
Introduzione
L’intelligenza artificiale (AI) ha fatto passi da gigante in vari settori e l’assistenza sanitaria non fa eccezione. Una delle aree più promettenti dell’intelligenza artificiale nel settore sanitario è l’elaborazione del linguaggio naturale (NLP), che ha il potenziale per rivoluzionare la cura dei pazienti facilitando un’analisi e una comunicazione dei dati più efficiente e accurata.
La PNL ha dimostrato di essere un punto di svolta nel campo dell’assistenza sanitaria. La PNL sta trasformando il modo in cui gli operatori sanitari forniscono assistenza ai pazienti. Dalla gestione della salute della popolazione al rilevamento delle malattie, la PNL aiuta gli operatori sanitari a prendere decisioni informate e a fornire risultati terapeutici migliori.
obiettivi formativi
- Comprendere e analizzare l'uso della PNL e dell'intelligenza artificiale nel settore sanitario
- Acquisire le nozioni di base della PNL
- Conoscere alcune librerie NLP comunemente utilizzate nel settore sanitario
- Conoscere i casi d'uso della PNL in ambito sanitario
Questo articolo è stato pubblicato come parte di Blogathon sulla scienza dei dati.
Sommario
- La motivazione per l’utilizzo di AI e PNL nel settore sanitario
- Che cos'è l'elaborazione del linguaggio naturale?
- Diverse tecniche utilizzate nella PNL
3.1 Tecniche basate su regole
3.2 Tecniche statistiche che utilizzano modelli di Machine Learning
3.3 Trasferire l'apprendimento - Varie librerie di PNL e loro framework
- Cosa sono i modelli linguistici di grandi dimensioni (LLM)?
- La PNL nel testo clinico: la necessità di un approccio diverso
- Alcune librerie PNL utilizzate nel settore sanitario
- Comprensione dei set di dati clinici
- Quali sono i diversi tipi di dati clinici?
- Casi d'uso e applicazioni della PNL nel settore sanitario
- Come costruire una pipeline di PNL con testo clinico?
11.1 Progettazione della Soluzione
11.2 Codice passo passo - Conclusione
La motivazione per l’utilizzo di AI e PNL nel settore sanitario
La motivazione per l'utilizzo AI e la PNL nel settore sanitario è radicata nel miglioramento della cura del paziente e dei risultati del trattamento riducendo al contempo i costi sanitari. Il settore sanitario genera grandi quantità di dati, tra cui cartelle cliniche elettroniche, note cliniche e post sui social media relativi alla salute, che possono fornire informazioni preziose sulla salute dei pazienti e sui risultati del trattamento. Tuttavia, gran parte di questi dati non sono strutturati e difficili da analizzare manualmente.
Inoltre, il settore sanitario si trova ad affrontare diverse sfide, come l’invecchiamento della popolazione, l’aumento dei tassi di malattie croniche e la carenza di operatori sanitari.
Queste sfide hanno portato a una crescente necessità di un’assistenza sanitaria più efficiente ed efficace.
Fornendo preziose informazioni provenienti da dati medici non strutturati, la PNL può aiutare a migliorare la cura del paziente e i risultati del trattamento e supportare gli operatori sanitari nel prendere decisioni cliniche più informate.
Che cos'è l'elaborazione del linguaggio naturale?
L'elaborazione del linguaggio naturale (NLP) è un sottocampo dell'intelligenza artificiale (AI) che si occupa dell'interazione tra computer e linguaggio umano. Utilizza tecniche computazionali per analizzare, comprendere e generare il linguaggio umano. La PNL viene utilizzata in molte applicazioni, tra cui il riconoscimento vocale, la traduzione automatica, l'analisi dei sentimenti e il riepilogo del testo.
Esploreremo ora le varie tecniche, librerie e framework della PNL.
Diverse tecniche utilizzate nella PNL
Esistono due tecniche comunemente utilizzate nel settore della PNL.
