
Introduzione
Machine Learning (ML) è un campo di studio che si concentra sullo sviluppo di algoritmi per apprendere automaticamente dai dati, fare previsioni e inferire schemi senza che gli venga detto esplicitamente come farlo. Mira a creare sistemi che migliorano automaticamente con l'esperienza e i dati.
Ciò può essere ottenuto attraverso l'apprendimento supervisionato, in cui il modello viene addestrato utilizzando dati etichettati per fare previsioni, o attraverso l'apprendimento non supervisionato, in cui il modello cerca di scoprire modelli o correlazioni all'interno dei dati senza output target specifici da anticipare.
Il machine learning è emerso come uno strumento indispensabile e ampiamente utilizzato in varie discipline, tra cui informatica, biologia, finanza e marketing. Ha dimostrato la sua utilità in diverse applicazioni come la classificazione delle immagini, l'elaborazione del linguaggio naturale e il rilevamento delle frodi.
Attività di apprendimento automatico
L'apprendimento automatico può essere ampiamente classificato in tre attività principali:
- Apprendimento supervisionato
- Apprendimento senza supervisione
- Insegnamento rafforzativo
Qui, ci concentreremo sui primi due casi.
Apprendimento supervisionato
L'apprendimento supervisionato comporta l'addestramento di un modello su dati etichettati, in cui i dati di input sono abbinati all'output corrispondente o alla variabile target. L'obiettivo è apprendere una funzione in grado di mappare i dati di input sull'output corretto. Gli algoritmi comuni di apprendimento supervisionato includono la regressione lineare, la regressione logistica, gli alberi decisionali e le macchine vettoriali di supporto.
Esempio di codice di apprendimento supervisionato utilizzando Python:
from sklearn.linear_model import LinearRegression model = LinearRegression() model.fit(X_train, y_train) predictions = model.predict(X_test)
In questo semplice esempio di codice, addestriamo il file LinearRegression algoritmo di scikit-learn sui nostri dati di addestramento, quindi applicalo per ottenere previsioni per i nostri dati di test.
Un caso d'uso reale dell'apprendimento supervisionato è la classificazione dello spam nelle e-mail. Con la crescita esponenziale della comunicazione via e-mail, identificare e filtrare le e-mail di spam è diventato cruciale. Utilizzando algoritmi di apprendimento supervisionato, è possibile addestrare un modello per distinguere tra e-mail legittime e spam basato su dati etichettati.
Il modello di apprendimento supervisionato può essere addestrato su un set di dati contenente e-mail etichettate come "spam" o "non spam". Il modello apprende modelli e caratteristiche dai dati etichettati, come la presenza di determinate parole chiave, la struttura dell'e-mail o le informazioni sul mittente dell'e-mail. Una volta che il modello è stato addestrato, può essere utilizzato per classificare automaticamente le email in arrivo come spam o non spam, filtrando in modo efficiente i messaggi indesiderati.
Apprendimento senza supervisione
Nell'apprendimento non supervisionato, i dati di input non sono etichettati e l'obiettivo è scoprire modelli o strutture all'interno dei dati. Gli algoritmi di apprendimento senza supervisione mirano a trovare rappresentazioni o cluster significativi nei dati.
Esempi di algoritmi di apprendimento senza supervisione includono k-significa raggruppamento, clustering gerarchicoe analisi delle componenti principali (PCA).
Esempio di codice di apprendimento senza supervisione:
from sklearn.cluster import KMeans model = KMeans(n_clusters=3) model.fit(X) predictions = model.predict(X_new)
In questo semplice esempio di codice, addestriamo il file KMeans algoritmo di scikit-learn per identificare tre cluster nei nostri dati e quindi inserire nuovi dati in tali cluster.
