
Vous pouvez désormais recycler les modèles d'apprentissage automatique (ML) et automatiser les flux de travail de prédiction par lots avec des ensembles de données mis à jour dans Toile Amazon SageMaker, facilitant ainsi l'apprentissage et l'amélioration constants des performances du modèle et de l'efficacité de la conduite. L'efficacité d'un modèle ML dépend de la qualité et de la pertinence des données sur lesquelles il est formé. Au fil du temps, les modèles sous-jacents, les tendances et les distributions des données peuvent changer. En mettant à jour le jeu de données, vous vous assurez que le modèle apprend à partir des données les plus récentes et les plus représentatives, améliorant ainsi sa capacité à faire des prédictions précises. Canvas prend désormais en charge la mise à jour automatique et manuelle des ensembles de données, ce qui vous permet d'utiliser la dernière version de l'ensemble de données tabulaire, image et document pour la formation des modèles ML.
Une fois le modèle formé, vous souhaiterez peut-être exécuter des prédictions dessus. L'exécution de prédictions par lots sur un modèle ML permet de traiter plusieurs points de données simultanément au lieu de faire des prédictions une par une. L'automatisation de ce processus offre efficacité, évolutivité et prise de décision rapide. Une fois les prédictions générées, elles peuvent être analysées, agrégées ou visualisées plus en détail pour obtenir des informations, identifier des modèles ou prendre des décisions éclairées en fonction des résultats prédits. Canvas prend désormais en charge la configuration d'une configuration de prédiction par lots automatisée et l'association d'un ensemble de données à celle-ci. Lorsque l'ensemble de données associé est actualisé, manuellement ou selon un calendrier, un workflow de prédiction par lots sera déclenché automatiquement sur le modèle correspondant. Les résultats des prédictions peuvent être visualisés en ligne ou téléchargés pour un examen ultérieur.
Dans cet article, nous montrons comment recycler les modèles ML et automatiser les prédictions par lots à l'aide d'ensembles de données mis à jour dans Canvas.
Présentation de la solution
Pour notre cas d'utilisation, nous jouons le rôle d'un analyste commercial pour une entreprise de commerce électronique. Notre équipe produit souhaite que nous déterminions les paramètres les plus critiques qui influencent la décision d'achat d'un acheteur. Pour cela, nous formons un modèle ML dans Canvas avec un ensemble de données de session en ligne sur le site Web client de l'entreprise. Nous évaluons les performances du modèle et, si nécessaire, réentraînons le modèle avec des données supplémentaires pour voir si cela améliore ou non les performances du modèle existant. Pour ce faire, nous utilisons la fonctionnalité de mise à jour automatique de l'ensemble de données dans Canvas et réentraînons notre modèle ML existant avec la dernière version de l'ensemble de données d'entraînement. Ensuite, nous configurons des workflows de prédiction par lots automatiques. Lorsque l'ensemble de données de prédiction correspondant est mis à jour, il déclenche automatiquement la tâche de prédiction par lots sur le modèle et met les résultats à notre disposition pour examen.
Les étapes du flux de travail sont les suivantes :
- Téléchargez les données de session en ligne du site Web du client téléchargées sur Service de stockage simple Amazon (Amazon S3) et créez un nouvel ensemble de données de formation Canvas. Pour la liste complète des sources de données prises en charge, reportez-vous à Importation de données dans Amazon SageMaker Canvas.
- Créez des modèles ML et analysez leurs métriques de performance. Reportez-vous aux étapes pour savoir comment créer un modèle ML personnalisé dans Canvas et évaluer les performances d'un modèle.
- Configurez la mise à jour automatique sur l'ensemble de données de formation existant et téléchargez de nouvelles données vers l'emplacement Amazon S3 qui sauvegarde cet ensemble de données. Une fois terminé, il devrait créer une nouvelle version du jeu de données.
- Utilisez la dernière version de l'ensemble de données pour réentraîner le modèle ML et analyser ses performances.
- Mettre en place prédictions automatiques par lots sur la version de modèle la plus performante et afficher les résultats de prédiction.
Vous pouvez effectuer ces étapes dans Canvas sans écrire une seule ligne de code.
Aperçu des données
L'ensemble de données se compose de vecteurs de caractéristiques appartenant à 12,330 1 sessions. L'ensemble de données a été formé de manière à ce que chaque session appartienne à un utilisateur différent sur une période d'un an afin d'éviter toute tendance à une campagne, une journée spéciale, un profil utilisateur ou une période spécifique. Le tableau suivant décrit le schéma de données.
| Nom de colonne | Type de données | Description |
Administrative |
Numérique | Nombre de pages visitées par l'utilisateur pour les activités liées à la gestion du compte utilisateur. |
Administrative_Duration |
Numérique | Temps passé dans cette catégorie de pages. |
Informational |
Numérique | Nombre de pages de ce type (informatives) visitées par l'utilisateur. |
Informational_Duration |
Numérique | Temps passé dans cette catégorie de pages. |
ProductRelated |
Numérique | Nombre de pages de ce type (liées au produit) visitées par l'utilisateur. |
ProductRelated_Duration |
Numérique | Temps passé dans cette catégorie de pages. |
BounceRates |
Numérique | Pourcentage de visiteurs qui accèdent au site Web via cette page et en sortent sans déclencher de tâches supplémentaires. |
ExitRates |
Numérique | Taux de sortie moyen des pages visitées par l'utilisateur. Il s'agit du pourcentage de personnes qui ont quitté votre site à partir de cette page. |
Page Values |
Numérique | Valeur de page moyenne des pages visitées par l'utilisateur. Il s'agit de la valeur moyenne d'une page qu'un utilisateur a visitée avant d'atterrir sur la page d'objectif ou d'effectuer une transaction de commerce électronique (ou les deux). |
SpecialDay |
binaire | La fonctionnalité « Jour spécial » indique la proximité de l'heure de visite du site avec un jour spécial spécifique (comme la fête des mères ou la Saint-Valentin) au cours duquel les sessions sont plus susceptibles d'être finalisées par une transaction. |
Month |
Catégorique | Mois de la visite. |
OperatingSystems |
Catégorique | Systèmes d'exploitation du visiteur. |
Browser |
Catégorique | Navigateur utilisé par l'utilisateur. |
Region |
Catégorique | Région géographique à partir de laquelle la session a été démarrée par le visiteur. |
TrafficType |
Catégorique | Source de trafic par laquelle l'utilisateur est entré sur le site Web. |
VisitorType |
Catégorique | Si le client est un nouvel utilisateur, un ancien utilisateur ou autre. |
Weekend |
binaire | Si le client a visité le site Web le week-end. |
Revenue |
binaire | Si un achat a été effectué. |
Le chiffre d'affaires est la colonne cible, ce qui nous aidera à prédire si un acheteur achètera ou non un produit.
La première étape consiste à télécharger le jeu de données que nous allons utiliser. Notez que cet ensemble de données est une gracieuseté du référentiel d'apprentissage automatique de l'UCI.
Pré-requis
Pour cette procédure pas à pas, effectuez les étapes préalables suivantes :
- Divisez le CSV téléchargé qui contient 20,000 XNUMX lignes en plusieurs fichiers de blocs plus petits.
Ceci afin que nous puissions présenter la fonctionnalité de mise à jour de l'ensemble de données. Assurez-vous que tous les fichiers CSV ont les mêmes en-têtes, sinon vous risquez de rencontrer des erreurs d'incompatibilité de schéma lors de la création d'un ensemble de données d'entraînement dans Canvas.

