
Dieser Beitrag wurde gemeinsam von Goktug Cinar, Michael Binder und Adrian Horvath vom Bosch Center for Artificial Intelligence (BCAI) verfasst.
Umsatzprognosen sind in den meisten Unternehmen eine herausfordernde, aber entscheidende Aufgabe für strategische Geschäftsentscheidungen und die Finanzplanung. Umsatzprognosen werden häufig manuell von Finanzanalysten durchgeführt und sind sowohl zeitaufwändig als auch subjektiv. Solche manuellen Bemühungen stellen eine besondere Herausforderung für große, multinationale Unternehmensorganisationen dar, die Umsatzprognosen für eine Vielzahl von Produktgruppen und geografischen Gebieten auf mehreren Granularitätsebenen benötigen. Dies erfordert nicht nur Genauigkeit, sondern auch hierarchische Kohärenz der Prognosen.
Bosch ist ein multinationales Unternehmen mit Einheiten, die in mehreren Sektoren tätig sind, darunter Automobil, Industrielösungen und Konsumgüter. Angesichts der Auswirkungen einer genauen und kohärenten Umsatzprognose auf einen gesunden Geschäftsbetrieb, die Bosch Zentrum für Künstliche Intelligenz (BCAI) hat stark in den Einsatz von maschinellem Lernen (ML) investiert, um die Effizienz und Genauigkeit von Finanzplanungsprozessen zu verbessern. Das Ziel besteht darin, die manuellen Prozesse zu erleichtern, indem angemessene grundlegende Umsatzprognosen über ML bereitgestellt werden, wobei nur gelegentliche Anpassungen durch die Finanzanalysten erforderlich sind, die ihr Branchen- und Domänenwissen nutzen.
Um dieses Ziel zu erreichen, hat BCAI einen internen Prognoserahmen entwickelt, der in der Lage ist, groß angelegte hierarchische Prognosen über kundenspezifische Ensembles einer breiten Palette von Basismodellen bereitzustellen. Ein Meta-Lerner wählt die leistungsstärksten Modelle basierend auf Merkmalen aus, die aus jeder Zeitreihe extrahiert wurden. Die Prognosen der ausgewählten Modelle werden dann gemittelt, um die aggregierte Prognose zu erhalten. Das architektonische Design ist modularisiert und erweiterbar durch die Implementierung einer Schnittstelle im REST-Stil, die eine kontinuierliche Leistungsverbesserung durch die Einbeziehung zusätzlicher Modelle ermöglicht.
BCAI ist eine Partnerschaft mit der Amazon ML-Lösungslabor (MLSL), um die neuesten Fortschritte bei Deep Neural Network (DNN)-basierten Modellen für Umsatzprognosen zu integrieren. Jüngste Fortschritte bei neuronalen Prognostikern haben eine hochmoderne Leistung für viele praktische Vorhersageprobleme gezeigt. Im Vergleich zu herkömmlichen Prognosemodellen können viele neuronale Prognostiker zusätzliche Kovariaten oder Metadaten der Zeitreihen einbeziehen. Wir schließen CNN-QR und DeepAR+, zwei handelsübliche Modelle, ein Amazon-Prognose, sowie ein benutzerdefiniertes Transformer-Modell, das mit trainiert wurde Amazon Sage Maker. Die drei Modelle decken einen repräsentativen Satz von Encoder-Backbones ab, die häufig in neuronalen Prognostikern verwendet werden: Convolutional Neural Network (CNN), Sequential Recurrent Neural Network (RNN) und transformatorbasierte Encoder.
Eine der größten Herausforderungen für die BCAI-MLSL-Partnerschaft bestand darin, robuste und vernünftige Prognosen unter den Auswirkungen von COVID-19 bereitzustellen, einem beispiellosen globalen Ereignis, das eine große Volatilität bei den Finanzergebnissen von Unternehmen weltweit verursacht. Da neuronale Prognostiker auf historischen Daten trainiert werden, könnten die Prognosen, die auf der Grundlage von Out-of-Distribution-Daten aus volatileren Zeiträumen generiert werden, ungenau und unzuverlässig sein. Daher haben wir vorgeschlagen, einen maskierten Aufmerksamkeitsmechanismus in der Transformer-Architektur hinzuzufügen, um dieses Problem zu beheben.
