
Pengantar
Machine Learning (ML) adalah bidang studi yang berfokus pada pengembangan algoritme untuk belajar secara otomatis dari data, membuat prediksi, dan menyimpulkan pola tanpa diberi tahu secara eksplisit cara melakukannya. Ini bertujuan untuk menciptakan sistem yang secara otomatis meningkat dengan pengalaman dan data.
Hal ini dapat dicapai melalui pembelajaran terawasi, di mana model dilatih menggunakan data berlabel untuk membuat prediksi, atau melalui pembelajaran tak terawasi, di mana model berusaha mengungkap pola atau korelasi dalam data tanpa keluaran target khusus untuk diantisipasi.
ML telah muncul sebagai alat yang sangat diperlukan dan digunakan secara luas di berbagai disiplin ilmu, termasuk ilmu komputer, biologi, keuangan, dan pemasaran. Ini telah membuktikan kegunaannya dalam beragam aplikasi seperti klasifikasi gambar, pemrosesan bahasa alami, dan deteksi penipuan.
Tugas Pembelajaran Mesin
Pembelajaran mesin dapat secara luas diklasifikasikan menjadi tiga tugas utama:
- Pembelajaran terawasi
- Pembelajaran tanpa pengawasan
- Pembelajaran penguatan
Di sini, kita akan fokus pada dua kasus pertama.
Pembelajaran yang Diawasi
Pembelajaran yang diawasi melibatkan pelatihan model pada data berlabel, di mana data input dipasangkan dengan variabel output atau target yang sesuai. Tujuannya adalah untuk mempelajari fungsi yang dapat memetakan data input ke output yang benar. Algoritme pembelajaran terawasi umum meliputi regresi linier, regresi logistik, pohon keputusan, dan mesin vektor pendukung.
Contoh kode pembelajaran yang diawasi menggunakan Python:
from sklearn.linear_model import LinearRegression model = LinearRegression() model.fit(X_train, y_train) predictions = model.predict(X_test)