- Créer un compartiment S3 et charger
online_shoppers_intentions1-3.csvau compartiment S3.

- Mettez de côté 1,500 XNUMX lignes du fichier CSV téléchargé pour exécuter des prédictions par lots après l'apprentissage du modèle ML.
- Retirer le
Revenuecolonne de ces fichiers afin que lorsque vous exécutez la prédiction par lots sur le modèle ML, c'est la valeur que votre modèle prédira.
Assurer tous les predict*.csv les fichiers ont les mêmes en-têtes, sinon vous risquez de rencontrer des erreurs d'incompatibilité de schéma lors de la création d'un ensemble de données de prédiction (inférence) dans Canvas.

- Effectuez les démarches nécessaires pour configurer un domaine SageMaker et une application Canvas.
Créer un jeu de données
Pour créer un ensemble de données dans Canvas, procédez comme suit :
- Dans Canvas, choisissez Jeux de données dans le volet de navigation.
- Selectionnez Création et choisissez Tabulaire.

- Donnez un nom à votre ensemble de données. Pour cet article, nous appelons notre ensemble de données d'entraînement
OnlineShoppersIntentions. - Selectionnez Création.

- Choisissez votre source de données (pour cet article, notre source de données est Amazon S3).
Notez qu'au moment d'écrire ces lignes, la fonctionnalité de mise à jour de l'ensemble de données n'est prise en charge que pour Amazon S3 et les sources de données téléchargées localement.
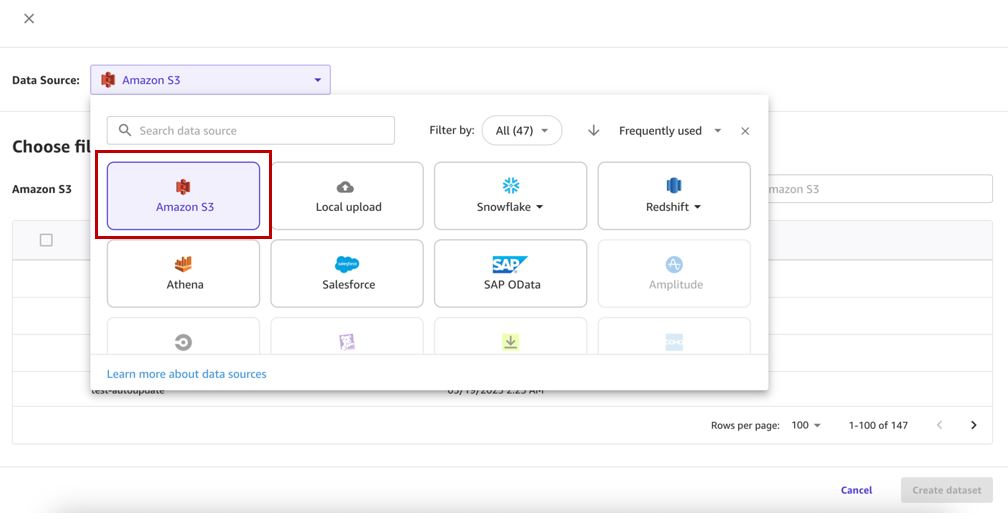
- Sélectionnez le compartiment correspondant et téléchargez les fichiers CSV pour l'ensemble de données.
Vous pouvez maintenant créer un jeu de données avec plusieurs fichiers.

