
A partir de la versión 6.14, Estudio de Amazon EMR admite análisis interactivos en Amazon EMR sin servidor. Ahora puede utilizar aplicaciones EMR Serverless como proceso, además de Amazon EMR en clústeres EC2 y Amazon EMR en EKS clústeres virtuales, para ejecutar cuadernos de JupyterLab desde EMR Studio Workspaces.
EMR Studio es un entorno de desarrollo integrado (IDE) que facilita a los científicos e ingenieros de datos desarrollar, visualizar y depurar aplicaciones de análisis escritas en PySpark, Python y Scala. EMR Serverless es una opción sin servidor para EMR de Amazon eso hace que sea sencillo ejecutar marcos de análisis de big data de código abierto, como Apache Spark, sin configurar, administrar y escalar clústeres o servidores.
En la publicación, demostramos cómo hacer lo siguiente:
- Cree un punto final EMR Serverless para aplicaciones interactivas
- Adjunte el punto final a un entorno de EMR Studio existente
- Cree un cuaderno y ejecute una aplicación interactiva
- Diagnostique sin problemas aplicaciones interactivas desde EMR Studio
Requisitos previos
En una organización típica, un administrador de cuentas de AWS configurará recursos de AWS como Gestión de identidades y accesos de AWS (IAM) roles, Servicio de almacenamiento simple de Amazon (Amazon S3) cubos y Nube privada virtual de Amazon (Amazon VPC) para acceso a Internet y acceso a otros recursos en la VPC. Asignan administradores de EMR Studio que gestionan la configuración de EMR Studios y la asignación de usuarios a un EMR Studio específico. Una vez asignados, los desarrolladores de EMR Studio pueden utilizar EMR Studio para desarrollar y monitorear cargas de trabajo.
Asegúrese de configurar recursos como su depósito S3, subredes de VPC y EMR Studio en la misma región de AWS.
Complete los siguientes pasos para implementar estos requisitos previos:
- Lanzar lo siguiente Formación en la nube de AWS asociación.

- Ingrese valores para Clave de administrador y Contraseña de desarrollo y tome nota de las contraseñas que cree.
- Elige Siguiente.
- Mantenga la configuración predeterminada y elija Siguiente de nuevo.
- Seleccione Reconozco que AWS CloudFormation podría crear recursos de IAM con nombres personalizados.
- Elija Enviar.
También proporcionamos instrucciones para implementar estos recursos manualmente con políticas de IAM de muestra en el Repositorio GitHub.
Configure EMR Studio y una aplicación interactiva sin servidor
Después de que el administrador de la cuenta de AWS complete los requisitos previos, el administrador de EMR Studio puede iniciar sesión en Consola de administración de AWS para crear una aplicación EMR Studio, Workspace y EMR Serverless.
Crear un estudio y espacio de trabajo EMR
El administrador de EMR Studio debe iniciar sesión en la consola utilizando el emrs-interactive-app-admin-user credenciales de usuario. Si implementó los recursos de requisitos previos utilizando la plantilla de CloudFormation proporcionada, use la contraseña que proporcionó como parámetro de entrada.
- En la consola de Amazon EMR, elija EMR sin servidor en el panel de navegación.

- Elige ¡Empieza aquí!.
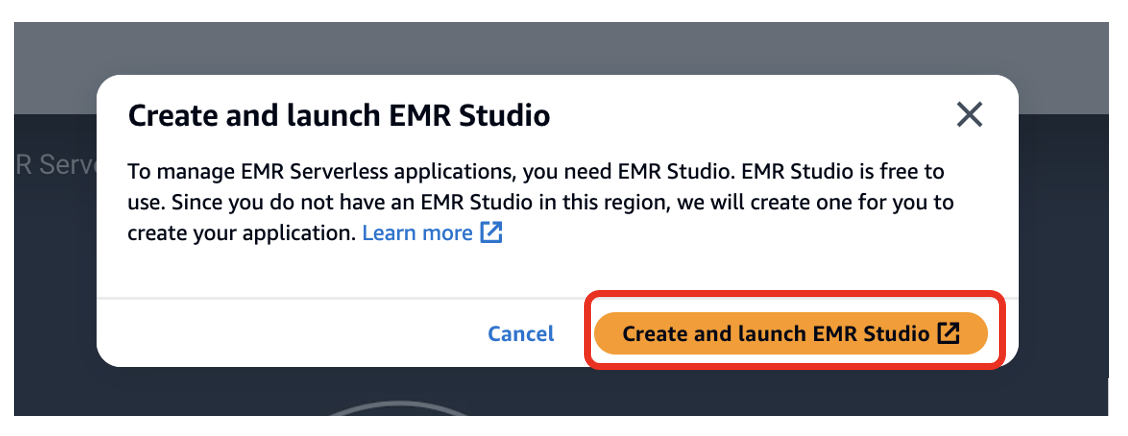
- Seleccione Crear y ejecutar EMR Studio.
