
Postingan ini ditulis bersama oleh Goktug Cinar, Michael Binder, dan Adrian Horvath dari Bosch Center for Artificial Intelligence (BCAI).
Peramalan pendapatan adalah tugas yang menantang namun penting untuk keputusan bisnis strategis dan perencanaan fiskal di sebagian besar organisasi. Seringkali, perkiraan pendapatan dilakukan secara manual oleh analis keuangan dan memakan waktu dan subjektif. Upaya manual semacam itu sangat menantang bagi organisasi bisnis multinasional berskala besar yang memerlukan perkiraan pendapatan di berbagai kelompok produk dan wilayah geografis pada berbagai tingkat perincian. Ini tidak hanya membutuhkan akurasi tetapi juga koherensi hierarkis dari prakiraan.
Bosch adalah perusahaan multinasional dengan entitas yang beroperasi di berbagai sektor, termasuk otomotif, solusi industri, dan barang konsumsi. Mengingat dampak dari perkiraan pendapatan yang akurat dan koheren pada operasi bisnis yang sehat, Pusat Kecerdasan Buatan Bosch (BCAI) telah banyak berinvestasi dalam penggunaan pembelajaran mesin (ML) untuk meningkatkan efisiensi dan akurasi proses perencanaan keuangan. Tujuannya adalah untuk meringankan proses manual dengan memberikan perkiraan pendapatan dasar yang wajar melalui ML, dengan hanya penyesuaian sesekali yang diperlukan oleh analis keuangan menggunakan pengetahuan industri dan domain mereka.
Untuk mencapai tujuan ini, BCAI telah mengembangkan kerangka kerja peramalan internal yang mampu memberikan prakiraan hierarkis skala besar melalui ansambel yang disesuaikan dari berbagai model dasar. Seorang meta-pelajar memilih model dengan kinerja terbaik berdasarkan fitur yang diekstraksi dari setiap deret waktu. Perkiraan dari model yang dipilih kemudian dirata-ratakan untuk mendapatkan perkiraan agregat. Desain arsitektural dimodulasi dan diperluas melalui penerapan antarmuka gaya REST, yang memungkinkan peningkatan kinerja berkelanjutan melalui penyertaan model tambahan.
BCAI bermitra dengan Lab Solusi Amazon ML (MLSL) untuk menggabungkan kemajuan terbaru dalam model berbasis jaringan saraf dalam (DNN) untuk perkiraan pendapatan. Kemajuan terbaru dalam peramal saraf telah menunjukkan kinerja canggih untuk banyak masalah prakiraan praktis. Dibandingkan dengan model peramalan tradisional, banyak peramal saraf dapat menggabungkan kovariat tambahan atau metadata dari deret waktu. Kami menyertakan CNN-QR dan DeepAR+, dua model siap pakai di Prakiraan Amazon, serta model Transformer khusus yang dilatih menggunakan Amazon SageMaker. Tiga model mencakup satu set perwakilan tulang punggung encoder yang sering digunakan dalam peramal saraf: jaringan saraf convolutional (CNN), jaringan saraf berulang sekuensial (RNN), dan pembuat enkode berbasis transformator.
Salah satu tantangan utama yang dihadapi oleh kemitraan BCAI-MLSL adalah untuk memberikan perkiraan yang kuat dan masuk akal di bawah dampak COVID-19, peristiwa global yang belum pernah terjadi sebelumnya yang menyebabkan volatilitas besar pada hasil keuangan perusahaan global. Karena peramal saraf dilatih berdasarkan data historis, prakiraan yang dihasilkan berdasarkan data di luar distribusi dari periode yang lebih bergejolak bisa jadi tidak akurat dan tidak dapat diandalkan. Oleh karena itu, kami mengusulkan penambahan mekanisme perhatian bertopeng dalam arsitektur Transformer untuk mengatasi masalah ini.
Peramal saraf dapat dibundel sebagai model ensemble tunggal, atau digabungkan secara individual ke dalam dunia model Bosch, dan diakses dengan mudah melalui titik akhir REST API. Kami mengusulkan pendekatan untuk menggabungkan peramal saraf melalui hasil backtest, yang memberikan kinerja yang kompetitif dan kuat dari waktu ke waktu. Selain itu, kami menyelidiki dan mengevaluasi sejumlah teknik rekonsiliasi hierarki klasik untuk memastikan bahwa perkiraan digabungkan secara koheren di seluruh grup produk, geografi, dan organisasi bisnis.
