
En la gestión de activos, los gestores de carteras deben seguir de cerca las empresas de su universo de inversión para identificar riesgos y oportunidades y orientar las decisiones de inversión. El seguimiento de eventos directos, como informes de ganancias o rebajas de crédito, es sencillo: puede configurar alertas para notificar a los gerentes sobre noticias que contengan nombres de empresas. Sin embargo, detectar impactos de segundo y tercer orden que surgen de eventos en proveedores, clientes, socios u otras entidades en el ecosistema de una empresa es un desafío.
Por ejemplo, una interrupción de la cadena de suministro en un proveedor clave probablemente afectaría negativamente a los fabricantes intermedios. O la pérdida de un cliente importante para un cliente importante plantea un riesgo de demanda para el proveedor. Muy a menudo, estos eventos no aparecen en los titulares y presentan directamente a la empresa afectada, pero aún así es importante prestarles atención. En esta publicación, demostramos una solución automatizada que combina gráficos de conocimiento y inteligencia artificial generativa (IA) sacar a la luz tales riesgos cruzando mapas de relaciones con noticias en tiempo real.
En términos generales, esto implica dos pasos: primero, construir las intrincadas relaciones entre empresas (clientes, proveedores, directores) en un gráfico de conocimiento. En segundo lugar, utilizar esta base de datos gráfica junto con IA generativa para detectar impactos de segundo y tercer orden de eventos noticiosos. Por ejemplo, esta solución puede resaltar que los retrasos en un proveedor de repuestos pueden interrumpir la producción de los fabricantes de automóviles intermedios en una cartera, aunque no se haga referencia directa a ninguno de ellos.
Con AWS, puede implementar esta solución en una arquitectura sin servidor, escalable y totalmente basada en eventos. Esta publicación demuestra una prueba de concepto basada en dos servicios clave de AWS muy adecuados para la representación del conocimiento gráfico y el procesamiento del lenguaje natural: Amazonas Neptuno y lecho rocoso del amazonas. Neptune es un servicio de base de datos de gráficos rápido, confiable y totalmente administrado que simplifica la creación y ejecución de aplicaciones que funcionan con conjuntos de datos altamente conectados. Amazon Bedrock es un servicio totalmente administrado que ofrece una selección de modelos básicos (FM) de alto rendimiento de empresas líderes en inteligencia artificial como AI21 Labs, Anthropic, Cohere, Meta, Stability AI y Amazon a través de una única API, junto con un amplio conjunto de capacidades para crear aplicaciones de IA generativa con seguridad, privacidad e IA responsable.
En general, este prototipo demuestra el arte de lo posible con gráficos de conocimiento e IA generativa: derivar señales conectando puntos dispares. Lo que los profesionales de la inversión deben aprender es la capacidad de mantenerse al tanto de los acontecimientos más cercanos a la señal y, al mismo tiempo, evitar el ruido.
Construya el gráfico de conocimiento
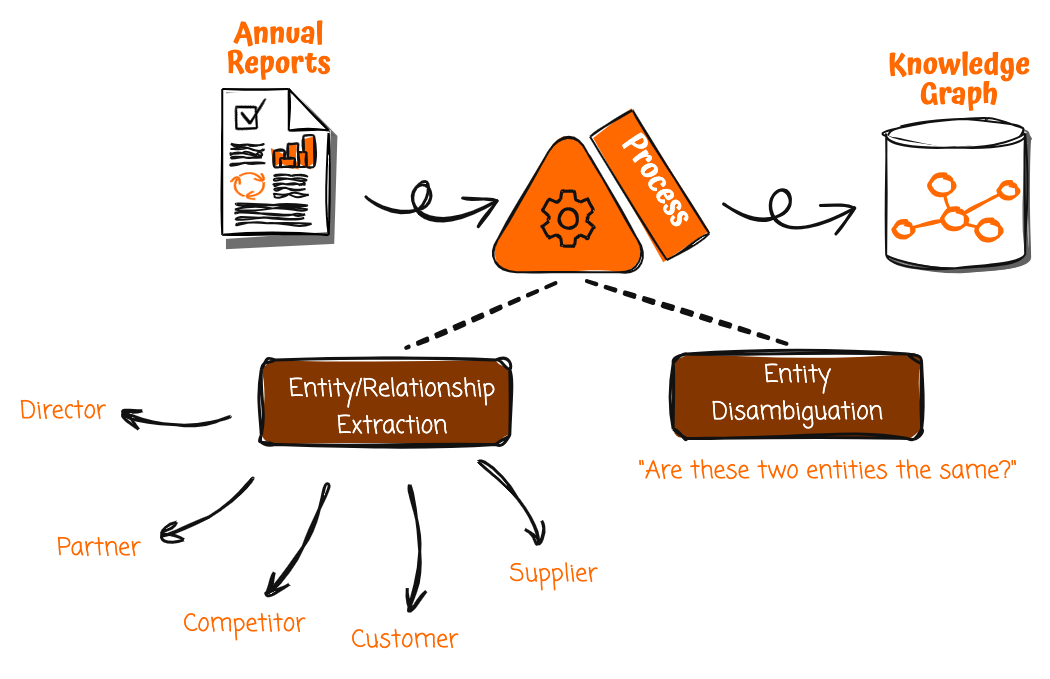
