
دستیارهای هوش مصنوعی مکالمه ای (AI) برای ارائه پاسخ های دقیق و در زمان واقعی از طریق مسیریابی هوشمند پرس و جوها به مناسب ترین عملکردهای هوش مصنوعی مهندسی شده اند. با خدمات هوش مصنوعی مولد AWS مانند بستر آمازون، توسعه دهندگان می توانند سیستم هایی ایجاد کنند که به طور ماهرانه درخواست های کاربران را مدیریت کرده و به آنها پاسخ دهند. Amazon Bedrock یک سرویس کاملاً مدیریت شده است که انتخابی از مدلهای پایه (FM) با کارایی بالا را از شرکتهای پیشرو هوش مصنوعی مانند AI21 Labs، Anthropic، Cohere، Meta، Stability AI و Amazon با استفاده از یک API منفرد، همراه با مجموعه وسیعی از فونداسیون ارائه میکند. قابلیت هایی که برای ساخت برنامه های هوش مصنوعی مولد با امنیت، حریم خصوصی و هوش مصنوعی مسئولانه نیاز دارید.
این پست دو رویکرد اصلی برای توسعه دستیاران هوش مصنوعی را ارزیابی می کند: استفاده از خدمات مدیریت شده مانند نمایندگان آمازون بستر، و استفاده از فناوری های منبع باز مانند LangChain. ما مزایا و چالش های هر کدام را بررسی می کنیم تا بتوانید مناسب ترین مسیر را برای نیازهای خود انتخاب کنید.
دستیار هوش مصنوعی چیست؟
دستیار هوش مصنوعی یک سیستم هوشمند است که پرس و جوهای زبان طبیعی را درک می کند و با ابزارها، منابع داده و API های مختلف برای انجام وظایف یا بازیابی اطلاعات از طرف کاربر تعامل دارد. دستیاران هوش مصنوعی کارآمد دارای قابلیت های کلیدی زیر هستند:
- پردازش زبان طبیعی (NLP) و جریان مکالمه
- ادغام پایگاه دانش و جستجوهای معنایی برای درک و بازیابی اطلاعات مرتبط بر اساس تفاوت های ظریف زمینه گفتگو
- اجرای وظایف، مانند پرس و جوهای پایگاه داده و سفارشی AWS لامبدا توابع
- رسیدگی به مکالمات تخصصی و درخواست های کاربران
ما مزایای دستیاران هوش مصنوعی را با استفاده از مدیریت دستگاه اینترنت اشیا (IoT) به عنوان مثال نشان می دهیم. در این مورد، هوش مصنوعی میتواند به تکنسینها کمک کند تا با دستوراتی که دادهها را دریافت میکنند یا وظایف را خودکار میکنند، ماشینآلات را به طور موثر مدیریت کنند و عملیات تولید را سادهتر کنند.
Agents for Amazon Bedrock رویکرد
نمایندگان آمازون بستر به شما این امکان را می دهد که برنامه های کاربردی هوش مصنوعی تولید کنید که می توانند وظایف چند مرحله ای را در سیستم ها و منابع داده یک شرکت اجرا کنند. این قابلیت های کلیدی زیر را ارائه می دهد:
- ایجاد سریع خودکار از دستورالعمل ها، جزئیات API و اطلاعات منبع داده، صرفه جویی در هفته ها تلاش مهندسی سریع
- Retrieval Augmented Generation (RAG) برای اتصال ایمن عوامل به منابع داده یک شرکت و ارائه پاسخ های مرتبط
- هماهنگ سازی و اجرای وظایف چند مرحله ای با شکستن درخواست ها به دنباله های منطقی و فراخوانی API های ضروری
- مشاهده استدلال عامل از طریق ردیابی زنجیره ای از فکر (CoT) که امکان عیب یابی و هدایت رفتار مدل را فراهم می کند.