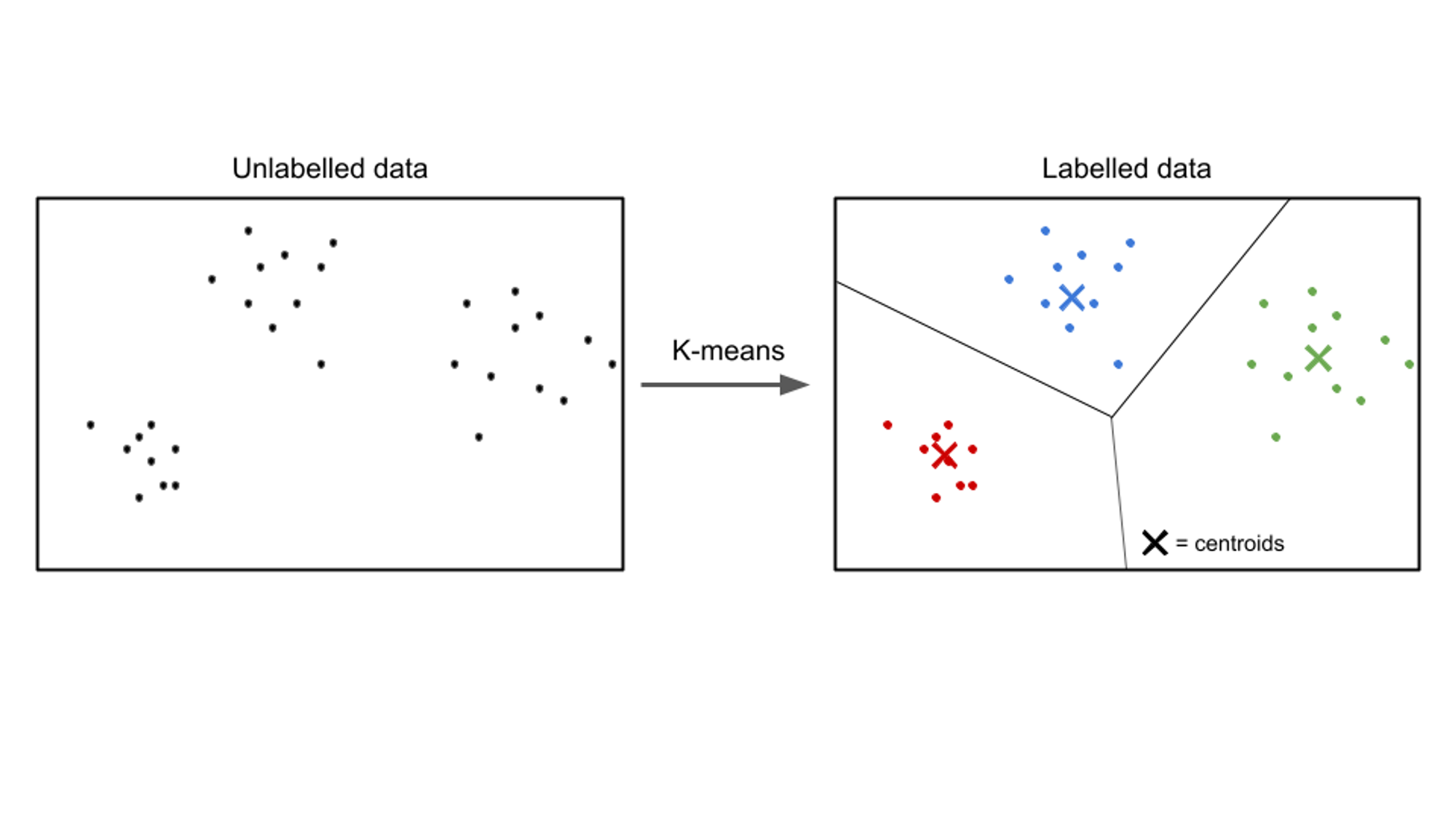
Un esempio di caso d'uso di apprendimento senza supervisione è la segmentazione dei clienti. In vari settori, le aziende mirano a comprendere meglio la loro base di clienti per adattare le loro strategie di marketing, personalizzare le loro offerte e ottimizzare le esperienze dei clienti. Gli algoritmi di apprendimento senza supervisione possono essere impiegati per segmentare i clienti in gruppi distinti in base alle loro caratteristiche e comportamenti condivisi.
