
Cet article est co-écrit par Goktug Cinar, Michael Binder et Adrian Horvath du Bosch Center for Artificial Intelligence (BCAI).
La prévision des revenus est une tâche difficile mais cruciale pour les décisions commerciales stratégiques et la planification budgétaire dans la plupart des organisations. Souvent, la prévision des revenus est effectuée manuellement par des analystes financiers et est à la fois chronophage et subjective. Ces efforts manuels sont particulièrement difficiles pour les entreprises multinationales à grande échelle qui ont besoin de prévisions de revenus pour un large éventail de groupes de produits et de zones géographiques à plusieurs niveaux de granularité. Cela nécessite non seulement de la précision mais aussi une cohérence hiérarchique des prévisions.
Bosch est une société multinationale avec des entités opérant dans plusieurs secteurs, notamment l'automobile, les solutions industrielles et les biens de consommation. Compte tenu de l'impact de prévisions de revenus précises et cohérentes sur des opérations commerciales saines, le Centre Bosch pour l'intelligence artificielle (BCAI) a investi massivement dans l'utilisation de l'apprentissage automatique (ML) pour améliorer l'efficacité et la précision des processus de planification financière. L'objectif est d'alléger les processus manuels en fournissant des prévisions de revenus de base raisonnables via ML, avec seulement des ajustements occasionnels nécessaires par les analystes financiers en utilisant leurs connaissances du secteur et du domaine.
Pour atteindre cet objectif, BCAI a développé un cadre de prévision interne capable de fournir des prévisions hiérarchiques à grande échelle via des ensembles personnalisés d'un large éventail de modèles de base. Un méta-apprenant sélectionne les modèles les plus performants en fonction des caractéristiques extraites de chaque série temporelle. Les prévisions des modèles sélectionnés sont ensuite moyennées pour obtenir la prévision agrégée. La conception architecturale est modularisée et extensible grâce à la mise en œuvre d'une interface de style REST, qui permet une amélioration continue des performances via l'inclusion de modèles supplémentaires.
BCAI s'est associé au Laboratoire de solutions Amazon ML (MLSL) pour intégrer les dernières avancées des modèles basés sur les réseaux de neurones profonds (DNN) pour la prévision des revenus. Les progrès récents des prévisionnistes neuronaux ont démontré des performances de pointe pour de nombreux problèmes de prévision pratiques. Par rapport aux modèles de prévision traditionnels, de nombreux prévisionnistes neuronaux peuvent incorporer des covariables ou des métadonnées supplémentaires de la série chronologique. Nous incluons CNN-QR et DeepAR+, deux modèles prêts à l'emploi dans Prévisions Amazon, ainsi qu'un modèle Transformer personnalisé formé à l'aide Amazon Sage Maker. Les trois modèles couvrent un ensemble représentatif des dorsales d'encodeurs souvent utilisées dans les prévisionnistes neuronaux : réseau de neurones convolutionnels (CNN), réseau de neurones récurrents séquentiels (RNN) et encodeurs à base de transformateurs.
L'un des principaux défis auxquels était confronté le partenariat BCAI-MLSL était de fournir des prévisions solides et raisonnables sous l'impact du COVID-19, un événement mondial sans précédent entraînant une grande volatilité sur les résultats financiers des entreprises mondiales. Étant donné que les prévisionnistes neuronaux sont formés sur des données historiques, les prévisions générées sur la base de données hors distribution des périodes les plus volatiles pourraient être inexactes et peu fiables. Par conséquent, nous avons proposé l'ajout d'un mécanisme d'attention masquée dans l'architecture Transformer pour résoudre ce problème.
Les prévisionnistes neuronaux peuvent être regroupés en un seul modèle d'ensemble, ou incorporés individuellement dans l'univers du modèle de Bosch, et facilement accessibles via les points de terminaison de l'API REST. Nous proposons une approche pour regrouper les prévisionnistes neuronaux à travers des résultats de backtest, qui fournit des performances compétitives et robustes dans le temps. De plus, nous avons étudié et évalué un certain nombre de techniques classiques de rapprochement hiérarchique pour nous assurer que les prévisions s'agrègent de manière cohérente entre les groupes de produits, les zones géographiques et les organisations commerciales.