Esto crea un estudio con el nombre predeterminado. studio_1 y un espacio de trabajo con el nombre predeterminado My_First_Workspace. Se abrirá una nueva pestaña del navegador para Studio_1 interfaz de usuario.
Cree una aplicación EMR sin servidor
Complete los siguientes pasos para crear una aplicación EMR Serverless:
- En la consola de EMR Studio, elija Aplicaciones en el panel de navegación.
- Crear una nueva aplicación.
- Nombre, ingrese un nombre (por ejemplo,
my-serverless-interactive-application). - Opciones de configuración de la aplicación, seleccione Usar configuraciones personalizadas para cargas de trabajo interactivas.
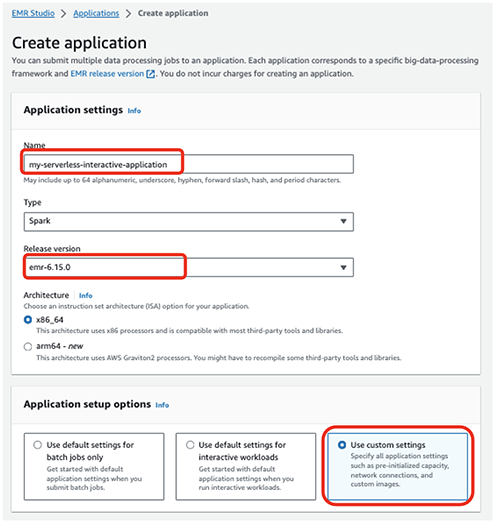
Para aplicaciones interactivas, como práctica recomendada, recomendamos mantener el controlador y los trabajadores preinicializados configurando el capacidad preiniciada en el momento de la creación de la aplicación. Esto crea efectivamente un grupo cálido de trabajadores para una aplicación y mantiene los recursos listos para ser consumidos, lo que permite que la aplicación responda en segundos. Para conocer más prácticas recomendadas para crear aplicaciones EMR Serverless, consulte Defina límites de recursos por equipo para cargas de trabajo de big data mediante Amazon EMR Serverless.
- En Punto final interactivo sección, seleccionar Habilitar punto final interactivo.
- En Conexiones de red , elija la VPC, las subredes privadas y el grupo de seguridad que creó anteriormente.
Si implementó la pila de CloudFormation proporcionada en esta publicación, elija emr-serverless-sg como grupo de seguridad.
Se necesita una VPC para que la carga de trabajo pueda acceder a Internet desde la aplicación EMR Serverless para descargar paquetes externos de Python. La VPC también le permite acceder a recursos como Servicio de base de datos relacional de Amazon (Amazon RDS) y Desplazamiento al rojo de Amazon que están en la VPC de esta aplicación. Adjuntar una aplicación sin servidor a una VPC puede provocar el agotamiento de la IP en la subred, así que asegúrese de que haya suficientes direcciones IP en su subred.
- Elige Crear e iniciar la aplicación.

En la página de aplicaciones, puede verificar que el estado de su aplicación sin servidor cambie a empezar?.
- Selecciona tu aplicación y elige Cómo funciona.
- Elige Ver e iniciar espacios de trabajo.
- Elige Configurar estudio.

