
Bevezetés
A gépi tanulás (ML) egy olyan kutatási terület, amely olyan algoritmusok kifejlesztésére összpontosít, amelyek automatikusan tanulnak az adatokból, előrejelzéseket készítenek és mintákra következtetnek anélkül, hogy kifejezetten megmondanák, hogyan kell ezt csinálni. Célja olyan rendszerek létrehozása, amelyek automatikusan javulnak a tapasztalattal és az adatokkal.
Ez felügyelt tanulással érhető el, ahol a modellt címkézett adatok felhasználásával képezik előrejelzések készítéséhez, vagy felügyelet nélküli tanulással, ahol a modell az adatokon belüli mintázatokat vagy összefüggéseket igyekszik feltárni anélkül, hogy konkrét célkimeneteket kellene előre jelezni.
Az ML nélkülözhetetlen és széles körben alkalmazott eszközzé vált számos tudományágban, beleértve a számítástechnikát, a biológiát, a pénzügyet és a marketinget. Hasznosságát számos alkalmazásban bebizonyította, mint például a képosztályozás, a természetes nyelv feldolgozása és a csalások felderítése.
Gépi tanulási feladatok
A gépi tanulás nagyjából három fő feladatra osztható:
- Felügyelt tanulás
- Nem felügyelt tanulás
- Erősítő tanulás
Itt az első két esetre összpontosítunk.
Felügyelt tanulás
A felügyelt tanulás magában foglalja egy modell betanítását címkézett adatokon, ahol a bemeneti adatok párosulnak a megfelelő kimeneti vagy célváltozóval. A cél egy olyan függvény megtanulása, amely képes a bemeneti adatokat a megfelelő kimenetre képezni. A gyakori felügyelt tanulási algoritmusok közé tartozik a lineáris regresszió, a logisztikus regresszió, a döntési fák és a támogató vektorgépek.
Példa felügyelt tanulási kódra Python használatával:
from sklearn.linear_model import LinearRegression model = LinearRegression() model.fit(X_train, y_train) predictions = model.predict(X_test)
Ebben az egyszerű kódpéldában megtanítjuk a LinearRegression a scikit-learn algoritmusát az edzési adatainkra, majd alkalmazza azt, hogy előrejelzéseket kapjon tesztadatainkra vonatkozóan.
A felügyelt tanulás egyik valós alkalmazása az e-mail spam osztályozása. Az e-mailes kommunikáció exponenciális növekedésével a spam e-mailek azonosítása és szűrése kulcsfontosságúvá vált. A felügyelt tanulási algoritmusok használatával modellt lehet betanítani arra, hogy a címkézett adatok alapján különbséget tegyen a legitim e-mailek és a spam között.
A felügyelt tanulási modell betanítható egy „spam” vagy „nem spam” címkével ellátott e-maileket tartalmazó adatkészletre. A modell mintákat és jellemzőket tanul meg a címkézett adatokból, például bizonyos kulcsszavak jelenlétét, az e-mail szerkezetét vagy az e-mail küldő adatait. A modell betanítása után a bejövő e-mailek automatikusan spamnek vagy nem levélszemétnek minősíthetők, hatékonyan kiszűrve a nem kívánt üzeneteket.
Felügyelet nélküli tanulás
A felügyelet nélküli tanulás során a bemeneti adatok címkézetlenek, és a cél az adatokon belüli minták vagy struktúrák felfedezése. A nem felügyelt tanulási algoritmusok célja, hogy értelmes reprezentációkat vagy klasztereket találjanak az adatokban.
A felügyelt tanulási algoritmusok példái közé tartozik k-klaszterezést jelent, hierarchikus klaszterezésés főkomponens-elemzés (PCA).
Példa felügyelet nélküli tanulási kódra:
from sklearn.cluster import KMeans model = KMeans(n_clusters=3) model.fit(X) predictions = model.predict(X_new)
Ebben az egyszerű kódpéldában megtanítjuk a KMeans A scikit-learn algoritmussal három klasztert azonosíthat az adatainkban, majd új adatokat illeszthet ezekbe a klaszterekbe.