Die neuronalen Prognostiker können als einzelnes Ensemble-Modell gebündelt oder einzeln in das Modelluniversum von Bosch integriert und über REST-API-Endpunkte einfach aufgerufen werden. Wir schlagen einen Ansatz vor, um die neuronalen Prognostiker durch Backtest-Ergebnisse zu vereinen, was im Laufe der Zeit eine wettbewerbsfähige und robuste Leistung bietet. Darüber hinaus haben wir eine Reihe klassischer hierarchischer Abstimmungstechniken untersucht und bewertet, um sicherzustellen, dass Prognosen über Produktgruppen, Regionen und Unternehmensorganisationen hinweg kohärent aggregiert werden.
In diesem Beitrag demonstrieren wir Folgendes:
- Anwenden von Forecast und benutzerdefiniertem SageMaker-Modelltraining für hierarchische, groß angelegte Zeitreihen-Prognoseprobleme
- So kombinieren Sie benutzerdefinierte Modelle mit Standardmodellen von Forecast
- So reduzieren Sie die Auswirkungen von Störereignissen wie COVID-19 auf Prognoseprobleme
- So erstellen Sie einen End-to-End-Prognose-Workflow auf AWS
Herausforderungen
Wir haben uns zwei Herausforderungen gestellt: der Erstellung hierarchischer, groß angelegter Umsatzprognosen und den Auswirkungen der COVID-19-Pandemie auf langfristige Prognosen.
Hierarchische, groß angelegte Umsatzprognose
Finanzanalysten haben die Aufgabe, Finanzkennzahlen zu prognostizieren, darunter Einnahmen, Betriebskosten und F&E-Ausgaben. Diese Metriken bieten Einblicke in die Geschäftsplanung auf verschiedenen Aggregationsebenen und ermöglichen eine datengesteuerte Entscheidungsfindung. Jede automatisierte Prognoselösung muss Prognosen auf jeder beliebigen Ebene der Geschäftsbereichsaggregation bereitstellen. Bei Bosch kann man sich die Aggregationen als gruppierte Zeitreihen als allgemeinere Form der hierarchischen Struktur vorstellen. Die folgende Abbildung zeigt ein vereinfachtes Beispiel mit einer zweistufigen Struktur, die die hierarchische Umsatzprognosestruktur bei Bosch nachahmt. Der Gesamtumsatz wird je nach Produkt und Region in mehrere Aggregationsebenen aufgeteilt.
Die Gesamtzahl der bei Bosch zu prognostizierenden Zeitreihen bewegt sich im Millionenbereich. Beachten Sie, dass die Zeitreihen der obersten Ebene entweder nach Produkten oder Regionen aufgeteilt werden können, wodurch mehrere Pfade zu den Prognosen der untersten Ebene erstellt werden. Der Umsatz muss an jedem Knoten in der Hierarchie mit einem Prognosehorizont von 12 Monaten in die Zukunft prognostiziert werden. Monatliche Verlaufsdaten sind verfügbar.
Die hierarchische Struktur lässt sich in folgender Form mit der Notation einer Summenmatrix darstellen S (Hyndman und Athanasopoulos):
![]()
In dieser Gleichung Y gleicht folgendem:

Hier b stellt die Zeitreihe der untersten Ebene zu einem Zeitpunkt dar t.
Auswirkungen der COVID-19-Pandemie
Die COVID-19-Pandemie brachte aufgrund ihrer disruptiven und beispiellosen Auswirkungen auf fast alle Aspekte des Arbeits- und Soziallebens erhebliche Herausforderungen für die Prognose mit sich. Für langfristige Umsatzprognosen brachte die Unterbrechung auch unerwartete nachgelagerte Auswirkungen mit sich. Zur Veranschaulichung dieser Problematik zeigt die folgende Abbildung eine beispielhafte Zeitreihe, bei der die Produktumsätze zu Beginn der Pandemie deutlich zurückgingen und sich danach allmählich erholten. Ein typisches neuronales Prognosemodell verwendet Umsatzdaten, einschließlich der Out-of-Distribution (OOD)-COVID-Periode, als historische Kontexteingabe sowie die Grundwahrheit für das Modelltraining. Dadurch sind die erstellten Prognosen nicht mehr verlässlich.