- توانایی های مهندسی سریع برای اصلاح الگوی سریع تولید شده به طور خودکار برای کنترل پیشرفته بر عوامل
می توانید از Agents for Amazon Bedrock و پایگاه های دانش برای آمازون بستر برای ساخت و استقرار دستیارهای هوش مصنوعی برای موارد استفاده پیچیده مسیریابی. آنها با سادهسازی مدیریت زیرساخت، افزایش مقیاسپذیری، بهبود امنیت و کاهش وزنکشی غیرمتمایز، یک مزیت استراتژیک برای توسعهدهندگان و سازمانها فراهم میکنند. آنها همچنین به کد لایه برنامه ساده تر اجازه می دهند زیرا منطق مسیریابی، برداری و حافظه به طور کامل مدیریت می شود.
بررسی اجمالی راه حل
این راه حل یک دستیار هوش مصنوعی مکالمه ای را معرفی می کند که برای مدیریت و عملیات دستگاه IoT در هنگام استفاده از Anthropic's Claude v2.1 در Amazon Bedrock طراحی شده است. عملکرد اصلی دستیار هوش مصنوعی توسط مجموعهای از دستورالعملها کنترل میشود که به نام a اعلان سیستم، که توانایی ها و زمینه های تخصصی آن را مشخص می کند. این راهنمایی اطمینان حاصل می کند که دستیار هوش مصنوعی می تواند طیف گسترده ای از وظایف، از مدیریت اطلاعات دستگاه گرفته تا اجرای دستورات عملیاتی را انجام دهد.
دستیار هوش مصنوعی مجهز به این قابلیتها، همانطور که در اعلان سیستم توضیح داده شده است، یک گردش کار ساختاریافته را برای پاسخگویی به سوالات کاربر دنبال میکند. شکل زیر نمایشی بصری از این گردش کار را ارائه می دهد و هر مرحله از تعامل اولیه کاربر تا پاسخ نهایی را نشان می دهد.
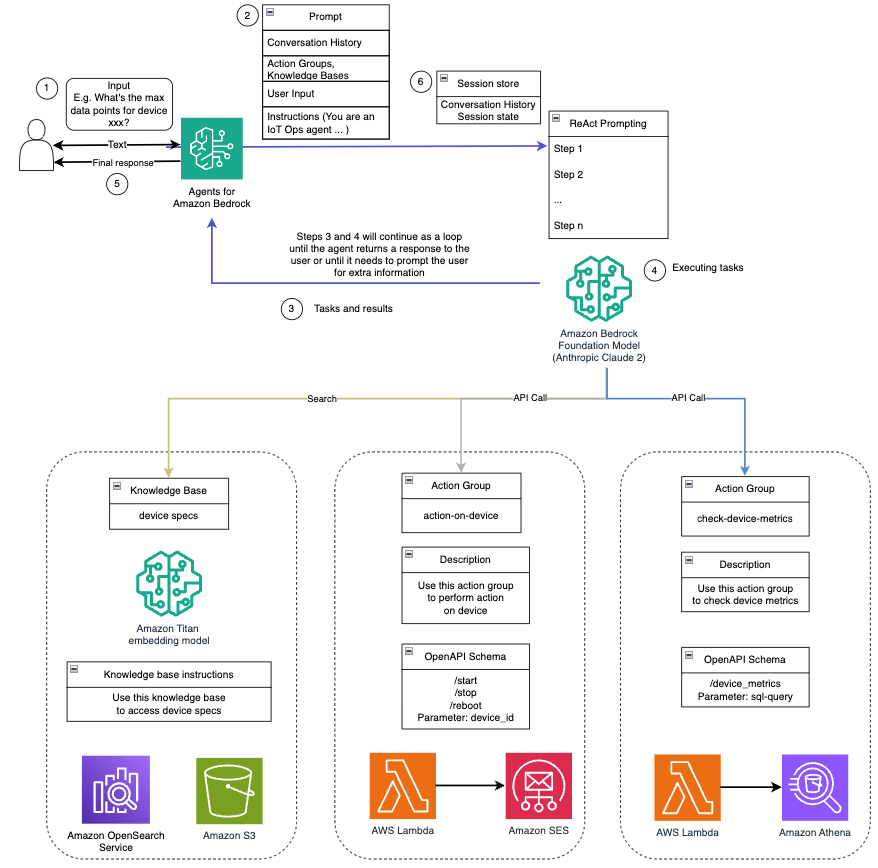
گردش کار از مراحل زیر تشکیل شده است:
- این فرآیند زمانی شروع می شود که کاربر از دستیار درخواست می کند تا کاری را انجام دهد. به عنوان مثال، درخواست حداکثر نقاط داده برای یک دستگاه IoT خاص
device_xxx. این ورودی متن گرفته شده و به دستیار هوش مصنوعی ارسال می شود. - دستیار هوش مصنوعی ورودی متن کاربر را تفسیر می کند. از تاریخچه مکالمه ارائه شده، گروه های اقدام و پایگاه های دانش برای درک زمینه و تعیین وظایف ضروری استفاده می کند.
