
Julkaisusta 6.14 alkaen Amazon EMR Studio tukee interaktiivista analytiikkaa Amazon EMR-palvelimeton. Voit nyt käyttää laskentana EMR-palvelimettomia sovelluksia Amazon EMR:n lisäksi EC2-klustereissa ja Amazon EMR EKS:ssä virtuaalisia klustereita JupyterLab-muistikirjojen suorittamiseen EMR Studio Workspacesista.
EMR Studio on integroitu kehitysympäristö (IDE), jonka avulla tietotutkijat ja tietosuunnittelijat voivat helposti kehittää, visualisoida ja korjata PySparkissa, Pythonissa ja Scalassa kirjoitettuja analytiikkasovelluksia. EMR Serverless on palvelimeton vaihtoehto Amazonin EMR Tämä tekee avoimen lähdekoodin suurdatan analytiikkakehysten, kuten Apache Sparkin, suorittamisesta yksinkertaista ilman klustereiden tai palvelimien määrittämistä, hallintaa ja skaalausta.
Viestissä näytämme, kuinka voit tehdä seuraavat asiat:
- Luo EMR-palvelimeton päätepiste interaktiivisille sovelluksille
- Liitä päätepiste olemassa olevaan EMR Studio -ympäristöön
- Luo muistikirja ja suorita interaktiivinen sovellus
- Diagnosoi saumattomasti interaktiivisia sovelluksia EMR Studiosta
Edellytykset
Tyypillisessä organisaatiossa AWS-tilin järjestelmänvalvoja määrittää AWS-resurssit, kuten AWS Identity and Access Management (IAM) roolit, Amazonin yksinkertainen tallennuspalvelu (Amazon S3) kauhat ja Amazonin virtuaalinen yksityinen pilvi (Amazon VPC) -resurssit Internet-yhteyteen ja muihin VPC:n resursseihin. He nimeävät EMR Studio -järjestelmänvalvojat, jotka hallinnoivat EMR Studioiden määrittämistä ja käyttäjien määrittämistä tiettyyn EMR Studioon. Kun EMR Studion kehittäjät saavat tehtävänsä, he voivat käyttää EMR Studiota työkuormien kehittämiseen ja seurantaan.
Varmista, että määrität samalle AWS-alueelle resurssit, kuten S3-säihön, VPC-aliverkot ja EMR Studion.
Ota nämä edellytykset käyttöön suorittamalla seuraavat vaiheet:
- Käynnistä seuraava AWS-pilven muodostuminen pino.

- Anna arvot kohteelle AdminPassword ja DevPassword ja kirjoita luomasi salasanat muistiin.
- Valita seuraava.
- Pidä asetukset oletusarvoisina ja valitse seuraava uudelleen.
- valita Myönnän, että AWS CloudFormation saattaa luoda IAM-resursseja mukautetuilla nimillä.
- Valitse Lähetä.
Olemme myös toimittaneet ohjeet näiden resurssien manuaaliseen käyttöönottamiseksi IAM-mallien käytäntöjen avulla GitHub repo.
Asenna EMR Studio ja palvelimeton interaktiivinen sovellus
Kun AWS-tilin järjestelmänvalvoja on suorittanut edellytykset, EMR Studion järjestelmänvalvoja voi kirjautua sisään AWS-hallintakonsoli luodaksesi EMR Studio-, Workspace- ja EMR Serverless -sovelluksen.
Luo EMR Studio ja työtila
EMR Studion järjestelmänvalvojan tulee kirjautua sisään konsoliin käyttämällä emrs-interactive-app-admin-user käyttäjätunnukset. Jos otit käyttöön tarvittavat resurssit toimitetun CloudFormation-mallin avulla, käytä syöteparametrina antamaasi salasanaa.
- Valitse Amazon EMR -konsolista EMR-palvelimeton navigointipaneelissa.

- Valita Aloita.
