ist, welche Fortschritte es gibt und welches am nützlichsten ist.
Umarmendes Gesicht verfügt über ein Open LLM Leaderboard, das LLMs bei ihrer Veröffentlichung verfolgt, bewertet und einordnet. Sie verwenden ein einzigartiges Framework, mit dem generative Sprachmodelle für verschiedene Bewertungsaufgaben getestet werden.
Zuletzt stand LLaMA (Large Language Model Meta AI) an der Spitze der Bestenliste und wurde kürzlich von einem neuen vortrainierten LLM – Falcon 40B – entthront.
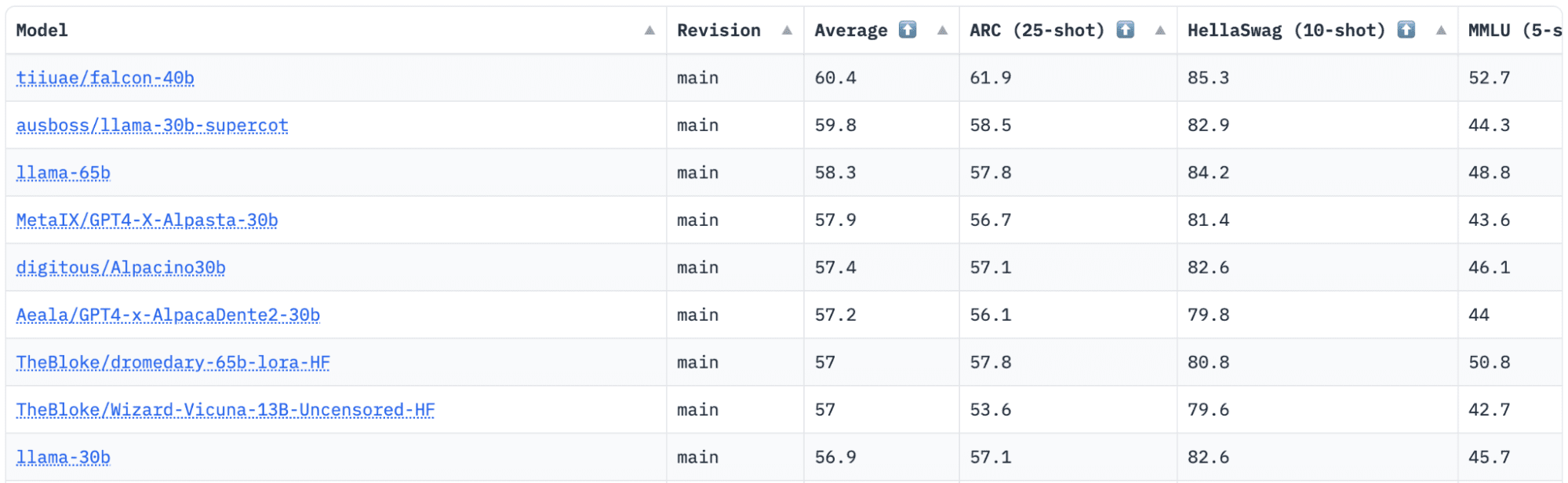
Bild von HuggingFace Open LLM-Bestenliste
Falcon LLM wurde von der gegründet und gebaut Institut für Technologieinnovation (TII), ein Unternehmen, das Teil des Advanced Technology Research Council der Regierung von Abu Dhabi ist. Die Regierung überwacht die Technologieforschung in den gesamten Vereinigten Arabischen Emiraten, wo sich das Team aus Wissenschaftlern, Forschern und Ingenieuren auf die Bereitstellung transformativer Technologien und Entdeckungen in der Wissenschaft konzentriert.
Falcon-40B ist ein grundlegendes LLM mit 40B Parametern, das auf einer Billion Token trainiert. Falcon 40B ist ein reines autoregressives Decodermodell. Ein autoregressives Nur-Decoder-Modell bedeutet, dass das Modell darauf trainiert ist, das nächste Token in einer Sequenz anhand der vorherigen Token vorherzusagen. Das GPT-Modell ist ein gutes Beispiel dafür.
Es hat sich gezeigt, dass die Architektur von Falcon GPT-3 bei nur 75 % des Trainingsrechenbudgets deutlich übertrifft und außerdem nur ? der Berechnung zum Inferenzzeitpunkt.