Dans cet article, nous démontrons ce qui suit :
- Comment appliquer la formation de modèle personnalisé Forecast et SageMaker pour les problèmes de prévision hiérarchiques à grande échelle de séries chronologiques
- Comment combiner des modèles personnalisés avec des modèles prêts à l'emploi de Forecast
- Comment réduire l'impact d'événements perturbateurs tels que le COVID-19 sur les problèmes de prévision
- Comment créer un workflow de prévision de bout en bout sur AWS
Défis
Nous avons relevé deux défis : créer des prévisions de revenus hiérarchiques à grande échelle et l'impact de la pandémie de COVID-19 sur les prévisions à long terme.
Prévision hiérarchique des revenus à grande échelle
Les analystes financiers sont chargés de prévoir les chiffres financiers clés, y compris les revenus, les coûts opérationnels et les dépenses de R&D. Ces métriques fournissent des informations sur la planification des activités à différents niveaux d'agrégation et permettent une prise de décision basée sur les données. Toute solution de prévision automatisée doit fournir des prévisions à n'importe quel niveau arbitraire d'agrégation des secteurs d'activité. Chez Bosch, les agrégations peuvent être imaginées comme des séries chronologiques groupées comme une forme plus générale de structure hiérarchique. La figure suivante montre un exemple simplifié avec une structure à deux niveaux, qui imite la structure hiérarchique de prévision des revenus chez Bosch. Le revenu total est divisé en plusieurs niveaux d'agrégations en fonction du produit et de la région.
Le nombre total de séries chronologiques qui doivent être prévues chez Bosch se chiffre en millions. Notez que la série chronologique de niveau supérieur peut être divisée par produits ou par régions, créant ainsi plusieurs chemins vers les prévisions de niveau inférieur. Les revenus doivent être prévus à chaque nœud de la hiérarchie avec un horizon de prévision de 12 mois dans le futur. Des données historiques mensuelles sont disponibles.
La structure hiérarchique peut être représentée sous la forme suivante avec la notation d'une matrice de sommation S (Hyndman et Athanasopoulos):
![]()
Dans cette équation, Y est égal à ce qui suit :

Ici, b représente la série chronologique de niveau inférieur au moment t.
Impacts de la pandémie de COVID-19
La pandémie de COVID-19 a posé des défis importants pour les prévisions en raison de ses effets perturbateurs et sans précédent sur presque tous les aspects du travail et de la vie sociale. Pour les prévisions de revenus à long terme, la perturbation a également entraîné des impacts inattendus en aval. Pour illustrer ce problème, la figure suivante montre un exemple de série chronologique où les revenus des produits ont connu une baisse significative au début de la pandémie et se sont progressivement redressés par la suite. Un modèle de prévision neuronal typique prendra des données sur les revenus, y compris la période COVID hors distribution (OOD) comme entrée de contexte historique, ainsi que la vérité de terrain pour la formation du modèle. Par conséquent, les prévisions produites ne sont plus fiables.

Approches de modélisation
Dans cette section, nous discutons de nos différentes approches de modélisation.
Prévisions Amazon
Forecast est un service AI/ML entièrement géré d'AWS qui fournit des modèles de prévision de séries chronologiques préconfigurés à la pointe de la technologie. Il combine ces offres avec ses capacités internes d'optimisation automatisée des hyperparamètres, de modélisation d'ensemble (pour les modèles fournis par Forecast) et de génération de prévisions probabilistes. Cela vous permet d'ingérer facilement des ensembles de données personnalisés, de prétraiter les données, de former des modèles de prévision et de générer des prévisions fiables. La conception modulaire du service nous permet en outre d'interroger et de combiner facilement des prédictions à partir de modèles personnalisés supplémentaires développés en parallèle.