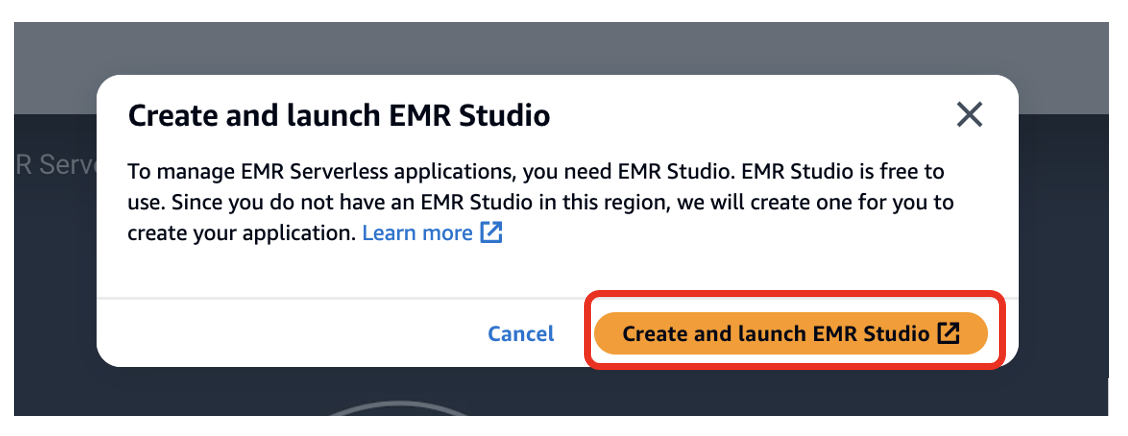
- valita Luo ja käynnistä EMR Studio.
Tämä luo Studion oletusnimellä studio_1 ja työtila oletusnimellä My_First_Workspace. Uusi selaimen välilehti avautuu Studio_1 käyttöliittymä.
Luo EMR-palvelinton sovellus
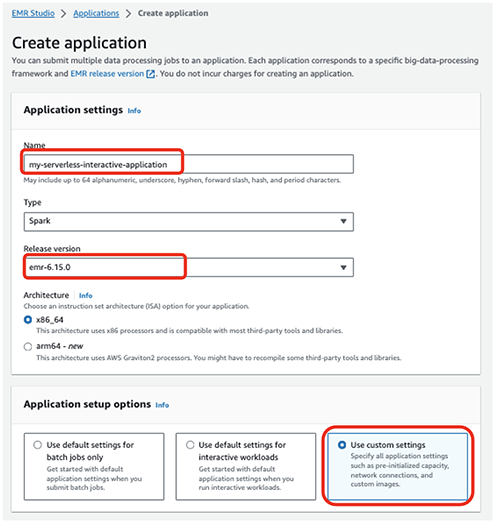
Luo EMR-palvelinton sovellus suorittamalla seuraavat vaiheet:
- Valitse EMR Studio -konsolissa Sovellukset navigointipaneelissa.
- Luo uusi sovellus.
- varten Nimi, kirjoita nimi (esimerkiksi
my-serverless-interactive-application). - varten Sovelluksen asetusvaihtoehdotvalitse Käytä mukautettuja asetuksia interaktiivisiin työkuormiin.
Interaktiivisissa sovelluksissa suosittelemme parhaana käytäntönä pitämään kuljettaja ja työntekijät valmiiksi alustettuina määrittämällä esialustettu kapasiteetti sovelluksen luomisen yhteydessä. Tämä luo tehokkaasti lämpimän joukon työntekijöitä sovellukselle ja pitää resurssit valmiina kulutettaviksi, jolloin sovellus voi vastata sekunneissa. Katso lisää parhaita käytäntöjä EMR-palvelimettomien sovellusten luomiseen Määritä tiimikohtaiset resurssirajat suurille datatyökuormille Amazon EMR Serverlessin avulla.
- In Interaktiivinen päätepiste , valitse Ota interaktiivinen päätepiste käyttöön.
- In Verkkoyhteydet Valitse aiemmin luomasi VPC, yksityiset aliverkot ja suojausryhmä.