Modellierungsansätze
In diesem Abschnitt diskutieren wir unsere verschiedenen Modellierungsansätze.
Amazon-Prognose
Forecast ist ein vollständig verwalteter KI/ML-Service von AWS, der vorkonfigurierte, hochmoderne Zeitreihen-Prognosemodelle bereitstellt. Es kombiniert diese Angebote mit seinen internen Fähigkeiten zur automatisierten Hyperparameter-Optimierung, Ensemble-Modellierung (für die von Forecast bereitgestellten Modelle) und probabilistischen Prognosegenerierung. Auf diese Weise können Sie ganz einfach benutzerdefinierte Datensätze aufnehmen, Daten vorverarbeiten, Prognosemodelle trainieren und robuste Prognosen erstellen. Das modulare Design des Dienstes ermöglicht es uns außerdem, Vorhersagen aus zusätzlichen, parallel entwickelten benutzerdefinierten Modellen einfach abzufragen und zu kombinieren.
Wir integrieren zwei neuronale Prognostiker von Forecast: CNN-QR und DeepAR+. Beides sind überwachte Deep-Learning-Methoden, die ein globales Modell für den gesamten Zeitreihendatensatz trainieren. Sowohl CNNQR- als auch DeepAR+-Modelle können statische Metadateninformationen zu jeder Zeitreihe aufnehmen, die in unserem Fall das entsprechende Produkt, die Region und die Unternehmensorganisation sind. Sie fügen auch automatisch zeitliche Merkmale wie den Monat des Jahres als Teil der Eingabe in das Modell hinzu.
Transformator mit Aufmerksamkeitsmasken für COVID
Die Transformer-Architektur (Vaswani et al.), ursprünglich für die Verarbeitung natürlicher Sprache (Natural Language Processing, NLP) konzipiert, hat sich kürzlich zu einer beliebten architektonischen Wahl für Zeitreihenprognosen entwickelt. Hier haben wir die in beschriebene Transformer-Architektur verwendet Zhouet al. ohne probabilistisches Protokoll spärliche Aufmerksamkeit. Das Modell verwendet ein typisches Architekturdesign, indem es einen Encoder und einen Decoder kombiniert. Für die Umsatzprognose konfigurieren wir den Decoder so, dass er die Prognose des 12-Monats-Horizonts direkt ausgibt, anstatt die Prognose Monat für Monat autoregressiv zu generieren. Basierend auf der Häufigkeit der Zeitreihen werden zusätzliche zeitbezogene Merkmale wie der Monat des Jahres als Eingangsvariable hinzugefügt. Über eine trainierbare Einbettungsschicht werden weitere kategoriale Variablen, die die Metainformationen (Produkt, Region, Unternehmensorganisation) beschreiben, in das Netzwerk eingespeist.
Das folgende Diagramm veranschaulicht die Transformer-Architektur und den Aufmerksamkeitsmaskierungsmechanismus. Auf allen Encoder- und Decoder-Layern wird eine Aufmerksamkeitsmaskierung angewendet, wie orange hervorgehoben, um zu verhindern, dass OOD-Daten die Vorhersagen beeinflussen.

Wir mildern die Auswirkungen von OOD-Kontextfenstern, indem wir Aufmerksamkeitsmasken hinzufügen. Das Modell ist darauf trainiert, dem COVID-Zeitraum, der Ausreißer enthält, durch Maskierung nur sehr wenig Aufmerksamkeit zu widmen, und führt Prognosen mit maskierten Informationen durch. Die Aufmerksamkeitsmaske wird in jeder Schicht der Decodierer- und Codiererarchitektur angewendet. Das maskierte Fenster kann entweder manuell oder durch einen Ausreißererkennungsalgorithmus angegeben werden. Wenn außerdem ein Zeitfenster verwendet wird, das Ausreißer als Trainingsetiketten enthält, werden die Verluste nicht zurückpropagiert. Diese auf Aufmerksamkeitsmaskierung basierende Methode kann angewendet werden, um Störungen und OOD-Fälle zu behandeln, die durch andere seltene Ereignisse verursacht werden, und die Robustheit der Prognosen zu verbessern.
