
Introduction
L'apprentissage automatique (ML) est un domaine d'étude qui se concentre sur le développement d'algorithmes pour apprendre automatiquement à partir de données, faire des prédictions et déduire des modèles sans qu'on leur dise explicitement comment le faire. Il vise à créer des systèmes qui s'améliorent automatiquement avec l'expérience et les données.
Cela peut être réalisé grâce à un apprentissage supervisé, où le modèle est formé à l'aide de données étiquetées pour faire des prédictions, ou par un apprentissage non supervisé, où le modèle cherche à découvrir des modèles ou des corrélations dans les données sans sorties cibles spécifiques à anticiper.
Le ML est devenu un outil indispensable et largement utilisé dans diverses disciplines, notamment l'informatique, la biologie, la finance et le marketing. Il a prouvé son utilité dans diverses applications telles que la classification d'images, le traitement du langage naturel et la détection de fraude.
Tâches d'apprentissage automatique
L'apprentissage automatique peut être globalement classé en trois tâches principales :
- Enseignement supervisé
- Apprentissage non supervisé
- Apprentissage par renforcement
Ici, nous nous concentrerons sur les deux premiers cas.
Apprentissage supervisé
L'apprentissage supervisé implique la formation d'un modèle sur des données étiquetées, où les données d'entrée sont associées à la sortie correspondante ou à la variable cible. L'objectif est d'apprendre une fonction qui peut mapper les données d'entrée à la sortie correcte. Les algorithmes d'apprentissage supervisé courants incluent la régression linéaire, la régression logistique, les arbres de décision et les machines à vecteurs de support.
Exemple de code d'apprentissage supervisé utilisant Python :
from sklearn.linear_model import LinearRegression model = LinearRegression() model.fit(X_train, y_train) predictions = model.predict(X_test)