Jos otit käyttöön tässä viestissä tarjotun CloudFormation-pinon, valitse emr-serverless-sg turvaryhmänä.
VPC tarvitaan, jotta työkuorma voi käyttää Internetiä EMR Serverless -sovelluksesta ulkoisten Python-pakettien lataamista varten. VPC mahdollistaa myös pääsyn resursseihin, kuten Amazon Relational Database -palvelu (Amazon RDS) ja Amazonin punainen siirto jotka ovat tämän sovelluksen VPC:ssä. Palvelittoman sovelluksen liittäminen VPC:hen voi johtaa aliverkon IP-osoitteiden loppumiseen, joten varmista, että aliverkossasi on riittävästi IP-osoitteita.
- Valita Luo ja käynnistä sovellus.

Sovellussivulla voit tarkistaa, että palvelimettoman sovelluksesi tila muuttuu muotoon aloitti.
- Valitse sovelluksesi ja valitse Kuinka se toimii.
- Valita Tarkastele ja käynnistä työtiloja.
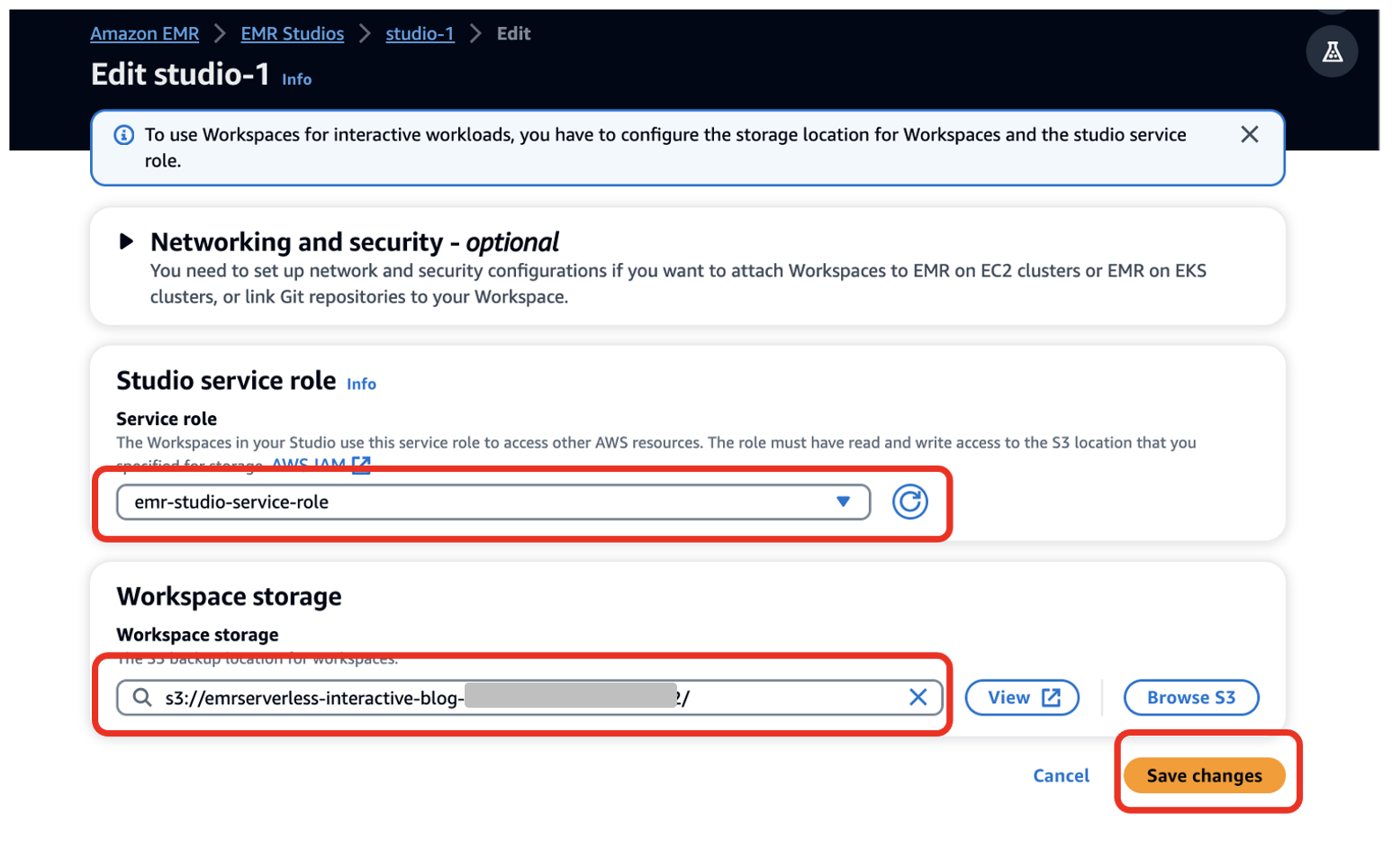
- Valita Määritä studio.