Nous intégrons deux prévisionnistes neuronaux de Forecast : CNN-QR et DeepAR+. Les deux sont des méthodes d'apprentissage en profondeur supervisées qui forment un modèle global pour l'ensemble de données de la série chronologique. Les modèles CNNQR et DeepAR + peuvent prendre en charge des informations de métadonnées statiques sur chaque série temporelle, qui sont le produit, la région et l'organisation commerciale correspondants dans notre cas. Ils ajoutent également automatiquement des caractéristiques temporelles telles que le mois de l'année dans le cadre de l'entrée du modèle.
Transformateur avec masques d'attention pour COVID
L'architecture du transformateur (Vaswani et coll.), conçu à l'origine pour le traitement du langage naturel (TLN), est récemment devenu un choix architectural populaire pour la prévision de séries chronologiques. Ici, nous avons utilisé l'architecture Transformer décrite dans Zhou et coll. sans attention logarithmique probabiliste clairsemée. Le modèle utilise une conception d'architecture typique en combinant un encodeur et un décodeur. Pour la prévision des revenus, nous configurons le décodeur pour produire directement la prévision de l'horizon de 12 mois au lieu de générer la prévision mois par mois de manière autorégressive. En fonction de la fréquence de la série chronologique, des caractéristiques supplémentaires liées au temps, telles que le mois de l'année, sont ajoutées en tant que variable d'entrée. Des variables catégorielles supplémentaires décrivant les méta-informations (produit, région, organisation commerciale) sont introduites dans le réseau via une couche d'intégration entraînable.
Le schéma suivant illustre l'architecture Transformer et le mécanisme de masquage d'attention. Le masquage d'attention est appliqué dans toutes les couches d'encodeur et de décodeur, comme surligné en orange, pour empêcher les données OOD d'affecter les prévisions.

Nous atténuons l'impact des fenêtres de contexte OOD en ajoutant des masques d'attention. Le modèle est formé pour accorder très peu d'attention à la période COVID qui contient des valeurs aberrantes via le masquage, et effectue des prévisions avec des informations masquées. Le masque d'attention est appliqué dans chaque couche de l'architecture du décodeur et du codeur. La fenêtre masquée peut être spécifiée manuellement ou via un algorithme de détection des valeurs aberrantes. De plus, lors de l'utilisation d'une fenêtre temporelle contenant des valeurs aberrantes comme étiquettes d'apprentissage, les pertes ne sont pas rétropropagées. Cette méthode basée sur le masquage d'attention peut être appliquée pour gérer les perturbations et les cas OOD apportés par d'autres événements rares et améliorer la robustesse des prévisions.
Modèle d'ensemble
L'ensemble de modèles surpasse souvent les modèles uniques pour la prévision - il améliore la généralisabilité du modèle et est plus efficace pour gérer les données de séries chronologiques avec des caractéristiques variables en termes de périodicité et d'intermittence. Nous incorporons une série de stratégies d'ensemble de modèles pour améliorer les performances du modèle et la robustesse des prévisions. Une forme courante d'ensemble de modèles d'apprentissage en profondeur consiste à agréger les résultats d'exécutions de modèles avec différentes initialisations de poids aléatoires ou à différentes époques d'apprentissage. Nous utilisons cette stratégie pour obtenir des prévisions pour le modèle Transformer.
Pour construire davantage un ensemble au-dessus de différentes architectures de modèles, telles que Transformer, CNNQR et DeepAR +, nous utilisons une stratégie d'ensemble pan-modèle qui sélectionne les modèles les plus performants pour chaque série chronologique en fonction des résultats du backtest et obtient leur moyennes. Étant donné que les résultats des backtests peuvent être exportés directement à partir de modèles de prévision formés, cette stratégie nous permet de tirer parti de services clés en main tels que Forecast avec des améliorations obtenues à partir de modèles personnalisés tels que Transformer. Une telle approche d'ensemble de modèles de bout en bout ne nécessite pas la formation d'un méta-apprenant ni le calcul de caractéristiques de séries chronologiques pour la sélection de modèles.