1. Tecniche basate su regole: si basano su regole grammaticali e dizionari predefiniti
2. Tecniche statistiche: utilizzare algoritmi di apprendimento automatico per analizzare e comprendere il linguaggio
3. Utilizzo del modello linguistico di grandi dimensioni Trasferimento di apprendimento
Ecco una pipeline PNL standard con varie attività PNL
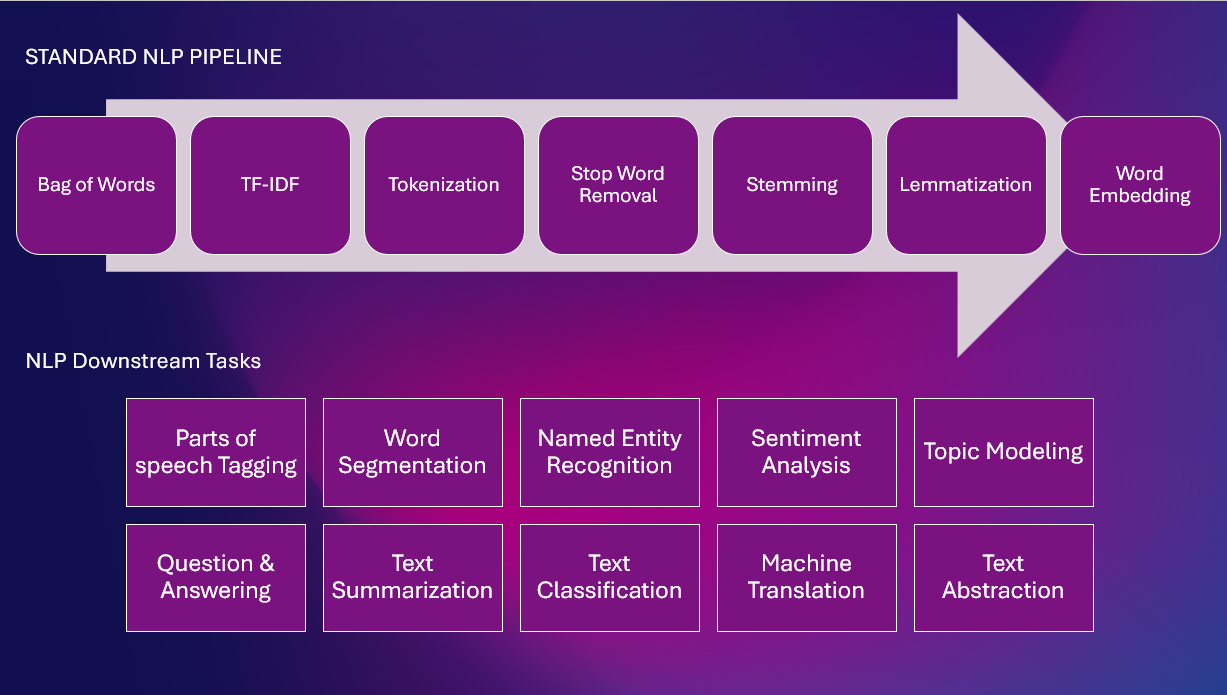
Tecniche basate su regole
Queste tecniche implicano la creazione di una serie di regole o modelli realizzati a mano per estrarre informazioni significative dal testo. I sistemi basati su regole in genere funzionano definendo modelli specifici che corrispondono alle informazioni di destinazione, come entità denominate o parole chiave specifiche, e quindi estraendo tali informazioni in base a tali modelli. Sistemi basati su regole sono veloci, affidabili e semplici, ma sono limitati dalla qualità e dal numero di regole definite e possono essere difficili da mantenere e aggiornare.
Ad esempio, un sistema basato su regole per il riconoscimento delle entità denominate potrebbe essere progettato per identificare i nomi propri nel testo e classificarli in tipi di entità predefiniti, come una persona, un luogo, un'organizzazione, una malattia, farmaci, ecc. Il sistema utilizzerebbe una serie di regole per identificare modelli nel testo che corrispondono ai criteri per ciascun tipo di entità, come l'uso delle maiuscole per i nomi delle persone o parole chiave specifiche per le organizzazioni.
Tecniche statistiche che utilizzano modelli di machine learning
Queste tecniche utilizzano algoritmi statistici per apprendere modelli nei dati e fare previsioni basate su tali modelli. I modelli di machine learning possono essere addestrati su grandi quantità di dati annotati, rendendoli più flessibili e scalabili rispetto ai sistemi basati su regole. Nella PNL vengono utilizzati diversi tipi di modelli di apprendimento automatico, inclusi alberi decisionali, foreste casuali, macchine vettoriali di supportoe reti neurali.
Ad esempio, un modello di machine learning per l'analisi del sentiment potrebbe essere addestrato su un ampio corpus di testo annotato, in cui ciascun testo è contrassegnato come positivo, negativo o neutro. Il modello apprenderebbe i modelli statistici nei dati che distinguono tra testo positivo e negativo e quindi utilizzerebbe tali modelli per fare previsioni su testo nuovo e invisibile. Il vantaggio di questo approccio è che il modello può imparare a identificare modelli di sentiment che non sono esplicitamente definiti nelle regole.
Trasferimento di apprendimento
Queste tecniche rappresentano un approccio ibrido che combina i punti di forza dei modelli basati su regole e di apprendimento automatico. L'apprendimento trasferito utilizza un modello di apprendimento automatico pre-addestrato, ad esempio un modello linguistico addestrato su un ampio corpus di testo, come punto di partenza per mettere a punto un'attività o un dominio specifico. Questo approccio sfrutta la conoscenza generale appresa dal modello pre-addestrato, riducendo la quantità di dati etichettati richiesti per l'addestramento e consentendo previsioni più rapide e accurate su un'attività specifica.
Ad esempio, un approccio di trasferimento di apprendimento per il riconoscimento di entità denominate potrebbe mettere a punto un modello linguistico pre-addestrato su un corpus più piccolo di testo medico annotato. Il modello inizierebbe con la conoscenza generale appresa dal modello pre-addestrato e quindi adeguerebbe i suoi pesi per adattarli meglio ai modelli del testo medico. Questo approccio ridurrebbe la quantità di dati etichettati necessari per la formazione e darebbe luogo a un modello più accurato per il riconoscimento delle entità denominate nel settore medico.