- varten Palvelurooli¸ anna luomasi EMR Studio -palvelurooli edellytyksenä (
emr-studio-service-role). - varten Työtilan varastointi, kirjoita edellytyksenä luomasi S3-ämpäri polku (
emrserverless-interactive-blog-<account-id>-<region-name>). - Valita Tallenna muutokset.
14. Siirry Studios-konsoliin valitsemalla Studios vasemmassa navigointivalikossa EMR-studio osio. Huomaa Studion käyttöoikeuden URL-osoite Studios-konsolista ja anna se kehittäjillesi Spark-sovellusten ajamista varten.
Suorita ensimmäinen Spark-sovelluksesi
Kun EMR Studion järjestelmänvalvoja on luonut Studion, Workspacen ja palvelimettoman sovelluksen, Studion käyttäjä voi käyttää työtilaa ja sovellusta Spark-työkuormien kehittämiseen ja valvontaan.
Käynnistä Workspace ja liitä palvelimeton sovellus
Suorita seuraavat vaiheet:
- Kirjaudu sisään käyttämällä EMR Studion järjestelmänvalvojan antamaa Studion URL-osoitetta
emrs-interactive-app-dev-userAWS-tilin järjestelmänvalvojan jakamat käyttäjätiedot.
Jos otit käyttöön tarvittavat resurssit toimitetun CloudFormation-mallin avulla, käytä syöteparametrina antamaasi salasanaa.
On työtilat -sivulla voit tarkistaa työtilasi tilan. Kun työtila käynnistetään, näet tilan muuttuvan muotoon Valmis.
- Käynnistä työtila valitsemalla työtilan nimi (
My_First_Workspace).
Tämä avaa uuden välilehden. Varmista, että selaimesi sallii ponnahdusikkunat.
- Valitse työtilassa Laskea (klusterikuvake) navigointiruudussa.
- varten EMR-palvelinton sovellus, valitse sovelluksesi (
my-serverless-interactive-application). - varten Interaktiivinen ajonaikainen rooli, valitse interaktiivinen suoritusaikarooli (tässä viestissä käytämme
emr-serverless-runtime-role). - Valita Liittää liittääksesi palvelimettoman sovelluksen laskentatyypiksi kaikille tämän työtilan muistikirjoille.

Suorita Spark-sovellus interaktiivisesti
Suorita seuraavat vaiheet:
- Valitse Muistikirjan näytteitä (kolmen pisteen kuvake) navigointiruudussa ja avaa
Getting-started-with-emr-serverlessmuistikirja. - Valita Tallenna työtilaan.
Muistikirjaamme on kolme eri ydinvaihtoehtoa: Python 3, PySpark ja Spark (Scalalle).
- Valitse kehotettaessa PySpark ytimenä.
- Valita valita.