Dalam posting ini, kami menunjukkan yang berikut:
- Cara menerapkan pelatihan model kustom Forecast dan SageMaker untuk masalah perkiraan deret waktu skala besar dan hierarkis
- Cara menggabungkan model khusus dengan model siap pakai dari Forecast
- Bagaimana mengurangi dampak peristiwa yang mengganggu seperti COVID-19 pada masalah peramalan
- Cara membangun alur kerja perkiraan ujung ke ujung di AWS
Tantangan
Kami membahas dua tantangan: menciptakan peramalan pendapatan skala besar yang hierarkis, dan dampak pandemi COVID-19 pada peramalan jangka panjang.
Perkiraan pendapatan berskala besar dan hierarkis
Analis keuangan ditugaskan untuk memperkirakan angka keuangan utama, termasuk pendapatan, biaya operasional, dan pengeluaran R&D. Metrik ini memberikan wawasan perencanaan bisnis di berbagai tingkat agregasi dan memungkinkan pengambilan keputusan berdasarkan data. Setiap solusi peramalan otomatis perlu memberikan prakiraan pada setiap tingkat agregasi lini bisnis yang berubah-ubah. Di Bosch, agregasi dapat dibayangkan sebagai deret waktu yang dikelompokkan sebagai bentuk struktur hierarki yang lebih umum. Gambar berikut menunjukkan contoh sederhana dengan struktur dua tingkat, yang meniru struktur perkiraan pendapatan hierarkis di Bosch. Total pendapatan dibagi menjadi beberapa tingkat agregasi berdasarkan produk dan wilayah.
Jumlah total deret waktu yang perlu diramalkan di Bosch adalah dalam skala jutaan. Perhatikan bahwa deret waktu tingkat atas dapat dibagi berdasarkan produk atau wilayah, membuat beberapa jalur ke perkiraan tingkat bawah. Pendapatan perlu diramalkan di setiap node dalam hierarki dengan cakrawala peramalan 12 bulan ke depan. Data historis bulanan tersedia.
Struktur hierarki dapat direpresentasikan menggunakan bentuk berikut dengan notasi matriks penjumlahan: S (Hyndman dan Athanasopoulos):
![]()
Dalam persamaan ini, Y sama dengan berikut ini:

Di sini, b mewakili deret waktu tingkat bawah pada waktu t.
Dampak pandemi COVID-19
Pandemi COVID-19 membawa tantangan signifikan untuk peramalan karena dampaknya yang mengganggu dan belum pernah terjadi sebelumnya pada hampir semua aspek pekerjaan dan kehidupan sosial. Untuk perkiraan pendapatan jangka panjang, gangguan tersebut juga membawa dampak hilir yang tidak terduga. Untuk mengilustrasikan masalah ini, gambar berikut menunjukkan rangkaian waktu sampel di mana pendapatan produk mengalami penurunan yang signifikan pada awal pandemi dan secara bertahap pulih setelahnya. Model perkiraan saraf tipikal akan mengambil data pendapatan termasuk periode COVID di luar distribusi (OOD) sebagai input konteks historis, serta kebenaran dasar untuk pelatihan model. Akibatnya, ramalan yang dihasilkan tidak lagi dapat diandalkan.

Pendekatan pemodelan
Pada bagian ini, kami membahas berbagai pendekatan pemodelan kami.
Prakiraan Amazon
Forecast adalah layanan AI/ML yang terkelola sepenuhnya dari AWS yang menyediakan model prakiraan deret waktu canggih yang telah dikonfigurasi sebelumnya. Ini menggabungkan penawaran ini dengan kemampuan internalnya untuk pengoptimalan hyperparameter otomatis, pemodelan ensemble (untuk model yang disediakan oleh Forecast), dan pembuatan perkiraan probabilistik. Hal ini memungkinkan Anda untuk dengan mudah menyerap kumpulan data khusus, data praproses, melatih model perkiraan, dan menghasilkan perkiraan yang kuat. Desain modular layanan lebih lanjut memungkinkan kami untuk dengan mudah melakukan kueri dan menggabungkan prediksi dari model kustom tambahan yang dikembangkan secara paralel.