- Prévisualisez tous les fichiers du jeu de données et choisissez Créer un jeu de données.

Nous avons maintenant la version 1 du OnlineShoppersIntentions ensemble de données avec trois fichiers créés.
- Choisissez le jeu de données pour afficher les détails.

La Données affiche un aperçu du jeu de données.
- Selectionnez Détails de l'ensemble de données pour afficher les fichiers que contient le jeu de données.
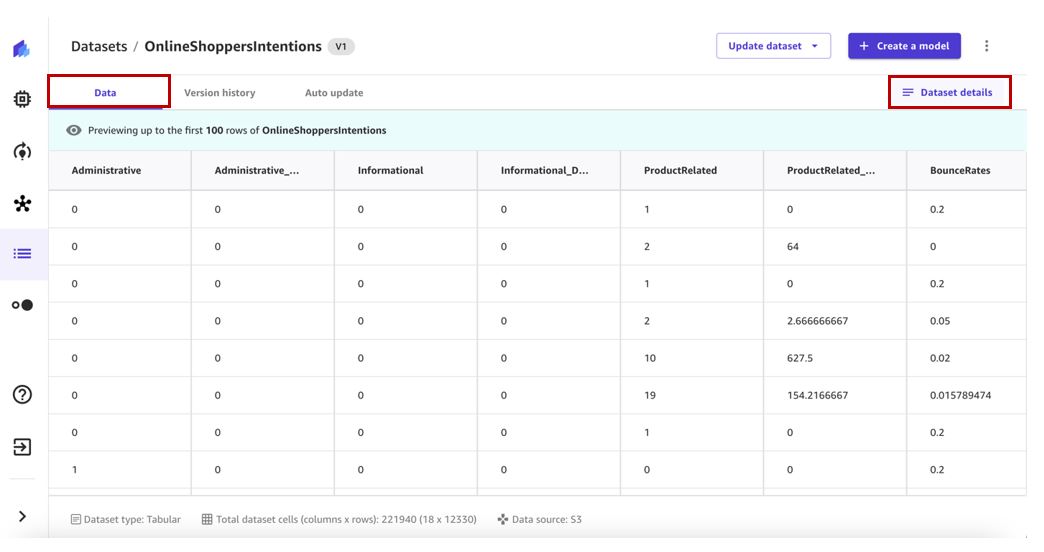
La Fichiers de jeu de données Le volet répertorie les fichiers disponibles.

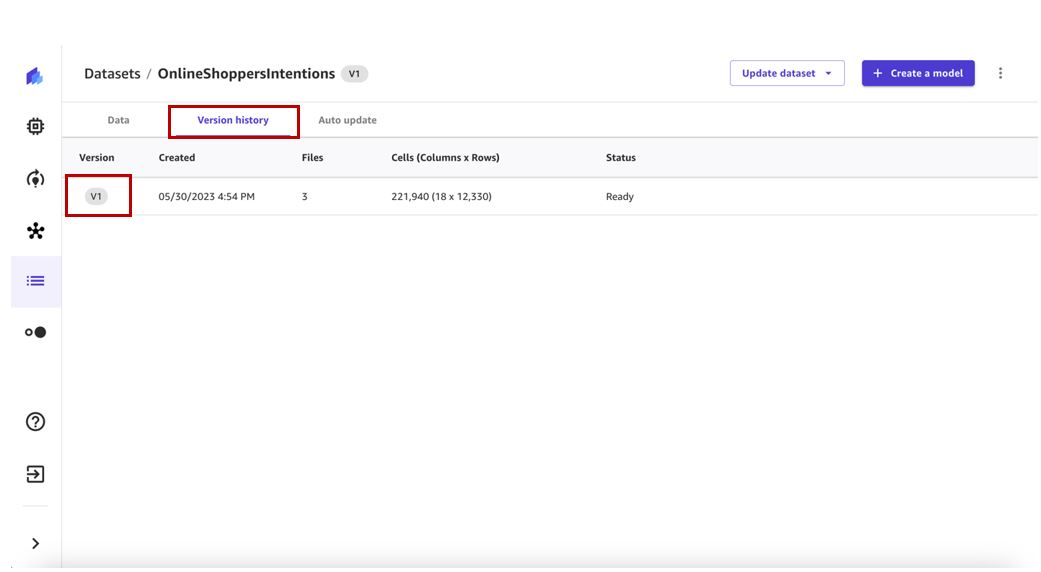
- Choisissez le Historique des versions pour afficher toutes les versions de ce jeu de données.
Nous pouvons voir que notre première version du jeu de données contient trois fichiers. Toute version ultérieure inclura tous les fichiers des versions précédentes et fournira une vue cumulative des données.
Entraîner un modèle ML avec la version 1 de l'ensemble de données
Entraînons un modèle ML avec la version 1 de notre ensemble de données.
- Dans Canvas, choisissez Mes modèles dans le volet de navigation.
- Selectionnez Nouveau modèle.
- Entrez un nom de modèle (par exemple,
OnlineShoppersIntentionsModel), sélectionnez le type de problème, puis choisissez Création.
- Sélectionnez le jeu de données. Pour ce poste, nous sélectionnons le
OnlineShoppersIntentionsjeu de données.
Par défaut, Canvas sélectionne la version la plus récente de l'ensemble de données pour l'entraînement.