Nyt voit suorittaa Spark-sovelluksesi. Käytä tätä varten %%configure Sparkmagic komento, joka määrittää istunnon luontiparametrit. Interaktiiviset sovellukset tukevat Python-virtuaaliympäristöjä. Käytämme mukautettua ympäristöä työntekijän solmuissa määrittämällä polun eri Python-ajonaikaiselle suorittajaympäristölle käyttämällä spark.executorEnv.PYSPARK_PYTHON. Katso seuraava koodi:
Asenna ulkoiset paketit
Nyt kun sinulla on itsenäinen virtuaaliympäristö työntekijöitä varten, EMR Studio -kannettavat voit asentaa ulkoisia paketteja palvelimettomasta sovelluksesta Sparkin avulla. install_pypi_package toimivat Spark-kontekstin kautta. Tämän toiminnon avulla paketti on kaikkien EMR-palvelimettomien työntekijöiden käytettävissä.
Asenna ensin matplotlib, Python-paketti PyPistä:
Jos edellinen vaihe ei vastaa, tarkista VPC-asetukset ja varmista, että se on määritetty oikein Internet-yhteyttä varten.
Nyt voit käyttää tietojoukkoa ja visualisoida tietosi.
Luo visualisointeja
Visualisaatioiden luomiseen käytämme julkista tietojoukkoa NYC:n keltaisista takseista:
Edellisessä koodilohkossa luit Parquet-tiedoston julkisesta ämpäristä Amazon S3:ssa. Tiedostossa on otsikot, ja haluamme Sparkin päättelevän skeeman. Tämän jälkeen käytät Spark-tietokehystä tiettyjen sarakkeiden ryhmittelyyn ja laskemiseen taxi_df:
Käyttää %%display magic nähdäksesi tuloksen taulukkomuodossa:

Voit myös visualisoida tiedot nopeasti viiden tyyppisen kaavion avulla. Voit valita näyttötyypin ja kaavio muuttuu sen mukaan. Seuraavassa kuvakaappauksessa käytämme pylväskaaviota tietojemme visualisointiin.

Ole vuorovaikutuksessa EMR Serverlessin kanssa Spark SQL:n avulla
Voit olla vuorovaikutuksessa taulukoiden kanssa AWS-liimatietoluettelo käyttämällä Spark SQL:ää EMR Serverlessissä. Esimerkkimuistikirjassa näytämme, kuinka voit muuntaa tietoja käyttämällä Spark-tietokehystä.
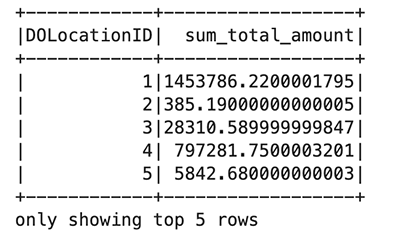
Luo ensin uusi väliaikainen näkymä nimeltä taksit. Tämän avulla voit käyttää Spark SQL:ää tietojen valitsemiseen tästä näkymästä. Luo sitten taksitietokehys jatkokäsittelyä varten:
Voit laajentaa EMR Studio -muistikirjan jokaista solua Spark Job Progress tarkastellaksesi EMR Serverlessille lähetetyn työn eri vaiheita tätä solua suoritettaessa. Näet kunkin vaiheen suorittamiseen kuluvan ajan. Seuraavassa esimerkissä työn vaiheessa 14 on 12 suoritettua tehtävää. Lisäksi, jos jokin vika ilmenee, voit nähdä lokit, mikä tekee vianmäärityksestä saumattoman kokemuksen. Keskustelemme tästä lisää seuraavassa osiossa.
![Työ[14]: showString osoitteessa NativeMethodAccessorImpl.java:0 ja Job[15]: showString osoitteessa NativeMethodAccessorImpl.java:0](https://xlera8.com/wp-content/uploads/2024/04/run-interactive-workloads-on-amazon-emr-serverless-from-amazon-emr-studio-amazon-web-services-11.png)
Käytä seuraavaa koodia visualisoidaksesi käsitellyn tietokehyksen matplotlib-paketin avulla. Käytät maptplotlib-kirjastoa pudotuspaikan ja kokonaissumman piirtämiseen pylväskaaviona.