Kami menggabungkan dua peramal saraf dari Forecast: CNN-QR dan DeepAR+. Keduanya adalah metode pembelajaran mendalam yang diawasi yang melatih model global untuk seluruh kumpulan data deret waktu. Model CNNQR dan DeepAR+ dapat mengambil informasi metadata statis tentang setiap deret waktu, yang merupakan produk, wilayah, dan organisasi bisnis yang sesuai dalam kasus kami. Mereka juga secara otomatis menambahkan fitur temporal seperti bulan dalam setahun sebagai bagian dari input ke model.
Transformer dengan masker perhatian untuk COVID
arsitektur transformator (Vaswani dkk.), awalnya dirancang untuk pemrosesan bahasa alami (NLP), baru-baru ini muncul sebagai pilihan arsitektur populer untuk peramalan deret waktu. Di sini, kami menggunakan arsitektur Transformer yang dijelaskan dalam Zhou dkk. tanpa perhatian log probabilistik jarang. Model ini menggunakan desain arsitektur yang khas dengan menggabungkan encoder dan decoder. Untuk perkiraan pendapatan, kami mengonfigurasi dekoder untuk secara langsung menampilkan perkiraan cakrawala 12 bulan alih-alih menghasilkan perkiraan bulan demi bulan dengan cara autoregresif. Berdasarkan frekuensi deret waktu, fitur terkait waktu tambahan seperti bulan dalam setahun ditambahkan sebagai variabel input. Variabel kategori tambahan yang menjelaskan informasi meta (produk, wilayah, organisasi bisnis) dimasukkan ke dalam jaringan melalui lapisan penyematan yang dapat dilatih.
Diagram berikut mengilustrasikan arsitektur Transformer dan mekanisme penyembunyian perhatian. Penyembunyian perhatian diterapkan di semua lapisan enkoder dan dekoder, seperti yang disorot dalam warna oranye, untuk mencegah data OOD memengaruhi prakiraan.

Kami mengurangi dampak jendela konteks OOD dengan menambahkan topeng perhatian. Model dilatih untuk menerapkan sangat sedikit perhatian pada periode COVID yang berisi outlier melalui masking, dan melakukan peramalan dengan informasi mask. Topeng perhatian diterapkan di setiap lapisan arsitektur dekoder dan enkoder. Jendela bertopeng dapat ditentukan secara manual atau melalui algoritma deteksi outlier. Selain itu, saat menggunakan jendela waktu yang berisi outlier sebagai label pelatihan, kerugian tidak disebarkan kembali. Metode berbasis penyamaran perhatian ini dapat diterapkan untuk menangani gangguan dan kasus OOD yang disebabkan oleh peristiwa langka lainnya dan meningkatkan kekokohan prakiraan.
Ansambel model
Ansambel model sering kali mengungguli model tunggal untuk peramalan—ini meningkatkan generalisasi model dan lebih baik dalam menangani data deret waktu dengan berbagai karakteristik dalam periodisitas dan intermiten. Kami menggabungkan serangkaian strategi model ensemble untuk meningkatkan kinerja model dan kekokohan prakiraan. Salah satu bentuk umum dari ansambel model pembelajaran mendalam adalah untuk menggabungkan hasil dari model yang berjalan dengan inisialisasi bobot acak yang berbeda, atau dari periode pelatihan yang berbeda. Kami menggunakan strategi ini untuk mendapatkan perkiraan untuk model Transformer.
Untuk lebih membangun ansambel di atas arsitektur model yang berbeda, seperti Transformer, CNNQR, dan DeepAR+, kami menggunakan strategi ansambel pan-model yang memilih model dengan performa terbaik untuk setiap deret waktu berdasarkan hasil backtest dan memperolehnya rata-rata. Karena hasil backtest dapat diekspor langsung dari model Forecast yang terlatih, strategi ini memungkinkan kami memanfaatkan layanan turnkey seperti Forecast dengan peningkatan yang diperoleh dari model khusus seperti Transformer. Pendekatan ansambel model end-to-end seperti itu tidak memerlukan pelatihan meta-pelajar atau menghitung fitur deret waktu untuk pemilihan model.