- Sur le Développer , choisissez la colonne cible à prédire. Pour ce post, nous choisissons la colonne Revenue.
- Selectionnez Construction rapide.

La formation sur le modèle prendra 2 à 5 minutes. Dans notre cas, le modèle entraîné nous donne un score de 89%.

Configurer les mises à jour automatiques des ensembles de données
Mettons à jour notre ensemble de données à l'aide de la fonctionnalité de mise à jour automatique et apportons plus de données et voyons si les performances du modèle s'améliorent avec la nouvelle version de l'ensemble de données. Les ensembles de données peuvent également être mis à jour manuellement.
- Sur le Jeux de données page, sélectionnez
OnlineShoppersIntentionsjeu de données et choisissez Mettre à jour l'ensemble de données. - Vous pouvez choisir Mise à jour manuelle, qui est une option de mise à jour unique, ou Mise à jour automatique, qui vous permet de mettre à jour automatiquement votre ensemble de données selon un calendrier. Pour cet article, nous présentons la fonctionnalité de mise à jour automatique.

Vous êtes redirigé vers le Mise à jour automatique onglet pour le jeu de données correspondant. On peut voir ça Activer la mise à jour automatique est actuellement désactivé.

- cabillot Activer la mise à jour automatique sur et spécifiez la source de données (à ce jour, les sources de données Amazon S3 sont prises en charge pour les mises à jour automatiques).
- Sélectionnez une fréquence et entrez une heure de début.
- Enregistrez les paramètres de configuration.

Une configuration de jeu de données de mise à jour automatique a été créée. Il peut être modifié à tout moment. Lorsqu'une tâche de mise à jour d'ensemble de données correspondante est déclenchée selon la planification spécifiée, la tâche apparaît dans la Historique de l'emploi .

- Ensuite, téléchargeons le
online_shoppers_intentions4.csv,online_shoppers_intentions5.csvetonline_shoppers_intentions6.csvfichiers à notre compartiment S3.

Nous pouvons consulter nos fichiers dans le dataset-update-demo Godet S3.

La tâche de mise à jour de l'ensemble de données sera déclenchée selon la planification spécifiée et créera une nouvelle version de l'ensemble de données.

Lorsque la tâche est terminée, la version 2 de l'ensemble de données contiendra tous les fichiers de la version 1 et les fichiers supplémentaires traités par la tâche de mise à jour de l'ensemble de données. Dans notre cas, la version 1 comporte trois fichiers et la tâche de mise à jour a récupéré trois fichiers supplémentaires, de sorte que la version finale du jeu de données comporte six fichiers.
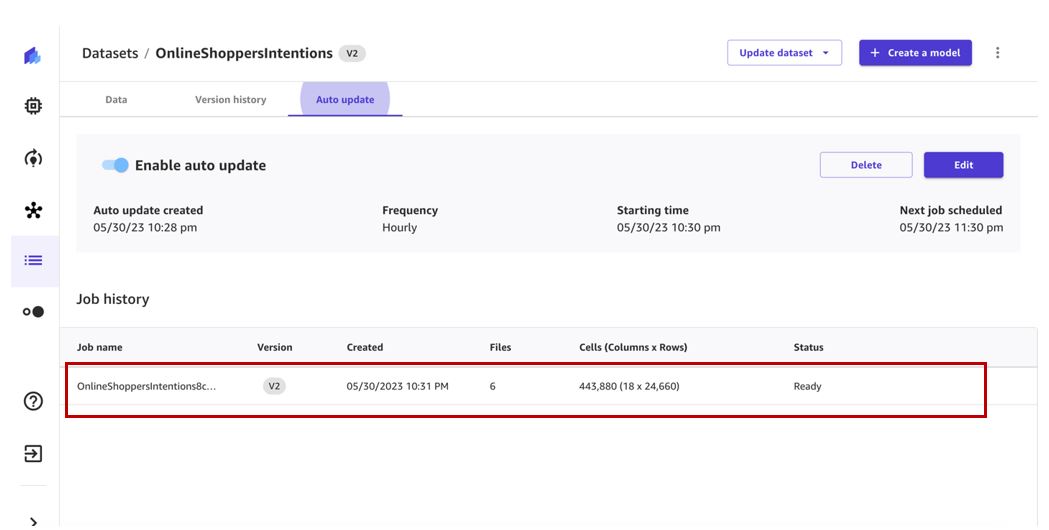
Nous pouvons voir la nouvelle version qui a été créée sur le Historique de la version languette.

La Données L'onglet contient un aperçu de l'ensemble de données et fournit une liste de tous les fichiers dans la dernière version de l'ensemble de données.