Dalam contoh kode sederhana ini, kami melatih LinearRegression algoritma dari scikit-learn pada data pelatihan kami, dan kemudian menerapkannya untuk mendapatkan prediksi untuk data pengujian kami.
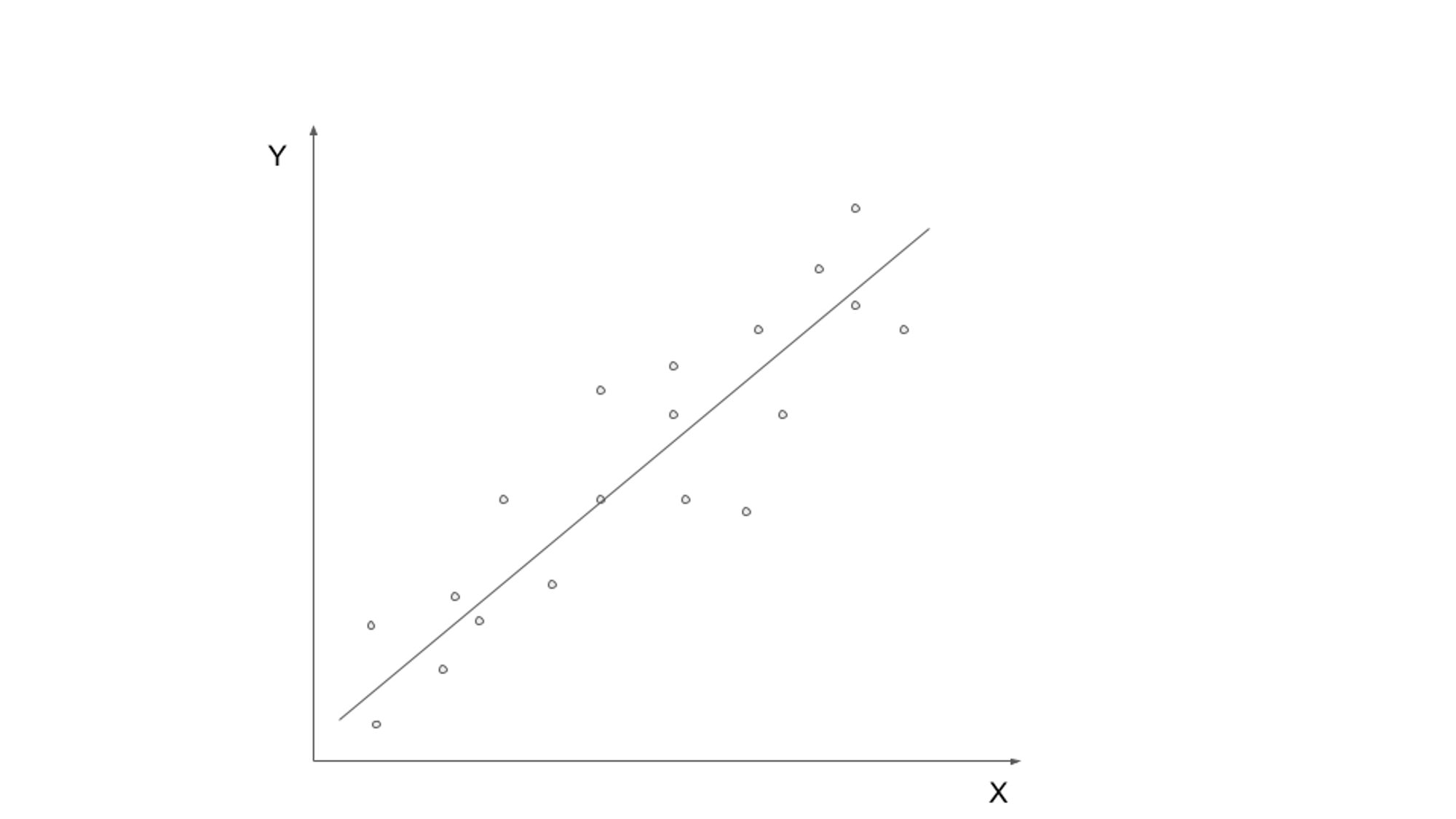
Salah satu kasus penggunaan pembelajaran terawasi di dunia nyata adalah klasifikasi spam email. Dengan pertumbuhan komunikasi email yang eksponensial, mengidentifikasi dan memfilter email spam menjadi sangat penting. Dengan memanfaatkan algoritme pembelajaran yang diawasi, dimungkinkan untuk melatih model untuk membedakan antara email yang sah dan spam berdasarkan data berlabel.
Model pembelajaran yang diawasi dapat dilatih pada kumpulan data yang berisi email yang diberi label sebagai "spam" atau "bukan spam". Model mempelajari pola dan fitur dari data berlabel, seperti keberadaan kata kunci tertentu, struktur email, atau informasi pengirim email. Setelah model dilatih, model ini dapat digunakan untuk secara otomatis mengklasifikasikan email masuk sebagai spam atau non-spam, memfilter pesan yang tidak diinginkan secara efisien.
Pembelajaran Tanpa Pengawasan
Dalam pembelajaran tanpa pengawasan, input data tidak diberi label, dan tujuannya adalah untuk menemukan pola atau struktur di dalam data. Algoritme pembelajaran tanpa pengawasan bertujuan untuk menemukan representasi atau kelompok yang bermakna dalam data.
Contoh algoritma pembelajaran tanpa pengawasan termasuk pengelompokan k-means, pengelompokan hierarki, dan analisis komponen utama (PCA).
Contoh kode pembelajaran tanpa pengawasan:
from sklearn.cluster import KMeans model = KMeans(n_clusters=3) model.fit(X) predictions = model.predict(X_new)
Dalam contoh kode sederhana ini, kami melatih KMeans algoritma dari scikit-learn untuk mengidentifikasi tiga cluster dalam data kami dan kemudian memasukkan data baru ke dalam cluster tersebut.
