
Melatih model bahasa besar (LLM) dengan miliaran parameter dapat menjadi tantangan. Selain merancang arsitektur model, peneliti perlu menyiapkan teknik pelatihan canggih untuk pelatihan terdistribusi seperti dukungan presisi campuran, akumulasi gradien, dan pos pemeriksaan. Dengan model besar, penyiapan pelatihan bahkan lebih menantang karena memori yang tersedia dalam satu perangkat akselerator membatasi ukuran model yang dilatih hanya dengan menggunakan paralelisme data, dan menggunakan pelatihan paralel model memerlukan tingkat modifikasi tambahan pada kode pelatihan. Perpustakaan seperti Kecepatan Dalam (pustaka pengoptimalan pembelajaran mendalam sumber terbuka untuk PyTorch) mengatasi beberapa tantangan ini, dan dapat membantu mempercepat pengembangan dan pelatihan model.
Dalam posting ini, kami menyiapkan pelatihan berbasis Intel Habana Gaudi Cloud komputasi elastis Amazon (Amazon EC2) DL1 instans dan mengukur manfaat menggunakan kerangka kerja penskalaan seperti DeepSpeed. Kami menyajikan hasil penskalaan untuk model transformator tipe encoder (BERT dengan 340 juta hingga 1.5 miliar parameter). Untuk model 1.5 miliar parameter, kami mencapai efisiensi penskalaan sebesar 82.7% di 128 akselerator (16 instans dl1.24xlarge) menggunakan DeepSpeed ZERO optimasi tahap 1. Status pengoptimal dipartisi oleh DeepSpeed untuk melatih model besar menggunakan paradigma paralel data. Pendekatan ini telah diperluas untuk melatih model 5 miliar parameter menggunakan paralelisme data. Kami juga menggunakan dukungan asli Gaudi untuk tipe data BF16 untuk mengurangi ukuran memori dan meningkatkan kinerja pelatihan dibandingkan dengan menggunakan tipe data FP32. Hasilnya, kami mencapai konvergensi model pra-pelatihan (fase 1) dalam waktu 16 jam (target kami adalah untuk melatih model besar dalam satu hari) untuk model parameter BERT 1.5 miliar menggunakan kumpulan data wikicorpus-en.
Pengaturan pelatihan
Kami menyediakan cluster komputasi terkelola yang terdiri dari 16 instans dl1.24xlarge menggunakan Batch AWS. Kami mengembangkan sebuah Lokakarya AWS Batch yang mengilustrasikan langkah-langkah untuk menyiapkan klaster pelatihan terdistribusi dengan AWS Batch. Setiap instans dl1.24xlarge memiliki delapan akselerator Habana Gaudi, masing-masing dengan memori 32 GB dan jaringan RoCE full mesh antar kartu dengan total bandwidth interkoneksi dua arah masing-masing 700 Gbps (lihat Instans Amazon EC2 DL1 Deep Dive untuk informasi lebih lanjut). Cluster dl1.24xlarge juga menggunakan empat Adaptor Kain Elastis AWS (EFA), dengan total 400 Gbps interkoneksi antar node.
Lokakarya pelatihan terdistribusi mengilustrasikan langkah-langkah untuk menyiapkan klaster pelatihan terdistribusi. Lokakarya tersebut menunjukkan penyiapan pelatihan terdistribusi menggunakan AWS Batch dan khususnya, fitur pekerjaan paralel multi-node untuk meluncurkan tugas pelatihan dalam wadah skala besar pada kluster yang dikelola sepenuhnya. Lebih khusus lagi, lingkungan komputasi AWS Batch yang terkelola sepenuhnya dibuat dengan instans DL1. Wadah ditarik dari Registry Kontainer Elastis Amazon (Amazon ECR) dan diluncurkan secara otomatis ke dalam instance di cluster berdasarkan definisi pekerjaan paralel multi-node. Lokakarya diakhiri dengan menjalankan pelatihan paralel data multi-node, multi-HPU dari model BERT (340 juta hingga 1.5 miliar parameter) menggunakan PyTorch dan DeepSpeed.
Pra-pelatihan BERT 1.5B dengan DeepSpeed
Havana SynapseAI v1.5 dan v1.6 mendukung pengoptimalan DeepSpeed ZeRO1. Itu Garpu Habana dari repositori GitHub DeepSpeed termasuk modifikasi yang diperlukan untuk mendukung akselerator Gaudi. Ada dukungan penuh untuk data terdistribusi paralel (multi-kartu, multi-instance), pengoptimalan ZeRO1, dan tipe data BF16.