Vorbildliches Ensemble
Das Modellensemble übertrifft häufig einzelne Modelle für die Vorhersage – es verbessert die Verallgemeinerbarkeit des Modells und ist besser in der Lage, Zeitreihendaten mit unterschiedlichen Merkmalen in Bezug auf Periodizität und Intermittenz zu verarbeiten. Wir integrieren eine Reihe von Modell-Ensemble-Strategien, um die Modellleistung und Robustheit von Prognosen zu verbessern. Eine gängige Form des Deep-Learning-Modellensembles besteht darin, Ergebnisse aus Modellläufen mit unterschiedlichen Zufallsgewichtungsinitialisierungen oder aus unterschiedlichen Trainingsepochen zu aggregieren. Wir verwenden diese Strategie, um Prognosen für das Transformer-Modell zu erhalten.
Um ein Ensemble auf verschiedenen Modellarchitekturen wie Transformer, CNNQR und DeepAR+ weiter aufzubauen, verwenden wir eine Gesamtmodell-Ensemble-Strategie, die die Top-k-Modelle mit der besten Leistung für jede Zeitreihe basierend auf den Backtest-Ergebnissen auswählt und deren erhält Durchschnitte. Da Backtest-Ergebnisse direkt aus trainierten Forecast-Modellen exportiert werden können, ermöglicht uns diese Strategie, schlüsselfertige Dienste wie Forecast mit Verbesserungen aus benutzerdefinierten Modellen wie Transformer zu nutzen. Ein solcher End-to-End-Modell-Ensemble-Ansatz erfordert weder das Training eines Meta-Lerners noch die Berechnung von Zeitreihenmerkmalen für die Modellauswahl.
Hierarchische Versöhnung
Das Framework ist anpassungsfähig, um eine breite Palette von Techniken als Nachbearbeitungsschritte für den hierarchischen Prognoseabgleich zu integrieren, einschließlich Bottom-up (BU), Top-down-Abgleich mit Prognoseanteilen (TDFP), gewöhnliche kleinste Quadrate (OLS) und gewichtete kleinste Quadrate ( WLS). Alle experimentellen Ergebnisse in diesem Beitrag werden unter Verwendung eines Top-Down-Abgleichs mit prognostizierten Anteilen gemeldet.
Architektur Überblick
Wir haben einen automatisierten End-to-End-Workflow auf AWS entwickelt, um Umsatzprognosen mithilfe von Diensten wie Forecast, SageMaker, Amazon Simple Storage-Service (Amazon S3), AWS Lambda, AWS Step-Funktionen und AWS Cloud-Entwicklungskit (AWS-CDK). Die bereitgestellte Lösung stellt individuelle Zeitreihenprognosen über eine REST-API bereit Amazon API-Gateway, indem die Ergebnisse im vordefinierten JSON-Format zurückgegeben werden.
Das folgende Diagramm veranschaulicht den End-to-End-Prognose-Workflow.

Wichtige Designüberlegungen für die Architektur sind Vielseitigkeit, Leistung und Benutzerfreundlichkeit. Das System sollte ausreichend vielseitig sein, um einen vielfältigen Satz von Algorithmen während der Entwicklung und Bereitstellung mit minimalen erforderlichen Änderungen zu integrieren, und kann leicht erweitert werden, wenn in Zukunft neue Algorithmen hinzugefügt werden. Das System sollte außerdem minimalen Overhead hinzufügen und parallelisiertes Training sowohl für Forecast als auch für SageMaker unterstützen, um die Trainingszeit zu verkürzen und die neuesten Prognosen schneller zu erhalten. Schließlich soll das System für Experimentierzwecke einfach zu handhaben sein.