Réentraîner le modèle ML avec un ensemble de données mis à jour
Réentraînons notre modèle ML avec la dernière version de l'ensemble de données.
- Sur le Mes modèles page, choisissez votre modèle.
- Selectionnez Ajouter une version.
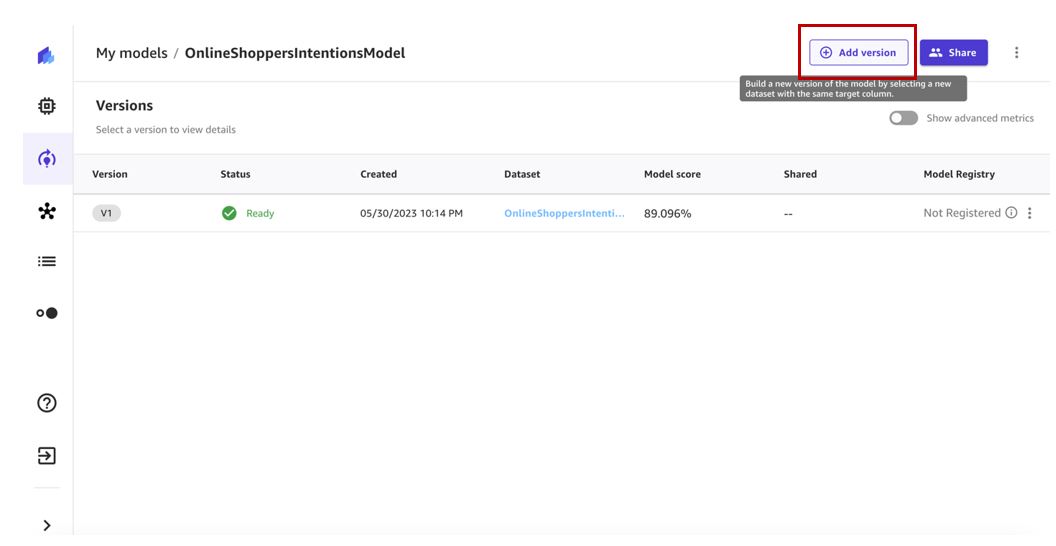
- Sélectionnez la dernière version du jeu de données (v2 dans notre cas) et choisissez Sélectionnez un jeu de données.
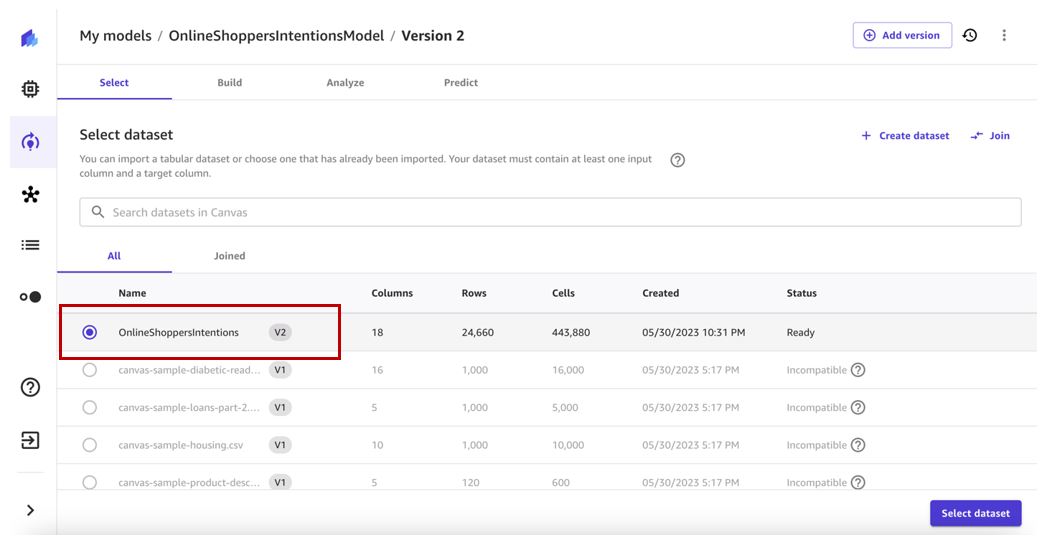
- Conservez la colonne cible et créez une configuration similaire à la version précédente du modèle.

Lorsque la formation est terminée, évaluons les performances du modèle. La capture d'écran suivante montre que l'ajout de données supplémentaires et le recyclage de notre modèle ML ont contribué à améliorer les performances de notre modèle.

Créer un ensemble de données de prédiction
Avec un modèle ML formé, créons un ensemble de données pour les prédictions et exécutons des prédictions par lots dessus.
- Sur le Jeux de données page, créez un jeu de données tabulaire.
- Entrez un nom et choisissez Création.

- Dans notre compartiment S3, chargez un fichier avec 500 lignes à prédire.