Réconciliation hiérarchique
Le cadre est adaptatif pour incorporer un large éventail de techniques en tant qu'étapes de post-traitement pour le rapprochement hiérarchique des prévisions, y compris le rapprochement ascendant (BU), le rapprochement descendant avec les proportions de prévision (TDFP), les moindres carrés ordinaires (OLS) et les moindres carrés pondérés ( WLS). Tous les résultats expérimentaux de cet article sont rapportés à l'aide d'un rapprochement descendant avec les proportions de prévision.
Aperçu de l'architecture
Nous avons développé un flux de travail automatisé de bout en bout sur AWS pour générer des prévisions de revenus à l'aide de services tels que Forecast, SageMaker, Service de stockage simple Amazon (Amazon S3), AWS Lambda, Fonctions d'étape AWSet Kit de développement AWS Cloud (AWSCDK). La solution déployée fournit des prévisions de séries chronologiques individuelles via une API REST utilisant Passerelle d'API Amazon, en renvoyant les résultats au format JSON prédéfini.
Le diagramme suivant illustre le workflow de prévision de bout en bout.

Les principales considérations de conception pour l'architecture sont la polyvalence, les performances et la convivialité. Le système doit être suffisamment polyvalent pour incorporer un ensemble diversifié d'algorithmes pendant le développement et le déploiement, avec un minimum de modifications requises, et peut être facilement étendu lors de l'ajout de nouveaux algorithmes à l'avenir. Le système devrait également ajouter un minimum de frais généraux et prendre en charge la formation parallèle pour Forecast et SageMaker afin de réduire le temps de formation et d'obtenir plus rapidement les dernières prévisions. Enfin, le système doit être simple à utiliser à des fins d'expérimentation.
Le workflow de bout en bout passe séquentiellement par les modules suivants :
- Un module de prétraitement pour le reformatage et la transformation des données
- Un module de formation de modèle incorporant à la fois le modèle de prévision et le modèle personnalisé sur SageMaker (les deux fonctionnent en parallèle)
- Un module de post-traitement prenant en charge l'ensemble de modèles, la réconciliation hiérarchique, les métriques et la génération de rapports
Step Functions organise et orchestre le flux de travail de bout en bout en tant que machine d'état. L'exécution de la machine d'état est configurée avec un fichier JSON contenant toutes les informations nécessaires, y compris l'emplacement des fichiers CSV de revenus historiques dans Amazon S3, l'heure de début prévue et les paramètres d'hyperparamètres du modèle pour exécuter le workflow de bout en bout. Des appels asynchrones sont créés pour paralléliser la formation du modèle dans la machine d'état à l'aide des fonctions Lambda. Toutes les données historiques, les fichiers de configuration, les résultats des prévisions, ainsi que les résultats intermédiaires tels que les résultats de backtesting sont stockés dans Amazon S3. L'API REST est construite sur Amazon S3 pour fournir une interface interrogeable pour interroger les résultats des prévisions. Le système peut être étendu pour intégrer de nouveaux modèles de prévision et des fonctions de support telles que la génération de rapports de visualisation des prévisions.
Evaluation
Dans cette section, nous détaillons le montage de l'expérience. Les composants clés incluent l'ensemble de données, les métriques d'évaluation, les fenêtres de backtest, ainsi que la configuration et la formation du modèle.
Ensemble de données
Pour protéger la confidentialité financière de Bosch tout en utilisant un ensemble de données significatif, nous avons utilisé un ensemble de données synthétiques présentant des caractéristiques statistiques similaires à un ensemble de données sur les revenus réels d'une unité commerciale de Bosch. L'ensemble de données contient 1,216 2016 séries chronologiques au total avec des revenus enregistrés à une fréquence mensuelle, couvrant de janvier 2022 à avril 877. L'ensemble de données est livré avec XNUMX séries chronologiques au niveau le plus granulaire (série chronologique inférieure), avec une structure de série chronologique groupée correspondante représentée sous la forme d'une matrice de sommation S. Chaque série temporelle est associée à trois attributs catégoriels statiques, qui correspondent à la catégorie de produit, à la région et à l'unité organisationnelle dans le jeu de données réel (anonymisé dans les données synthétiques).