El primer paso de esta solución es crear un gráfico de conocimiento, y una fuente de datos valiosa, aunque a menudo pasada por alto, para los gráficos de conocimiento son los informes anuales de la empresa. Debido a que las publicaciones corporativas oficiales se someten a un escrutinio antes de su publicación, es probable que la información que contienen sea precisa y confiable. Sin embargo, los informes anuales están escritos en un formato no estructurado destinado a la lectura humana y no al consumo automático. Para desbloquear su potencial, se necesita una forma de extraer y estructurar sistemáticamente la riqueza de hechos y relaciones que contienen.
Con servicios de IA generativa como Amazon Bedrock, ahora tiene la capacidad de automatizar este proceso. Puede tomar un informe anual y activar un proceso de procesamiento para ingerir el informe, dividirlo en partes más pequeñas y aplicar la comprensión del lenguaje natural para extraer entidades y relaciones destacadas.
Por ejemplo, una frase que indique que “[Empresa A] amplió su flota de reparto eléctrica europea con un pedido de 1,800 furgonetas eléctricas de [Empresa B]” permitiría a Amazon Bedrock identificar lo siguiente:
- [Empresa A] como cliente
- [Empresa B] como proveedor
- Una relación de proveedor entre [Empresa A] y [Empresa B]
- Detalles de relación de “proveedor de furgonetas de reparto eléctricas”
Para extraer dichos datos estructurados de documentos no estructurados es necesario proporcionar indicaciones cuidadosamente diseñadas a grandes modelos de lenguaje (LLM) para que puedan analizar texto y extraer entidades como empresas y personas, así como relaciones como clientes, proveedores y más. Las indicaciones contienen instrucciones claras sobre qué buscar y la estructura en la que devolver los datos. Al repetir este proceso en todo el informe anual, puede extraer las entidades y relaciones relevantes para construir un gráfico de conocimiento rico.
Sin embargo, antes de enviar la información extraída al gráfico de conocimiento, primero debe eliminar la ambigüedad de las entidades. Por ejemplo, es posible que ya exista otra entidad '[Empresa A]' en el gráfico de conocimiento, pero podría representar una organización diferente con el mismo nombre. Amazon Bedrock puede razonar y comparar atributos como el área de enfoque comercial, la industria y las industrias generadoras de ingresos y las relaciones con otras entidades para determinar si las dos entidades son realmente distintas. Esto evita fusionar de manera inexacta empresas no relacionadas en una sola entidad.
Una vez completada la desambiguación, puede agregar de manera confiable nuevas entidades y relaciones a su gráfico de conocimiento de Neptune, enriqueciéndolo con los datos extraídos de los informes anuales. Con el tiempo, la ingesta de datos confiables y la integración de fuentes de datos más confiables ayudarán a construir un gráfico de conocimiento integral que pueda respaldar la revelación de conocimientos a través de consultas y análisis de gráficos.
Esta automatización habilitada por la IA generativa hace posible procesar miles de informes anuales y desbloquea un activo invaluable para la curación de gráficos de conocimiento que de otro modo no se aprovecharía debido al esfuerzo manual prohibitivamente alto necesario.
La siguiente captura de pantalla muestra un ejemplo de la exploración visual que es posible en una base de datos de gráficos de Neptune utilizando el Explorador de gráficos .

Procesar artículos de noticias.

