
Introducción
Machine Learning (ML) es un campo de estudio que se enfoca en desarrollar algoritmos para aprender automáticamente de los datos, hacer predicciones e inferir patrones sin que se le indique explícitamente cómo hacerlo. Su objetivo es crear sistemas que mejoren automáticamente con la experiencia y los datos.
Esto se puede lograr a través del aprendizaje supervisado, en el que el modelo se entrena utilizando datos etiquetados para hacer predicciones, o mediante el aprendizaje no supervisado, en el que el modelo busca descubrir patrones o correlaciones dentro de los datos sin objetivos específicos que anticipar.
ML se ha convertido en una herramienta indispensable y ampliamente utilizada en varias disciplinas, incluidas la informática, la biología, las finanzas y el marketing. Ha demostrado su utilidad en diversas aplicaciones como clasificación de imágenes, procesamiento de lenguaje natural y detección de fraude.
Tareas de aprendizaje automático
El aprendizaje automático se puede clasificar en términos generales en tres tareas principales:
- Aprendizaje supervisado
- Aprendizaje sin supervisión
- Aprendizaje reforzado
Aquí nos centraremos en los dos primeros casos.
Aprendizaje supervisado
El aprendizaje supervisado implica entrenar un modelo con datos etiquetados, donde los datos de entrada se emparejan con la variable objetivo o de salida correspondiente. El objetivo es aprender una función que pueda asignar datos de entrada a la salida correcta. Los algoritmos comunes de aprendizaje supervisado incluyen regresión lineal, regresión logística, árboles de decisión y máquinas de vectores de soporte.
Ejemplo de código de aprendizaje supervisado usando Python:
from sklearn.linear_model import LinearRegression model = LinearRegression() model.fit(X_train, y_train) predictions = model.predict(X_test)