Dans cet exemple de code simple, nous formons le LinearRegression algorithme de scikit-learn sur nos données de formation, puis appliquez-le pour obtenir des prédictions pour nos données de test.
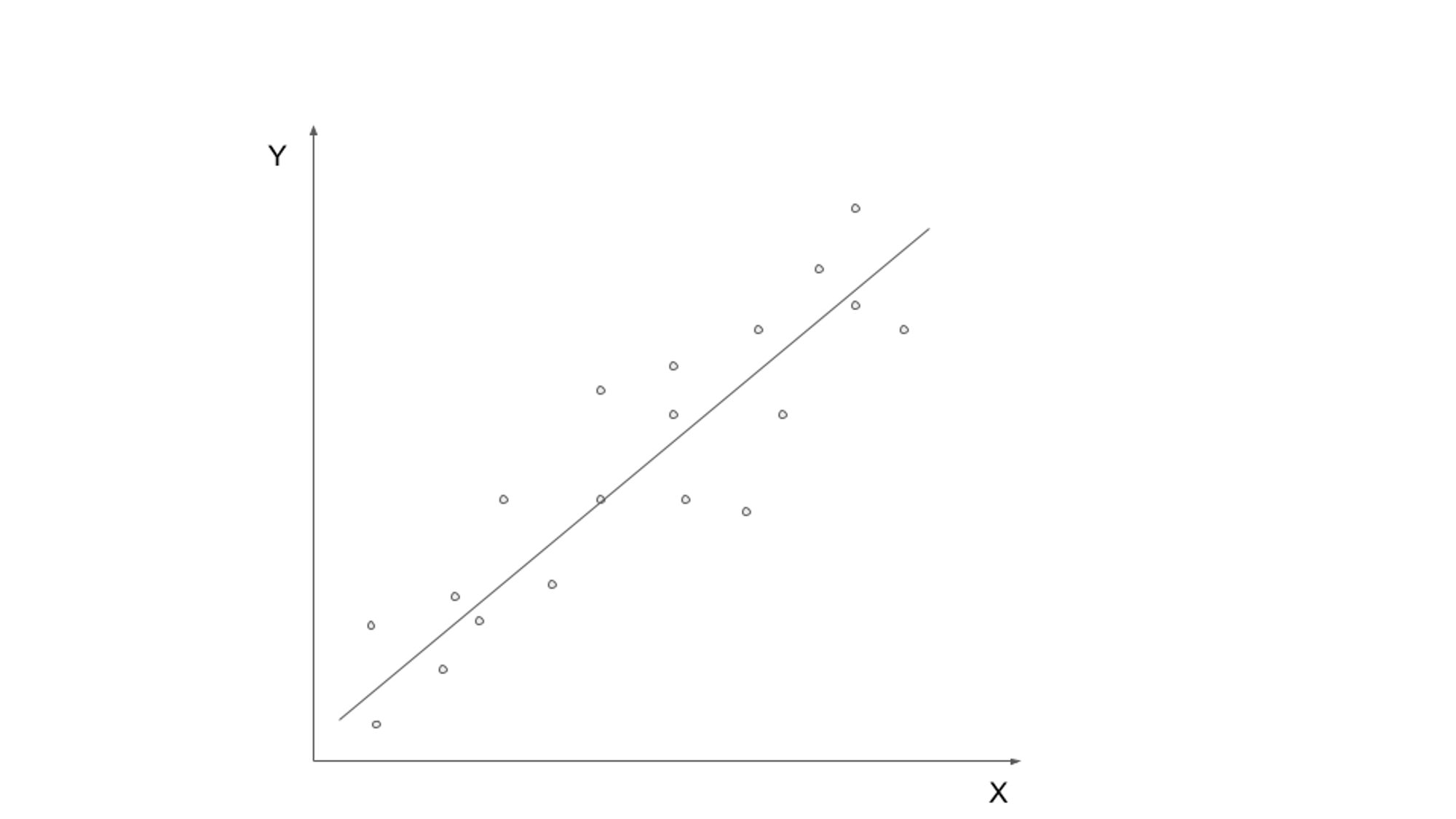
Un cas d'utilisation réel de l'apprentissage supervisé est la classification des spams par e-mail. Avec la croissance exponentielle de la communication par e-mail, l'identification et le filtrage des spams sont devenus cruciaux. En utilisant des algorithmes d'apprentissage supervisé, il est possible de former un modèle pour faire la distinction entre les e-mails légitimes et les spams sur la base de données étiquetées.
Le modèle d'apprentissage supervisé peut être formé sur un ensemble de données contenant des e-mails étiquetés comme "spam" ou "non spam". Le modèle apprend des modèles et des fonctionnalités à partir des données étiquetées, telles que la présence de certains mots-clés, la structure de l'e-mail ou les informations sur l'expéditeur de l'e-mail. Une fois le modèle formé, il peut être utilisé pour classer automatiquement les e-mails entrants comme spam ou non-spam, filtrant efficacement les messages indésirables.
Apprentissage non supervisé
Dans l'apprentissage non supervisé, les données d'entrée ne sont pas étiquetées et l'objectif est de découvrir des modèles ou des structures dans les données. Les algorithmes d'apprentissage non supervisé visent à trouver des représentations ou des clusters significatifs dans les données.
Des exemples d'algorithmes d'apprentissage non supervisés comprennent k-signifie clustering, classification hiérarchiqueet analyse en composantes principales (ACP).
Exemple de code d'apprentissage non supervisé :
from sklearn.cluster import KMeans model = KMeans(n_clusters=3) model.fit(X) predictions = model.predict(X_new)
Dans cet exemple de code simple, nous formons le KMeans algorithme de scikit-learn pour identifier trois clusters dans nos données, puis insérer de nouvelles données dans ces clusters.