- Rol de servicio¸ proporcione la función de servicio EMR Studio que creó como requisito previo (
emr-studio-service-role). - Almacenamiento del espacio de trabajo, ingrese la ruta del depósito S3 que creó como requisito previo (
emrserverless-interactive-blog-<account-id>-<region-name>). - Elige Guardar los cambios.
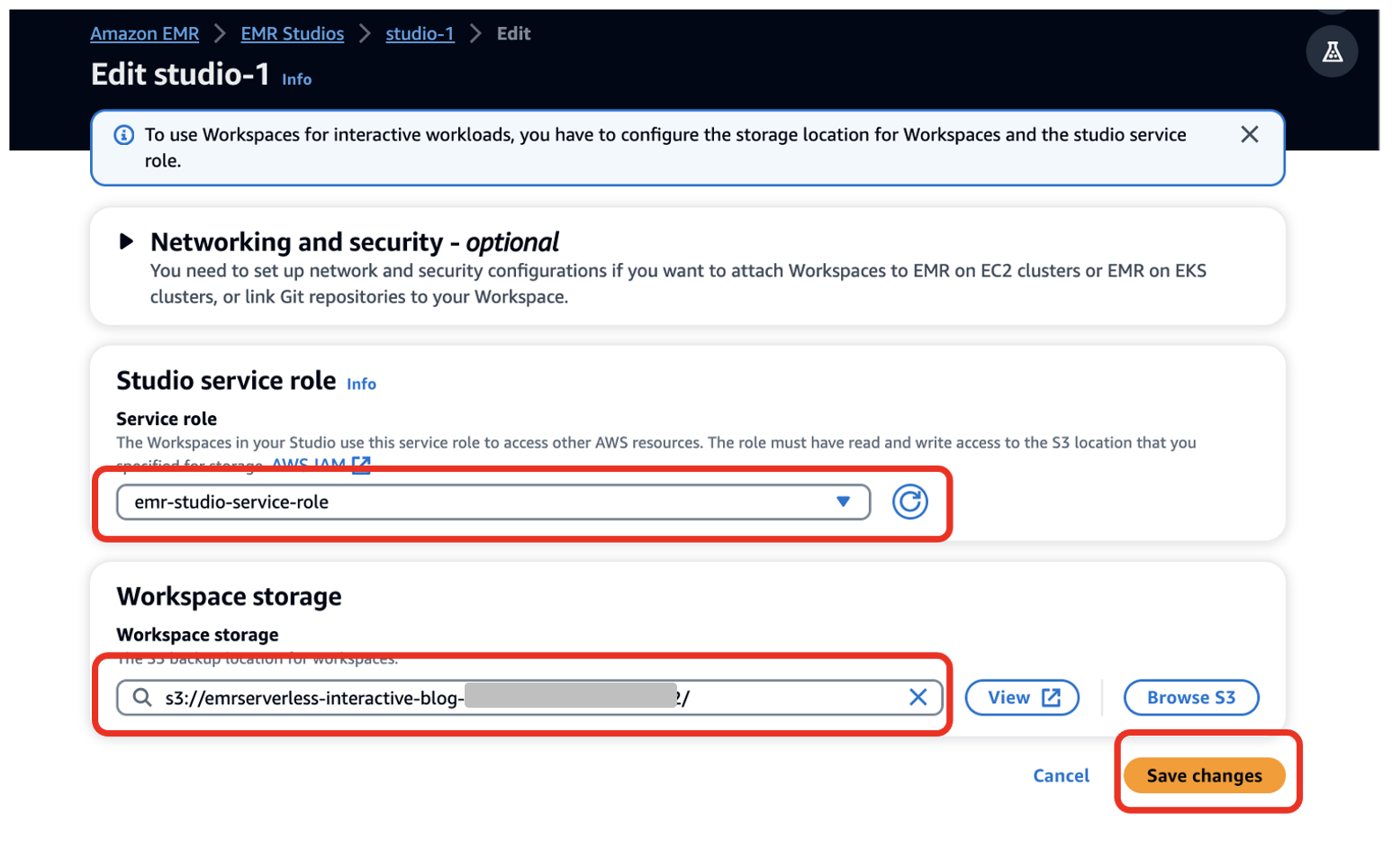
14. Navegue a la consola de Studios eligiendo Estudios en el menú de navegación izquierdo en el Estudio EMR sección. Nota la URL de acceso al estudio desde la consola de Studios y proporcionárselo a sus desarrolladores para ejecutar sus aplicaciones Spark.