El siguiente paso de la solución es enriquecer automáticamente las noticias de los gestores de cartera y resaltar artículos relevantes para sus intereses e inversiones. Para el servicio de noticias, los gestores de carteras pueden suscribirse a cualquier proveedor de noticias externo a través de Intercambio de datos de AWS u otra API de noticias de su elección.
Cuando un artículo de noticias ingresa al sistema, se invoca un canal de ingesta para procesar el contenido. Utilizando técnicas similares al procesamiento de informes anuales, Amazon Bedrock se utiliza para extraer entidades, atributos y relaciones del artículo de noticias, que luego se utilizan para eliminar la ambigüedad del gráfico de conocimiento para identificar la entidad correspondiente en el gráfico de conocimiento.
El gráfico de conocimiento contiene conexiones entre empresas y personas, y al vincular entidades de artículos a nodos existentes, puede identificar si algún sujeto está a dos saltos de las empresas en las que el administrador de cartera ha invertido o en las que está interesado. Encontrar dicha conexión indica el El artículo puede ser relevante para el administrador de cartera y, debido a que los datos subyacentes están representados en un gráfico de conocimiento, se puede visualizar para ayudar al administrador de cartera a comprender por qué y cómo este contexto es relevante. Además de identificar conexiones con la cartera, también puede utilizar Amazon Bedrock para realizar análisis de opinión sobre las entidades a las que se hace referencia.
El resultado final es una fuente de noticias enriquecida que muestra artículos que probablemente afectarán las áreas de interés e inversiones del administrador de cartera.
Resumen de la solución
La arquitectura general de la solución se parece al siguiente diagrama.

El flujo de trabajo consta de los siguientes pasos:
- Un usuario carga informes oficiales (en formato PDF) a un Servicio de almacenamiento simple de Amazon (Amazon S3) cubo. Los informes deben ser informes publicados oficialmente para minimizar la inclusión de datos inexactos en su gráfico de conocimiento (a diferencia de noticias y tabloides).
- La notificación de evento S3 invoca una AWS Lambda función, que envía el depósito S3 y el nombre del archivo a un Servicio de cola simple de Amazon (Amazon SQS) cola. La cola Primero en entrar, primero en salir (FIFO) garantiza que el proceso de ingesta de informes se realice de forma secuencial para reducir la probabilidad de introducir datos duplicados en su gráfico de conocimiento.
- An Puente de eventos de Amazon El evento basado en tiempo se ejecuta cada minuto para iniciar la ejecución de un Funciones de paso de AWS máquina de estados de forma asincrónica.
- La máquina de estado de Step Functions ejecuta una serie de tareas para procesar el documento cargado extrayendo información clave e insertándola en su gráfico de conocimiento:
- Reciba el mensaje de cola de Amazon SQS.
- Descargue el archivo de informe PDF de Amazon S3, divídalo en varios fragmentos de texto más pequeños (aproximadamente 1,000 palabras) para procesarlos y almacene los fragmentos de texto en Amazon DynamoDB.
- Utilice Claude v3 Sonnet de Anthropic en Amazon Bedrock para procesar los primeros fragmentos de texto para determinar la entidad principal a la que se refiere el informe, junto con los atributos relevantes (como la industria).
- Recupere los fragmentos de texto de DynamoDB y, para cada fragmento de texto, invoque una función Lambda para extraer entidades (como una empresa o una persona) y su relación (cliente, proveedor, socio, competidor o director) con la entidad principal mediante Amazon Bedrock. .
- Consolidar toda la información extraída.
- Filtre el ruido y las entidades irrelevantes (por ejemplo, términos genéricos como "consumidores") utilizando Amazon Bedrock.
- Utilice Amazon Bedrock para realizar la desambiguación razonando utilizando la información extraída en comparación con la lista de entidades similares del gráfico de conocimiento. Si la entidad no existe, insértela. De lo contrario, utilice la entidad que ya existe en el gráfico de conocimiento. Inserte todas las relaciones extraídas.
- Limpie eliminando el mensaje de la cola SQS y el archivo S3.
- Un usuario accede a una aplicación web basada en React para ver los artículos de noticias que se complementan con información sobre la entidad, el sentimiento y la ruta de conexión.
- Al utilizar la aplicación web, el usuario especifica el número de saltos (predeterminado N=2) en la ruta de conexión a monitorear.