- پس از تجزیه و درک هدف کاربر، دستیار هوش مصنوعی وظایف را تعریف می کند. این بر اساس دستورالعمل هایی است که توسط دستیار بر اساس درخواست سیستم و ورودی کاربر تفسیر می شود.
- سپس کارها از طریق یک سری فراخوانی API اجرا می شوند. این کار با استفاده از واکنش نشان دادن درخواست، که کار را به یک سری مراحل تقسیم می کند که به صورت متوالی پردازش می شوند:
- برای بررسی معیارهای دستگاه، از
check-device-metricsگروه اقدام، که شامل یک فراخوانی API به توابع لامبدا می شود و سپس پرس و جو می کند آمازون آتنا برای داده های درخواستی - برای اقدامات مستقیم دستگاه مانند شروع، توقف یا راهاندازی مجدد، از
action-on-deviceگروه اقدام، که تابع Lambda را فراخوانی می کند. این تابع فرآیندی را آغاز می کند که دستورات را به دستگاه IoT ارسال می کند. برای این پست، تابع Lambda با استفاده از اعلانها را ارسال میکند سرویس ایمیل ساده آمازون (Amazon SES). - ما از پایگاه های دانش برای Amazon Bedrock برای واکشی از داده های تاریخی ذخیره شده به عنوان جاسازی در سرویس جستجوی باز آمازون پایگاه داده برداری
- برای بررسی معیارهای دستگاه، از
- پس از تکمیل وظایف، پاسخ نهایی توسط Amazon Bedrock FM ایجاد شده و به کاربر منتقل می شود.
- Agents for Amazon Bedrock به طور خودکار اطلاعات را با استفاده از یک جلسه حالت حالت برای حفظ همان مکالمه ذخیره می کند. این حالت پس از سپری شدن مدت زمان بیکاری قابل تنظیم حذف می شود.
نمای کلی فنی
نمودار زیر معماری استقرار دستیار هوش مصنوعی با Agents for Amazon Bedrock را نشان می دهد.