Ejecute su primera aplicación Spark
Después de que el administrador de EMR Studio haya creado Studio, el espacio de trabajo y la aplicación sin servidor, el usuario de Studio puede usar el espacio de trabajo y la aplicación para desarrollar y monitorear cargas de trabajo de Spark.
Inicie el espacio de trabajo y adjunte la aplicación sin servidor
Complete los siguientes pasos:
- Usando la URL de Studio proporcionada por el administrador de EMR Studio, inicie sesión usando el
emrs-interactive-app-dev-userCredenciales de usuario compartidas por el administrador de la cuenta de AWS.
Si implementó los recursos de requisitos previos utilizando la plantilla de CloudFormation proporcionada, use la contraseña que proporcionó como parámetro de entrada.
En Espacios de trabajo página, puede verificar el estado de su espacio de trabajo. Cuando se inicia el espacio de trabajo, verá que el estado cambia a En Sus Marcas.
- Inicie el espacio de trabajo eligiendo el nombre del espacio de trabajo (
My_First_Workspace).
Esto abrirá una nueva pestaña. Asegúrese de que su navegador permita ventanas emergentes.
- En el espacio de trabajo, elija Calcular (icono de grupo) en el panel de navegación.
- Aplicación EMR sin servidor, elige tu aplicación (
my-serverless-interactive-application). - Rol de tiempo de ejecución interactivo, elija una función de tiempo de ejecución interactiva (para esta publicación, usamos
emr-serverless-runtime-role). - Elige Adjuntar para adjuntar la aplicación sin servidor como tipo de proceso para todos los portátiles en este espacio de trabajo.

Ejecute su aplicación Spark de forma interactiva
Complete los siguientes pasos:
- Elija el Muestras de cuadernos (icono de tres puntos) en el panel de navegación y abra
Getting-started-with-emr-serverlesscuaderno. - Elige Guardar en el espacio de trabajo.
Hay tres opciones de kernels para nuestro portátil: Python 3, PySpark y Spark (para Scala).
- Cuando se le solicite, elija PySpark como el kernel.
- Elige Seleccione.

Ahora puedes ejecutar tu aplicación Spark. Para ello, utilice el %%configure chispamagia comando, que configura los parámetros de creación de sesión. Las aplicaciones interactivas admiten entornos virtuales Python. Usamos un entorno personalizado en los nodos trabajadores especificando una ruta para un tiempo de ejecución de Python diferente para el entorno ejecutor usando spark.executorEnv.PYSPARK_PYTHON. Ver el siguiente código:
Instalar paquetes externos
Ahora que tiene un entorno virtual independiente para los trabajadores, los portátiles de EMR Studio le permiten instalar paquetes externos desde la aplicación sin servidor mediante Spark. install_pypi_package funcionar a través del contexto Spark. El uso de esta función hace que el paquete esté disponible para todos los trabajadores de EMR Serverless.
Primero, instale matplotlib, un paquete de Python, desde PyPi:
Si el paso anterior no responde, verifique la configuración de su VPC y asegúrese de que esté configurada correctamente para el acceso a Internet.
Ahora puede utilizar un conjunto de datos y visualizar sus datos.
