
Dans la gestion d'actifs, les gestionnaires de portefeuille doivent surveiller de près les entreprises de leur univers d'investissement pour identifier les risques et les opportunités et orienter les décisions d'investissement. Le suivi des événements directs tels que les rapports sur les bénéfices ou les dégradations de crédit est simple : vous pouvez configurer des alertes pour informer les responsables des actualités contenant des noms d'entreprise. Cependant, il est difficile de détecter les impacts de deuxième et troisième ordre résultant d'événements chez les fournisseurs, les clients, les partenaires ou d'autres entités de l'écosystème d'une entreprise.
Par exemple, une perturbation de la chaîne d’approvisionnement chez un fournisseur clé aurait probablement un impact négatif sur les fabricants en aval. Ou encore, la perte d'un client important pour un client majeur pose un risque de demande pour le fournisseur. Très souvent, ces événements ne font pas la une des journaux mettant directement en avant l’entreprise concernée, mais il est néanmoins important d’y prêter attention. Dans cet article, nous démontrons une solution automatisée combinant des graphiques de connaissances et intelligence artificielle générative (IA) pour faire apparaître ces risques en croisant les cartes des relations avec les actualités en temps réel.
Globalement, cela implique deux étapes : premièrement, construire les relations complexes entre les entreprises (clients, fournisseurs, dirigeants) dans un graphe de connaissances. Deuxièmement, utiliser cette base de données graphique ainsi que l’IA générative pour détecter les impacts de deuxième et troisième ordre des événements d’actualité. Par exemple, cette solution peut mettre en évidence que les retards chez un fournisseur de pièces détachées peuvent perturber la production des constructeurs automobiles en aval d'un portefeuille, même si aucun n'est directement référencé.
Avec AWS, vous pouvez déployer cette solution dans une architecture sans serveur, évolutive et entièrement basée sur les événements. Cet article présente une preuve de concept basée sur deux services AWS clés, bien adaptés à la représentation graphique des connaissances et au traitement du langage naturel : Amazone Neptune ainsi que Socle amazonien. Neptune est un service de base de données graphique rapide, fiable et entièrement géré qui facilite la création et l'exécution d'applications fonctionnant avec des ensembles de données hautement connectés. Amazon Bedrock est un service entièrement géré qui offre un choix de modèles de base (FM) hautes performances provenant de grandes sociétés d'IA telles que AI21 Labs, Anthropic, Cohere, Meta, Stability AI et Amazon via une API unique, ainsi qu'un large ensemble de capacités pour créer des applications d’IA génératives avec sécurité, confidentialité et IA responsable.
Dans l’ensemble, ce prototype démontre l’art du possible avec les graphiques de connaissances et l’IA générative, en dérivant des signaux en connectant des points disparates. Ce que les professionnels de l’investissement doivent retenir, c’est la capacité de rester au courant des évolutions plus proches du signal tout en évitant le bruit.
Construire le graphe de connaissances
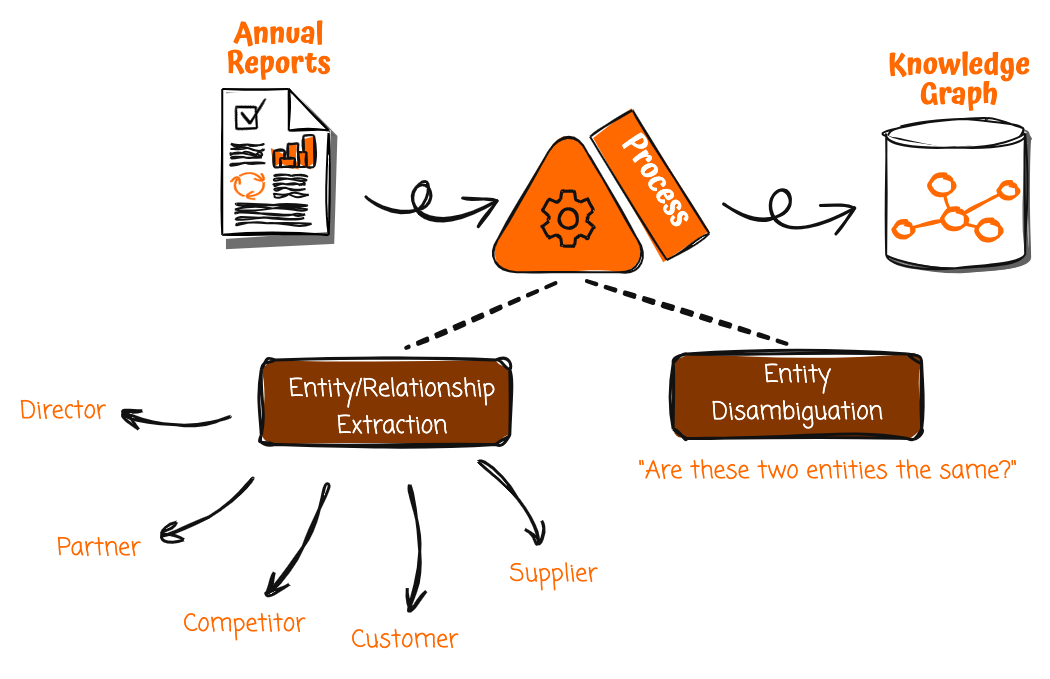
La première étape de cette solution consiste à créer un graphique de connaissances. Les rapports annuels de l'entreprise constituent une source de données précieuse, mais souvent négligée, pour les graphiques de connaissances. Étant donné que les publications officielles des entreprises sont soumises à un examen minutieux avant leur publication, les informations qu'elles contiennent sont susceptibles d'être exactes et fiables. Cependant, les rapports annuels sont rédigés dans un format non structuré destiné à une lecture humaine plutôt qu'à une consommation automatique. Pour libérer leur potentiel, vous avez besoin d’un moyen d’extraire et de structurer systématiquement la richesse des faits et des relations qu’ils contiennent.