En este ejemplo de código simple, entrenamos el LinearRegression algoritmo de scikit-learn en nuestros datos de entrenamiento y luego aplicarlo para obtener predicciones para nuestros datos de prueba.
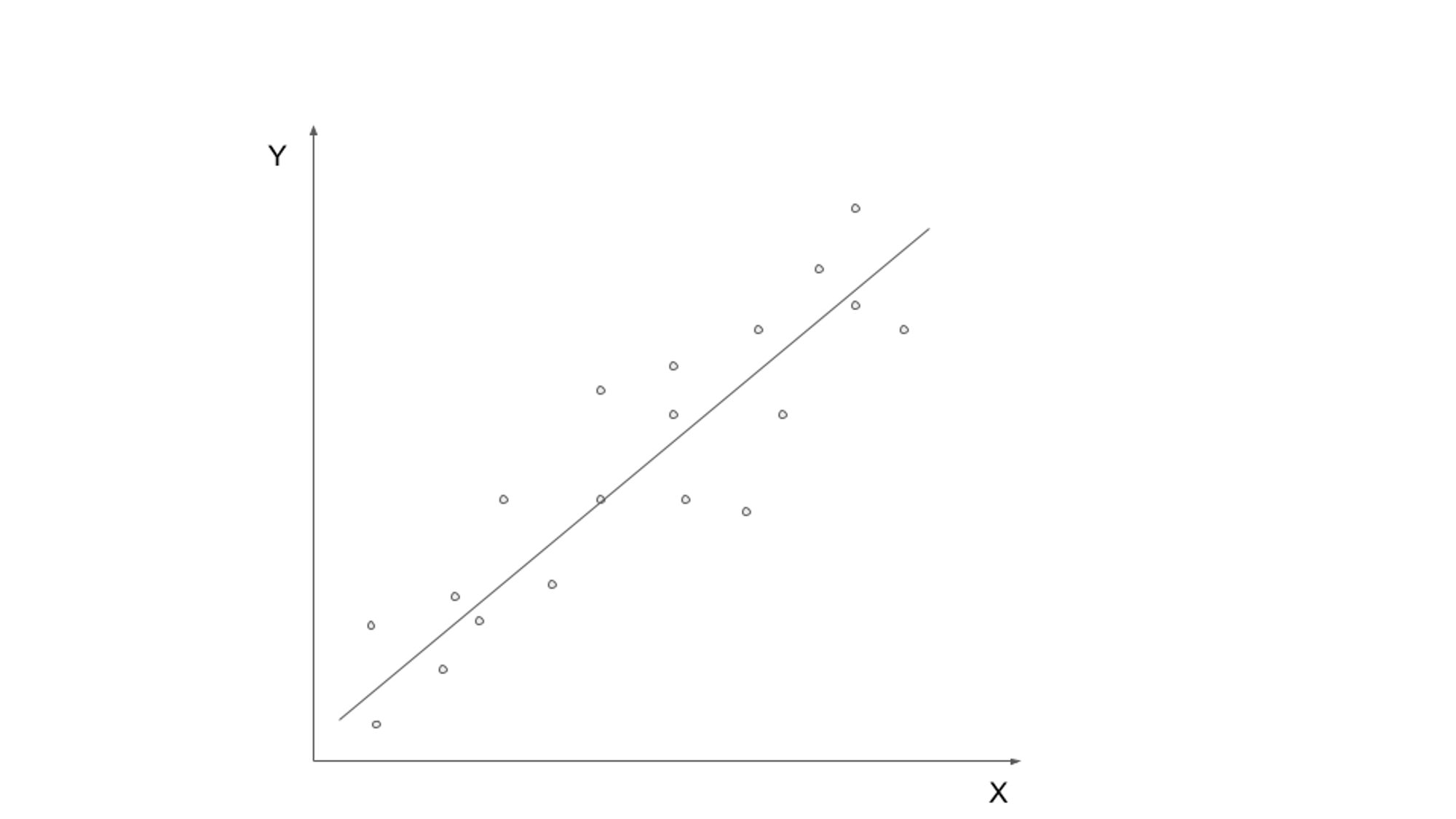
Un caso de uso real del aprendizaje supervisado es la clasificación de correo no deseado. Con el crecimiento exponencial de la comunicación por correo electrónico, identificar y filtrar correos electrónicos no deseados se ha vuelto crucial. Mediante el uso de algoritmos de aprendizaje supervisado, es posible entrenar un modelo para distinguir entre correos electrónicos legítimos y spam en función de los datos etiquetados.
El modelo de aprendizaje supervisado se puede entrenar en un conjunto de datos que contiene correos electrónicos etiquetados como "spam" o "no spam". El modelo aprende patrones y características de los datos etiquetados, como la presencia de ciertas palabras clave, la estructura del correo electrónico o la información del remitente del correo electrónico. Una vez que se entrena el modelo, se puede usar para clasificar automáticamente los correos electrónicos entrantes como spam o no spam, filtrando de manera eficiente los mensajes no deseados.
Aprendizaje sin supervisión
En el aprendizaje no supervisado, los datos de entrada no están etiquetados y el objetivo es descubrir patrones o estructuras dentro de los datos. Los algoritmos de aprendizaje no supervisados tienen como objetivo encontrar representaciones significativas o grupos en los datos.
Los ejemplos de algoritmos de aprendizaje no supervisados incluyen k-significa agrupamiento, agrupación jerárquicay análisis de componentes principales (PCA).
Ejemplo de código de aprendizaje no supervisado:
from sklearn.cluster import KMeans model = KMeans(n_clusters=3) model.fit(X) predictions = model.predict(X_new)
En este ejemplo de código simple, entrenamos el KMeans algoritmo de scikit-learn para identificar tres grupos en nuestros datos y luego ajustar nuevos datos en esos grupos.