Varie librerie di PNL e loro framework
Varie librerie forniscono un'ampia gamma di funzionalità PNL. Ad esempio :

Le librerie e i framework per l'elaborazione del linguaggio naturale (NLP) sono strumenti software che aiutano a sviluppare e distribuire applicazioni NLP. Sono disponibili diverse librerie e framework di PNL, ciascuno con punti di forza, di debolezza e aree di interesse.
Questi strumenti variano in termini di complessità degli algoritmi che supportano, dimensione dei modelli che possono gestire, facilità d'uso e grado di personalizzazione che consentono.
Cosa sono i modelli linguistici di grandi dimensioni (LLM)?
I modelli linguistici di grandi dimensioni vengono addestrati su enormi quantità di dati. Può generare testo simile a quello umano ed eseguire un'ampia gamma di attività di PNL con elevata precisione.
Ecco alcuni esempi di modelli linguistici di grandi dimensioni e una breve descrizione di ciascuno:
GPT-3 (Trasformatore generativo preaddestrato 3): Sviluppato da OpenAI, GPT-3 è un grande modello linguistico basato su trasformatore che utilizza algoritmi di deep learning per generare testo simile a quello umano. È stato addestrato su un enorme corpus di dati di testo, consentendogli di generare risposte testuali coerenti e contestualmente appropriate basate su un prompt.
BERTA (Rappresentazioni di encoder bidirezionali da trasformatori): Sviluppato da Google, BERT è un modello linguistico basato su trasformatore che è stato pre-addestrato su un ampio corpus di dati di testo. È progettato per funzionare bene in un'ampia gamma di attività della PNL, come il riconoscimento di entità denominate, la risposta a domande e la classificazione del testo, codificando il contesto e le relazioni tra le parole in una frase.
RoBERta (Approccio BERT fortemente ottimizzato): Sviluppato da Facebook AI, RoBERTa è una variante di BERT che è stata messa a punto e ottimizzata per le attività di PNL. È stato addestrato su un corpus più ampio di dati di testo e utilizza una strategia di formazione diversa rispetto a BERT, portando a prestazioni migliori sui benchmark della PNL.
ELMo (Incorporamenti da modelli linguistici): Sviluppato dall'Allen Institute for AI, ELMo è un modello di rappresentazione delle parole profondamente contestualizzato che utilizza una rete bidirezionale LSTM (Long Short-Term Memory) per apprendere rappresentazioni linguistiche da un ampio corpus di dati di testo. ELMo può essere ottimizzato per attività NLP specifiche o utilizzato come estrattore di funzionalità per altri modelli di apprendimento automatico.
ULMFiT (ottimizzazione del modello linguistico universale): Sviluppato da FastAI, ULMFiT è un metodo di trasferimento di apprendimento che mette a punto un modello linguistico pre-addestrato su una specifica attività di PNL utilizzando una piccola quantità di dati annotati specifici dell'attività. ULMFiT ha raggiunto prestazioni all'avanguardia su un'ampia gamma di benchmark della PNL ed è considerato un esempio importante di trasferimento dell'apprendimento nella PNL.
PNL nel testo clinico: la necessità di un approccio diverso
Il testo clinico è spesso non strutturato e contiene molto gergo medico e acronimi, rendendo difficile la comprensione e l'elaborazione dei modelli di PNL tradizionali. Inoltre, il testo clinico spesso include informazioni importanti come malattie, farmaci, informazioni sui pazienti, diagnosi e piani di trattamento, che richiedono modelli PNL specializzati in grado di estrarre e comprendere accuratamente queste informazioni mediche.
Un altro motivo per cui il testo clinico necessita di diversi modelli di PNL è che contiene una grande quantità di dati distribuiti tra diverse fonti, come cartelle cliniche elettroniche, note cliniche e referti radiologici, che devono essere integrati. Ciò richiede modelli in grado di elaborare e comprendere il testo, collegare e integrare i dati provenienti da diverse fonti e stabilire relazioni clinicamente accettabili.
Infine, il testo clinico spesso contiene informazioni sensibili sul paziente e deve essere protetto da normative rigorose come l'HIPAA. I modelli NLP utilizzati per elaborare il testo clinico devono essere in grado di identificare e proteggere le informazioni sensibili del paziente fornendo allo stesso tempo informazioni utili.
Alcune librerie PNL utilizzate nel settore sanitario
I dati testuali in medicina richiedono un sistema specializzato di elaborazione del linguaggio naturale (NLP) in grado di estrarre informazioni mediche da varie fonti come testi clinici e altri documenti medici.
Ecco un elenco di librerie e modelli NLP specifici per il dominio medico:
spazio: È una libreria PNL open source che fornisce modelli pronti all'uso per vari domini, incluso quello medico.