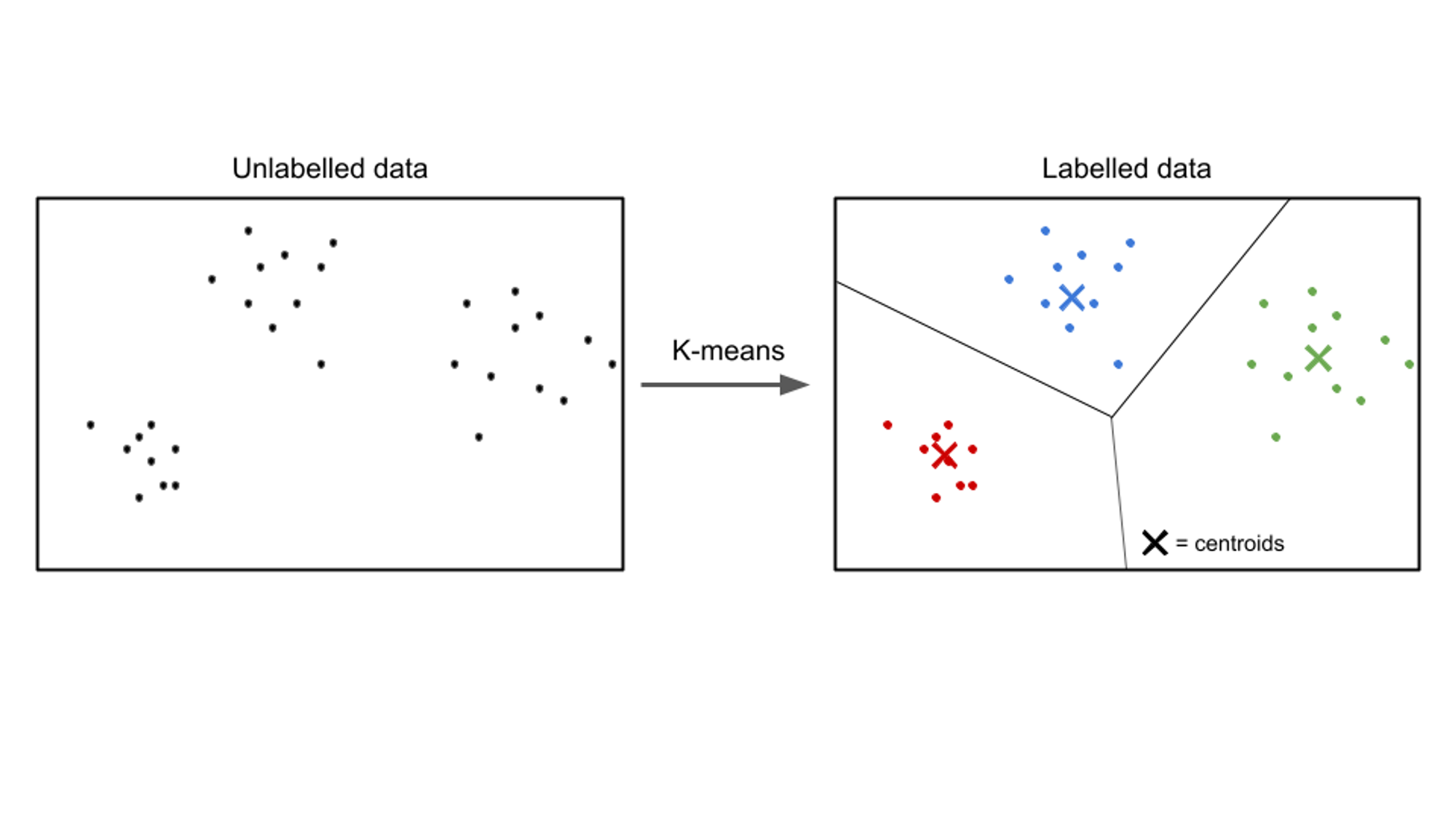
Contoh kasus penggunaan pembelajaran tanpa pengawasan adalah segmentasi pelanggan. Di berbagai industri, bisnis bertujuan untuk memahami basis pelanggan mereka dengan lebih baik untuk menyesuaikan strategi pemasaran mereka, mempersonalisasi penawaran mereka, dan mengoptimalkan pengalaman pelanggan. Algoritme pembelajaran tanpa pengawasan dapat digunakan untuk mengelompokkan pelanggan ke dalam kelompok yang berbeda berdasarkan karakteristik dan perilaku bersama mereka.
Lihat panduan praktis dan praktis kami untuk mempelajari Git, dengan praktik terbaik, standar yang diterima industri, dan termasuk lembar contekan. Hentikan perintah Googling Git dan sebenarnya belajar itu!