Crear visualizaciones
Para crear visualizaciones, utilizamos un conjunto de datos públicos sobre los taxis amarillos de Nueva York:
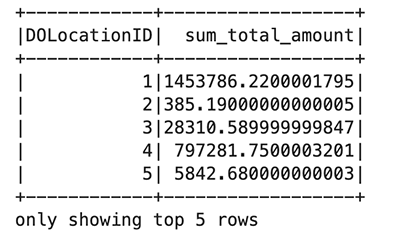
En el bloque de código anterior, leyó el archivo Parquet desde un depósito público en Amazon S3. El archivo tiene encabezados y queremos que Spark infiera el esquema. Luego usa un marco de datos de Spark para agrupar y contar columnas específicas de taxi_df:
Uso %%display magia para ver el resultado en formato de tabla:

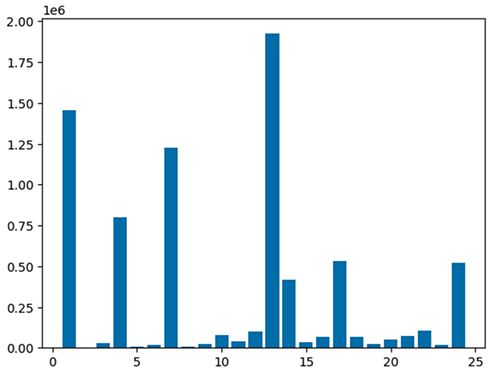
También puede visualizar rápidamente sus datos con cinco tipos de gráficos. Puede elegir el tipo de visualización y el gráfico cambiará en consecuencia. En la siguiente captura de pantalla, utilizamos un gráfico de barras para visualizar nuestros datos.

Interactuar con EMR Serverless usando Spark SQL
Puedes interactuar con las tablas en el Catálogo de datos de AWS Glue usando Spark SQL en EMR Serverless. En el cuaderno de muestra, mostramos cómo se pueden transformar datos utilizando un marco de datos de Spark.
Primero, cree una nueva vista temporal llamada taxis. Esto le permite utilizar Spark SQL para seleccionar datos de esta vista. Luego cree un marco de datos de taxi para su posterior procesamiento:
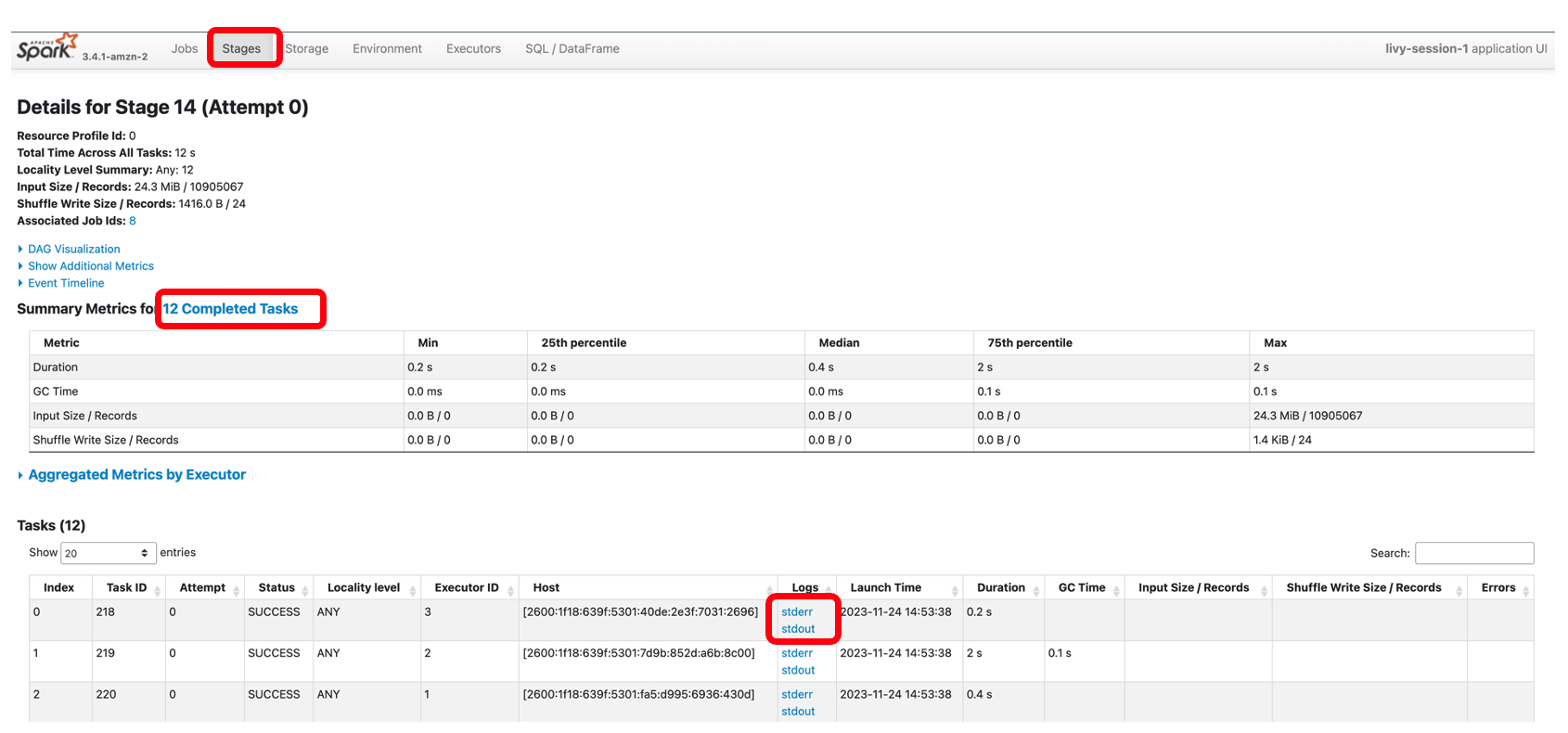