ScispaCia: Una versione specializzata di spaCy addestrata specificamente su testo scientifico e biomedico, che lo rende ideale per l'elaborazione di testi medici.
BioBERT: Un modello pre-addestrato basato su trasformatore progettato specificatamente per il settore biomedico. È pre-addestrato con Wiki + Books + PubMed + PMC.
BERT Clinico: Un altro modello pre-addestrato progettato per elaborare note cliniche e riepiloghi di dimissione dal database MIMIC-III.
Med7: Un modello basato su trasformatore addestrato sulle cartelle cliniche elettroniche (EHR) per estrarre sette concetti clinici chiave, tra cui diagnosi, farmaci e test di laboratorio.
DisMod-ML: Un framework di modellazione probabilistica per la modellazione delle malattie che utilizza tecniche di PNL per elaborare testi medici.
MEDICO: Un sistema PNL basato su regole per estrarre informazioni mediche dal testo.
Queste sono alcune delle librerie e dei modelli NLP più popolari progettati specificamente per il settore medico. Offrono una gamma di funzionalità, da modelli pre-addestrati a sistemi basati su regole, e possono aiutare le organizzazioni sanitarie a elaborare i testi medici in modo efficace.
Nel nostro modello NER utilizzeremo spaCy e Scispacy. Queste librerie sono relativamente facili da eseguire su Google Colab o sull'infrastruttura locale.
I modelli linguistici di grandi dimensioni BioBERT e ClinicalBERT ad alta intensità di risorse necessitano di GPU e infrastrutture più elevate.
Comprensione dei set di dati clinici
I dati di testo medico possono essere ottenuti da varie fonti, come cartelle cliniche elettroniche (EHR), riviste mediche, note cliniche, siti Web medici e database. Alcune di queste fonti forniscono set di dati disponibili al pubblico che possono essere utilizzati per l'addestramento di modelli di PNL, mentre altre potrebbero richiedere l'approvazione e considerazioni etiche prima di accedere ai dati. Le fonti dei dati dei testi medici includono:
1. Corpora medici open source come Banca dati MIMIC-III è un ampio database di cartelle cliniche elettroniche (EHR) liberamente accessibile di pazienti che hanno ricevuto cure presso il Beth Israel Deaconess Medical Center tra il 2001 e il 2012. Il database include informazioni quali dati demografici dei pazienti, segni vitali, test di laboratorio, farmaci, procedure e note degli operatori sanitari, come infermieri e medici. Inoltre, il database include informazioni sui ricoveri in terapia intensiva dei pazienti, compreso il tipo di terapia intensiva, la durata del ricovero e gli esiti. I dati in MIMIC-III sono deidentificati e possono essere utilizzati a fini di ricerca per supportare lo sviluppo di modelli predittivi e sistemi di supporto alle decisioni cliniche.
2. Biblioteca Nazionale di Medicina ClinicalTrials.gov il sito web contiene dati di studi clinici e dati di sorveglianza della malattia.
3. Biblioteca nazionale di medicina del National Institutes of Health, Centri nazionali per l'informazione sulle biotecnologie (NCBI), e l'Organizzazione Mondiale della Sanità (OMS)
4. Le istituzioni e le organizzazioni sanitarie come ospedali, cliniche e aziende farmaceutiche generano grandi quantità di dati di testi medici attraverso cartelle cliniche elettroniche, note cliniche, trascrizioni mediche e referti medici.
5. Le riviste e i database di ricerca medica, come PubMed e CINAHL, contengono grandi quantità di articoli e abstract di ricerca medica pubblicati.
6. Le piattaforme di social media come Twitter possono fornire approfondimenti in tempo reale sui punti di vista dei pazienti, sulle revisioni dei farmaci e sulle esperienze.
Per addestrare modelli PNL utilizzando dati di testo medico, è importante considerare la qualità e la pertinenza dei dati e garantire che siano adeguatamente pre-elaborati e formattati. Inoltre, è importante rispettare considerazioni etiche e legali quando si lavora con informazioni mediche sensibili.
Quali sono i diversi tipi di dati clinici?
Diversi tipi di dati clinici sono comunemente utilizzati in ambito sanitario:

I dati clinici si riferiscono alle informazioni sull'assistenza sanitaria degli individui, tra cui l'anamnesi del paziente, le diagnosi, i trattamenti, i risultati di laboratorio, gli studi di imaging e altre informazioni sanitarie rilevanti.
Dati EHR/EMR sono collegati a dati demografici (questo include informazioni personali come età, sesso, etnia e informazioni di contatto), dati generati dai pazienti (questo tipo di dati è generato dai pazienti stessi, comprese le informazioni raccolte attraverso le misurazioni dei risultati riferiti dai pazienti e -dati sanitari generati.)
Altri insiemi di dati sono:
Dati genomici: questo tipo si riferisce alle informazioni genetiche di un individuo, comprese sequenze e marcatori di DNA.
Dati del dispositivo indossabile: Questi dati includono informazioni raccolte da dispositivi indossabili come fitness tracker e cardiofrequenzimetri.