Rekonsiliasi hierarkis
Kerangka kerja adaptif untuk menggabungkan berbagai teknik sebagai langkah pascapemrosesan untuk rekonsiliasi perkiraan hierarkis, termasuk bottom-up (BU), rekonsiliasi top-down dengan proporsi peramalan (TDFP), kuadrat terkecil biasa (OLS), dan kuadrat terkecil tertimbang ( WLS). Semua hasil eksperimen dalam posting ini dilaporkan menggunakan rekonsiliasi top-down dengan proporsi peramalan.
Tinjauan arsitektur
Kami mengembangkan alur kerja end-to-end otomatis di AWS untuk menghasilkan perkiraan pendapatan menggunakan layanan termasuk Forecast, SageMaker, Layanan Penyimpanan Sederhana Amazon (Amazon S3), AWS Lambda, Fungsi Langkah AWS, dan Kit Pengembangan AWS Cloud (AWS CDK). Solusi yang diterapkan memberikan perkiraan deret waktu individual melalui REST API menggunakan Gerbang API Amazon, dengan mengembalikan hasil dalam format JSON yang telah ditentukan sebelumnya.
Diagram berikut mengilustrasikan alur kerja peramalan ujung ke ujung.

Pertimbangan desain utama untuk arsitektur adalah keserbagunaan, kinerja, dan keramahan pengguna. Sistem harus cukup fleksibel untuk menggabungkan serangkaian algoritme yang beragam selama pengembangan dan penerapan, dengan perubahan minimal yang diperlukan, dan dapat dengan mudah diperluas saat menambahkan algoritme baru di masa mendatang. Sistem juga harus menambahkan overhead minimum dan mendukung pelatihan paralel untuk Forecast dan SageMaker untuk mengurangi waktu pelatihan dan mendapatkan perkiraan terbaru lebih cepat. Akhirnya, sistem harus mudah digunakan untuk tujuan eksperimen.
Alur kerja ujung ke ujung secara berurutan berjalan melalui modul berikut:
- Modul pra-pemrosesan untuk pemformatan ulang dan transformasi data
- Modul pelatihan model yang menggabungkan model Prakiraan dan model khusus di SageMaker (keduanya berjalan secara paralel)
- Modul pascapemrosesan yang mendukung ansambel model, rekonsiliasi hierarkis, metrik, dan pembuatan laporan
Step Functions mengatur dan mengatur alur kerja dari ujung ke ujung sebagai mesin keadaan. Proses mesin negara dikonfigurasi dengan file JSON yang berisi semua informasi yang diperlukan, termasuk lokasi file CSV pendapatan historis di Amazon S3, perkiraan waktu mulai, dan pengaturan hyperparameter model untuk menjalankan alur kerja ujung ke ujung. Panggilan asinkron dibuat untuk memparalelkan pelatihan model di mesin status menggunakan fungsi Lambda. Semua data historis, file konfigurasi, hasil perkiraan, serta hasil antara seperti hasil pengujian ulang disimpan di Amazon S3. REST API dibangun di atas Amazon S3 untuk menyediakan antarmuka yang dapat dikueri untuk membuat kueri hasil perkiraan. Sistem dapat diperluas untuk menggabungkan model prakiraan baru dan fungsi pendukung seperti menghasilkan laporan visualisasi prakiraan.
Evaluasi
Di bagian ini, kami merinci pengaturan eksperimen. Komponen utama mencakup kumpulan data, metrik evaluasi, jendela backtest, serta pengaturan dan pelatihan model.
Dataset
Untuk melindungi privasi finansial Bosch saat menggunakan kumpulan data yang berarti, kami menggunakan kumpulan data sintetis yang memiliki karakteristik statistik serupa dengan kumpulan data pendapatan dunia nyata dari satu unit bisnis di Bosch. Kumpulan data berisi total 1,216 deret waktu dengan pendapatan yang dicatat dalam frekuensi bulanan, mencakup Januari 2016 hingga April 2022. Kumpulan data dikirimkan dengan 877 deret waktu pada tingkat paling terperinci (deret waktu bawah), dengan struktur deret waktu terkelompok yang sesuai diwakili sebagai matriks penjumlahan S. Setiap deret waktu dikaitkan dengan tiga atribut kategoris statis, yang sesuai dengan kategori produk, wilayah, dan unit organisasi dalam kumpulan data nyata (dianonimkan dalam data sintetis).