- Utilizando la aplicación web, el usuario especifica la lista de entidades a rastrear.
- Para generar noticias ficticias, el usuario elige Generar noticias de muestra para generar 10 artículos de noticias financieras de muestra con contenido aleatorio para incluirlos en el proceso de ingesta de noticias. El contenido se genera utilizando Amazon Bedrock y es puramente ficticio.
- Para descargar noticias actuales, el usuario elige Descargar Últimas Noticias para descargar las principales noticias de hoy (con tecnología de NewsAPI.org).
- El archivo de noticias (formato TXT) se carga en un depósito S3. Los pasos 8 y 9 cargan noticias en el depósito S3 automáticamente, pero también puede crear integraciones con su proveedor de noticias preferido, como AWS Data Exchange o cualquier proveedor de noticias externo, para colocar artículos de noticias como archivos en el depósito S3. El contenido del archivo de datos de noticias debe tener el formato
<date>{dd mmm yyyy}</date><title>{title}</title><text>{news content}</text>. - La notificación de eventos de S3 envía el nombre del archivo o depósito de S3 a Amazon SQS (estándar), que invoca múltiples funciones Lambda para procesar los datos de noticias en paralelo:
- Utilice Amazon Bedrock para extraer entidades mencionadas en las noticias junto con cualquier información, relaciones y sentimientos relacionados con la entidad mencionada.
- Verifique el gráfico de conocimiento y utilice Amazon Bedrock para realizar la desambiguación mediante el razonamiento utilizando la información disponible en las noticias y dentro del gráfico de conocimiento para identificar la entidad correspondiente.
- Una vez localizada la entidad, busque y devuelva cualquier ruta de conexión que conecte con las entidades marcadas con
INTERESTED=YESen el gráfico de conocimiento que están dentro de N = 2 saltos de distancia.
- La aplicación web se actualiza automáticamente cada segundo para extraer el último conjunto de noticias procesadas y mostrarlas en la aplicación web.
Implementar el prototipo
Puede implementar la solución prototipo y comenzar a experimentar usted mismo. El prototipo está disponible en GitHub e incluye detalles sobre lo siguiente:
- Requisitos previos de implementación
- Pasos de implementación
- Pasos de limpieza
Resumen
Esta publicación demostró una solución de prueba de concepto para ayudar a los administradores de carteras a detectar riesgos de segundo y tercer orden de eventos noticiosos, sin referencias directas a las empresas que rastrean. Al combinar un gráfico de conocimiento de las complejas relaciones de la empresa con un análisis de noticias en tiempo real utilizando IA generativa, se pueden resaltar los impactos posteriores, como los retrasos en la producción debido a problemas con los proveedores.
Aunque es sólo un prototipo, esta solución muestra la promesa de gráficos de conocimiento y modelos de lenguaje para conectar puntos y derivar señales a partir del ruido. Estas tecnologías pueden ayudar a los profesionales de la inversión al revelar riesgos más rápidamente a través de mapeos y razonamientos de relaciones. En general, se trata de una aplicación prometedora de bases de datos gráficas e inteligencia artificial que justifica su exploración para aumentar el análisis de inversiones y la toma de decisiones.
Si este ejemplo de IA generativa en servicios financieros es de interés para su negocio, o tiene una idea similar, comuníquese con su gerente de cuentas de AWS y estaremos encantados de explorar más a fondo con usted.
Sobre la autora
 Xan Huang es arquitecto senior de soluciones en AWS y tiene su sede en Singapur. Trabaja con las principales instituciones financieras para diseñar y crear soluciones seguras, escalables y de alta disponibilidad en la nube. Fuera del trabajo, Xan pasa la mayor parte de su tiempo libre con su familia y recibiendo órdenes de su hija de 3 años. Puedes encontrar a Xan en Etiqueta LinkedIn.
Xan Huang es arquitecto senior de soluciones en AWS y tiene su sede en Singapur. Trabaja con las principales instituciones financieras para diseñar y crear soluciones seguras, escalables y de alta disponibilidad en la nube. Fuera del trabajo, Xan pasa la mayor parte de su tiempo libre con su familia y recibiendo órdenes de su hija de 3 años. Puedes encontrar a Xan en Etiqueta LinkedIn.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/machine-learning/uncover-hidden-connections-in-unstructured-financial-data-with-amazon-bedrock-and-amazon-neptune/