Avec des services d'IA générative comme Amazon Bedrock, vous avez désormais la possibilité d'automatiser ce processus. Vous pouvez prendre un rapport annuel et déclencher un pipeline de traitement pour ingérer le rapport, le diviser en morceaux plus petits et appliquer la compréhension du langage naturel pour extraire les entités et les relations importantes.
Par exemple, une phrase indiquant que « [Entreprise A] a élargi sa flotte européenne de livraison électrique avec une commande de 1,800 XNUMX fourgons électriques de [Entreprise B] » permettrait à Amazon Bedrock d'identifier les éléments suivants :
- [Entreprise A] en tant que client
- [Entreprise B] en tant que fournisseur
- Une relation fournisseur entre [Entreprise A] et [Entreprise B]
- Détails de la relation du « fournisseur de camionnettes de livraison électriques »
L'extraction de telles données structurées à partir de documents non structurés nécessite de fournir des invites soigneusement conçues aux grands modèles de langage (LLM) afin qu'ils puissent analyser le texte et extraire des entités telles que des entreprises et des personnes, ainsi que des relations telles que des clients, des fournisseurs, etc. Les invites contiennent des instructions claires sur ce qu'il faut rechercher et la structure dans laquelle renvoyer les données. En répétant ce processus dans l'ensemble du rapport annuel, vous pouvez extraire les entités et les relations pertinentes pour construire un riche graphique de connaissances.
Cependant, avant de valider les informations extraites dans le graphe de connaissances, vous devez d'abord lever l'ambiguïté sur les entités. Par exemple, il peut déjà y avoir une autre entité « [Société A] » dans le graphe de connaissances, mais elle peut représenter une organisation différente portant le même nom. Amazon Bedrock peut raisonner et comparer les attributs tels que le domaine d'activité, le secteur d'activité, les industries génératrices de revenus et les relations avec d'autres entités pour déterminer si les deux entités sont réellement distinctes. Cela évite la fusion inexacte de sociétés non liées en une seule entité.
Une fois la désambiguïsation terminée, vous pouvez ajouter de manière fiable de nouvelles entités et relations dans votre graphique de connaissances Neptune, en l'enrichissant des faits extraits des rapports annuels. Au fil du temps, l'ingestion de données fiables et l'intégration de sources de données plus fiables aideront à créer un graphique de connaissances complet pouvant prendre en charge la révélation d'informations via des requêtes graphiques et des analyses.
Cette automatisation permise par l'IA générative permet de traiter des milliers de rapports annuels et débloque un atout inestimable pour la conservation des graphiques de connaissances qui autrement resterait inexploité en raison de l'effort manuel prohibitif nécessaire.
La capture d'écran suivante montre un exemple de l'exploration visuelle possible dans une base de données de graphiques Neptune à l'aide de l'outil Explorateur de graphiques outil.

Traiter les articles de presse

La prochaine étape de la solution consiste à enrichir automatiquement les flux d'actualités des gestionnaires de portefeuille et à mettre en évidence les articles pertinents à leurs intérêts et investissements. Pour le fil d'actualité, les gestionnaires de portefeuille peuvent s'abonner à n'importe quel fournisseur d'actualités tiers via Échange de données AWS ou une autre API d'actualités de leur choix.