Mesures d'évaluation
Nous utilisons l'erreur absolue en pourcentage de l'arc tangente médiane (médiane-MAAPE) et la MAAPE pondérée pour évaluer les performances du modèle et effectuer une analyse comparative, qui sont les mesures standard utilisées chez Bosch. MAAPE corrige les lacunes de la métrique d'erreur moyenne absolue en pourcentage (MAPE) couramment utilisée dans le contexte commercial. Médiane-MAAPE donne un aperçu des performances du modèle en calculant la médiane des MAAPE calculées individuellement sur chaque série temporelle. Weighted-MAAPE rapporte une combinaison pondérée des MAAPE individuels. Les pondérations correspondent à la proportion des revenus de chaque série chronologique par rapport aux revenus agrégés de l'ensemble de données. Le MAAPE pondéré reflète mieux les impacts commerciaux en aval de la précision des prévisions. Les deux métriques sont rapportées sur l'ensemble de données complet de 1,216 XNUMX séries chronologiques.
Fenêtres de backtest
Nous utilisons des fenêtres de backtest de 12 mois glissants pour comparer les performances des modèles. La figure suivante illustre les fenêtres de backtest utilisées dans les expériences et met en évidence les données correspondantes utilisées pour la formation et l'optimisation des hyperparamètres (HPO). Pour les fenêtres de backtest après le début de COVID-19, le résultat est affecté par les entrées OOD d'avril à mai 2020, sur la base de ce que nous avons observé à partir de la série chronologique des revenus.

Configuration et formation du modèle
Pour la formation Transformer, nous avons utilisé la perte quantile et mis à l'échelle chaque série temporelle en utilisant sa valeur moyenne historique avant de l'introduire dans Transformer et de calculer la perte de formation. Les prévisions finales sont remises à l'échelle pour calculer les mesures de précision, à l'aide du MeanScaler mis en œuvre dans GluonTS. Nous utilisons une fenêtre contextuelle avec des données de revenus mensuels des 18 derniers mois, sélectionnées via HPO dans la fenêtre de backtest de juillet 2018 à juin 2019. Des métadonnées supplémentaires sur chaque série temporelle sous la forme de variables catégorielles statiques sont introduites dans le modèle via une intégration. couche avant de l'alimenter aux couches du transformateur. Nous formons le transformateur avec cinq initialisations de poids aléatoires différentes et faisons la moyenne des résultats de prévision des trois dernières époques pour chaque exécution, avec une moyenne totale de 15 modèles. Les cinq exécutions d'entraînement du modèle peuvent être mises en parallèle pour réduire le temps d'entraînement. Pour le transformateur masqué, nous indiquons les mois d'avril à mai 2020 comme valeurs aberrantes.
Pour toutes les formations de modèle de prévision, nous avons activé HPO automatique, qui peut sélectionner le modèle et les paramètres de formation en fonction d'une période de backtest spécifiée par l'utilisateur, qui est définie sur les 12 derniers mois dans la fenêtre de données utilisée pour la formation et HPO.
Résultats de l'expérience
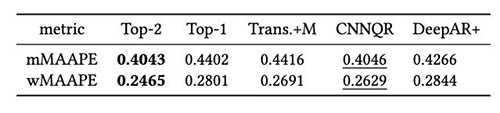
Nous formons des transformateurs masqués et non masqués en utilisant le même ensemble d'hyperparamètres, et comparons leurs performances pour les fenêtres de backtest immédiatement après le choc COVID-19. Dans le Transformer masqué, les deux mois masqués sont avril et mai 2020. Le tableau suivant montre les résultats d'une série de périodes de backtest avec des fenêtres de prévision de 12 mois à partir de juin 2020. Nous pouvons observer que le Transformer masqué surpasse systématiquement la version non masquée .