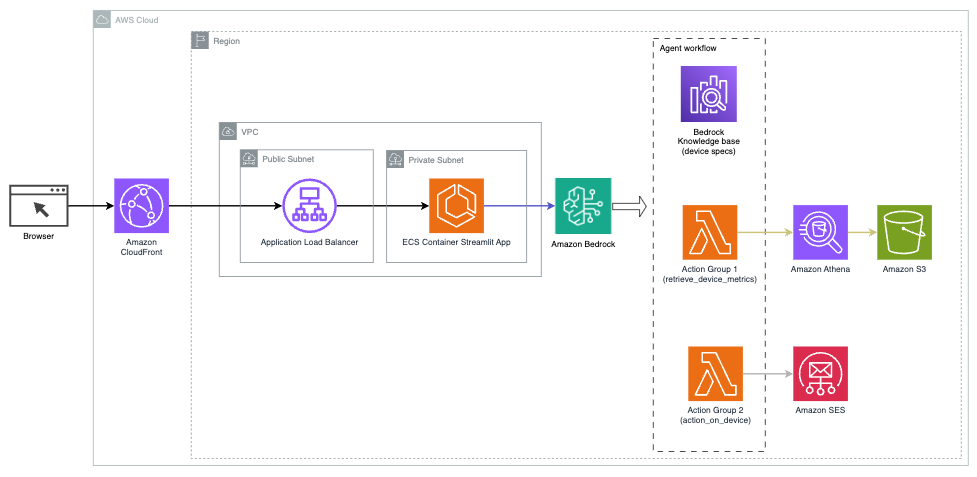
از اجزای کلیدی زیر تشکیل شده است:
- رابط مکالمه – رابط مکالمه از Streamlit، یک کتابخانه منبع باز پایتون استفاده می کند که ایجاد برنامه های وب سفارشی و جذاب بصری برای یادگیری ماشین (ML) و علم داده را ساده می کند. میزبانی شده است سرویس کانتینر الاستیک آمازون (Amazon ECS) با AWS Fargateو با استفاده از Application Load Balancer قابل دسترسی است. برای اجرا می توانید از Fargate با Amazon ECS استفاده کنید ظروف بدون نیاز به مدیریت سرورها، خوشه ها یا ماشین های مجازی.
- نمایندگان آمازون بستر - Agents for Amazon Bedrock پرس و جوهای کاربر را از طریق یک سری مراحل استدلال و اقدامات مربوطه بر اساس درخواست ReAct:
- پایگاه های دانش برای آمازون بستر – پایگاه های دانش برای Amazon Bedrock به طور کامل مدیریت شده را ارائه می دهد RAG برای دسترسی دستیار هوش مصنوعی به داده های شما. در مورد استفاده ما، مشخصات دستگاه را در یک آپلود کردیم سرویس ذخیره سازی ساده آمازون سطل (Amazon S3). به عنوان منبع داده برای پایگاه دانش عمل می کند.
- گروه های اقدام – اینها طرحواره های API تعریف شده ای هستند که عملکردهای Lambda خاصی را برای تعامل با دستگاه های IoT و سایر خدمات AWS فراخوانی می کنند.
- Anthropic Claude v2.1 در Amazon Bedrock - این مدل پرس و جوهای کاربر را تفسیر می کند و جریان کارها را هماهنگ می کند.
- آمازون تایتان Embeddings - این مدل به عنوان یک مدل جاسازی متن عمل می کند و متن زبان طبیعی - از تک کلمات به اسناد پیچیده - را به بردارهای عددی تبدیل می کند. این قابلیتهای جستجوی برداری را فعال میکند و به سیستم اجازه میدهد تا به صورت معنایی پرس و جوهای کاربر را با مرتبطترین ورودیهای پایگاه دانش برای جستجوی مؤثر مطابقت دهد.
این راه حل با سرویس های AWS مانند Lambda برای اجرای کد در پاسخ به تماس های API، Athena برای جستجوی مجموعه داده ها، سرویس OpenSearch برای جستجو در پایگاه های دانش و Amazon S3 برای ذخیره سازی یکپارچه شده است. این سرویسها با هم کار میکنند تا از طریق دستورات زبان طبیعی، تجربهای یکپارچه را برای مدیریت عملیات دستگاه اینترنت اشیا فراهم کنند.
مزایا
این راه حل مزایای زیر را ارائه می دهد:
- پیچیدگی پیاده سازی:
- خطوط کد کمتری مورد نیاز است، زیرا Agents for Amazon Bedrock بسیاری از پیچیدگی های اساسی را از بین می برد و تلاش توسعه را کاهش می دهد.
- مدیریت پایگاه های داده برداری مانند سرویس OpenSearch ساده شده است، زیرا پایگاه های دانش برای Amazon Bedrock، بردارسازی و ذخیره سازی را انجام می دهد.