Metrik evaluasi
Kami menggunakan Median-Mean Arctangent Absolute Percentage Error (median-MAAPE) dan weighted-MAAPE untuk mengevaluasi kinerja model dan melakukan analisis komparatif, yang merupakan metrik standar yang digunakan di Bosch. MAAPE mengatasi kekurangan metrik Mean Absolute Percentage Error (MAPE) yang biasa digunakan dalam konteks bisnis. Median-MAAPE memberikan gambaran kinerja model dengan menghitung median MAAPE yang dihitung secara individual pada setiap deret waktu. Weighted-MAAPE melaporkan kombinasi tertimbang dari MAAPE individu. Bobot adalah proporsi pendapatan untuk setiap deret waktu dibandingkan dengan pendapatan gabungan dari seluruh kumpulan data. Weighted-MAAPE lebih mencerminkan dampak bisnis hilir dari akurasi peramalan. Kedua metrik dilaporkan di seluruh kumpulan data 1,216 deret waktu.
Jendela backtest
Kami menggunakan jendela backtest 12 bulan bergulir untuk membandingkan kinerja model. Gambar berikut mengilustrasikan jendela backtest yang digunakan dalam eksperimen dan menyoroti data terkait yang digunakan untuk pelatihan dan optimasi hyperparameter (HPO). Untuk jendela backtest setelah COVID-19 dimulai, hasilnya dipengaruhi oleh input OOD dari April hingga Mei 2020, berdasarkan apa yang kami amati dari rangkaian waktu pendapatan.

Penyiapan dan pelatihan model
Untuk pelatihan Transformer, kami menggunakan kerugian kuantil dan menskalakan setiap deret waktu menggunakan nilai rata-rata historisnya sebelum memasukkannya ke dalam Transformer dan menghitung kerugian pelatihan. Prakiraan akhir diskalakan ulang untuk menghitung metrik akurasi, menggunakan MeanScaler yang diimplementasikan di GluonTS. Kami menggunakan jendela konteks dengan data pendapatan bulanan dari 18 bulan terakhir, dipilih melalui HPO di jendela backtest dari Juli 2018 hingga Juni 2019. Metadata tambahan tentang setiap deret waktu dalam bentuk variabel kategoris statis dimasukkan ke dalam model melalui penyematan lapisan sebelum mengumpankannya ke lapisan transformator. Kami melatih Transformer dengan lima inisialisasi bobot acak yang berbeda dan rata-rata hasil perkiraan dari tiga zaman terakhir untuk setiap proses, dengan total rata-rata 15 model. Lima model pelatihan berjalan dapat diparalelkan untuk mengurangi waktu pelatihan. Untuk Transformer bertopeng, kami menunjukkan bulan dari April hingga Mei 2020 sebagai outlier.
Untuk semua pelatihan model Prakiraan, kami mengaktifkan HPO otomatis, yang dapat memilih model dan parameter pelatihan berdasarkan periode pengujian ulang yang ditentukan pengguna, yang disetel ke 12 bulan terakhir di jendela data yang digunakan untuk pelatihan dan HPO.
Hasil percobaan
Kami melatih Transformer bertopeng dan membuka kedok menggunakan kumpulan hyperparameter yang sama, dan membandingkan kinerjanya untuk jendela backtest segera setelah kejutan COVID-19. Dalam Transformer bertopeng, dua bulan bertopeng adalah April dan Mei 2020. Tabel berikut menunjukkan hasil dari serangkaian periode backtest dengan jendela peramalan 12 bulan mulai dari Juni 2020. Kita dapat mengamati bahwa Transformer bertopeng secara konsisten mengungguli versi yang tidak tertutup. .

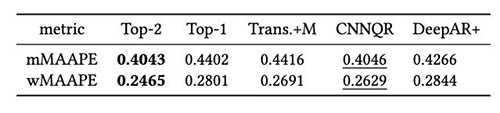
Selanjutnya kami melakukan evaluasi terhadap model ensemble strategy berdasarkan hasil backtest. Secara khusus, kami membandingkan dua kasus ketika hanya model berkinerja terbaik yang dipilih vs. ketika dua model berkinerja terbaik dipilih, dan rata-rata model dilakukan dengan menghitung nilai rata-rata perkiraan. Kami membandingkan kinerja model dasar dan model ensemble pada gambar berikut. Perhatikan bahwa tidak ada peramal saraf yang secara konsisten mengungguli yang lain untuk jendela backtest bergulir.