Nous avons en outre effectué une évaluation de la stratégie d'ensemble de modèles basée sur les résultats des backtests. En particulier, nous comparons les deux cas où seul le modèle le plus performant est sélectionné et lorsque les deux modèles les plus performants sont sélectionnés, et la moyenne du modèle est effectuée en calculant la valeur moyenne des prévisions. Nous comparons les performances des modèles de base et des modèles d'ensemble dans les figures suivantes. Notez qu'aucun des prévisionnistes neuronaux ne surpasse systématiquement les autres pour les fenêtres de backtest roulantes.


Le tableau suivant montre qu'en moyenne, la modélisation d'ensemble des deux premiers modèles donne les meilleures performances. CNNQR fournit le deuxième meilleur résultat.
Conclusion
Cet article a montré comment créer une solution ML de bout en bout pour les problèmes de prévision à grande échelle combinant Forecast et un modèle personnalisé formé sur SageMaker. En fonction de vos besoins métier et de vos connaissances en ML, vous pouvez utiliser un service entièrement géré tel que Forecast pour décharger le processus de création, de formation et de déploiement d'un modèle de prévision ; créez votre modèle personnalisé avec des mécanismes de réglage spécifiques avec SageMaker ; ou effectuer l'assemblage de modèles en combinant les deux services.
Si vous souhaitez obtenir de l'aide pour accélérer l'utilisation du ML dans vos produits et services, veuillez contacter le Laboratoire de solutions Amazon ML .
Bibliographie
Hyndman RJ, Athanasopoulos G. Prévision : principes et pratique. OTexts ; 2018 mai 8.
Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez AN, Kaiser Ł, Polosukhin I. L'attention est tout ce dont vous avez besoin. Progrès dans les systèmes de traitement neuronal de l'information. 2017;30.
Zhou H, Zhang S, Peng J, Zhang S, Li J, Xiong H, Zhang W. Informer : Au-delà d'un transformateur efficace pour la prévision de séries chronologiques à longue séquence. Dans Actes de l'AAAI 2021 le 2 février.
À propos des auteurs
 Goktug Cinar est un scientifique principal en ML et le responsable technique des prévisions basées sur le ML et les statistiques chez Robert Bosch LLC et Bosch Center for Artificial Intelligence. Il dirige la recherche sur les modèles de prévision, la consolidation hiérarchique et les techniques de combinaison de modèles ainsi que l'équipe de développement logiciel qui met à l'échelle ces modèles et les sert dans le cadre du logiciel interne de prévision financière de bout en bout.
Goktug Cinar est un scientifique principal en ML et le responsable technique des prévisions basées sur le ML et les statistiques chez Robert Bosch LLC et Bosch Center for Artificial Intelligence. Il dirige la recherche sur les modèles de prévision, la consolidation hiérarchique et les techniques de combinaison de modèles ainsi que l'équipe de développement logiciel qui met à l'échelle ces modèles et les sert dans le cadre du logiciel interne de prévision financière de bout en bout.
 Michel Binder est propriétaire de produit chez Bosch Global Services, où il coordonne le développement, le déploiement et la mise en œuvre de l'application d'analyse prédictive à l'échelle de l'entreprise pour la prévision automatisée à grande échelle des chiffres clés financiers.
Michel Binder est propriétaire de produit chez Bosch Global Services, où il coordonne le développement, le déploiement et la mise en œuvre de l'application d'analyse prédictive à l'échelle de l'entreprise pour la prévision automatisée à grande échelle des chiffres clés financiers.
 Adrien Horvath est développeur de logiciels au Bosch Center for Artificial Intelligence, où il développe et maintient des systèmes pour créer des prédictions basées sur divers modèles de prévision.
Adrien Horvath est développeur de logiciels au Bosch Center for Artificial Intelligence, où il développe et maintient des systèmes pour créer des prédictions basées sur divers modèles de prévision.
 Pan Pan Xu est scientifique appliquée senior et responsable du laboratoire de solutions Amazon ML chez AWS. Elle travaille sur la recherche et le développement d'algorithmes d'apprentissage automatique pour les applications client à fort impact dans une variété de secteurs industriels verticaux afin d'accélérer leur adoption de l'IA et du cloud. Ses intérêts de recherche comprennent l'interprétabilité des modèles, l'analyse causale, l'IA humaine dans la boucle et la visualisation interactive des données.