En cada celda de su cuaderno de EMR Studio, puede expandir Progreso del trabajo de Spark para ver las distintas etapas del trabajo enviado a EMR Serverless mientras se ejecuta esta celda específica. Puedes ver el tiempo necesario para completar cada etapa. En el siguiente ejemplo, la etapa 14 del trabajo tiene 12 tareas completadas. Además, si hay algún error, puede ver los registros, lo que hace que la resolución de problemas sea una experiencia perfecta. Hablaremos de esto más en la siguiente sección.
![Trabajo[14]: showString en NativeMethodAccessorImpl.java:0 y Trabajo[15]: showString en NativeMethodAccessorImpl.java:0](https://xlera8.com/wp-content/uploads/2024/04/run-interactive-workloads-on-amazon-emr-serverless-from-amazon-emr-studio-amazon-web-services-11.png)
Utilice el siguiente código para visualizar el marco de datos procesado utilizando el paquete matplotlib. Utilice la biblioteca maptplotlib para trazar la ubicación de entrega y el monto total como un gráfico de barras.
Diagnosticar aplicaciones interactivas
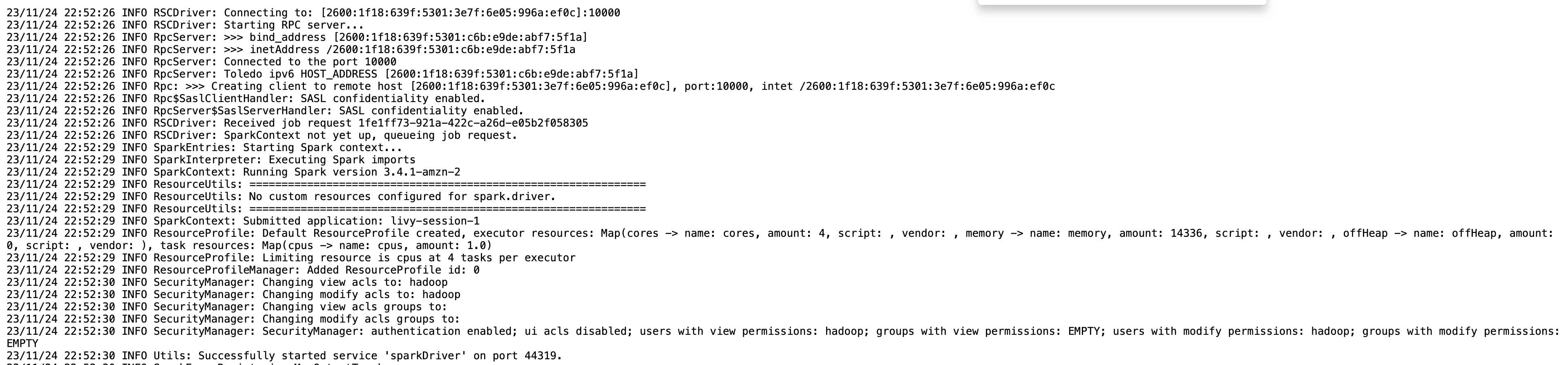
Puede obtener la información de la sesión para su punto final Livy utilizando el %%info Chispa mágica. Esto le brinda enlaces para acceder a la interfaz de usuario de Spark, así como al registro del controlador directamente en su computadora portátil.