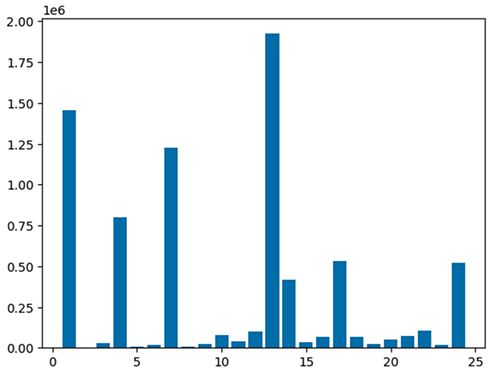
Diagnosoi interaktiiviset sovellukset
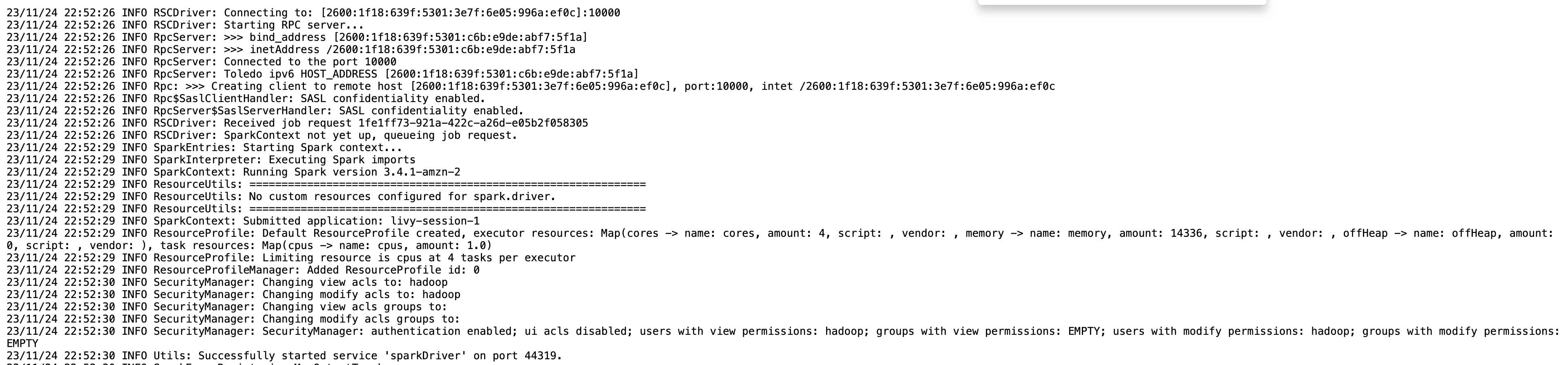
Voit saada Livy-päätepisteesi istuntotiedot käyttämällä %%info Sparkmagic. Tämä antaa sinulle linkit Spark-käyttöliittymään sekä ajurin lokiin suoraan kannettavassasi.

Seuraava kuvakaappaus on ohjainlokin katkelma sovelluksestamme, jonka avasimme muistikirjassamme olevan linkin kautta.