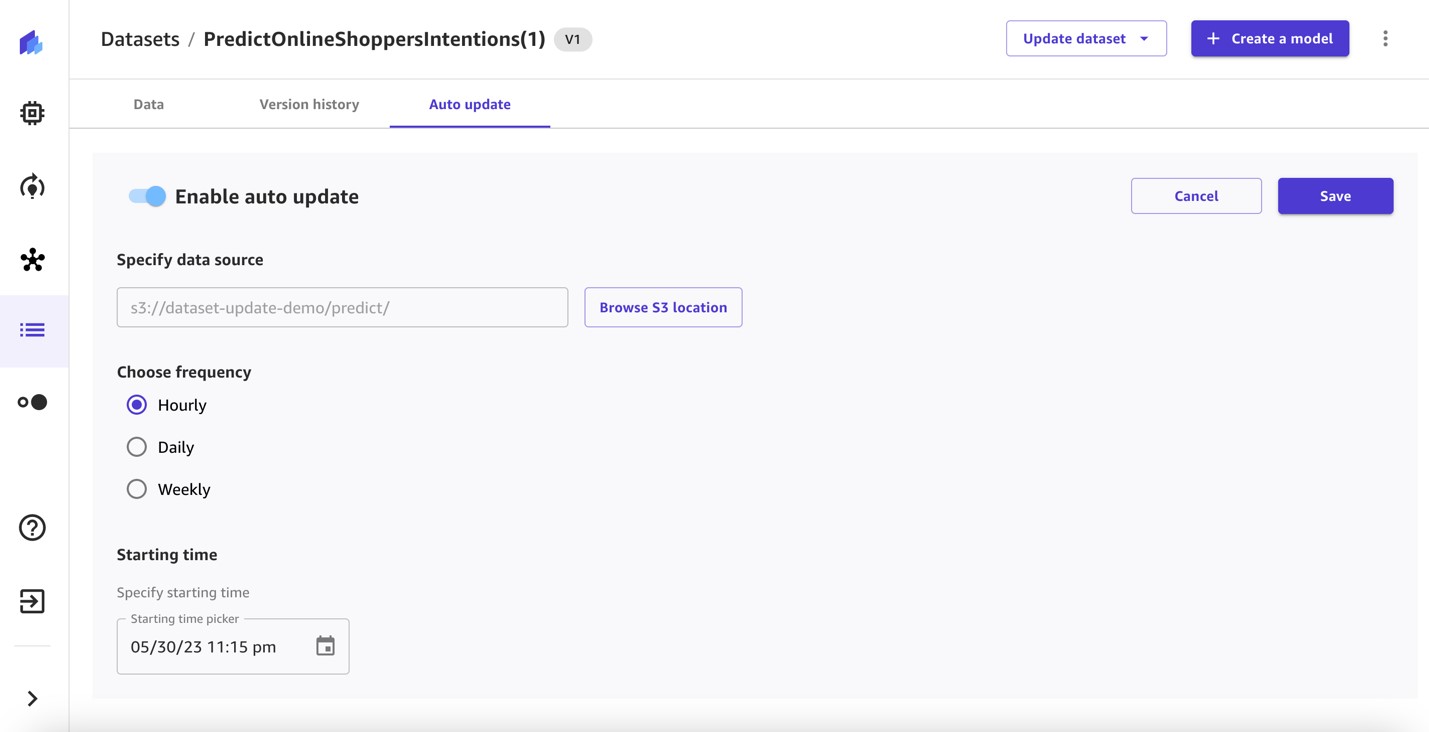
Ensuite, nous configurons les mises à jour automatiques sur l'ensemble de données de prédiction.
- cabillot Activer la mise à jour automatique sur et spécifiez la source de données.
- Sélectionnez la fréquence et spécifiez une heure de début.
- Enregistrez la configuration.
Automatisez le flux de travail de prédiction par lots sur un ensemble de données de prédictions mis à jour automatiquement
Dans cette étape, nous configurons nos workflows de prédiction automatique par lots.
- Sur le Mes modèles page, accédez à la version 2 de votre modèle.
- Sur le Prédire onglet, choisissez Prédiction par lots et Automatique.
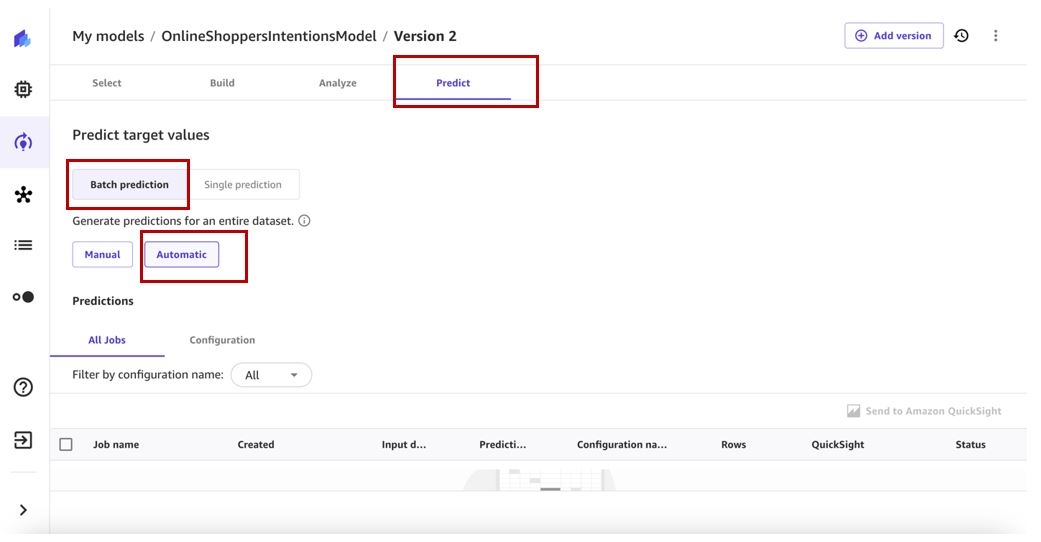
- Selectionnez Sélectionnez un jeu de données pour spécifier l'ensemble de données sur lequel générer des prédictions.