Lorsqu'un article d'actualité entre dans le système, un pipeline d'ingestion est appelé pour traiter le contenu. À l'aide de techniques similaires au traitement des rapports annuels, Amazon Bedrock est utilisé pour extraire les entités, les attributs et les relations de l'article d'actualité, qui sont ensuite utilisés pour lever l'ambiguïté par rapport au graphe de connaissances afin d'identifier l'entité correspondante dans le graphe de connaissances.
Le graphe de connaissances contient des connexions entre les entreprises et les personnes, et en reliant les entités d'articles aux nœuds existants, vous pouvez identifier si des sujets se trouvent à moins de deux sauts des entreprises dans lesquelles le gestionnaire de portefeuille a investi ou s'intéresse. La recherche d'une telle connexion indique le L'article peut être pertinent pour le gestionnaire de portefeuille, et comme les données sous-jacentes sont représentées dans un graphique de connaissances, elles peuvent être visualisées pour aider le gestionnaire de portefeuille à comprendre pourquoi et comment ce contexte est pertinent. En plus d'identifier les connexions au portefeuille, vous pouvez également utiliser Amazon Bedrock pour effectuer une analyse des sentiments sur les entités référencées.
Le résultat final est un fil d'actualité enrichi faisant apparaître des articles susceptibles d'avoir un impact sur les domaines d'intérêt et d'investissement du gestionnaire de portefeuille.
Vue d'ensemble de la solution
L'architecture globale de la solution ressemble au schéma suivant.

Le flux de travail comprend les étapes suivantes :
- Un utilisateur télécharge des rapports officiels (au format PDF) sur un Service de stockage simple Amazon (Amazon S3). Les rapports doivent être des rapports officiellement publiés afin de minimiser l'inclusion de données inexactes dans votre graphique de connaissances (par opposition aux actualités et aux tabloïds).
- La notification d'événement S3 appelle un AWS Lambda fonction, qui envoie le compartiment S3 et le nom du fichier à un Service Amazon Simple Queue (Amazon SQS). La file d'attente Premier entré, premier sorti (FIFO) garantit que le processus d'ingestion du rapport est effectué de manière séquentielle afin de réduire le risque d'introduction de données en double dans votre graphique de connaissances.
- An Amazon Event Bridge un événement temporel s'exécute toutes les minutes pour démarrer l'exécution d'un Fonctions d'étape AWS machine à états de manière asynchrone.
- La machine à états Step Functions exécute une série de tâches pour traiter le document téléchargé en extrayant les informations clés et en les insérant dans votre graphique de connaissances :
- Recevez le message de file d'attente d'Amazon SQS.
- Téléchargez le fichier de rapport PDF depuis Amazon S3, divisez-le en plusieurs morceaux de texte plus petits (environ 1,000 XNUMX mots) pour le traitement et stockez les morceaux de texte dans Amazon DynamoDB.
- Utilisez Claude v3 Sonnet d'Anthropic sur Amazon Bedrock pour traiter les premiers morceaux de texte afin de déterminer l'entité principale à laquelle le rapport fait référence, ainsi que les attributs pertinents (tels que l'industrie).
- Récupérez les morceaux de texte de DynamoDB et pour chaque morceau de texte, appelez une fonction Lambda pour extraire les entités (telles qu'une entreprise ou une personne) et sa relation (client, fournisseur, partenaire, concurrent ou directeur) avec l'entité principale à l'aide d'Amazon Bedrock. .
- Consolidez toutes les informations extraites.
- Filtrez le bruit et les entités non pertinentes (par exemple, les termes génériques tels que « consommateurs ») à l'aide d'Amazon Bedrock.
- Utilisez Amazon Bedrock pour lever l'ambiguïté en raisonnant à l'aide des informations extraites par rapport à la liste des entités similaires du graphe de connaissances. Si l'entité n'existe pas, insérez-la. Sinon, utilisez l'entité qui existe déjà dans le knowledge graph. Insérez toutes les relations extraites.
- Nettoyez en supprimant le message de la file d'attente SQS et le fichier S3.
- Un utilisateur accède à une application Web basée sur React pour afficher les articles d'actualité complétés par les informations sur l'entité, le sentiment et le chemin de connexion.
- À l'aide de l'application Web, l'utilisateur spécifie le nombre de sauts (par défaut N=2) sur le chemin de connexion à surveiller.