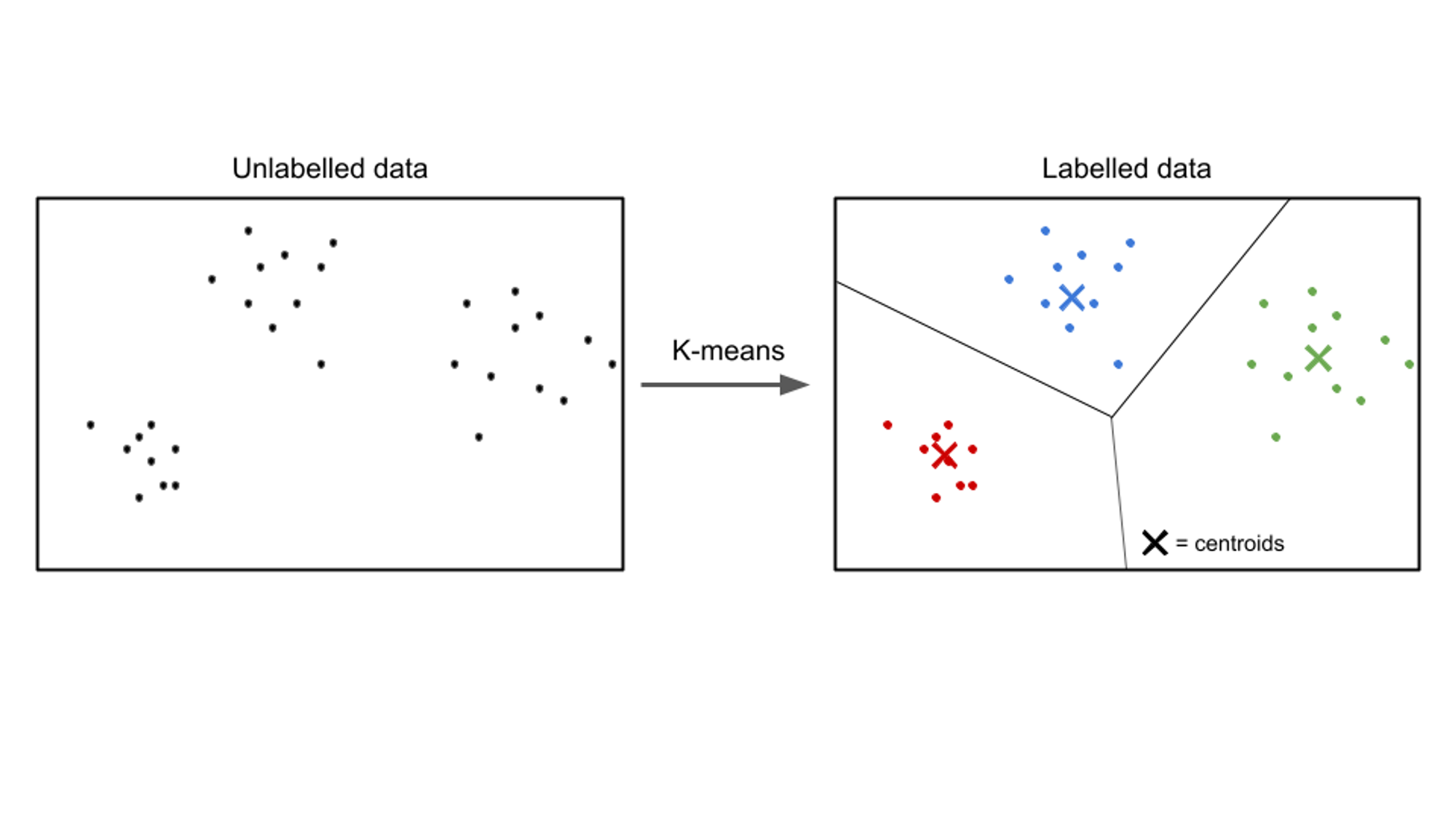
A felügyelet nélküli tanulási felhasználási esetre példa az ügyfélszegmentálás. A különböző iparágakban a vállalkozások arra törekednek, hogy jobban megértsék ügyfélbázisukat, hogy személyre szabhassák marketingstratégiáikat, személyre szabhassák kínálatukat és optimalizálhassák az ügyfélélményt. Felügyelet nélküli tanulási algoritmusok használhatók arra, hogy az ügyfeleket megkülönböztetett csoportokba szegmentálják közös jellemzőik és viselkedésük alapján.