Ciascun tipo di dati clinici svolge un ruolo unico nel fornire una visione completa della salute di un paziente e viene utilizzato in modi diversi dagli operatori sanitari e dai ricercatori per migliorare la cura del paziente e informare le decisioni terapeutiche.
Casi d'uso e applicazioni della PNL nel settore sanitario
L'elaborazione del linguaggio naturale (NLP) è stata ampiamente adottata nel settore sanitario e ha diversi casi d'uso. Alcuni di quelli importanti includono:
Popolazione: la PNL può essere utilizzata per elaborare grandi quantità di dati medici non strutturati come cartelle cliniche, sondaggi e dati sulle richieste di indennizzo per identificare modelli, correlazioni e approfondimenti. Ciò aiuta a monitorare la salute della popolazione e a individuare precocemente le malattie.
Cura del paziente: La PNL può essere utilizzata per elaborare le cartelle cliniche elettroniche (EHR) dei pazienti per estrarre informazioni vitali come diagnosi, farmaci e sintomi. Queste informazioni possono essere utilizzate per migliorare la cura del paziente e fornire un trattamento personalizzato.
Rilevazione della malattia: La PNL può essere utilizzata per elaborare grandi quantità di dati di testo, come articoli scientifici, articoli di notizie e post sui social media, per rilevare epidemie di malattie infettive.
Sistema di supporto alle decisioni cliniche (CDSS): La PNL può essere utilizzata per analizzare le cartelle cliniche elettroniche dei pazienti per fornire supporto decisionale in tempo reale agli operatori sanitari. Ciò aiuta a fornire le migliori opzioni di trattamento possibili e a migliorare la qualità complessiva dell’assistenza.
Test clinico: La PNL può elaborare i dati degli studi clinici per identificare correlazioni e potenziali nuovi trattamenti.
Eventi avversi da farmaci: La PNL può essere utilizzata per elaborare grandi quantità di dati sulla sicurezza dei farmaci per identificare eventi avversi e interazioni farmacologiche.
Salute di precisione: La PNL può essere utilizzata per elaborare dati genomici e cartelle cliniche per identificare opzioni di trattamento personalizzate per i singoli pazienti.
Miglioramento dell'efficienza del professionista medico: La PNL può automatizzare attività di routine come la codifica medica, l'immissione di dati e l'elaborazione delle richieste, consentendo ai professionisti medici di concentrarsi sulla fornitura di una migliore assistenza ai pazienti.
Questi sono solo alcuni esempi di come la PNL rivoluziona il settore sanitario. Poiché la tecnologia PNL continua ad avanzare, possiamo aspettarci di vedere in futuro usi più innovativi della PNL nel settore sanitario.
Come costruire una pipeline di PNL con testo clinico?
Svilupperemo una pipeline Spacy passo dopo passo utilizzando il modello NER SciSpacy per il testo clinico.
Obiettivo: Questo progetto mira a costruire una pipeline di PNL utilizzando SciSpacy per eseguire il riconoscimento personalizzato di entità denominate su testi clinici.
Risultato: Il risultato sarà l'estrazione di informazioni relative a malattie, farmaci e dosi di farmaci dal testo clinico, che potranno poi essere utilizzate in varie applicazioni a valle della PNL.
Progettazione della soluzione:
Ecco la soluzione di alto livello per estrarre informazioni sull'entità dal testo clinico. L'estrazione del NER è un'attività importante della PNL utilizzata nella maggior parte delle pipeline della PNL.