- ادغام با سرویس های مختلف AWS از طریق گروه های اقدام از پیش تعریف شده ساده تر می شود
- تجربه توسعه دهنده:
- کنسول Bedrock آمازون یک رابط کاربر پسند برای توسعه سریع، آزمایش و تجزیه و تحلیل علت اصلی (RCA) فراهم می کند و تجربه کلی توسعه دهنده را بهبود می بخشد.
- چابکی و انعطاف پذیری:
- Agents for Amazon Bedrock به FM های جدیدتر (مانند Claude 3.0) پس از در دسترس شدن امکان ارتقای یکپارچه را می دهد، بنابراین راه حل شما با آخرین پیشرفت ها به روز می شود.
- سهمیهها و محدودیتهای خدمات توسط AWS مدیریت میشوند و هزینههای سربار زیرساخت نظارت و مقیاسبندی را کاهش میدهند.
- امنیت:
- Amazon Bedrock یک سرویس کاملاً مدیریت شده است که از استانداردهای امنیتی و انطباق دقیق AWS پیروی می کند و به طور بالقوه بررسی های امنیتی سازمانی را ساده می کند.
اگرچه Agents for Amazon Bedrock یک راه حل ساده و مدیریت شده برای ساخت برنامه های هوش مصنوعی محاوره ای ارائه می دهد، برخی از سازمان ها ممکن است رویکرد منبع باز را ترجیح دهند. در چنین مواقعی می توانید از فریمورک هایی مانند LangChain استفاده کنید که در قسمت بعدی به آن می پردازیم.
رویکرد مسیریابی پویا LangChain
LangChain یک چارچوب متن باز است که ساخت هوش مصنوعی مکالمه را با امکان ادغام مدل های زبان بزرگ (LLM) و قابلیت های مسیریابی پویا ساده می کند. با زبان بیان LangChain (LCEL)، توسعه دهندگان می توانند این را تعریف کنند مسیریابی، که به شما امکان می دهد زنجیره های غیر قطعی ایجاد کنید که در آن خروجی مرحله قبلی مرحله بعدی را مشخص می کند. مسیریابی به ایجاد ساختار و سازگاری در تعامل با LLM ها کمک می کند.
برای این پست، از همان مثالی به عنوان دستیار هوش مصنوعی برای مدیریت دستگاه های اینترنت اشیا استفاده می کنیم. با این حال، تفاوت اصلی این است که ما باید دستورات سیستم را جداگانه مدیریت کنیم و هر زنجیره را به عنوان یک موجودیت جداگانه در نظر بگیریم. زنجیره مسیریابی زنجیره مقصد را بر اساس ورودی کاربر تعیین می کند. این تصمیم با پشتیبانی یک LLM با عبور از اعلان سیستم، تاریخچه چت و سوال کاربر گرفته می شود.
بررسی اجمالی راه حل
نمودار زیر گردش کار راه حل پویا مسیریابی را نشان می دهد.