Tabel berikut menunjukkan bahwa, rata-rata, pemodelan ensemble dari dua model teratas memberikan kinerja terbaik. CNNQR memberikan hasil terbaik kedua.
Kesimpulan
Postingan ini menunjukkan cara membuat solusi ML menyeluruh untuk masalah perkiraan skala besar yang menggabungkan Forecast dan model khusus yang dilatih di SageMaker. Bergantung pada kebutuhan bisnis dan pengetahuan ML Anda, Anda dapat menggunakan layanan yang terkelola sepenuhnya seperti Forecast untuk membongkar proses pembuatan, pelatihan, dan penerapan model perkiraan; buat model kustom Anda dengan mekanisme penyetelan khusus dengan SageMaker; atau melakukan model ensembling dengan menggabungkan kedua layanan tersebut.
Jika Anda membutuhkan bantuan untuk mempercepat penggunaan ML di produk dan layanan Anda, silakan hubungi Lab Solusi Amazon ML program.
Referensi
Hyndman RJ, Athanasopoulos G. Peramalan: prinsip dan praktik. OTeks; 2018 8 Mei
Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez AN, Kaiser , Polosukhin I. Perhatian adalah semua yang Anda butuhkan. Kemajuan dalam sistem pemrosesan informasi saraf. 2017;30.
Zhou H, Zhang S, Peng J, Zhang S, Li J, Xiong H, Zhang W. Informan: Di luar transformator efisien untuk peramalan deret waktu urutan panjang. InProceedings AAI 2021 Feb 2
Tentang Penulis
 Goktug Cinar adalah ilmuwan ML utama dan pemimpin teknis ML dan peramalan berbasis statistik di Robert Bosch LLC dan Pusat Kecerdasan Buatan Bosch. Dia memimpin penelitian model peramalan, konsolidasi hierarkis, dan teknik kombinasi model serta tim pengembangan perangkat lunak yang menskalakan model-model ini dan menyajikannya sebagai bagian dari perangkat lunak peramalan keuangan ujung-ke-ujung internal.
Goktug Cinar adalah ilmuwan ML utama dan pemimpin teknis ML dan peramalan berbasis statistik di Robert Bosch LLC dan Pusat Kecerdasan Buatan Bosch. Dia memimpin penelitian model peramalan, konsolidasi hierarkis, dan teknik kombinasi model serta tim pengembangan perangkat lunak yang menskalakan model-model ini dan menyajikannya sebagai bagian dari perangkat lunak peramalan keuangan ujung-ke-ujung internal.
 Michael Binder adalah pemilik produk di Bosch Global Services, di mana dia mengoordinasikan pengembangan, penerapan, dan penerapan aplikasi analitik prediktif di seluruh perusahaan untuk peramalan data keuangan yang didorong oleh data otomatis berskala besar.
Michael Binder adalah pemilik produk di Bosch Global Services, di mana dia mengoordinasikan pengembangan, penerapan, dan penerapan aplikasi analitik prediktif di seluruh perusahaan untuk peramalan data keuangan yang didorong oleh data otomatis berskala besar.
 Adrian Horvath adalah Pengembang Perangkat Lunak di Bosch Center for Artificial Intelligence, tempat ia mengembangkan dan memelihara sistem untuk membuat prediksi berdasarkan berbagai model peramalan.
Adrian Horvath adalah Pengembang Perangkat Lunak di Bosch Center for Artificial Intelligence, tempat ia mengembangkan dan memelihara sistem untuk membuat prediksi berdasarkan berbagai model peramalan.
 Pan Pan Xu adalah Ilmuwan dan Manajer Terapan Senior dengan Amazon ML Solutions Lab di AWS. Dia sedang mengerjakan penelitian dan pengembangan algoritme Pembelajaran Mesin untuk aplikasi pelanggan berdampak tinggi di berbagai vertikal industri untuk mempercepat adopsi AI dan cloud mereka. Minat penelitiannya mencakup interpretasi model, analisis kausal, AI manusia dalam lingkaran, dan visualisasi data interaktif.