Der End-to-End-Workflow durchläuft nacheinander die folgenden Module:
- Ein Vorverarbeitungsmodul für die Neuformatierung und Transformation von Daten
- Ein Modellschulungsmodul, das sowohl das Prognosemodell als auch das benutzerdefinierte Modell auf SageMaker enthält (beide laufen parallel)
- Ein Nachbearbeitungsmodul, das Modellensemble, hierarchische Abstimmung, Metriken und Berichterstellung unterstützt
Step Functions organisiert und orchestriert den Workflow von Ende zu Ende als Zustandsmaschine. Die Ausführung des Zustandsautomaten wird mit einer JSON-Datei konfiguriert, die alle erforderlichen Informationen enthält, einschließlich des Speicherorts der CSV-Dateien mit den historischen Einnahmen in Amazon S3, der prognostizierten Startzeit und der Modell-Hyperparametereinstellungen zum Ausführen des End-to-End-Workflows. Asynchrone Aufrufe werden erstellt, um das Modelltraining in der Zustandsmaschine mithilfe von Lambda-Funktionen zu parallelisieren. Alle historischen Daten, Konfigurationsdateien, Prognoseergebnisse sowie Zwischenergebnisse wie Backtesting-Ergebnisse werden in Amazon S3 gespeichert. Die REST-API baut auf Amazon S3 auf, um eine abfragbare Schnittstelle zum Abfragen von Prognoseergebnissen bereitzustellen. Das System kann erweitert werden, um neue Prognosemodelle und unterstützende Funktionen, wie z. B. die Erstellung von Prognosevisualisierungsberichten, einzubinden.
Evaluierung
In diesem Abschnitt erläutern wir den Versuchsaufbau. Zu den Schlüsselkomponenten gehören der Datensatz, Bewertungsmetriken, Backtest-Fenster sowie die Einrichtung und das Training des Modells.
Datensatz
Um die finanzielle Privatsphäre von Bosch zu schützen und gleichzeitig einen aussagekräftigen Datensatz zu verwenden, haben wir einen synthetischen Datensatz verwendet, der ähnliche statistische Eigenschaften aufweist wie ein realer Umsatzdatensatz aus einer Geschäftseinheit bei Bosch. Der Datensatz enthält insgesamt 1,216 Zeitreihen mit monatlich erfassten Umsätzen von Januar 2016 bis April 2022. Der Datensatz wird mit 877 Zeitreihen auf der feinsten Ebene (unterste Zeitreihe) geliefert, wobei eine entsprechende gruppierte Zeitreihenstruktur dargestellt wird als Summenmatrix S. Jede Zeitreihe ist mit drei statischen kategorialen Attributen verknüpft, die der Produktkategorie, der Region und der Organisationseinheit im realen Datensatz (anonymisiert in den synthetischen Daten) entsprechen.
Bewertungsmetriken
Wir verwenden Median-Mean Arctangent Absolute Percentage Error (Median-MAAPE) und Weighted-MAAPE, um die Modellleistung zu bewerten und vergleichende Analysen durchzuführen, die die bei Bosch verwendeten Standardmetriken sind. MAAPE behebt die Mängel der Mean Absolute Percentage Error (MAPE)-Metrik, die häufig im Geschäftskontext verwendet wird. Median-MAAPE gibt einen Überblick über die Modellleistung, indem der Median der MAAPEs berechnet wird, die für jede Zeitreihe einzeln berechnet werden. Weighted-MAAPE meldet eine gewichtete Kombination der einzelnen MAAPEs. Die Gewichtungen sind der Anteil des Umsatzes für jede Zeitreihe im Vergleich zum aggregierten Umsatz des gesamten Datensatzes. Der gewichtete MAAPE spiegelt die nachgelagerten geschäftlichen Auswirkungen der Prognosegenauigkeit besser wider. Beide Metriken werden für den gesamten Datensatz von 1,216 Zeitreihen gemeldet.