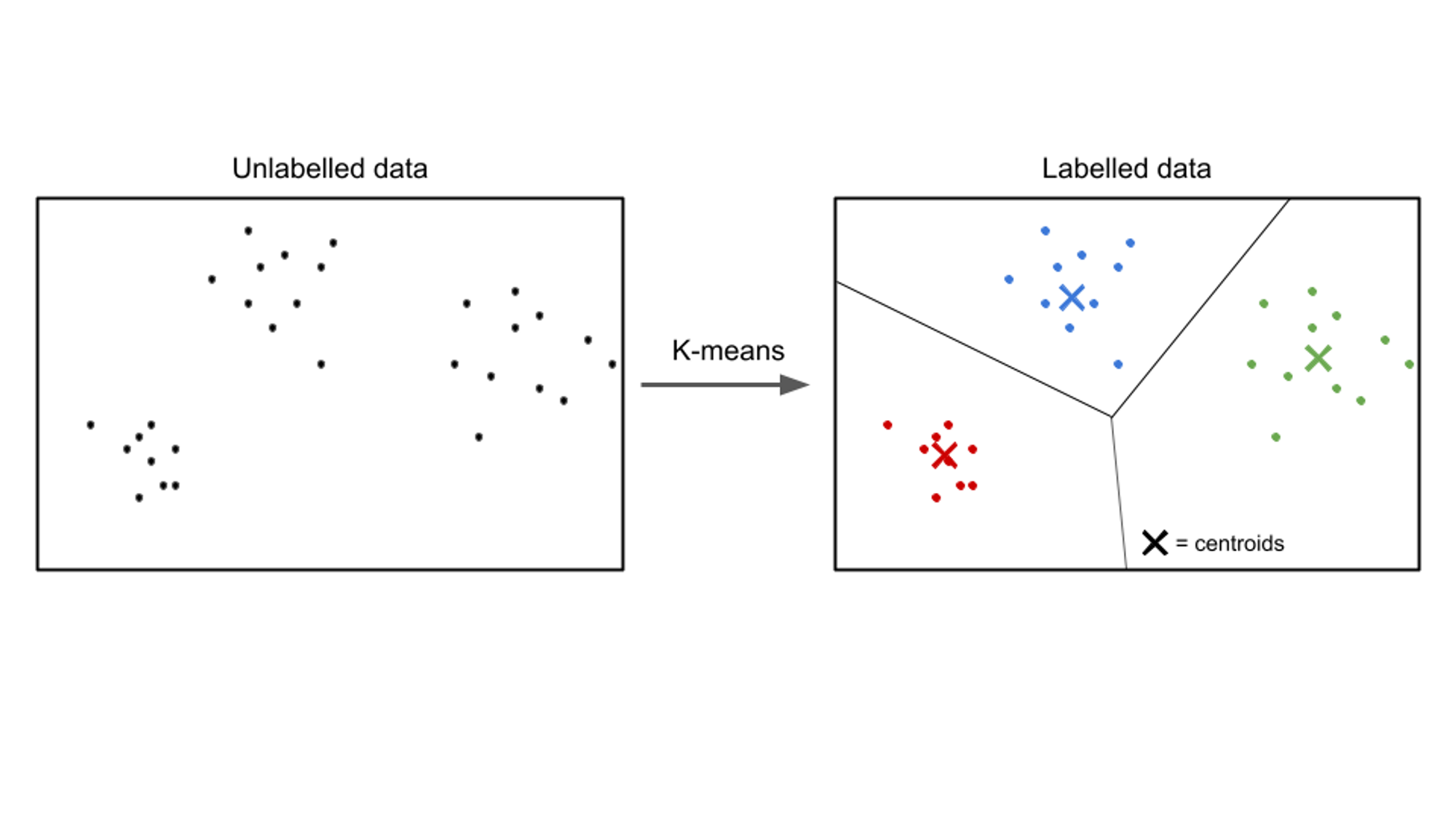
Un exemple de cas d'utilisation d'apprentissage non supervisé est la segmentation de la clientèle. Dans divers secteurs, les entreprises cherchent à mieux comprendre leur clientèle pour adapter leurs stratégies marketing, personnaliser leurs offres et optimiser l'expérience client. Des algorithmes d'apprentissage non supervisés peuvent être utilisés pour segmenter les clients en groupes distincts en fonction de leurs caractéristiques et comportements communs.