- Sélectionnez le
predictensemble de données que nous avons créé précédemment et choisissez Choisir un jeu de données.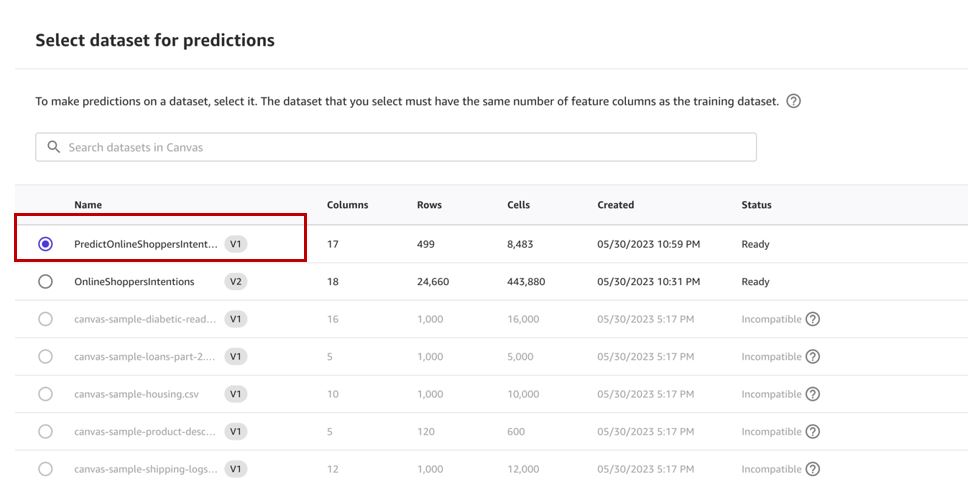
- Selectionnez Mettre en place.

Nous avons maintenant un flux de travail de prédiction automatique par lots. Celle-ci sera déclenchée lorsque le Predict l'ensemble de données est automatiquement mis à jour.

Maintenant téléchargeons plus de fichiers CSV sur le predict dossier S3.
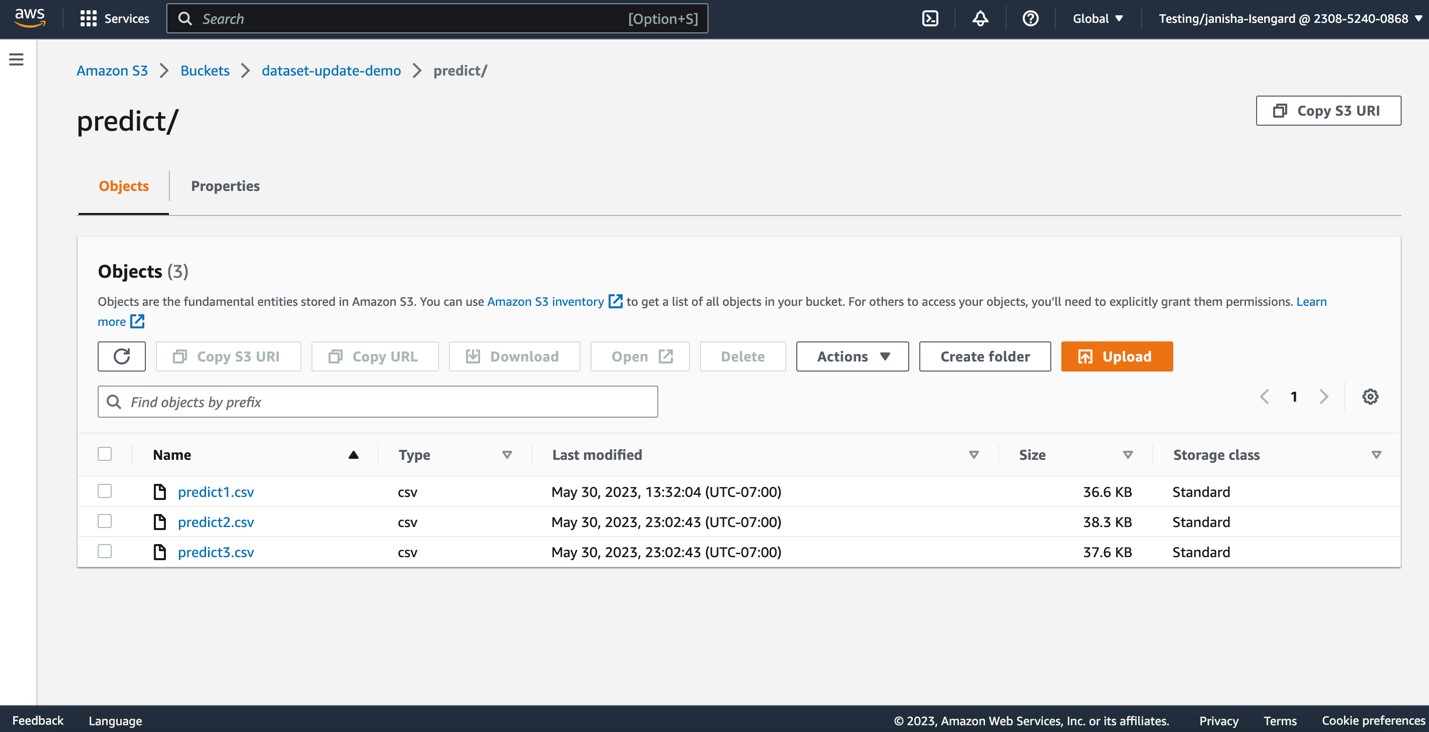
Cette opération déclenchera une mise à jour automatique du predict jeu de données.
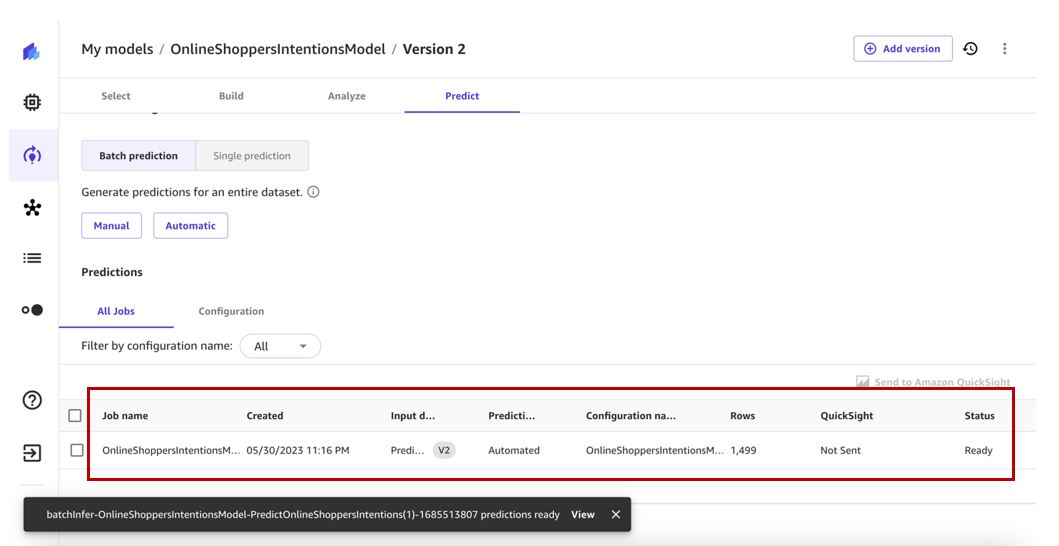
Cela déclenchera à son tour le flux de travail de prédiction automatique par lots et générera des prédictions que nous pourrons voir.