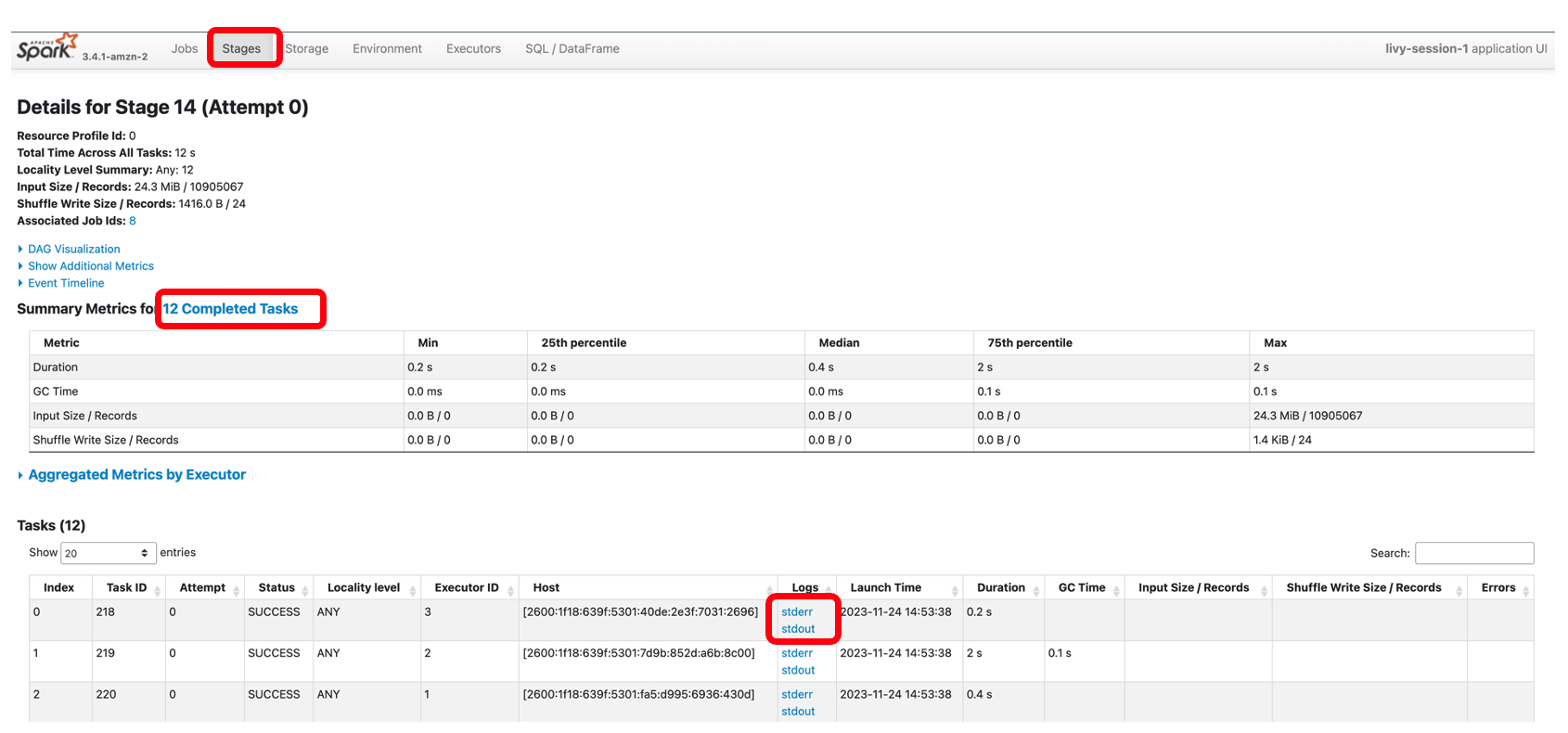
Vastaavasti voit valita alla olevan linkin Spark UI avataksesi käyttöliittymän. Seuraava kuvakaappaus näyttää Suorittajat -välilehti, joka tarjoaa pääsyn ohjain- ja suorituslokeihin.

Seuraavassa kuvakaappauksessa näkyy vaihe 14, joka vastaa aiemmin näkemäämme Spark SQL -vaihetta, jossa laskettiin 12 tehtävään jaettujen taksikeräysten sijaintikohtainen summa. Spark-käyttöliittymän kautta interaktiivinen sovellus tarjoaa tarkat tehtävätason tilan, I/O- ja satunnaistiedot sekä linkit kunkin tämän vaiheen tehtävän vastaaviin lokeihin suoraan kannettavasta tietokoneesta, mikä mahdollistaa saumattoman vianetsintäkokemuksen.
Puhdistaa
Jos et enää halua säilyttää tässä viestissä luotuja resursseja, suorita seuraavat puhdistusvaiheet:
- Poista EMR Serverless -sovellus.