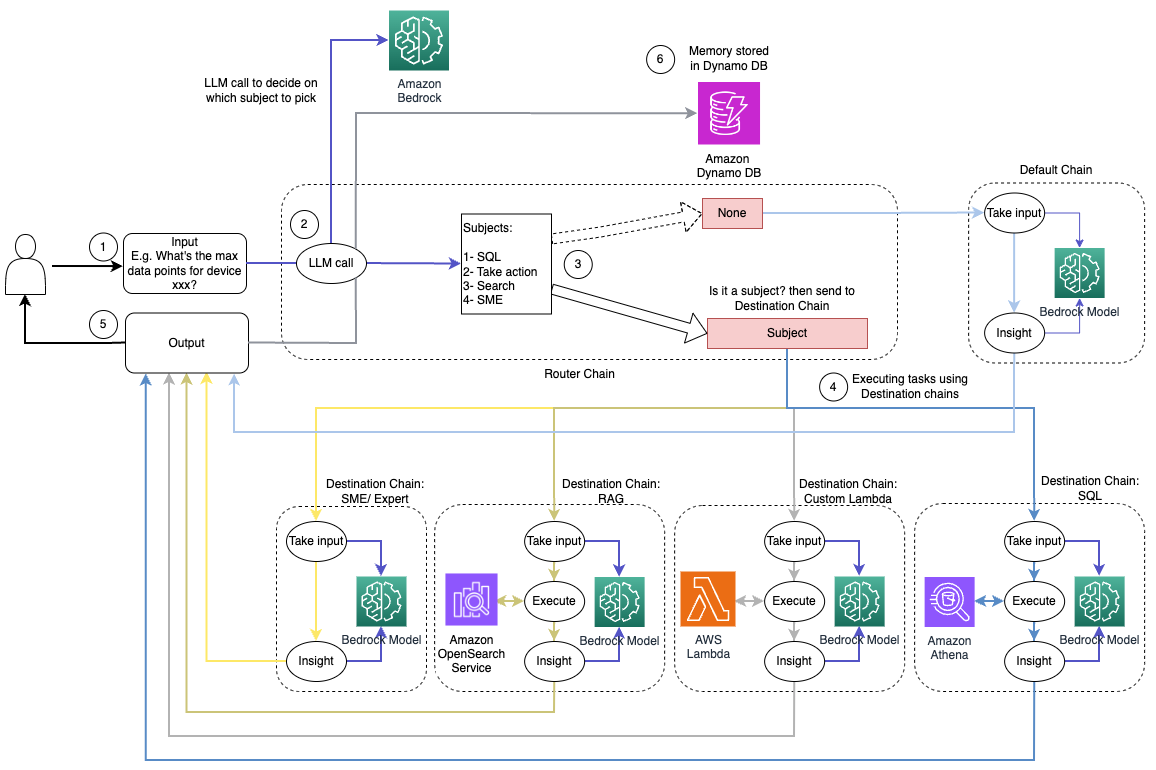
گردش کار شامل مراحل زیر است:
- کاربر سؤالی را به دستیار هوش مصنوعی ارائه می دهد. به عنوان مثال، "حداکثر معیارها برای دستگاه 1009 چیست؟"
- یک LLM هر سوال را همراه با تاریخچه چت از همان جلسه ارزیابی می کند تا ماهیت آن و حوزه موضوعی آن را تعیین کند (مانند SQL، اقدام، جستجو یا SME). LLM ورودی را طبقه بندی می کند و زنجیره مسیریابی LCEL آن ورودی را می گیرد.
- زنجیره روتر زنجیره مقصد را بر اساس ورودی انتخاب می کند و LLM با اعلان سیستم زیر ارائه می شود:
LLM سؤال کاربر را به همراه تاریخچه چت ارزیابی می کند تا ماهیت پرس و جو و حوزه موضوعی آن را مشخص کند. سپس LLM ورودی را طبقه بندی می کند و یک پاسخ JSON را در قالب زیر خروجی می دهد:
زنجیره روتر از این پاسخ JSON برای فراخوانی زنجیره مقصد مربوطه استفاده می کند. چهار زنجیره مقصد برای موضوع خاص وجود دارد که هر کدام دارای اعلان سیستم خاص خود هستند:
- پرس و جوهای مربوط به SQL برای تعاملات پایگاه داده به زنجیره مقصد SQL ارسال می شوند. برای ساختن می توانید از LCEL استفاده کنید زنجیره SQL.
- سوالات کنش گرا زنجیره مقصد سفارشی Lambda را برای اجرای عملیات فراخوانی می کنند. با LCEL، شما می توانید خود را تعریف کنید عملکرد سفارشی; در مورد ما، این یک تابع برای اجرای یک تابع لامبدا از پیش تعریف شده برای ارسال ایمیل با شناسه دستگاه تجزیه شده است. نمونه ورودی کاربر ممکن است «خاموش کردن دستگاه 1009» باشد.