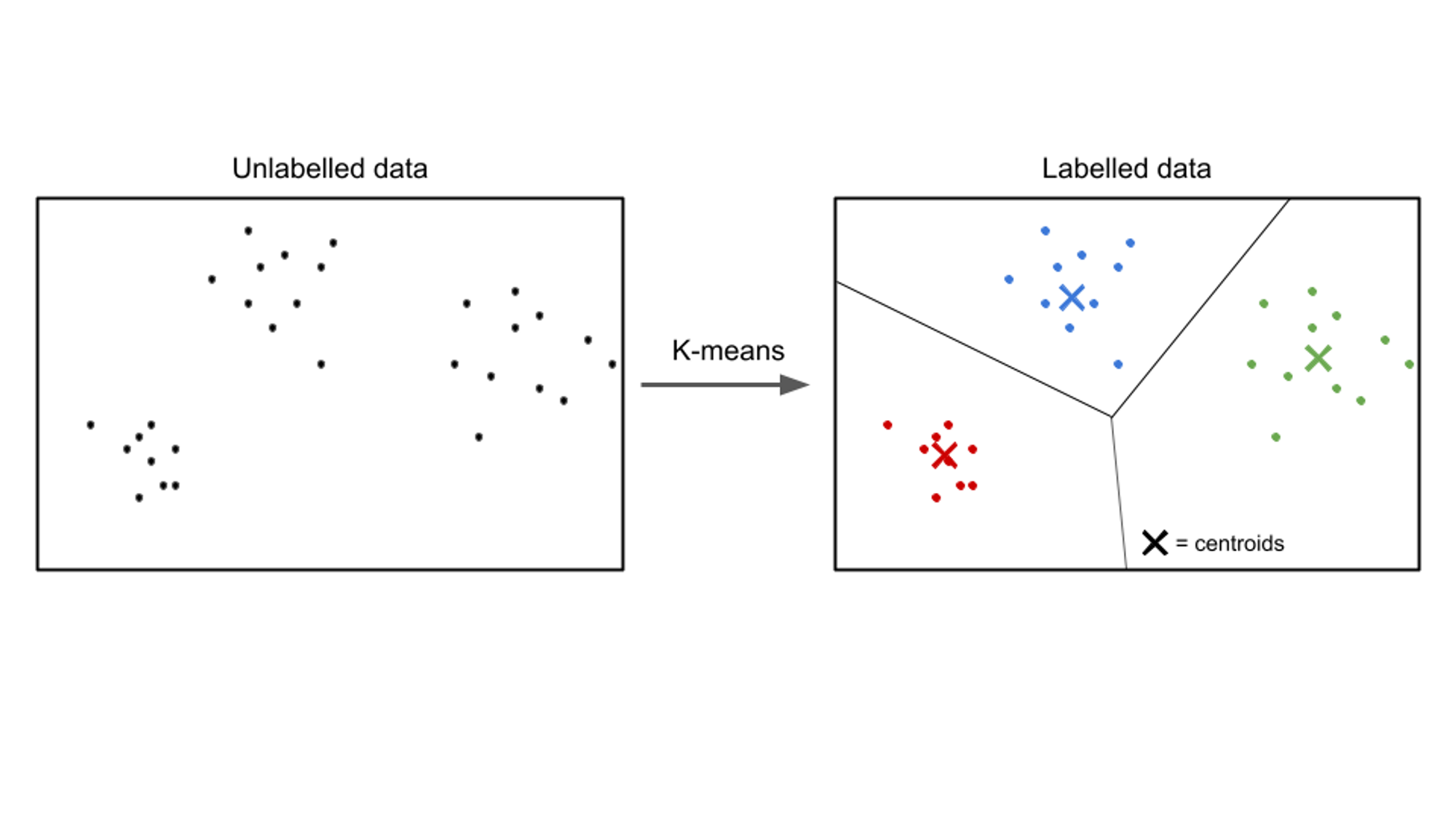
Un ejemplo de un caso de uso de aprendizaje no supervisado es la segmentación de clientes. En varias industrias, las empresas buscan comprender mejor su base de clientes para adaptar sus estrategias de marketing, personalizar sus ofertas y optimizar las experiencias de los clientes. Los algoritmos de aprendizaje no supervisados se pueden emplear para segmentar a los clientes en distintos grupos en función de sus características y comportamientos compartidos.