- Poista EMR Studio ja siihen liittyvät työtilat ja muistikirjat.
- Jos haluat poistaa loput resurssit, siirry CloudFormation-konsoliin, valitse pino ja valitse Poista.
Kaikki resurssit poistetaan paitsi S3-säilö, jonka poistokäytäntö on asetettu säilytettäväksi.
Yhteenveto
Viesti osoitti kuinka suorittaa interaktiivisia PySpark-työkuormia EMR Studiossa käyttämällä EMR Serverless -ohjelmaa laskentana. Voit myös rakentaa ja valvoa Spark-sovelluksia interaktiivisessa JupyterLab-työtilassa.
Tulevassa viestissä keskustelemme EMR Serverless Interactive -sovellusten lisäominaisuuksista, kuten:
- Työskentely resurssien, kuten Amazon RDS:n ja Amazon Redshiftin, kanssa VPC:ssäsi (esimerkiksi JDBC/ODBC-yhteyksiä varten)
- Tapahtumatyökuormien suorittaminen palvelimettomilla päätepisteillä
Jos tämä on ensimmäinen kerta, kun tutustut EMR Studioon, suosittelemme tutustumaan Amazon EMR -työpajat ja viitaten Luo EMR -studio.
Tietoja Tekijät
 Sekar Srinivasan on AWS:n johtava asiantuntijaratkaisuarkkitehti, joka keskittyy data-analyysiin ja tekoälyyn. Sekarilla on yli 20 vuoden kokemus tiedon parissa. Hän haluaa auttaa asiakkaita rakentamaan skaalautuvia ratkaisuja, jotka modernisoivat heidän arkkitehtuuriaan ja luovat oivalluksia heidän tiedoistaan. Vapaa-ajallaan hän työskentelee mielellään voittoa tavoittelemattomissa projekteissa, jotka keskittyvät vähäosaisten lasten koulutukseen.
Sekar Srinivasan on AWS:n johtava asiantuntijaratkaisuarkkitehti, joka keskittyy data-analyysiin ja tekoälyyn. Sekarilla on yli 20 vuoden kokemus tiedon parissa. Hän haluaa auttaa asiakkaita rakentamaan skaalautuvia ratkaisuja, jotka modernisoivat heidän arkkitehtuuriaan ja luovat oivalluksia heidän tiedoistaan. Vapaa-ajallaan hän työskentelee mielellään voittoa tavoittelemattomissa projekteissa, jotka keskittyvät vähäosaisten lasten koulutukseen.
 Disha Umarwani on vanhempi data-arkkitehti Amazonin asiantuntijapalveluista Global Health Care and LifeSciences -alalla. Hän on työskennellyt asiakkaiden kanssa tietostrategian suunnittelussa, arkkitehtuurissa ja toteuttamisessa mittakaavassa. Hän on erikoistunut Data Mesh -arkkitehtuurien suunnitteluun Enterprise-alustoille.
Disha Umarwani on vanhempi data-arkkitehti Amazonin asiantuntijapalveluista Global Health Care and LifeSciences -alalla. Hän on työskennellyt asiakkaiden kanssa tietostrategian suunnittelussa, arkkitehtuurissa ja toteuttamisessa mittakaavassa. Hän on erikoistunut Data Mesh -arkkitehtuurien suunnitteluun Enterprise-alustoille.
- SEO-pohjainen sisällön ja PR-jakelu. Vahvista jo tänään.
- PlatoData.Network Vertical Generatiivinen Ai. Vahvista itseäsi. Pääsy tästä.
- PlatoAiStream. Web3 Intelligence. Tietoa laajennettu. Pääsy tästä.
- PlatoESG. hiili, CleanTech, energia, ympäristö, Aurinko, Jätehuolto. Pääsy tästä.
- PlatonHealth. Biotekniikan ja kliinisten kokeiden älykkyys. Pääsy tästä.
- Lähde: https://aws.amazon.com/blogs/big-data/run-interactive-workloads-on-amazon-emr-serverless-from-amazon-emr-studio/