- پرس و جوهای متمرکز بر جستجو به سمت RAG زنجیره مقصد برای بازیابی اطلاعات
- سوالات مربوط به SME برای بینش تخصصی به زنجیره مقصد SME/متخصص مراجعه کنید.
- هر زنجیره مقصد ورودی را می گیرد و مدل ها یا توابع لازم را اجرا می کند:
- زنجیره SQL از Athena برای اجرای کوئری ها استفاده می کند.
- زنجیره RAG از سرویس OpenSearch برای جستجوی معنایی استفاده می کند.
- زنجیره سفارشی Lambda توابع Lambda را برای اقدامات اجرا می کند.
- زنجیره SME/expert بینش هایی را با استفاده از مدل Amazon Bedrock ارائه می دهد.
- پاسخها از هر زنجیره مقصد توسط LLM به بینشهای منسجمی فرموله میشوند. سپس این بینش ها به کاربر تحویل داده می شود و چرخه پرس و جو را تکمیل می کند.
- ورودی و پاسخ های کاربر در آن ذخیره می شود آمازون DynamoDB برای ارائه زمینه به LLM برای جلسه جاری و از تعاملات گذشته. مدت زمان ماندگاری اطلاعات در DynamoDB توسط برنامه کنترل می شود.
نمای کلی فنی
نمودار زیر معماری راه حل مسیریابی پویا LangChain را نشان می دهد.

برنامه وب بر روی Streamlit که در Amazon ECS با Fargate میزبانی شده است ساخته شده است و با استفاده از Application Load Balancer قابل دسترسی است. ما از Anthropic's Claude v2.1 در Amazon Bedrock به عنوان LLM خود استفاده می کنیم. برنامه وب با استفاده از کتابخانه های LangChain با مدل تعامل دارد. همچنین با انواع دیگر سرویسهای AWS مانند OpenSearch Service، Athena و DynamoDB تعامل دارد تا نیازهای کاربران نهایی را برآورده کند.
مزایا
این راه حل مزایای زیر را ارائه می دهد:
- پیچیدگی پیاده سازی:
- اگرچه نیاز به کد و توسعه سفارشی بیشتری دارد، اما LangChain انعطاف پذیری و کنترل بیشتری بر روی منطق مسیریابی و یکپارچگی با اجزای مختلف فراهم می کند.
- مدیریت پایگاههای داده برداری مانند سرویس OpenSearch به تلاشهای بیشتری برای راهاندازی و پیکربندی نیاز دارد. فرآیند برداری به صورت کد پیاده سازی می شود.
- ادغام با خدمات AWS ممکن است شامل کد و پیکربندی سفارشی بیشتری باشد.
- تجربه توسعه دهنده:
- رویکرد مبتنی بر Python و مستندات گسترده LangChain می تواند برای توسعه دهندگانی که قبلاً با Python و ابزارهای منبع باز آشنا هستند جذاب باشد.
- توسعه سریع و اشکال زدایی ممکن است به تلاش دستی بیشتری در مقایسه با استفاده از کنسول آمازون بستر نیاز داشته باشد.
- چابکی و انعطاف پذیری:
- LangChain از طیف گسترده ای از LLM ها پشتیبانی می کند و به شما امکان می دهد بین مدل ها یا ارائه دهندگان مختلف جابجا شوید و انعطاف پذیری را تقویت کنید.
- ماهیت منبع باز LangChain بهبودها و سفارشی سازی های مبتنی بر جامعه را امکان پذیر می کند.
- امنیت:
- به عنوان یک چارچوب متن باز، LangChain ممکن است به بررسی های امنیتی دقیق تر و بررسی در سازمان ها نیاز داشته باشد که به طور بالقوه هزینه های اضافی را اضافه می کند.