Tekintse meg gyakorlatias, gyakorlati útmutatónkat a Git tanulásához, amely tartalmazza a bevált gyakorlatokat, az iparág által elfogadott szabványokat és a mellékelt csalólapot. Hagyd abba a guglizást a Git parancsokkal, és valójában tanulni meg!
Felügyelet nélküli tanulási technikák, például klaszterezés alkalmazásával a vállalkozások értelmes mintákat és csoportokat tárhatnak fel ügyféladataikon belül. A fürtözési algoritmusok például azonosíthatják a vásárlók csoportjait, amelyek hasonló vásárlási szokásokkal, demográfiai jellemzőkkel vagy preferenciákkal rendelkeznek. Ezek az információk felhasználhatók célzott marketingkampányok létrehozására, termékajánlások optimalizálására és a vásárlói elégedettség javítására.
Fő algoritmus osztályok
Felügyelt tanulási algoritmusok
-
Lineáris modellek: Folyamatos változók előrejelzésére szolgál a jellemzők és a célváltozó közötti lineáris kapcsolatok alapján.
-
Fa alapú modellek: bináris döntések sorozatával készültek előrejelzések vagy osztályozások készítéséhez.
-
Együttes modellek: Olyan módszer, amely több (fa alapú vagy lineáris) modellt kombinál a pontosabb előrejelzések érdekében.
-
Neurális hálózati modellek: lazán az emberi agyon alapuló módszerek, ahol több funkció működik a hálózat csomópontjaként.
Felügyelet nélküli tanulási algoritmusok
-
Hierarchikus klaszterezés: A klaszterek hierarchiáját építi fel, iteratív összevonásával vagy felosztásával.
-
Nem hierarchikus klaszterezés: Az adatokat hasonlóság alapján különálló klaszterekre osztja fel.
-
Dimenziócsökkentés: Csökkenti az adatok dimenzióját, miközben megőrzi a legfontosabb információkat.
Modell értékelése
Felügyelt tanulás
A felügyelt tanulási modellek teljesítményének értékelésére különféle mérőszámokat használnak, beleértve a pontosságot, precizitást, felidézést, F1 pontszámot és ROC-AUC-t. A keresztellenőrzési technikák, mint például a k-szeres keresztellenőrzés, segíthetnek megbecsülni a modell általánosítási teljesítményét.
Felügyelet nélküli tanulás
A felügyelet nélküli tanulási algoritmusok értékelése gyakran nagyobb kihívást jelent, mivel nincs alapigazság. Az olyan mérőszámok, mint a sziluett pontszám vagy a tehetetlenség, felhasználhatók a klaszterezési eredmények minőségének értékelésére. A vizualizációs technikák a klaszterek szerkezetébe is betekintést nyújthatnak.
Tippek és trükkök
Felügyelt tanulás
- A bemeneti adatok előfeldolgozása és normalizálása a modell teljesítményének javítása érdekében.
- A hiányzó értékeket megfelelően kezelje, akár imputálással, akár eltávolítással.
- A funkciótervezés javíthatja a modell azon képességét, hogy rögzítse a releváns mintákat.
Felügyelet nélküli tanulás
- Válassza ki a megfelelő számú klasztert a tartományi ismeretek alapján vagy olyan technikák használatával, mint a könyök módszer.
- Vegye figyelembe a különböző távolságmérőket az adatpontok közötti hasonlóság mérésére.
- Szabályozza a klaszterezési folyamatot a túlillesztés elkerülése érdekében.
Összefoglalva, a gépi tanulás számos feladatot, technikát, algoritmust, modellértékelési módszert és hasznos tanácsokat foglal magában. Ezen szempontok megértésével a szakemberek hatékonyan alkalmazhatják a gépi tanulást valós problémákra, és jelentős betekintést nyerhetnek az adatokból. A megadott kódpéldák a felügyelt és felügyelet nélküli tanulási algoritmusok felhasználását mutatják be, kiemelve azok gyakorlati megvalósítását.
- SEO által támogatott tartalom és PR terjesztés. Erősödjön még ma.
- EVM Finance. Egységes felület a decentralizált pénzügyekhez. Hozzáférés itt.
- Quantum Media Group. IR/PR erősített. Hozzáférés itt.
- PlatoAiStream. Web3 adatintelligencia. Felerősített tudás. Hozzáférés itt.
- Forrás: https://stackabuse.com/supervised-learning-vs-unsupervised-learning-algorithms/