Backtest-Fenster
Wir verwenden rollierende 12-monatige Backtest-Fenster, um die Modellleistung zu vergleichen. Die folgende Abbildung veranschaulicht die in den Experimenten verwendeten Backtest-Fenster und hebt die entsprechenden Daten hervor, die für das Training und die Hyperparameter-Optimierung (HPO) verwendet wurden. Für Backtest-Fenster nach Beginn von COVID-19 wird das Ergebnis von April bis Mai 2020 durch OOD-Eingaben beeinflusst, basierend auf unseren Beobachtungen aus der Umsatzzeitreihe.

Modellaufbau und Training
Für das Transformer-Training haben wir den Quantilverlust verwendet und jede Zeitreihe mit ihrem historischen Mittelwert skaliert, bevor wir sie in Transformer eingespeist und den Trainingsverlust berechnet haben. Die endgültigen Prognosen werden neu skaliert, um die Genauigkeitsmetriken mithilfe des in implementierten MeanScaler zu berechnen GluonTS. Wir verwenden ein Kontextfenster mit monatlichen Umsatzdaten der letzten 18 Monate, ausgewählt über HPO im Backtest-Fenster von Juli 2018 bis Juni 2019. Zusätzliche Metadaten zu jeder Zeitreihe in Form von statischen kategorialen Variablen werden über eine Einbettung in das Modell eingespeist Schicht, bevor sie den Transformatorschichten zugeführt wird. Wir trainieren den Transformer mit fünf verschiedenen Zufallsgewichtungsinitialisierungen und mitteln die Vorhersageergebnisse aus den letzten drei Epochen für jeden Lauf, insgesamt durchschnittlich 15 Modelle. Die fünf Modelltrainingsläufe können parallelisiert werden, um die Trainingszeit zu verkürzen. Für den maskierten Transformer geben wir die Monate April bis Mai 2020 als Ausreißer an.
Für das gesamte Forecast-Modelltraining haben wir das automatische HPO aktiviert, das die Modell- und Trainingsparameter basierend auf einem benutzerdefinierten Backtest-Zeitraum auswählen kann, der im Datenfenster für Training und HPO auf die letzten 12 Monate eingestellt ist.
Versuchsergebnisse
Wir trainieren maskierte und unmaskierte Transformer mit denselben Hyperparametern und verglichen ihre Leistung für Backtest-Fenster unmittelbar nach dem COVID-19-Schock. Beim maskierten Transformer sind die beiden maskierten Monate April und Mai 2020. Die folgende Tabelle zeigt die Ergebnisse einer Reihe von Backtest-Perioden mit 12-monatigen Prognosefenstern ab Juni 2020. Wir können beobachten, dass der maskierte Transformer die unmaskierte Version durchweg übertrifft .

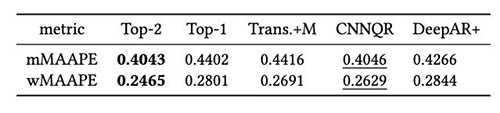
Wir haben außerdem eine Bewertung der Modell-Ensemble-Strategie basierend auf Backtest-Ergebnissen durchgeführt. Insbesondere vergleichen wir die beiden Fälle, in denen nur das leistungsstärkste Modell ausgewählt wird, und wenn die beiden leistungsstärksten Modelle ausgewählt werden, und die Modellmittelung durch Berechnung des Mittelwerts der Prognosen durchgeführt wird. Wir vergleichen die Leistung der Basismodelle und der Ensemble-Modelle in den folgenden Abbildungen. Beachten Sie, dass keiner der neuralen Prognostiker andere für die rollierenden Backtest-Fenster durchweg übertrifft.


Die folgende Tabelle zeigt, dass die Ensemble-Modellierung der beiden besten Modelle im Durchschnitt die beste Leistung liefert. CNNQR liefert das zweitbeste Ergebnis.
