
Ez egy vendégbejegyzés, amelyet Maik Leuthold és Nick Harmening a BMW Group-tól közösen írt.
A BMW Group székhelye Münchenben, Németországban található, ahol a vállalat 149,000 30 alkalmazottat felügyel, és 15 ország több mint XNUMX gyártóhelyén gyárt autókat és motorkerékpárokat. Ez a multinacionális termelési stratégia még nemzetközibb és kiterjedtebb beszállítói hálózatot követ.
A világ számos autóipari vállalatához hasonlóan a BMW Group is kihívásokkal néz szembe ellátási láncában a félvezetők világméretű hiánya miatt. A BMW Group félvezetők iránti jelenlegi és jövőbeli keresletével kapcsolatos átláthatóság megteremtése az egyik kulcsfontosságú stratégiai szempont a hiányok beszállítókkal és félvezetőgyártókkal történő megoldásában. A gyártóknak ismerniük kell a BMW Group pontos jelenlegi és jövőbeli félvezető mennyiségi információit, ami hatékonyan segíti a világszerte elérhető kínálat irányítását.
A fő követelmény az automatizált, átlátható és hosszú távú félvezetőigény-előrejelzés. Ezen túlmenően ennek az előrejelző rendszernek adatbővítési lépéseket kell biztosítania, beleértve a melléktermékeket, a félvezető-kezelés alapadataiként kell szolgálnia, és lehetővé kell tennie a további felhasználási eseteket a BMW csoportnál.
Ennek a használati esetnek az engedélyezéséhez a BMW Group felhőalapú natív adatplatformját, a Cloud Data Hub-ot használtuk. 2019-ben a BMW Group úgy döntött, hogy újratervezi és áthelyezi helyszíni adatforrását az AWS Cloudba, hogy lehetővé tegye az adatvezérelt innovációt, miközben a szervezet dinamikus igényeihez igazodik. A Cloud Data Hub feldolgozza és egyesíti a járműérzékelőkből és a vállalaton belüli egyéb forrásokból származó anonimizált adatokat, hogy könnyen hozzáférhetővé tegye azokat az ügyfelek felé néző és belső alkalmazásokat létrehozó belső csapatok számára. Ha többet szeretne megtudni a Cloud Data Hubról, lásd: A BMW Group AWS-alapú Data Lake-et használ az adatok erejének felszabadítására.
Ebben a bejegyzésben megosztjuk, hogyan elemzi a BMW Group a félvezető keresletet AWS ragasztó.
Logika és rendszerek az igény-előrejelzés mögött
Az első lépés a kereslet-előrejelzés felé egy járműtípus félvezető-releváns alkatrészeinek azonosítása. Minden komponenst egyedi cikkszám ír le, amely kulcsként szolgál minden rendszerben az összetevő azonosításához. Alkatrész lehet például fényszóró vagy kormánykerék.
Történelmi okokból az összesítési lépéshez szükséges adatok el vannak zárva, és különböző rendszerekben eltérően jelennek meg. Mivel minden forrásrendszernek és adattípusnak saját sémája és formátuma van, különösen nehéz ezeken az adatokon alapuló elemzést végezni. Egyes forrásrendszerek már elérhetőek a Cloud Data Hubban (például a résztörzsadatok), ezért egyszerűen használható az AWS-fiókunkból. A fennmaradó adatforrások eléréséhez speciális feldolgozási feladatokat kell létrehoznunk, amelyek adatokat olvasnak be a megfelelő rendszerből.
A következő ábra szemlélteti a megközelítést.