Datenqualität im großen Maßstab war ein wichtiger Schwerpunkt des Teams am Technology Innovation Institute, da wir wissen, dass LLMs sehr empfindlich auf die Qualität von Trainingsdaten reagieren. Das Team baute eine Datenpipeline auf, die für eine schnelle Verarbeitung auf Zehntausende CPU-Kerne skaliert werden konnte und mithilfe umfassender Filterung und Deduplizierung hochwertige Inhalte aus dem Web extrahieren konnte.
Es gibt auch eine weitere kleinere Version: Falcon-7B mit 7B Parametern, trainiert auf 1,500B Token. Sowie ein Falcon-40B-Instruktion und Falcon-7B-Instruktion Modelle verfügbar, wenn Sie ein gebrauchsfertiges Chat-Modell suchen.
Was kann Falcon 40B?
Ähnlich wie andere LLMs kann Falcon 40B:
- Generieren Sie kreative Inhalte
- Komplexe Probleme lösen
- Kundendiensteinsätze
- Virtuelle Assistenten
- Sprachübersetzungsdienste
- Stimmungsanalyse.
- Reduzieren und automatisieren Sie „sich wiederholende“ Arbeiten.
- Helfen Sie emiratischen Unternehmen, effizienter zu werden
Wie wurde Falcon 40B trainiert?
Da es mit 1 Billion Token trainiert wurde, waren über einen Zeitraum von zwei Monaten 384 GPUs auf AWS erforderlich. Auf 1,000 Milliarden Token trainiert RefinedWeb, ein riesiger englischer Webdatensatz, der von TII erstellt wurde.
Vortrainingsdaten bestanden aus einer Sammlung öffentlicher Daten aus dem Internet CommonCrawl. Das Team durchlief eine gründliche Filterphase, um maschinengenerierten Text und nicht jugendfreie Inhalte sowie jegliche Deduplizierung zu entfernen, um einen Vortrainingsdatensatz von fast fünf Billionen Token zu erstellen.
Der auf CommonCrawl aufbauende RefinedWeb-Datensatz hat gezeigt, dass Modelle eine bessere Leistung erzielen als Modelle, die auf kuratierten Datensätzen trainiert werden. RefinedWeb ist auch multimodal-freundlich.
Sobald es fertig war, wurde Falcon anhand von Open-Source-Benchmarks wie EAI Harness, HELM und BigBench validiert.
Sie haben Open-Source-Falcon LLM der Öffentlichkeit zugänglich gemacht, wodurch Falcon 40B und 7B für Forscher und Entwickler zugänglicher werden, da es auf der Apache-Lizenzversion 2.0 basiert.
Das LLM, das einst nur der Forschung und kommerziellen Nutzung diente, ist nun Open Source, um der weltweiten Nachfrage nach einem integrativen Zugang zu KI gerecht zu werden. Es ist jetzt frei von Lizenzgebühren für kommerzielle Nutzungsbeschränkungen, da sich die VAE dafür einsetzen, die Herausforderungen und Grenzen innerhalb der KI zu ändern und zu zeigen, wie sie in Zukunft eine wichtige Rolle spielt.
Mit dem Ziel, ein Ökosystem der Zusammenarbeit, Innovation und des Wissensaustauschs in der Welt der KI zu schaffen, gewährleistet Apache 2.0 Sicherheit und sichere Open-Source-Software.
Wenn Sie eine einfachere Version von Falcon-40B ausprobieren möchten, die sich besser für allgemeine Anweisungen im Chatbot-Stil eignet, sollten Sie Falcon-7B verwenden.
Also lasst uns anfangen…
Falls noch nicht geschehen, installieren Sie die folgenden Pakete:
!pip install transformers
!pip install einops
!pip install accelerate
!pip install xformers
Sobald Sie diese Pakete installiert haben, können Sie mit der Ausführung des bereitgestellten Codes fortfahren Falcon 7-B-Anweisung:
from transformers import AutoTokenizer, AutoModelForCausalLM
import transformers
import torch model = "tiiuae/falcon-7b-instruct" tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline( "text-generation", model=model, tokenizer=tokenizer, torch_dtype=torch.bfloat16, trust_remote_code=True, device_map="auto",
)
sequences = pipeline( "Girafatron is obsessed with giraffes, the most glorious animal on the face of this Earth. Giraftron believes all other animals are irrelevant when compared to the glorious majesty of the giraffe.nDaniel: Hello, Girafatron!nGirafatron:", max_length=200, do_sample=True, top_k=10, num_return_sequences=1, eos_token_id=tokenizer.eos_token_id,
)
for seq in sequences: print(f"Result: {seq['generated_text']}")
Als bestes Open-Source-Modell auf dem Markt hat sich Falcon die Krone der LLaMAs gesichert, und die Leute sind erstaunt über seine stark optimierte Architektur, Open-Source mit einer einzigartigen Lizenz und es ist in zwei Größen erhältlich: 40B- und 7B-Parameter.