Semua fitur ini diaktifkan di Repositori referensi model BERT 1.5B, yang memperkenalkan model enkoder dua arah 48 lapis, 1600 dimensi tersembunyi, dan 25 kepala, yang berasal dari implementasi BERT. Repositori juga berisi implementasi model dasar BERT Large: arsitektur jaringan saraf 24-lapisan, 1024-tersembunyi, 16-kepala, 340-juta-parameter. Skrip pemodelan pra-pelatihan berasal dari Repositori Contoh Deep Learning NVIDIA untuk mengunduh data wikicorpus_en, memproses data mentah menjadi token, dan membagi data menjadi kumpulan data h5 yang lebih kecil untuk pelatihan paralel data terdistribusi. Anda dapat mengadopsi pendekatan umum ini untuk melatih arsitektur model PyTorch khusus menggunakan kumpulan data Anda menggunakan instans DL1.
Hasil penskalaan pra-pelatihan (fase 1).
Untuk model skala besar pra-pelatihan, kami terutama berfokus pada dua aspek solusi: kinerja pelatihan, yang diukur dengan waktu pelatihan, dan efektivitas biaya untuk mencapai solusi yang sepenuhnya terkonvergensi. Selanjutnya, kita menyelam lebih dalam ke dua metrik ini dengan pra-pelatihan BERT 1.5B sebagai contoh.
Menskalakan kinerja dan waktu untuk berlatih
Kami mulai dengan mengukur kinerja implementasi BERT Large sebagai dasar untuk skalabilitas. Tabel berikut mencantumkan throughput terukur dari urutan per detik dari instans 1-8 dl1.24xlarge (dengan delapan perangkat akselerator per instans). Dengan menggunakan throughput instans tunggal sebagai dasar, kami mengukur efisiensi penskalaan di beberapa instans, yang merupakan pengungkit penting untuk memahami metrik pelatihan kinerja harga.
| Jumlah Instance | Jumlah Akselerator | Urutan per Detik | Urutan per Detik per Akselerator | Efisiensi Penskalaan |
| 1 | 8 | 1,379.76 | 172.47 | 100.0% |
| 2 | 16 | 2,705.57 | 169.10 | 98.04% |
| 4 | 32 | 5,291.58 | 165.36 | 95.88% |
| 8 | 64 | 9,977.54 | 155.90 | 90.39% |
Gambar berikut mengilustrasikan efisiensi penskalaan.

Untuk BERT 1.5B, kami memodifikasi hyperparameter untuk model di repositori referensi untuk menjamin konvergensi. Ukuran batch efektif per akselerator diatur ke 384 (untuk pemanfaatan memori maksimum), dengan batch mikro 16 per langkah dan akumulasi gradien 24 langkah. Tingkat pembelajaran masing-masing 0.0015 dan 0.003 digunakan untuk 8 dan 16 node. Dengan konfigurasi ini, kami mencapai konvergensi prapelatihan fase 1 BERT 1.5B di 8 instans dl1.24xlarge (64 akselerator) dalam waktu sekitar 25 jam, dan 15 jam di instans 16 dl1.24xlarge (128 akselerator). Gambar berikut menunjukkan kerugian rata-rata sebagai fungsi dari jumlah masa pelatihan, saat kami meningkatkan jumlah akselerator.

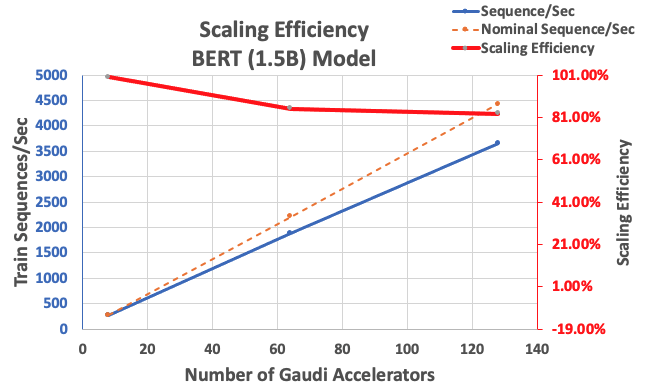
Dengan konfigurasi yang dijelaskan sebelumnya, kami memperoleh efisiensi penskalaan kuat 85% dengan 64 akselerator dan 83% dengan 128 akselerator, dari baseline 8 akselerator dalam satu contoh. Tabel berikut meringkas parameter.
| Jumlah Instance | Jumlah Akselerator | Urutan per Detik | Urutan per Detik per Akselerator | Efisiensi Penskalaan |
| 1 | 8 | 276.66 | 34.58 | 100.0% |
| 8 | 64 | 1,883.63 | 29.43 | 85.1% |
| 16 | 128 | 3,659.15 | 28.59 | 82.7% |
Gambar berikut mengilustrasikan efisiensi penskalaan.
Kesimpulan
Dalam postingan ini, kami mengevaluasi dukungan untuk DeepSpeed oleh Habana SynapseAI v1.5/v1.6 dan bagaimana dukungan ini membantu menskalakan pelatihan LLM pada akselerator Habana Gaudi. Pra-pelatihan model BERT 1.5 miliar parameter membutuhkan waktu 16 jam untuk menyatu pada sekelompok 128 akselerator Gaudi, dengan penskalaan kuat 85%. Kami mendorong Anda untuk melihat arsitektur yang ditunjukkan di bengkel AWS dan pertimbangkan untuk mengadopsinya untuk melatih arsitektur model PyTorch khusus menggunakan instans DL1.