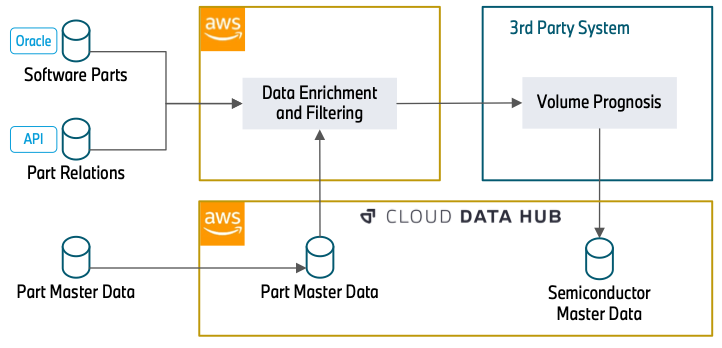
Az adatok gazdagítása egy Oracle adatbázissal (szoftverrészekkel) kezdődik, amely a szoftverhez kapcsolódó cikkszámokat tartalmazza. Ez lehet egy fényszóró vezérlőegysége vagy egy kamerarendszer az automatizált vezetéshez. Mivel a félvezetők jelentik a szoftverek futtatásának alapját, ez az adatbázis képezi adatfeldolgozásunk alapját.
A következő lépésben REST API-kat (Part Relations) használunk az adatok további attribútumokkal való gazdagításához. Ez magában foglalja, hogy az alkatrészek hogyan kapcsolódnak egymáshoz (például egy adott vezérlőegység, amelyet a fényszóróba szerelnek be), és azt, hogy mennyi időn belül kerül beépítésre az alkatrészszám a járműbe. Az alkatrészviszonyok ismerete elengedhetetlen ahhoz, hogy megértsük, hogy egy adott félvezető, jelen esetben a vezérlőegység mennyire releváns egy általánosabb alkatrész, a fényszóró szempontjából. Az alkatrészszámok használatára vonatkozó időbeli információk lehetővé teszik, hogy kiszűrjük az elavult cikkszámokat, amelyeket a jövőben nem használunk, és ezért nincs jelentősége az előrejelzésben.
Az adatok (Part Master Data) közvetlenül felhasználhatók a Cloud Data Hubból. Ez az adatbázis attribútumokat tartalmaz egy cikkszám állapotára és anyagtípusaira vonatkozóan. Erre az információra azért van szükség, hogy kiszűrjük azokat a cikkszámokat, amelyeket az előző lépésekben gyűjtöttünk össze, de nincs jelentősége a félvezetőknek. Az API-kból összegyűjtött információkkal ezek az adatok is lekérdezésre kerülnek, hogy további olyan cikkszámokat nyerjenek ki, amelyeket az előző lépésekben nem vettek fel.
Az adatok gazdagítása és szűrése után egy harmadik féltől származó rendszer beolvassa a szűrt alkatrészadatokat, és gazdagítja a félvezető információkat. Ezt követően hozzáadja az összetevők mennyiségi információit. Végül központilag biztosítja a félvezető iránti kereslet általános előrejelzését a Cloud Data Hub számára.
Alkalmazott szolgáltatások
Megoldásunk a szerver nélküli szolgáltatásokat használja AWS ragasztó és a Amazon egyszerű tárolási szolgáltatás (Amazon S3) az ETL (extract, transform and load) munkafolyamatok futtatásához infrastruktúra kezelése nélkül. A költségeket is csökkenti azáltal, hogy csak a munkák futásának idejéért fizet. A szerver nélküli megközelítés nagyon jól illeszkedik a munkafolyamat ütemtervéhez, mivel hetente csak egyszer futtatjuk le a terhelést.
Mivel változatos adatforrás-rendszereket, valamint összetett feldolgozást és összesítést használunk, fontos az ETL-feladatok szétválasztása. Ez lehetővé teszi, hogy az egyes adatforrásokat egymástól függetlenül dolgozzuk fel. Az adatátalakítást is több modulra bontjuk (Adataggregáció, Adatszűrés és Adat-előkészítés), hogy átláthatóbbá és könnyebben karbantarthatóvá tegyük a rendszert. Ez a megközelítés a meglévő munkahelyek bővítése vagy módosítása esetén is segítséget nyújt.
Bár minden modul egy adatforrásra vagy egy adott adatátalakításra vonatkozik, minden feladaton belül újrafelhasználható blokkokat használunk. Ez lehetővé teszi az egyes művelettípusok egységesítését, és leegyszerűsíti az új adatforrások és az átalakítási lépések jövőbeni hozzáadásának folyamatát.