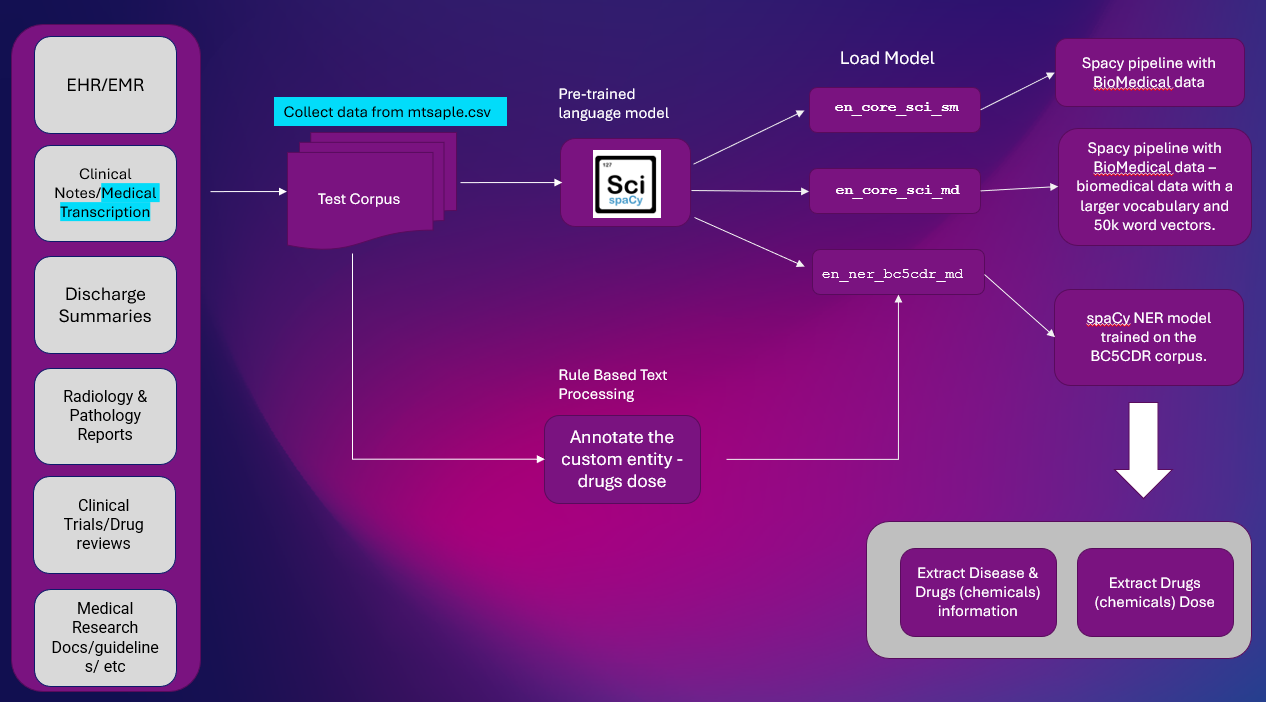
Piattaforma: Google Cola
Librerie di PNL: spaCy e SciSpacy
dataset: mtsample.csv (dati scartati da mtsample).
Abbiamo usato ScispaCy modello NER pre-addestrato en_ner_bc5cdr_md-0.5.1 per estrarre malattie e farmaci. I farmaci vengono estratti come prodotti chimici.
en_ner_bc5cdr_md-0.5.1 è un modello spaCy per il riconoscimento delle entità denominate (NER) nel dominio biomedico.
Il "bc5cdr" si riferisce al file BC5CDR corpus, un corpus di testi biomedici utilizzato per addestrare il modello. La “md” nel nome si riferisce al settore biomedico. La “0.5.1” nel nome si riferisce alla versione del modello.
Utilizzeremo il testo di "trascrizione" di esempio da mtsample.csv e annoteremo utilizzando un modello basato su regole per estrarre le dosi di farmaco.
Codice passo passo:
Installa i pacchetti spacy e scispacy. I modelli spaCy sono progettati per eseguire attività NLP specifiche, come la tokenizzazione, il tagging di parti del discorso e il riconoscimento di entità denominate.
!pip install -U spacy !pip install scispacy
Installa modelli base Scispacy e modelli NER
Il modello en_ner_bc5cdr_md-0.5.1 è specificamente progettato per riconoscere entità denominate nel testo biomedico, come malattie, geni e farmaci, come sostanze chimiche.
Questo modello può essere utile per attività di PNL nel dominio biomedico, come l'estrazione di informazioni, la classificazione del testo e la risposta alle domande.
!pip install https://s3-us-west-2.amazonaws.com/ai2-s2-scispacy/releases/v0.5.1/en_core_sci_sm-0.5.1.tar.gz !pip install https://s3-us-west-2.amazonaws.com/ai2-s2-scispacy/releases/v0.5.1/en_core_sci_md-0.5.1.tar.gz !pip install https://s3-us-west-2.amazonaws.com/ai2-s2-scispacy/releases/v0.5.1/en_ner_bc5cdr_md-0.5.1.tar.gz
Installa altri pacchetti
rendering dell'installazione pip
Importa pacchetti
import scispacy import spacy #Core models import en_core_sci_sm import en_core_sci_md
#Modelli specifici NER import en_ner_bc5cdr_md #Strumenti per estrarre e visualizzare i dati da spacy import displacy import pandas as pd
Codice Python:
Testare i modelli con dati campione
# Scegli la trascrizione specifica da utilizzare (riga 3, colonna "trascrizione") e testa il modello NER di scispacy text = mtsample_df.loc[10, "transcription"]

Carica il modello specifico: en_core_sci_sm e passa il testo
nlp_sm = en_core_sci_sm.load() doc = nlp_sm(testo)
#Visualizza risultato
estrazione entità displacy_image = displacy.render(doc, jupyter=True,style='ent')

Tieni presente che l'entità è contrassegnata qui. Per lo più termini medici. Si tratta tuttavia di entità generiche.
Ora carica il modello specifico: en_core_sci_md e passa il testo
nlp_md = en_core_sci_md.load() doc = nlp_md(testo)
#Visualizza l'estrazione dell'entità risultante
displacy_image = displacy.render(doc, jupyter=True,style='ent')

Questa volta i numeri sono anche contrassegnati come entità da en_core_sci_md.
Ora carica il modello specifico: importa en_ner_bc5cdr_md e passa il testo
nlp_bc = en_ner_bc5cdr_md.load() doc = nlp_bc(text) #Visualizza l'estrazione dell'entità risultante displacy_image = displacy.render(doc, jupyter=True,style='ent')

Ora vengono etichettate due entità mediche: malattia e sostanza chimica (farmaci).