Zusammenfassung
In diesem Beitrag wurde gezeigt, wie eine End-to-End-ML-Lösung für groß angelegte Prognoseprobleme erstellt wird, indem Forecast und ein benutzerdefiniertes Modell kombiniert werden, das auf SageMaker trainiert wurde. Abhängig von Ihren Geschäftsanforderungen und ML-Kenntnissen können Sie einen vollständig verwalteten Dienst wie Forecast verwenden, um den Erstellungs-, Schulungs- und Bereitstellungsprozess eines Prognosemodells auszulagern. Erstellen Sie Ihr benutzerdefiniertes Modell mit spezifischen Tuning-Mechanismen mit SageMaker; oder führen Sie eine Modellzusammenstellung durch, indem Sie die beiden Dienste kombinieren.
Wenn Sie Hilfe benötigen, um den Einsatz von ML in Ihren Produkten und Dienstleistungen zu beschleunigen, wenden Sie sich bitte an die Amazon ML-Lösungslabor
Bibliographie
Hyndman RJ, Athanasopoulos G. Prognose: Prinzipien und Praxis. OTexte; 2018. Mai 8.
Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez AN, Kaiser Ł, Polosukhin I. Aufmerksamkeit ist alles, was Sie brauchen. Fortschritte bei neuronalen Informationsverarbeitungssystemen. 2017;30.
H. Zhou, S. Zhang, J. Peng, S. Zhang, J. Li, H. Xiong, W. Zhang. In Proceedings of AAAI 2021, 2. Februar.
Über die Autoren
 Göktug Cinar ist leitender ML-Wissenschaftler und technischer Leiter der ML- und statistikbasierten Prognose bei Robert Bosch LLC und Bosch Center for Artificial Intelligence. Er leitet die Forschung zu Prognosemodellen, hierarchischer Konsolidierung und Modellkombinationstechniken sowie das Softwareentwicklungsteam, das diese Modelle skaliert und als Teil der internen End-to-End-Finanzprognosesoftware bereitstellt.
Göktug Cinar ist leitender ML-Wissenschaftler und technischer Leiter der ML- und statistikbasierten Prognose bei Robert Bosch LLC und Bosch Center for Artificial Intelligence. Er leitet die Forschung zu Prognosemodellen, hierarchischer Konsolidierung und Modellkombinationstechniken sowie das Softwareentwicklungsteam, das diese Modelle skaliert und als Teil der internen End-to-End-Finanzprognosesoftware bereitstellt.
 Michael Binder ist Product Owner bei Bosch Global Services, wo er die Entwicklung, Bereitstellung und Implementierung der unternehmensweiten Predictive-Analytics-Anwendung für die groß angelegte automatisierte datengesteuerte Prognose von Finanzkennzahlen koordiniert.
Michael Binder ist Product Owner bei Bosch Global Services, wo er die Entwicklung, Bereitstellung und Implementierung der unternehmensweiten Predictive-Analytics-Anwendung für die groß angelegte automatisierte datengesteuerte Prognose von Finanzkennzahlen koordiniert.
 Adrian Horvath ist Softwareentwickler am Bosch Center for Artificial Intelligence, wo er Systeme entwickelt und wartet, um Vorhersagen basierend auf verschiedenen Prognosemodellen zu erstellen.
Adrian Horvath ist Softwareentwickler am Bosch Center for Artificial Intelligence, wo er Systeme entwickelt und wartet, um Vorhersagen basierend auf verschiedenen Prognosemodellen zu erstellen.
 Panpan Xu ist Senior Applied Scientist und Manager im Amazon ML Solutions Lab bei AWS. Sie arbeitet an der Forschung und Entwicklung von Algorithmen für maschinelles Lernen für hochwirksame Kundenanwendungen in einer Vielzahl von Branchen, um deren KI- und Cloud-Einführung zu beschleunigen. Ihre Forschungsinteressen umfassen Modellinterpretierbarkeit, Kausalanalyse, Human-in-the-Loop-KI und interaktive Datenvisualisierung.