Consultez notre guide pratique et pratique pour apprendre Git, avec les meilleures pratiques, les normes acceptées par l'industrie et la feuille de triche incluse. Arrêtez de googler les commandes Git et en fait apprendre il!
En appliquant des techniques d'apprentissage non supervisé, telles que le clustering, les entreprises peuvent découvrir des modèles et des groupes significatifs dans leurs données clients. Par exemple, les algorithmes de clustering peuvent identifier des groupes de clients ayant des habitudes d'achat, des données démographiques ou des préférences similaires. Ces informations peuvent être exploitées pour créer des campagnes marketing ciblées, optimiser les recommandations de produits et améliorer la satisfaction client.
Principales classes d'algorithmes
Algorithmes d'apprentissage supervisé
-
Modèles linéaires : utilisés pour prédire des variables continues basées sur des relations linéaires entre les entités et la variable cible.
-
Modèles arborescents : construits à l'aide d'une série de décisions binaires pour effectuer des prédictions ou des classifications.
-
Modèles d'ensemble : méthode qui combine plusieurs modèles (arborescents ou linéaires) pour effectuer des prédictions plus précises.
-
Modèles de réseaux de neurones : méthodes vaguement basées sur le cerveau humain, où plusieurs fonctions fonctionnent comme des nœuds d'un réseau.
Algorithmes d'apprentissage non supervisé
-
Clustering hiérarchique : crée une hiérarchie de clusters en les fusionnant ou en les divisant de manière itérative.
-
Clustering non hiérarchique : divise les données en clusters distincts en fonction de la similarité.
-
Réduction de la dimensionnalité : réduit la dimensionnalité des données tout en préservant les informations les plus importantes.
Évaluation du modèle
Apprentissage supervisé
Pour évaluer les performances des modèles d'apprentissage supervisé, diverses mesures sont utilisées, notamment l'exactitude, la précision, le rappel, le score F1 et le ROC-AUC. Les techniques de validation croisée, telles que la validation croisée k-fold, peuvent aider à estimer les performances de généralisation du modèle.
Apprentissage non supervisé
L'évaluation des algorithmes d'apprentissage non supervisé est souvent plus difficile car il n'y a pas de vérité fondamentale. Des métriques telles que le score de silhouette ou l'inertie peuvent être utilisées pour évaluer la qualité des résultats de clustering. Les techniques de visualisation peuvent également fournir des informations sur la structure des clusters.
Trucs et astuces
Apprentissage supervisé
- Prétraitez et normalisez les données d'entrée pour améliorer les performances du modèle.
- Traitez les valeurs manquantes de manière appropriée, soit par imputation, soit par suppression.
- L'ingénierie des fonctionnalités peut améliorer la capacité du modèle à capturer des modèles pertinents.
Apprentissage non supervisé
- Choisissez le nombre approprié de clusters en fonction de la connaissance du domaine ou en utilisant des techniques telles que la méthode du coude.
- Envisagez différentes mesures de distance pour mesurer la similarité entre les points de données.
- Régularisez le processus de clustering pour éviter le surajustement.
En résumé, l'apprentissage automatique implique de nombreuses tâches, techniques, algorithmes, méthodes d'évaluation de modèles et conseils utiles. En comprenant ces aspects, les praticiens peuvent appliquer efficacement l'apprentissage automatique aux problèmes du monde réel et tirer des informations importantes des données. Les exemples de code donnés présentent l'utilisation d'algorithmes d'apprentissage supervisés et non supervisés, mettant en évidence leur mise en œuvre pratique.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- Financement EVM. Interface unifiée pour la finance décentralisée. Accéder ici.
- Groupe de médias quantiques. IR/PR amplifié. Accéder ici.
- PlatoAiStream. Intelligence des données Web3. Connaissance Amplifiée. Accéder ici.
- La source: https://stackabuse.com/supervised-learning-vs-unsupervised-learning-algorithms/