Dengan menerapkan teknik pembelajaran tanpa pengawasan, seperti pengelompokan, bisnis dapat mengungkap pola dan kelompok yang bermakna dalam data pelanggan mereka. Misalnya, algoritme pengelompokan dapat mengidentifikasi kelompok pelanggan dengan kebiasaan pembelian, demografi, atau preferensi yang serupa. Informasi ini dapat dimanfaatkan untuk membuat kampanye pemasaran yang terarah, mengoptimalkan rekomendasi produk, dan meningkatkan kepuasan pelanggan.
Kelas Algoritma Utama
Algoritma Pembelajaran yang Diawasi
-
Model linier: Digunakan untuk memprediksi variabel kontinu berdasarkan hubungan linier antara fitur dan variabel target.
-
Model Berbasis Pohon: Dibangun menggunakan serangkaian keputusan biner untuk membuat prediksi atau klasifikasi.
-
Model Ensemble: Metode yang menggabungkan beberapa model (berbasis pohon atau linier) untuk membuat prediksi yang lebih akurat.
-
Model Jaringan Neural: Metode yang secara longgar didasarkan pada otak manusia, di mana banyak fungsi berfungsi sebagai simpul jaringan.
Algoritma Pembelajaran Tanpa Pengawasan
-
Pengelompokan Hierarki: Membangun hierarki kluster dengan menggabungkan atau memisahkannya secara iteratif.
-
Non-Hierarchical Clustering: Membagi data menjadi cluster yang berbeda berdasarkan kesamaan.
-
Pengurangan Dimensi: Mengurangi dimensi data sambil mempertahankan informasi yang paling penting.
Evaluasi Model
Pembelajaran yang Diawasi
Untuk mengevaluasi kinerja model pembelajaran terbimbing, berbagai metrik digunakan, termasuk akurasi, presisi, daya ingat, skor F1, dan ROC-AUC. Teknik validasi silang, seperti validasi silang k-fold, dapat membantu memperkirakan kinerja generalisasi model.
Pembelajaran Tanpa Pengawasan
Mengevaluasi algoritme pembelajaran tanpa pengawasan seringkali lebih menantang karena tidak ada kebenaran dasar. Metrik seperti skor siluet atau inersia dapat digunakan untuk menilai kualitas hasil pengelompokan. Teknik visualisasi juga dapat memberikan wawasan tentang struktur cluster.
Tips dan Trik
Pembelajaran yang Diawasi
- Praproses dan normalisasi data input untuk meningkatkan performa model.
- Tangani nilai yang hilang dengan tepat, baik dengan imputasi atau penghapusan.
- Rekayasa fitur dapat meningkatkan kemampuan model untuk menangkap pola yang relevan.
Pembelajaran Tanpa Pengawasan
- Pilih jumlah klaster yang sesuai berdasarkan pengetahuan domain atau menggunakan teknik seperti metode siku.
- Pertimbangkan metrik jarak yang berbeda untuk mengukur kesamaan antara titik data.
- Regulerkan proses pengelompokan untuk menghindari overfitting.
Singkatnya, pembelajaran mesin melibatkan banyak tugas, teknik, algoritme, metode evaluasi model, dan petunjuk bermanfaat. Dengan memahami aspek-aspek ini, praktisi dapat secara efisien menerapkan pembelajaran mesin ke masalah dunia nyata dan mendapatkan wawasan yang signifikan dari data. Contoh kode yang diberikan menunjukkan pemanfaatan algoritma pembelajaran yang diawasi dan tidak diawasi, menyoroti penerapan praktisnya.
- Konten Bertenaga SEO & Distribusi PR. Dapatkan Amplifikasi Hari Ini.
- Keuangan EVM. Antarmuka Terpadu untuk Keuangan Terdesentralisasi. Akses Di Sini.
- Grup Media Kuantum. IR/PR Diperkuat. Akses Di Sini.
- PlatoAiStream. Kecerdasan Data Web3. Pengetahuan Diperkuat. Akses Di Sini.
- Sumber: https://stackabuse.com/supervised-learning-vs-unsupervised-learning-algorithms/