Pan Pan Xu adalah Ilmuwan dan Manajer Terapan Senior dengan Amazon ML Solutions Lab di AWS. Dia sedang mengerjakan penelitian dan pengembangan algoritme Pembelajaran Mesin untuk aplikasi pelanggan berdampak tinggi di berbagai vertikal industri untuk mempercepat adopsi AI dan cloud mereka. Minat penelitiannya mencakup interpretasi model, analisis kausal, AI manusia dalam lingkaran, dan visualisasi data interaktif.
 Jasleen Grewal adalah Ilmuwan Terapan di Amazon Web Services, tempat dia bekerja dengan pelanggan AWS untuk memecahkan masalah dunia nyata menggunakan pembelajaran mesin, dengan fokus khusus pada pengobatan presisi dan genomik. Dia memiliki latar belakang yang kuat dalam bioinformatika, onkologi, dan genomik klinis. Dia bersemangat menggunakan AI/ML dan layanan cloud untuk meningkatkan perawatan pasien.
Jasleen Grewal adalah Ilmuwan Terapan di Amazon Web Services, tempat dia bekerja dengan pelanggan AWS untuk memecahkan masalah dunia nyata menggunakan pembelajaran mesin, dengan fokus khusus pada pengobatan presisi dan genomik. Dia memiliki latar belakang yang kuat dalam bioinformatika, onkologi, dan genomik klinis. Dia bersemangat menggunakan AI/ML dan layanan cloud untuk meningkatkan perawatan pasien.
 Selvan Senthivel adalah Senior ML Engineer dengan Amazon ML Solutions Lab di AWS, dengan fokus membantu pelanggan dalam pembelajaran mesin, masalah pembelajaran mendalam, dan solusi ML ujung ke ujung. Dia adalah pemimpin teknik pendiri Amazon Comprehend Medical dan berkontribusi pada desain dan arsitektur beberapa layanan AI AWS.
Selvan Senthivel adalah Senior ML Engineer dengan Amazon ML Solutions Lab di AWS, dengan fokus membantu pelanggan dalam pembelajaran mesin, masalah pembelajaran mendalam, dan solusi ML ujung ke ujung. Dia adalah pemimpin teknik pendiri Amazon Comprehend Medical dan berkontribusi pada desain dan arsitektur beberapa layanan AI AWS.
 Ruilin Zhang adalah SDE dengan Amazon ML Solutions Lab di AWS. Dia membantu pelanggan mengadopsi layanan AWS AI dengan membangun solusi untuk mengatasi masalah bisnis umum.
Ruilin Zhang adalah SDE dengan Amazon ML Solutions Lab di AWS. Dia membantu pelanggan mengadopsi layanan AWS AI dengan membangun solusi untuk mengatasi masalah bisnis umum.
 Shane Rai adalah Pakar Strategi Senior ML dengan Amazon ML Solutions Lab di AWS. Dia bekerja dengan pelanggan di berbagai spektrum industri untuk menyelesaikan kebutuhan bisnis mereka yang paling mendesak dan inovatif menggunakan layanan AI/ML berbasis cloud yang luas dari AWS.
Shane Rai adalah Pakar Strategi Senior ML dengan Amazon ML Solutions Lab di AWS. Dia bekerja dengan pelanggan di berbagai spektrum industri untuk menyelesaikan kebutuhan bisnis mereka yang paling mendesak dan inovatif menggunakan layanan AI/ML berbasis cloud yang luas dari AWS.
 Lin LeeCheong adalah Manajer Sains Terapan dengan tim Amazon ML Solutions Lab di AWS. Dia bekerja dengan pelanggan AWS strategis untuk menjelajahi dan menerapkan kecerdasan buatan dan pembelajaran mesin untuk menemukan wawasan baru dan memecahkan masalah kompleks.
Lin LeeCheong adalah Manajer Sains Terapan dengan tim Amazon ML Solutions Lab di AWS. Dia bekerja dengan pelanggan AWS strategis untuk menjelajahi dan menerapkan kecerdasan buatan dan pembelajaran mesin untuk menemukan wawasan baru dan memecahkan masalah kompleks.