Dai un'occhiata alla nostra guida pratica e pratica per l'apprendimento di Git, con le migliori pratiche, gli standard accettati dal settore e il cheat sheet incluso. Smetti di cercare su Google i comandi Git e in realtà imparare esso!
Applicando tecniche di apprendimento non supervisionato, come il clustering, le aziende possono scoprire modelli e gruppi significativi all'interno dei dati dei clienti. Ad esempio, gli algoritmi di clustering possono identificare gruppi di clienti con abitudini di acquisto, dati demografici o preferenze simili. Queste informazioni possono essere sfruttate per creare campagne di marketing mirate, ottimizzare i consigli sui prodotti e migliorare la soddisfazione del cliente.
Principali classi di algoritmi
Algoritmi di apprendimento supervisionato
-
Modelli lineari: utilizzati per prevedere variabili continue basate su relazioni lineari tra le caratteristiche e la variabile target.
-
Modelli basati su alberi: costruiti utilizzando una serie di decisioni binarie per fare previsioni o classificazioni.
-
Modelli di ensemble: metodo che combina più modelli (basati su alberi o lineari) per effettuare previsioni più accurate.
-
Modelli di rete neurale: metodi vagamente basati sul cervello umano, in cui più funzioni funzionano come nodi di una rete.
Algoritmi di apprendimento non supervisionati
-
Clustering gerarchico: crea una gerarchia di cluster unendoli o suddividendoli in modo iterativo.
-
Clustering non gerarchico: suddivide i dati in cluster distinti in base alla somiglianza.
-
Riduzione della dimensionalità: riduce la dimensionalità dei dati preservando le informazioni più importanti.
Valutazione del modello
Apprendimento supervisionato
Per valutare le prestazioni dei modelli di apprendimento supervisionato, vengono utilizzate varie metriche, tra cui accuratezza, precisione, richiamo, punteggio F1 e ROC-AUC. Le tecniche di convalida incrociata, come la convalida incrociata k-fold, possono aiutare a stimare le prestazioni di generalizzazione del modello.
Apprendimento senza supervisione
La valutazione degli algoritmi di apprendimento senza supervisione è spesso più impegnativa poiché non esiste una verità fondamentale. Metriche come il punteggio della silhouette o l'inerzia possono essere utilizzate per valutare la qualità dei risultati del clustering. Le tecniche di visualizzazione possono anche fornire informazioni sulla struttura dei cluster.
Tips and Tricks
Apprendimento supervisionato
- Preelabora e normalizza i dati di input per migliorare le prestazioni del modello.
- Gestire i valori mancanti in modo appropriato, tramite imputazione o rimozione.
- L'ingegnerizzazione delle funzionalità può migliorare la capacità del modello di acquisire modelli pertinenti.
Apprendimento senza supervisione
- Scegli il numero appropriato di cluster in base alla conoscenza del dominio o utilizzando tecniche come il metodo del gomito.
- Prendi in considerazione diverse metriche di distanza per misurare la somiglianza tra i punti dati.
- Regolarizzare il processo di clustering per evitare l'overfitting.
In sintesi, l'apprendimento automatico comporta numerosi compiti, tecniche, algoritmi, metodi di valutazione del modello e suggerimenti utili. Comprendendo questi aspetti, i professionisti possono applicare in modo efficiente l'apprendimento automatico ai problemi del mondo reale e ricavare informazioni significative dai dati. Gli esempi di codice forniti mostrano l'utilizzo di algoritmi di apprendimento supervisionati e non supervisionati, evidenziando la loro implementazione pratica.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- EVM Finance. Interfaccia unificata per la finanza decentralizzata. Accedi qui.
- Quantum Media Group. IR/PR amplificato. Accedi qui.
- PlatoAiStream. Intelligenza dei dati Web3. Conoscenza amplificata. Accedi qui.
- Fonte: https://stackabuse.com/supervised-learning-vs-unsupervised-learning-algorithms/