Consulte nuestra guía práctica y práctica para aprender Git, con las mejores prácticas, los estándares aceptados por la industria y la hoja de trucos incluida. Deja de buscar en Google los comandos de Git y, de hecho, aprenden ella!
Al aplicar técnicas de aprendizaje no supervisado, como la agrupación en clústeres, las empresas pueden descubrir patrones y grupos significativos dentro de los datos de sus clientes. Por ejemplo, los algoritmos de agrupamiento pueden identificar grupos de clientes con hábitos de compra, datos demográficos o preferencias similares. Esta información se puede aprovechar para crear campañas de marketing dirigidas, optimizar las recomendaciones de productos y mejorar la satisfacción del cliente.
Principales clases de algoritmos
Algoritmos de aprendizaje supervisado
-
Modelos lineales: se utilizan para predecir variables continuas en función de las relaciones lineales entre las características y la variable de destino.
-
Modelos basados en árboles: Construidos usando una serie de decisiones binarias para hacer predicciones o clasificaciones.
-
Modelos de conjunto: método que combina múltiples modelos (basados en árboles o lineales) para hacer predicciones más precisas.
-
Modelos de Redes Neuronales: Métodos vagamente basados en el cerebro humano, donde múltiples funciones funcionan como nodos de una red.
Algoritmos de aprendizaje no supervisados
-
Agrupamiento jerárquico: crea una jerarquía de clústeres fusionándolos o dividiéndolos iterativamente.
-
Agrupación en clústeres no jerárquica: divide los datos en clústeres distintos en función de la similitud.
-
Reducción de la dimensionalidad: reduce la dimensionalidad de los datos al tiempo que conserva la información más importante.
Evaluación del modelo
Aprendizaje supervisado
Para evaluar el desempeño de los modelos de aprendizaje supervisado, se utilizan varias métricas, que incluyen exactitud, precisión, recuperación, puntaje F1 y ROC-AUC. Las técnicas de validación cruzada, como la validación cruzada k-fold, pueden ayudar a estimar el rendimiento de generalización del modelo.
Aprendizaje sin supervisión
La evaluación de algoritmos de aprendizaje no supervisados suele ser más desafiante, ya que no existe una realidad fundamental. Se pueden utilizar métricas como la puntuación de la silueta o la inercia para evaluar la calidad de los resultados de la agrupación. Las técnicas de visualización también pueden proporcionar información sobre la estructura de los clústeres.
Consejos y trucos
Aprendizaje supervisado
- Preprocesar y normalizar los datos de entrada para mejorar el rendimiento del modelo.
- Manejar los valores faltantes de manera adecuada, ya sea por imputación o eliminación.
- La ingeniería de características puede mejorar la capacidad del modelo para capturar patrones relevantes.
Aprendizaje sin supervisión
- Elija el número apropiado de clústeres en función del conocimiento del dominio o utilizando técnicas como el método del codo.
- Considere diferentes métricas de distancia para medir la similitud entre los puntos de datos.
- Regularice el proceso de agrupación para evitar el sobreajuste.
En resumen, el aprendizaje automático implica numerosas tareas, técnicas, algoritmos, métodos de evaluación de modelos y sugerencias útiles. Al comprender estos aspectos, los profesionales pueden aplicar de manera eficiente el aprendizaje automático a problemas del mundo real y obtener conocimientos significativos de los datos. Los ejemplos de código dados muestran la utilización de algoritmos de aprendizaje supervisados y no supervisados, destacando su implementación práctica.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- EVM Finanzas. Interfaz unificada para finanzas descentralizadas. Accede Aquí.
- Grupo de medios cuánticos. IR/PR amplificado. Accede Aquí.
- PlatoAiStream. Inteligencia de datos Web3. Conocimiento amplificado. Accede Aquí.
- Fuente: https://stackabuse.com/supervised-learning-vs-unsupervised-learning-algorithms/