Haben Sie es versucht? Wenn ja, teilen Sie uns in den Kommentaren Ihre Meinung mit.
Nisha Arya ist Data Scientist, freiberuflicher technischer Redakteur und Community Manager bei KDnuggets. Sie ist besonders daran interessiert, Data Science Karriereberatung oder Tutorials und theoriebasiertes Wissen rund um Data Science anzubieten. Sie möchte auch die verschiedenen Möglichkeiten untersuchen, wie künstliche Intelligenz der Langlebigkeit des menschlichen Lebens zugute kommt/kann. Eine begeisterte Lernende, die ihr technisches Wissen und ihre Schreibfähigkeiten erweitern möchte, während sie anderen hilft, sie zu führen.
Falcon LLM: Der neue König der Open-Source-LLMs – KDnuggets
Neuauflage von Plato
Bild vom Herausgeber
Wir haben gesehen, wie jede Woche große Sprachmodelle (LLMs) ausspuckten und immer mehr Chatbots für uns zur Verfügung standen. Es kann jedoch schwierig sein, herauszufinden, welches das Beste ist, welche Fortschritte es gibt und welches am nützlichsten ist.
Umarmendes Gesicht verfügt über ein Open LLM Leaderboard, das LLMs bei ihrer Veröffentlichung verfolgt, bewertet und einordnet. Sie verwenden ein einzigartiges Framework, mit dem generative Sprachmodelle für verschiedene Bewertungsaufgaben getestet werden.
Zuletzt stand LLaMA (Large Language Model Meta AI) an der Spitze der Bestenliste und wurde kürzlich von einem neuen vortrainierten LLM – Falcon 40B – entthront.
Bild von HuggingFace Open LLM-Bestenliste
Falcon LLM wurde von der gegründet und gebaut Institut für Technologieinnovation (TII), ein Unternehmen, das Teil des Advanced Technology Research Council der Regierung von Abu Dhabi ist. Die Regierung überwacht die Technologieforschung in den gesamten Vereinigten Arabischen Emiraten, wo sich das Team aus Wissenschaftlern, Forschern und Ingenieuren auf die Bereitstellung transformativer Technologien und Entdeckungen in der Wissenschaft konzentriert.
Falcon-40B ist ein grundlegendes LLM mit 40B Parametern, das auf einer Billion Token trainiert. Falcon 40B ist ein reines autoregressives Decodermodell. Ein autoregressives Nur-Decoder-Modell bedeutet, dass das Modell darauf trainiert ist, das nächste Token in einer Sequenz anhand der vorherigen Token vorherzusagen. Das GPT-Modell ist ein gutes Beispiel dafür.
Es hat sich gezeigt, dass die Architektur von Falcon GPT-3 bei nur 75 % des Trainingsrechenbudgets deutlich übertrifft und außerdem nur ? der Berechnung zum Inferenzzeitpunkt.
Datenqualität im großen Maßstab war ein wichtiger Schwerpunkt des Teams am Technology Innovation Institute, da wir wissen, dass LLMs sehr empfindlich auf die Qualität von Trainingsdaten reagieren. Das Team baute eine Datenpipeline auf, die für eine schnelle Verarbeitung auf Zehntausende CPU-Kerne skaliert werden konnte und mithilfe umfassender Filterung und Deduplizierung hochwertige Inhalte aus dem Web extrahieren konnte.
Es gibt auch eine weitere kleinere Version: Falcon-7B mit 7B Parametern, trainiert auf 1,500B Token. Sowie ein Falcon-40B-Instruktion und Falcon-7B-Instruktion Modelle verfügbar, wenn Sie ein gebrauchsfertiges Chat-Modell suchen.
Was kann Falcon 40B?
Ähnlich wie andere LLMs kann Falcon 40B:
Wie wurde Falcon 40B trainiert?
Da es mit 1 Billion Token trainiert wurde, waren über einen Zeitraum von zwei Monaten 384 GPUs auf AWS erforderlich. Auf 1,000 Milliarden Token trainiert RefinedWeb, ein riesiger englischer Webdatensatz, der von TII erstellt wurde.