Panpan Xu ist Senior Applied Scientist und Manager im Amazon ML Solutions Lab bei AWS. Sie arbeitet an der Forschung und Entwicklung von Algorithmen für maschinelles Lernen für hochwirksame Kundenanwendungen in einer Vielzahl von Branchen, um deren KI- und Cloud-Einführung zu beschleunigen. Ihre Forschungsinteressen umfassen Modellinterpretierbarkeit, Kausalanalyse, Human-in-the-Loop-KI und interaktive Datenvisualisierung.
 Jasleen Grewal ist Applied Scientist bei Amazon Web Services, wo sie mit AWS-Kunden zusammenarbeitet, um reale Probleme mithilfe von maschinellem Lernen zu lösen, mit besonderem Schwerpunkt auf Präzisionsmedizin und Genomik. Sie hat einen starken Hintergrund in Bioinformatik, Onkologie und klinischer Genomik. Sie setzt sich leidenschaftlich für den Einsatz von KI/ML und Cloud-Diensten ein, um die Patientenversorgung zu verbessern.
Jasleen Grewal ist Applied Scientist bei Amazon Web Services, wo sie mit AWS-Kunden zusammenarbeitet, um reale Probleme mithilfe von maschinellem Lernen zu lösen, mit besonderem Schwerpunkt auf Präzisionsmedizin und Genomik. Sie hat einen starken Hintergrund in Bioinformatik, Onkologie und klinischer Genomik. Sie setzt sich leidenschaftlich für den Einsatz von KI/ML und Cloud-Diensten ein, um die Patientenversorgung zu verbessern.
 Selvan Senthivel ist Senior ML Engineer im Amazon ML Solutions Lab bei AWS und konzentriert sich darauf, Kunden bei maschinellem Lernen, Deep-Learning-Problemen und End-to-End-ML-Lösungen zu unterstützen. Er war Gründungsingenieur von Amazon Comprehend Medical und trug zum Design und zur Architektur mehrerer AWS-KI-Services bei.
Selvan Senthivel ist Senior ML Engineer im Amazon ML Solutions Lab bei AWS und konzentriert sich darauf, Kunden bei maschinellem Lernen, Deep-Learning-Problemen und End-to-End-ML-Lösungen zu unterstützen. Er war Gründungsingenieur von Amazon Comprehend Medical und trug zum Design und zur Architektur mehrerer AWS-KI-Services bei.
 Ruilin Zhang ist eine SDE mit dem Amazon ML Solutions Lab bei AWS. Er hilft Kunden bei der Einführung von AWS AI-Services, indem er Lösungen entwickelt, um allgemeine Geschäftsprobleme zu lösen.
Ruilin Zhang ist eine SDE mit dem Amazon ML Solutions Lab bei AWS. Er hilft Kunden bei der Einführung von AWS AI-Services, indem er Lösungen entwickelt, um allgemeine Geschäftsprobleme zu lösen.
 Shane Rai ist Senior ML Strategist im Amazon ML Solutions Lab bei AWS. Er arbeitet mit Kunden aus den unterschiedlichsten Branchen zusammen, um ihre dringendsten und innovativsten Geschäftsanforderungen zu lösen, indem er die Breite der Cloud-basierten KI/ML-Services von AWS nutzt.
Shane Rai ist Senior ML Strategist im Amazon ML Solutions Lab bei AWS. Er arbeitet mit Kunden aus den unterschiedlichsten Branchen zusammen, um ihre dringendsten und innovativsten Geschäftsanforderungen zu lösen, indem er die Breite der Cloud-basierten KI/ML-Services von AWS nutzt.
 Lin Lee Cheong ist Applied Science Manager im Amazon ML Solutions Lab-Team bei AWS. Sie arbeitet mit strategischen AWS-Kunden zusammen, um künstliche Intelligenz und maschinelles Lernen zu erforschen und anzuwenden, um neue Erkenntnisse zu gewinnen und komplexe Probleme zu lösen.
Lin Lee Cheong ist Applied Science Manager im Amazon ML Solutions Lab-Team bei AWS. Sie arbeitet mit strategischen AWS-Kunden zusammen, um künstliche Intelligenz und maschinelles Lernen zu erforschen und anzuwenden, um neue Erkenntnisse zu gewinnen und komplexe Probleme zu lösen.