نتیجه
دستیارهای هوش مصنوعی مکالمه ای ابزارهای متحول کننده ای برای ساده کردن عملیات و افزایش تجربیات کاربر هستند. این پست دو رویکرد قدرتمند با استفاده از سرویسهای AWS را بررسی میکند: عوامل مدیریتشده برای Amazon Bedrock و مسیریابی پویا منبع باز و انعطافپذیر LangChain. انتخاب بین این رویکردها به الزامات سازمان شما، اولویت های توسعه و سطح دلخواه سفارشی سازی بستگی دارد. صرف نظر از مسیر طی شده، AWS شما را قادر می سازد تا دستیاران هوش مصنوعی هوشمند ایجاد کنید که تعاملات تجاری و مشتریان را متحول می کند.
کد راه حل و دارایی های استقرار را در ما پیدا کنید مخزن GitHub، جایی که می توانید مراحل دقیق هر رویکرد هوش مصنوعی مکالمه را دنبال کنید.
درباره نویسنده
 امیر حکمه یک معمار AWS Solutions مستقر در پنسیلوانیا است. او با فروشندگان نرم افزار مستقل (ISVs) در منطقه شمال شرقی همکاری می کند و به آنها در طراحی و ساخت پلتفرم های مقیاس پذیر و مدرن بر روی AWS Cloud کمک می کند. Ameer که متخصص در AI/ML و هوش مصنوعی مولد است، به مشتریان کمک می کند تا پتانسیل این فناوری های پیشرفته را کشف کنند. در اوقات فراغت از موتور سواری و گذراندن اوقات فراغت با خانواده لذت می برد.
امیر حکمه یک معمار AWS Solutions مستقر در پنسیلوانیا است. او با فروشندگان نرم افزار مستقل (ISVs) در منطقه شمال شرقی همکاری می کند و به آنها در طراحی و ساخت پلتفرم های مقیاس پذیر و مدرن بر روی AWS Cloud کمک می کند. Ameer که متخصص در AI/ML و هوش مصنوعی مولد است، به مشتریان کمک می کند تا پتانسیل این فناوری های پیشرفته را کشف کنند. در اوقات فراغت از موتور سواری و گذراندن اوقات فراغت با خانواده لذت می برد.
 شارون لی یک معمار راه حل های AI/ML در خدمات وب آمازون مستقر در بوستون است و علاقه زیادی به طراحی و ساخت برنامه های کاربردی هوش مصنوعی مولد در AWS دارد. او با مشتریان همکاری می کند تا از خدمات AWS AI/ML برای راه حل های نوآورانه استفاده کند.
شارون لی یک معمار راه حل های AI/ML در خدمات وب آمازون مستقر در بوستون است و علاقه زیادی به طراحی و ساخت برنامه های کاربردی هوش مصنوعی مولد در AWS دارد. او با مشتریان همکاری می کند تا از خدمات AWS AI/ML برای راه حل های نوآورانه استفاده کند.
 کوثر کمال یک معمار ارشد راه حل در خدمات وب آمازون با بیش از 15 سال تجربه در اتوماسیون زیرساخت و فضای امنیتی است. او به مشتریان کمک می کند تا راه حل های DevSecOps و AI/ML مقیاس پذیر را در Cloud طراحی و بسازند.
کوثر کمال یک معمار ارشد راه حل در خدمات وب آمازون با بیش از 15 سال تجربه در اتوماسیون زیرساخت و فضای امنیتی است. او به مشتریان کمک می کند تا راه حل های DevSecOps و AI/ML مقیاس پذیر را در Cloud طراحی و بسازند.
- محتوای مبتنی بر SEO و توزیع روابط عمومی. امروز تقویت شوید.
- PlatoData.Network Vertical Generative Ai. به خودت قدرت بده دسترسی به اینجا.
- PlatoAiStream. هوش وب 3 دانش تقویت شده دسترسی به اینجا.
- PlatoESG. کربن ، CleanTech، انرژی، محیط، خورشیدی، مدیریت پسماند دسترسی به اینجا.
- PlatoHealth. هوش بیوتکنولوژی و آزمایشات بالینی. دسترسی به اینجا.
- منبع: https://aws.amazon.com/blogs/machine-learning/enhance-conversational-ai-with-advanced-routing-techniques-with-amazon-bedrock/