Nous pouvons voir toutes les automatisations sur le Automatismes .

Grâce à la mise à jour automatique des ensembles de données et aux flux de travail de prédiction automatique par lots, nous pouvons utiliser la dernière version de l'ensemble de données tabulaire, image et document pour former des modèles ML, et créer des flux de travail de prédiction par lots qui se déclenchent automatiquement à chaque mise à jour de l'ensemble de données.
Nettoyer
Pour éviter d'encourir des frais futurs, déconnectez-vous de Canvas. Canvas vous facture pour la durée de la session et nous vous recommandons de vous déconnecter de Canvas lorsque vous ne l'utilisez pas. Faire référence à Déconnexion d'Amazon SageMaker Canvas pour plus de détails.
Conclusion
Dans cet article, nous avons expliqué comment nous pouvons utiliser la nouvelle fonctionnalité de mise à jour des ensembles de données pour créer de nouvelles versions d'ensembles de données et former nos modèles ML avec les dernières données dans Canvas. Nous avons également montré comment nous pouvons automatiser efficacement le processus d'exécution des prédictions par lots sur des données mises à jour.
Pour commencer votre parcours ML low-code/no-code, reportez-vous au Guide du développeur Amazon SageMaker Canvas.
Un merci spécial à tous ceux qui ont contribué au lancement.
À propos des auteurs
 Janisha Anand est chef de produit senior au sein de l'équipe SageMaker No/Low-Code ML, qui comprend SageMaker Canvas et SageMaker Autopilot. Elle aime le café, rester active et passer du temps avec sa famille.
Janisha Anand est chef de produit senior au sein de l'équipe SageMaker No/Low-Code ML, qui comprend SageMaker Canvas et SageMaker Autopilot. Elle aime le café, rester active et passer du temps avec sa famille.
 Prasanth est ingénieur en développement logiciel chez Amazon SageMaker et travaille principalement avec les produits low-code et no-code de SageMaker.
Prasanth est ingénieur en développement logiciel chez Amazon SageMaker et travaille principalement avec les produits low-code et no-code de SageMaker.
 Esha Dutta est ingénieur en développement logiciel chez Amazon SageMaker. Elle se concentre sur la création d'outils et de produits ML pour les clients. En dehors du travail, elle aime le plein air, le yoga et la randonnée.
Esha Dutta est ingénieur en développement logiciel chez Amazon SageMaker. Elle se concentre sur la création d'outils et de produits ML pour les clients. En dehors du travail, elle aime le plein air, le yoga et la randonnée.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- Financement EVM. Interface unifiée pour la finance décentralisée. Accéder ici.
- Groupe de médias quantiques. IR/PR amplifié. Accéder ici.
- PlatoAiStream. Intelligence des données Web3. Connaissance Amplifiée. Accéder ici.
- La source: https://aws.amazon.com/blogs/machine-learning/retrain-ml-models-and-automate-batch-predictions-in-amazon-sagemaker-canvas-using-updated-datasets/