Beállításunk során a legkevesebb privilégium elvének biztonsági bevált gyakorlatát követjük, hogy biztosítsuk az információk védelmét a véletlen vagy szükségtelen hozzáférés ellen. Ezért minden modul rendelkezik AWS Identity and Access Management (IAM) szerepkörök csak a szükséges engedélyekkel, nevezetesen csak azokhoz az adatforrásokhoz és gyűjtőkhöz való hozzáféréssel, amelyekkel a feladat foglalkozik. A legjobb biztonsági gyakorlatokkal kapcsolatos további információkért lásd: Bevált biztonsági gyakorlatok az IAM-ben.
Megoldás áttekintése
A következő diagram azt a teljes munkafolyamatot mutatja, amelyben több AWS ragasztófeladat egymás után kölcsönhatásba lép egymással.

Ahogy korábban említettük, a Cloud Data Hub-ot, az Oracle DB-t és más adatforrásokat használtuk, amelyekkel a REST API-n keresztül kommunikálunk. A megoldás első lépése a Data Source Ingest modul, amely különböző adatforrásokból gyűjti be az adatokat. Ebből a célból az AWS Glue-feladatok különböző adatforrásokból olvasnak információkat, és az S3-forrásgyűjtőkbe írnak. A bevitt adatokat a titkosított tárolóhelyekben tárolják, a kulcsokat pedig a kezeli AWS kulcskezelési szolgáltatás (AWS KMS).
Az Adatforrás-feldolgozás lépést követően a köztes feladatok összesítik és gazdagítják a táblázatokat más adatforrásokkal, például az összetevők verziójával és kategóriáival, a modell gyártási dátumaival stb. Ezután beírják azokat az Adatösszesítés modul közbenső kockáiba, így átfogó és bőséges adatábrázolást hoznak létre. Ezenkívül az üzleti logikai munkafolyamatnak megfelelően az Adatszűrés és az Adat-előkészítés modulok létrehozzák a végső törzsadattáblázatot, amely csak a tényleges és a termelés szempontjából releváns információkat tartalmazza.
Az AWS Glue munkafolyamat ezeket a feldolgozási és szűrési feladatokat a végétől a végéig kezeli. Az AWS Glue munkafolyamat ütemezése hetente van konfigurálva, hogy a munkafolyamat szerdánként futhasson. Amíg a munkafolyamat fut, minden job végrehajtási naplókat (információkat vagy hibákat) ír be Amazon Simple Notification Service (Amazon SNS) és amazonfelhőóra megfigyelési célokra. Az Amazon SNS továbbítja a végrehajtási eredményeket a megfigyelő eszközöknek, például a Mail, a Teams vagy a Slack csatornáknak. Ha bármilyen hiba történik a munkákban, az Amazon SNS figyelmezteti a hallgatókat a feladat végrehajtásának eredményéről, hogy tegyenek lépéseket.
A megoldás utolsó lépéseként a harmadik féltől származó rendszer beolvassa a főtáblát az előkészített adatgyűjtőből a Amazon Athéné. További adattervezési lépések, például a félvezető információk gazdagítása és a kötetinformációk integrációja után a végső törzsadat-eszköz a Cloud Data Hubba kerül. A Cloud Data Hubban most biztosított adatokkal más felhasználási esetek is használhatják ezeket a félvezető törzsadatokat anélkül, hogy több interfészt építenének a különböző forrásrendszerekhez.
Business outcome
A projekt eredményei a BMW csoport számára jelentős átláthatóságot biztosítanak a félvezető iránti keresletről a teljes járműportfóliójuk tekintetében a jelenben és a jövőben is. Egy ilyen nagyságrendű adatbázis létrehozása lehetővé teszi a BMW Group számára, hogy még további felhasználási eseteket állapítson meg az ellátási lánc nagyobb átláthatósága, valamint az első osztályú beszállítókkal és félvezetőgyártókkal való világosabb és mélyebb információcsere érdekében. Nemcsak a jelenlegi nehéz piaci helyzet megoldását segíti, hanem a jövőbeni ellenálló képességet is. Ezért ez egy fontos lépés a digitális, átlátható ellátási lánc felé.