Visualizza l'entità
print("TEXT", "START", "END", "ENTITY TYPE") per ent in doc.ents: print(ent.text, ent.start_char, ent.end_char, ent.label_)
TIPO ENTITA' INIZIO FINE TESTO
Obesità patologica 26 40 MALATTIA
Obesità patologica 70 84 MALATTIA
perdita di peso 400 411 MALATTIA
Marcaine 1256 1264 CHIMICO
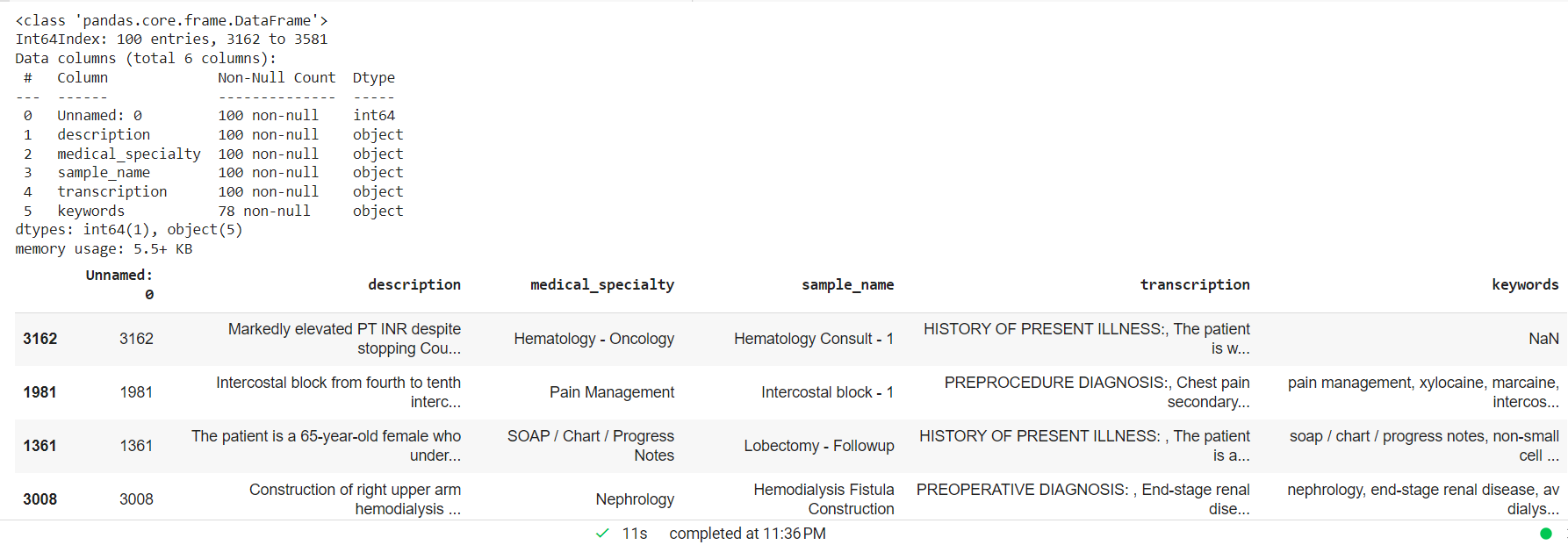
Elabora il testo clinico eliminando i valori NAN e creando un campione casuale più piccolo per il modello di entità personalizzato.
mtsample_df.dropna(subset=['trascrizione'], inplace=True) mtsample_df_subset = mtsample_df.sample(n=100, replace=False, random_state=42) mtsample_df_subset.info() mtsample_df_subset.head()
abbinamento spaCy – La corrispondenza basata su regole ricorda l'utilizzo delle espressioni regolari, ma spaCy fornisce funzionalità aggiuntive. L'utilizzo dei token e delle relazioni all'interno di un documento consente di identificare modelli che includono entità con l'aiuto dei modelli NER. L'obiettivo è individuare i nomi dei farmaci e i loro dosaggi dal testo, il che potrebbe aiutare a rilevare errori terapeutici confrontandoli con standard e linee guida.
L'obiettivo è individuare i nomi dei farmaci e i loro dosaggi dal testo, il che potrebbe aiutare a rilevare errori terapeutici confrontandoli con standard e linee guida.
da spacy.matcher importa Matcher
pattern = [{'ENT_TYPE':'CHEMICAL'}, {'LIKE_NUM': True}, {'IS_ASCII': True}] matcher = Matcher(nlp_bc.vocab) matcher.add("DRUG_DOSE", [pattern])
for transcription in mtsample_df_subset['transcription']: doc = nlp_bc(transcription)matches = matcher(doc) for match_id, start, end inmatch: string_id = nlp_bc.vocab.strings[match_id] # ottieni rappresentazione della stringa span = doc[start :end] # l'intervallo corrispondente aggiungendo le dosi dei farmaci print(span.text, start, end, string_id,) #Aggiungi malattia e farmaci per ent in doc.ents: print(ent.text, ent.start_char, ent.end_char, ent .etichetta_)
L'output mostrerà le entità estratte dal campione di testo clinico.