- A l'aide de l'application web, l'utilisateur précise la liste des entités à suivre.
- Pour générer des informations fictives, l'utilisateur choisit Générer des exemples de nouvelles pour générer 10 exemples d'articles d'actualité financière avec un contenu aléatoire à intégrer dans le processus d'ingestion d'actualités. Le contenu est généré à l'aide d'Amazon Bedrock et est purement fictif.
- Pour télécharger les actualités actuelles, l'utilisateur choisit Télécharger les dernières nouvelles pour télécharger les principales nouvelles du jour (propulsé par NewsAPI.org).
- Le fichier d'actualités (format TXT) est téléchargé dans un compartiment S3. Les étapes 8 et 9 téléchargent automatiquement les actualités dans le compartiment S3, mais vous pouvez également créer des intégrations avec votre fournisseur de nouvelles préféré tel qu'AWS Data Exchange ou tout autre fournisseur de nouvelles tiers pour déposer des articles d'actualité sous forme de fichiers dans le compartiment S3. Le contenu du fichier de données d'actualité doit être formaté comme suit :
<date>{dd mmm yyyy}</date><title>{title}</title><text>{news content}</text>. - La notification d'événement S3 envoie le nom du compartiment ou du fichier S3 à Amazon SQS (standard), qui appelle plusieurs fonctions Lambda pour traiter les données d'actualité en parallèle :
- Utilisez Amazon Bedrock pour extraire les entités mentionnées dans l'actualité ainsi que toutes les informations, relations et sentiments associés à l'entité mentionnée.
- Vérifiez par rapport au graphe de connaissances et utilisez Amazon Bedrock pour effectuer une levée d'ambiguïté en raisonnant à l'aide des informations disponibles dans les actualités et dans le graphe de connaissances pour identifier l'entité correspondante.
- Une fois l'entité localisée, recherchez et renvoyez tous les chemins de connexion se connectant aux entités marquées de
INTERESTED=YESdans le graphe de connaissances qui se trouvent à N = 2 sauts.
- L'application Web s'actualise automatiquement toutes les secondes pour extraire le dernier ensemble d'actualités traitées à afficher sur l'application Web.
Déployer le prototype
Vous pouvez déployer la solution prototype et commencer à expérimenter vous-même. Le prototype est disponible auprès de GitHub et comprend des détails sur les éléments suivants :
- Conditions préalables au déploiement
- Étapes de déploiement
- Étapes de nettoyage
Résumé
Cet article présente une solution de validation de principe pour aider les gestionnaires de portefeuille à détecter les risques de deuxième et troisième ordre liés aux événements d'actualité, sans référence directe aux entreprises qu'ils suivent. En combinant un graphique de connaissances des relations complexes de l'entreprise avec une analyse de l'actualité en temps réel à l'aide de l'IA générative, les impacts en aval peuvent être mis en évidence, tels que les retards de production dus à des problèmes de fournisseurs.
Bien qu'il ne s'agisse que d'un prototype, cette solution montre la promesse des graphes de connaissances et des modèles de langage pour relier des points et dériver des signaux à partir du bruit. Ces technologies peuvent aider les professionnels de l’investissement en révélant les risques plus rapidement grâce à la cartographie et au raisonnement des relations. Dans l’ensemble, il s’agit d’une application prometteuse des bases de données graphiques et de l’IA qui mérite d’être explorée pour améliorer l’analyse des investissements et la prise de décision.
Si cet exemple d'IA générative dans les services financiers intéresse votre entreprise, ou si vous avez une idée similaire, contactez votre responsable de compte AWS et nous serons ravis d'explorer davantage avec vous.
À propos de l’auteur
 Xan Huang est architecte de solutions senior chez AWS et est basé à Singapour. Il travaille avec de grandes institutions financières pour concevoir et créer des solutions cloud sécurisées, évolutives et hautement disponibles. En dehors du travail, Xan passe la plupart de son temps libre avec sa famille et se laisse diriger par sa fille de 3 ans. Vous pouvez trouver Xan sur LinkedIn.
Xan Huang est architecte de solutions senior chez AWS et est basé à Singapour. Il travaille avec de grandes institutions financières pour concevoir et créer des solutions cloud sécurisées, évolutives et hautement disponibles. En dehors du travail, Xan passe la plupart de son temps libre avec sa famille et se laisse diriger par sa fille de 3 ans. Vous pouvez trouver Xan sur LinkedIn.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://aws.amazon.com/blogs/machine-learning/uncover-hidden-connections-in-unstructured-financial-data-with-amazon-bedrock-and-amazon-neptune/