Pan Pan Xu est scientifique appliquée senior et responsable du laboratoire de solutions Amazon ML chez AWS. Elle travaille sur la recherche et le développement d'algorithmes d'apprentissage automatique pour les applications client à fort impact dans une variété de secteurs industriels verticaux afin d'accélérer leur adoption de l'IA et du cloud. Ses intérêts de recherche comprennent l'interprétabilité des modèles, l'analyse causale, l'IA humaine dans la boucle et la visualisation interactive des données.
 Jasleen Grewal est scientifique appliquée chez Amazon Web Services, où elle travaille avec des clients AWS pour résoudre des problèmes du monde réel à l'aide de l'apprentissage automatique, avec un accent particulier sur la médecine de précision et la génomique. Elle possède une solide expérience en bioinformatique, en oncologie et en génomique clinique. Elle est passionnée par l'utilisation de l'IA/ML et des services cloud pour améliorer les soins aux patients.
Jasleen Grewal est scientifique appliquée chez Amazon Web Services, où elle travaille avec des clients AWS pour résoudre des problèmes du monde réel à l'aide de l'apprentissage automatique, avec un accent particulier sur la médecine de précision et la génomique. Elle possède une solide expérience en bioinformatique, en oncologie et en génomique clinique. Elle est passionnée par l'utilisation de l'IA/ML et des services cloud pour améliorer les soins aux patients.
 Senthivel de Selvan est ingénieur ML senior au Amazon ML Solutions Lab d'AWS, se concentrant sur l'aide aux clients sur l'apprentissage automatique, les problèmes d'apprentissage en profondeur et les solutions ML de bout en bout. Il a été l'un des responsables fondateurs de l'ingénierie d'Amazon Comprehend Medical et a contribué à la conception et à l'architecture de plusieurs services AWS AI.
Senthivel de Selvan est ingénieur ML senior au Amazon ML Solutions Lab d'AWS, se concentrant sur l'aide aux clients sur l'apprentissage automatique, les problèmes d'apprentissage en profondeur et les solutions ML de bout en bout. Il a été l'un des responsables fondateurs de l'ingénierie d'Amazon Comprehend Medical et a contribué à la conception et à l'architecture de plusieurs services AWS AI.
 Ruilin Zhang est un SDE avec le Amazon ML Solutions Lab chez AWS. Il aide les clients à adopter les services AWS AI en créant des solutions pour résoudre les problèmes commerciaux courants.
Ruilin Zhang est un SDE avec le Amazon ML Solutions Lab chez AWS. Il aide les clients à adopter les services AWS AI en créant des solutions pour résoudre les problèmes commerciaux courants.
 Shane Raï est Sr. ML Strategist avec le Amazon ML Solutions Lab chez AWS. Il travaille avec des clients dans un large éventail d'industries pour résoudre leurs besoins commerciaux les plus urgents et innovants en utilisant l'étendue des services AI/ML basés sur le cloud d'AWS.
Shane Raï est Sr. ML Strategist avec le Amazon ML Solutions Lab chez AWS. Il travaille avec des clients dans un large éventail d'industries pour résoudre leurs besoins commerciaux les plus urgents et innovants en utilisant l'étendue des services AI/ML basés sur le cloud d'AWS.
 Lin Lee Cheong est responsable des sciences appliquées au sein de l'équipe Amazon ML Solutions Lab chez AWS. Elle travaille avec des clients AWS stratégiques pour explorer et appliquer l'intelligence artificielle et l'apprentissage automatique afin de découvrir de nouvelles idées et de résoudre des problèmes complexes.
Lin Lee Cheong est responsable des sciences appliquées au sein de l'équipe Amazon ML Solutions Lab chez AWS. Elle travaille avec des clients AWS stratégiques pour explorer et appliquer l'intelligence artificielle et l'apprentissage automatique afin de découvrir de nouvelles idées et de résoudre des problèmes complexes.