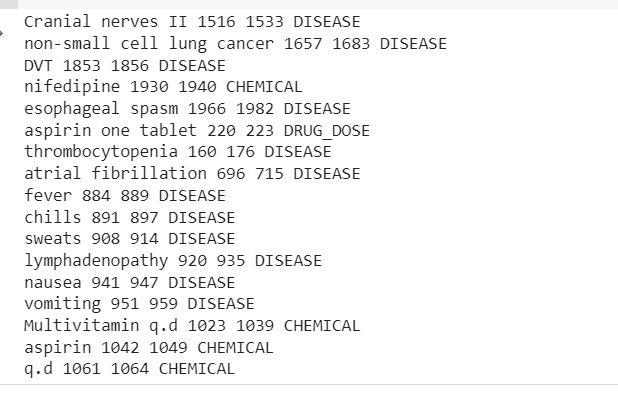
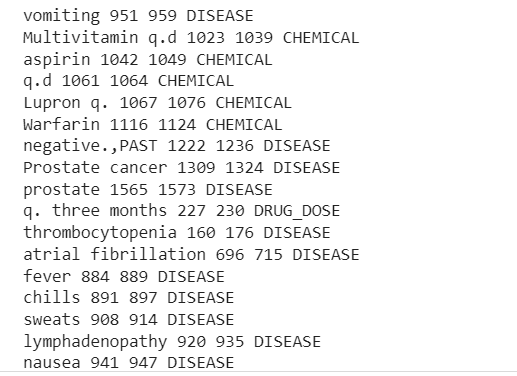
Ora possiamo vedere la pipeline estratta Malattia, farmaci (prodotti chimici) e dosi di farmaci informazioni dal testo clinico.
C'è qualche errore di classificazione, ma possiamo aumentare le prestazioni del modello utilizzando più dati.
Ora possiamo utilizzare queste entità mediche in vari compiti come il rilevamento delle malattie, l'analisi predittiva, il sistema di supporto alle decisioni cliniche, la classificazione dei testi medici, il riepilogo, la risposta alle domande e molto altro.
Conclusione
1. In questo articolo, abbiamo esplorato alcune delle caratteristiche chiave della PNL nel settore sanitario, che aiuteranno a comprendere i complessi dati dei testi sanitari.
Abbiamo anche implementato scispaCy e spaCy e costruito un semplice modello NER personalizzato attraverso un modello NER preaddestrato e un abbinamento basato su regole. Sebbene abbiamo trattato solo un modello NER, ne sono disponibili numerosi altri e una grande quantità di funzionalità aggiuntive da scoprire.
2. All'interno del framework scispaCy, ci sono numerose tecniche aggiuntive da esplorare, inclusi metodi per rilevare le abbreviazioni, eseguire l'analisi delle dipendenze e identificare singole frasi.
3. Le ultime tendenze nella PNL per l'assistenza sanitaria includono lo sviluppo di modelli specifici del dominio come BioBERT e ClinicalBert e l'utilizzo di modelli linguistici di grandi dimensioni come GPT-3. Questi modelli offrono un elevato livello di precisione ed efficienza, ma il loro utilizzo solleva anche preoccupazioni su bias, privacy e controllo sui dati.
ChatGPT (un modello avanzato di intelligenza artificiale conversazionale sviluppato da OpenAI) sta già avendo un enorme impatto nel mondo della PNL. Il modello è addestrato su un'enorme quantità di dati di testo provenienti da Internet e ha la capacità di generare risposte di testo simili a quelle umane in base all'input che riceve. Può essere utilizzato per varie attività come la risposta a domande, il riepilogo, la traduzione e altro ancora. Il modello è inoltre ottimizzato per casi d'uso specifici, come la generazione di codice o la scrittura di articoli, per migliorare le sue prestazioni in quelle aree specifiche.
5. Tuttavia, nonostante i suoi numerosi vantaggi, la PNL nel settore sanitario non è priva di sfide. Garantire l’accuratezza e l’equità dei modelli di PNL e superare le preoccupazioni sulla privacy dei dati sono alcune delle sfide che devono essere affrontate per realizzare appieno il potenziale della PNL nel settore sanitario.
6. Con i suoi numerosi vantaggi, è essenziale che gli operatori sanitari abbraccino e incorporino la PNL nei loro flussi di lavoro. Sebbene ci siano molte sfide da superare, la PNL nel settore sanitario è sicuramente una tendenza che vale la pena osservare e su cui investire.
I media mostrati in questo articolo non sono di proprietà di Analytics Vidhya e vengono utilizzati a discrezione dell'autore.
Leggi Anche
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- Platoblockchain. Web3 Metaverse Intelligence. Conoscenza amplificata. Accedi qui.
- Fonte: https://www.analyticsvidhya.com/blog/2023/02/extracting-medical-information-from-clinical-text-with-nlp/