Vortrainingsdaten bestanden aus einer Sammlung öffentlicher Daten aus dem Internet CommonCrawl. Das Team durchlief eine gründliche Filterphase, um maschinengenerierten Text und nicht jugendfreie Inhalte sowie jegliche Deduplizierung zu entfernen, um einen Vortrainingsdatensatz von fast fünf Billionen Token zu erstellen.
Der auf CommonCrawl aufbauende RefinedWeb-Datensatz hat gezeigt, dass Modelle eine bessere Leistung erzielen als Modelle, die auf kuratierten Datensätzen trainiert werden. RefinedWeb ist auch multimodal-freundlich.
Sobald es fertig war, wurde Falcon anhand von Open-Source-Benchmarks wie EAI Harness, HELM und BigBench validiert.
Sie haben Open-Source-Falcon LLM der Öffentlichkeit zugänglich gemacht, wodurch Falcon 40B und 7B für Forscher und Entwickler zugänglicher werden, da es auf der Apache-Lizenzversion 2.0 basiert.
Das LLM, das einst nur der Forschung und kommerziellen Nutzung diente, ist nun Open Source, um der weltweiten Nachfrage nach einem integrativen Zugang zu KI gerecht zu werden. Es ist jetzt frei von Lizenzgebühren für kommerzielle Nutzungsbeschränkungen, da sich die VAE dafür einsetzen, die Herausforderungen und Grenzen innerhalb der KI zu ändern und zu zeigen, wie sie in Zukunft eine wichtige Rolle spielt.
Mit dem Ziel, ein Ökosystem der Zusammenarbeit, Innovation und des Wissensaustauschs in der Welt der KI zu schaffen, gewährleistet Apache 2.0 Sicherheit und sichere Open-Source-Software.
Wenn Sie eine einfachere Version von Falcon-40B ausprobieren möchten, die sich besser für allgemeine Anweisungen im Chatbot-Stil eignet, sollten Sie Falcon-7B verwenden.
Also lasst uns anfangen…
Falls noch nicht geschehen, installieren Sie die folgenden Pakete:
Sobald Sie diese Pakete installiert haben, können Sie mit der Ausführung des bereitgestellten Codes fortfahren Falcon 7-B-Anweisung:
Als bestes Open-Source-Modell auf dem Markt hat sich Falcon die Krone der LLaMAs gesichert, und die Leute sind erstaunt über seine stark optimierte Architektur, Open-Source mit einer einzigartigen Lizenz und es ist in zwei Größen erhältlich: 40B- und 7B-Parameter.
Haben Sie es versucht? Wenn ja, teilen Sie uns in den Kommentaren Ihre Meinung mit.
Nisha Arya ist Data Scientist, freiberuflicher technischer Redakteur und Community Manager bei KDnuggets. Sie ist besonders daran interessiert, Data Science Karriereberatung oder Tutorials und theoriebasiertes Wissen rund um Data Science anzubieten. Sie möchte auch die verschiedenen Möglichkeiten untersuchen, wie künstliche Intelligenz der Langlebigkeit des menschlichen Lebens zugute kommt/kann. Eine begeisterte Lernende, die ihr technisches Wissen und ihre Schreibfähigkeiten erweitern möchte, während sie anderen hilft, sie zu führen.
Mehr zu diesem Thema
Edonia mit Sitz in Paris sammelt 2 Millionen Euro für die Herstellung pflanzlicher Inhaltsstoffe aus Mikroalgen | EU-Startups
US-Energieministerium senkt regulatorische Hürden für Solar-, Energiespeicher- und Übertragungsprojekte – CleanTechnica
Pixacare mit Sitz in Straßburg sammelt 3 Millionen Euro für die Automatisierung der Wundversorgungsüberwachung | EU-Startups
Generative KI-Landschaft in der mobilen App-Entwicklungsbranche
Die USA sagen „Bye-Bye TikTok“, es sei denn, ByteDance verkauft die App
Atomenergie. Die meisten Energiequellen werden in allen Ländern des Landes „gemindert“.
Alle Möglichkeiten, Cannabis zu konsumieren
Nein, Apple hat die Produktion von Vision Pro nicht wirklich um 50 % gekürzt
In der Legislaturperiode 2024 von NC geht es nicht nur um das Budget – Medical Marijuana Program Connection
BioUrban: Wie sind Mikroalgen zur klimatechnischen Lösung der Natur geworden?