La siguiente captura de pantalla es un fragmento de registro del controlador para nuestra aplicación, que abrimos mediante el enlace en nuestro cuaderno.
Del mismo modo, puedes elegir el siguiente enlace. Interfaz de usuario de Spark para abrir la interfaz de usuario. La siguiente captura de pantalla muestra la Ejecutores pestaña, que proporciona acceso a los registros del controlador y del ejecutor.

La siguiente captura de pantalla muestra la etapa 14, que corresponde al paso de Spark SQL que vimos anteriormente en el que calculamos la suma por ubicación de las recaudaciones totales de taxis, que se habían dividido en 12 tareas. A través de la interfaz de usuario de Spark, la aplicación interactiva proporciona estado detallado a nivel de tarea, E/S y detalles de reproducción aleatoria, así como enlaces a los registros correspondientes para cada tarea para esta etapa directamente desde su computadora portátil, lo que permite una experiencia de resolución de problemas perfecta.
Limpiar
Si ya no desea conservar los recursos creados en esta publicación, complete los siguientes pasos de limpieza:
- Eliminar la aplicación EMR Serverless.
- Elimine EMR Studio y los espacios de trabajo y cuadernos asociados.
- Para eliminar el resto de los recursos, navegue hasta la consola de CloudFormation, seleccione la pila y elija Borrar.
Todos los recursos se eliminarán excepto el depósito S3, que tiene su política de eliminación configurada para conservar.
Conclusión
La publicación mostró cómo ejecutar cargas de trabajo interactivas de PySpark en EMR Studio utilizando EMR Serverless como proceso. También puede crear y monitorear aplicaciones Spark en un espacio de trabajo interactivo de JupyterLab.
En una próxima publicación, analizaremos las capacidades adicionales de las aplicaciones interactivas sin servidor de EMR, como:
- Trabajar con recursos como Amazon RDS y Amazon Redshift en su VPC (por ejemplo, para conectividad JDBC/ODBC)
- Ejecutar cargas de trabajo transaccionales utilizando puntos finales sin servidor
Si es la primera vez que explora EMR Studio, le recomendamos que consulte el Talleres de Amazon EMR y refiriéndose a Cree un estudio EMR.
Acerca de los autores
 Sekar Srinivasan es arquitecto principal de soluciones especializado en AWS enfocado en análisis de datos e inteligencia artificial. Sekar tiene más de 20 años de experiencia trabajando con datos. Le apasiona ayudar a los clientes a crear soluciones escalables, modernizar su arquitectura y generar conocimientos a partir de sus datos. En su tiempo libre le gusta trabajar en proyectos sin ánimo de lucro, centrados en la educación de niños desfavorecidos.
Sekar Srinivasan es arquitecto principal de soluciones especializado en AWS enfocado en análisis de datos e inteligencia artificial. Sekar tiene más de 20 años de experiencia trabajando con datos. Le apasiona ayudar a los clientes a crear soluciones escalables, modernizar su arquitectura y generar conocimientos a partir de sus datos. En su tiempo libre le gusta trabajar en proyectos sin ánimo de lucro, centrados en la educación de niños desfavorecidos.
 Disha Umarwani es un arquitecto de datos sénior en Amazon Professional Services dentro de Global Health Care y LifeSciences. Ha trabajado con clientes para diseñar, diseñar e implementar estrategias de datos a escala. Se especializa en diseñar arquitecturas Data Mesh para plataformas empresariales.
Disha Umarwani es un arquitecto de datos sénior en Amazon Professional Services dentro de Global Health Care y LifeSciences. Ha trabajado con clientes para diseñar, diseñar e implementar estrategias de datos a escala. Se especializa en diseñar arquitecturas Data Mesh para plataformas empresariales.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/run-interactive-workloads-on-amazon-emr-serverless-from-amazon-emr-studio/