Tentang penulis
 Mahadewa Balasubramaniam adalah Arsitek Solusi Utama untuk Komputasi Otonom dengan pengalaman hampir 20 tahun di bidang pembelajaran mendalam yang diresapi fisika, membangun, dan menerapkan kembar digital untuk sistem industri dalam skala besar. Mahadevan memperoleh gelar PhD di bidang Teknik Mesin dari Massachusetts Institute of Technology dan memiliki lebih dari 25 paten dan publikasi.
Mahadewa Balasubramaniam adalah Arsitek Solusi Utama untuk Komputasi Otonom dengan pengalaman hampir 20 tahun di bidang pembelajaran mendalam yang diresapi fisika, membangun, dan menerapkan kembar digital untuk sistem industri dalam skala besar. Mahadevan memperoleh gelar PhD di bidang Teknik Mesin dari Massachusetts Institute of Technology dan memiliki lebih dari 25 paten dan publikasi.
 RJ adalah seorang insinyur di tim Search M5 yang memimpin upaya membangun sistem pembelajaran mendalam skala besar untuk pelatihan dan inferensi. Di luar pekerjaan ia menjelajahi berbagai masakan makanan dan bermain olahraga raket.
RJ adalah seorang insinyur di tim Search M5 yang memimpin upaya membangun sistem pembelajaran mendalam skala besar untuk pelatihan dan inferensi. Di luar pekerjaan ia menjelajahi berbagai masakan makanan dan bermain olahraga raket.
 Sundar Ranganathan adalah Kepala Pengembangan Bisnis, Kerangka ML di tim Amazon EC2. Dia berfokus pada beban kerja ML skala besar di seluruh layanan AWS seperti Amazon EKS, Amazon ECS, Adaptor Fabric Elastis, AWS Batch, dan Amazon SageMaker. Pengalamannya mencakup peran kepemimpinan dalam manajemen produk dan pengembangan produk di NetApp, Micron Technology, Qualcomm, dan Mentor Graphics.
Sundar Ranganathan adalah Kepala Pengembangan Bisnis, Kerangka ML di tim Amazon EC2. Dia berfokus pada beban kerja ML skala besar di seluruh layanan AWS seperti Amazon EKS, Amazon ECS, Adaptor Fabric Elastis, AWS Batch, dan Amazon SageMaker. Pengalamannya mencakup peran kepemimpinan dalam manajemen produk dan pengembangan produk di NetApp, Micron Technology, Qualcomm, dan Mentor Graphics.
 Abhinandan Patni adalah Insinyur Perangkat Lunak Senior di Amazon Search. Dia berfokus pada membangun sistem dan alat untuk pelatihan pembelajaran mendalam terdistribusi yang skalabel dan inferensi waktu nyata.
Abhinandan Patni adalah Insinyur Perangkat Lunak Senior di Amazon Search. Dia berfokus pada membangun sistem dan alat untuk pelatihan pembelajaran mendalam terdistribusi yang skalabel dan inferensi waktu nyata.
 Pierre-Yves Aquilant adalah Head of Frameworks ML Solutions di Amazon Web Services di mana dia membantu mengembangkan solusi ML Frameworks berbasis cloud terbaik di industri. Latar belakangnya adalah Komputasi Kinerja Tinggi dan sebelum bergabung dengan AWS, Pierre-Yves bekerja di industri Minyak & Gas. Pierre-Yves berasal dari Prancis dan memegang gelar Ph.D. dalam Ilmu Komputer dari University of Lille.
Pierre-Yves Aquilant adalah Head of Frameworks ML Solutions di Amazon Web Services di mana dia membantu mengembangkan solusi ML Frameworks berbasis cloud terbaik di industri. Latar belakangnya adalah Komputasi Kinerja Tinggi dan sebelum bergabung dengan AWS, Pierre-Yves bekerja di industri Minyak & Gas. Pierre-Yves berasal dari Prancis dan memegang gelar Ph.D. dalam Ilmu Komputer dari University of Lille.
- Konten Bertenaga SEO & Distribusi PR. Dapatkan Amplifikasi Hari Ini.
- Keuangan EVM. Antarmuka Terpadu untuk Keuangan Terdesentralisasi. Akses Di Sini.
- Grup Media Kuantum. IR/PR Diperkuat. Akses Di Sini.
- PlatoAiStream. Kecerdasan Data Web3. Pengetahuan Diperkuat. Akses Di Sini.
- Sumber: https://aws.amazon.com/blogs/machine-learning/accelerate-pytorch-with-deepspeed-to-train-large-language-models-with-intel-habana-gaudi-based-dl1-ec2-instances/