Következtetés
Ez a bejegyzés leírja, hogyan lehet elemezni a félvezető iránti keresletet számos adatforrásból nagy adatfeladatokkal egy AWS Glue munkafolyamatban. A kiszolgáló nélküli architektúra a szolgáltatások minimális sokféleségével megkönnyíti a kódbázis és az architektúra megértését és karbantartását. Ha többet szeretne megtudni arról, hogyan használhatja az AWS Glue munkafolyamatokat és feladatokat kiszolgáló nélküli hangszereléshez, látogassa meg a AWS ragasztó szolgáltatási oldal.
A szerzőkről
 Maik Leuthold projektvezető a BMW Groupnál az ellátási lánc és a beszerzés területén a fejlett elemzések területén, valamint a félvezető-menedzsment digitalizálási stratégiájának vezetője.
Maik Leuthold projektvezető a BMW Groupnál az ellátási lánc és a beszerzés területén a fejlett elemzések területén, valamint a félvezető-menedzsment digitalizálási stratégiájának vezetője.
 Nick Harmening IT projektvezető a BMW csoportnál és AWS minősítéssel rendelkező megoldástervező. Felhőalapú natív alkalmazásokat épít és üzemeltet, az adatfejlesztésre és a gépi tanulásra összpontosítva.
Nick Harmening IT projektvezető a BMW csoportnál és AWS minősítéssel rendelkező megoldástervező. Felhőalapú natív alkalmazásokat épít és üzemeltet, az adatfejlesztésre és a gépi tanulásra összpontosítva.
 Göksel Sarikaya az AWS Professional Services vezető felhőalkalmazás-építésze. Lehetővé teszi az ügyfelek számára, hogy méretezhető, költséghatékony és versenyképes alkalmazásokat tervezzenek az AWS platform innovatív gyártása révén. Segít nekik az ügyfelek és partnerek üzleti eredményeinek felgyorsításában a digitális átalakulás során.
Göksel Sarikaya az AWS Professional Services vezető felhőalkalmazás-építésze. Lehetővé teszi az ügyfelek számára, hogy méretezhető, költséghatékony és versenyképes alkalmazásokat tervezzenek az AWS platform innovatív gyártása révén. Segít nekik az ügyfelek és partnerek üzleti eredményeinek felgyorsításában a digitális átalakulás során.
 Alekszandr Celikov az AWS Professional Services adatépítésze, aki szenvedélyesen segíti ügyfeleit méretezhető adatok, elemzési és ML-megoldások létrehozásában, amelyek lehetővé teszik az időszerű betekintést és a kritikus üzleti döntések meghozatalát.
Alekszandr Celikov az AWS Professional Services adatépítésze, aki szenvedélyesen segíti ügyfeleit méretezhető adatok, elemzési és ML-megoldások létrehozásában, amelyek lehetővé teszik az időszerű betekintést és a kritikus üzleti döntések meghozatalát.
 Rahul Shaurya az Amazon Web Services vezető Big Data építésze. Segít, és szorosan együttműködik az ügyfelekkel, akik adatplatformokat és elemző alkalmazásokat építenek az AWS-en. A munkán kívül Rahul szeret hosszú sétákat tenni Barney kutyájával.
Rahul Shaurya az Amazon Web Services vezető Big Data építésze. Segít, és szorosan együttműködik az ügyfelekkel, akik adatplatformokat és elemző alkalmazásokat építenek az AWS-en. A munkán kívül Rahul szeret hosszú sétákat tenni Barney kutyájával.
- SEO által támogatott tartalom és PR terjesztés. Erősödjön még ma.
- PlatoAiStream. Web3 adatintelligencia. Felerősített tudás. Hozzáférés itt.
- A jövő pénzverése – Adryenn Ashley. Hozzáférés itt.
- Forrás: https://aws.amazon.com/blogs/big-data/how-the-bmw-group-analyses-semiconductor-demand-with-aws-glue/