
Nella gestione patrimoniale, i gestori di portafoglio devono monitorare da vicino le società nel loro universo di investimento per identificare rischi e opportunità e guidare le decisioni di investimento. Monitorare eventi diretti come rapporti sugli utili o declassamenti del credito è semplice: puoi impostare avvisi per avvisare i manager di notizie contenenti nomi di aziende. Tuttavia, rilevare gli impatti di secondo e terzo ordine derivanti da eventi presso fornitori, clienti, partner o altre entità nell’ecosistema di un’azienda è impegnativo.
Ad esempio, un’interruzione della catena di fornitura presso un fornitore chiave avrebbe probabilmente un impatto negativo sui produttori a valle. Oppure la perdita di un cliente importante per un cliente importante rappresenta un rischio per la domanda per il fornitore. Molto spesso, tali eventi non riescono a fare notizia direttamente sull’azienda colpita, ma è comunque importante prestare attenzione. In questo post, mostriamo una soluzione automatizzata che combina grafici di conoscenza e intelligenza artificiale generativa (AI) per far emergere tali rischi incrociando le mappe delle relazioni con le notizie in tempo reale.
In generale, ciò comporta due passaggi: in primo luogo, costruire le complesse relazioni tra le aziende (clienti, fornitori, direttori) in un grafico della conoscenza. In secondo luogo, utilizzare questo database a grafo insieme all’intelligenza artificiale generativa per rilevare gli impatti di secondo e terzo ordine degli eventi di notizie. Ad esempio, questa soluzione può evidenziare che i ritardi presso un fornitore di componenti possono interrompere la produzione per i produttori automobilistici a valle in un portafoglio sebbene non venga fatto riferimento direttamente a nessuno.
Con AWS, puoi distribuire questa soluzione in un'architettura serverless, scalabile e completamente basata sugli eventi. Questo post dimostra una prova di concetto basata su due servizi AWS chiave adatti per la rappresentazione della conoscenza tramite grafici e l'elaborazione del linguaggio naturale: Amazon Nettuno ed Roccia Amazzonica. Neptune è un servizio di database a grafo veloce, affidabile e completamente gestito che semplifica la creazione e l'esecuzione di applicazioni che funzionano con set di dati altamente connessi. Amazon Bedrock è un servizio completamente gestito che offre una scelta di Foundation Model (FM) ad alte prestazioni di aziende leader nel settore dell'intelligenza artificiale come AI21 Labs, Anthropic, Cohere, Meta, Stability AI e Amazon attraverso un'unica API, insieme a un'ampia serie di funzionalità per creare applicazioni di intelligenza artificiale generativa con sicurezza, privacy e intelligenza artificiale responsabile.
Nel complesso, questo prototipo dimostra l'arte del possibile con i grafici della conoscenza e l'intelligenza artificiale generativa, che ricava segnali collegando punti disparati. Il vantaggio per i professionisti degli investimenti è la capacità di rimanere aggiornati sugli sviluppi più vicini al segnale evitando il rumore.
Costruisci il grafico della conoscenza
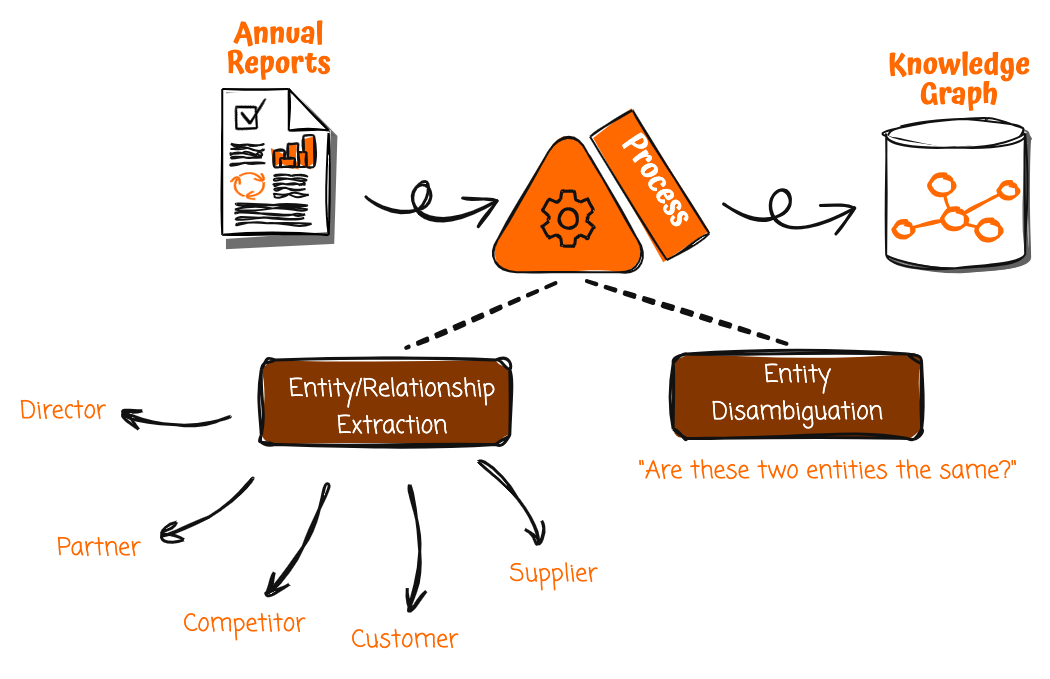
Il primo passo in questa soluzione è la creazione di un grafico della conoscenza e una fonte di dati preziosa ma spesso trascurata per i grafici della conoscenza sono i report annuali aziendali. Poiché le pubblicazioni aziendali ufficiali vengono sottoposte a controllo prima del rilascio, è probabile che le informazioni in esse contenute siano accurate e affidabili. Tuttavia, i rapporti annuali sono scritti in un formato non strutturato destinato alla lettura umana piuttosto che al consumo automatico. Per sbloccare il loro potenziale, è necessario un modo per estrarre e strutturare sistematicamente la ricchezza di fatti e relazioni che contengono.
Con servizi di intelligenza artificiale generativa come Amazon Bedrock, ora hai la possibilità di automatizzare questo processo. Puoi creare un report annuale e attivare una pipeline di elaborazione per acquisire il report, suddividerlo in parti più piccole e applicare la comprensione del linguaggio naturale per estrarre entità e relazioni salienti.
Ad esempio, una frase in cui si afferma che "[L'azienda A] ha ampliato la propria flotta europea di consegne elettriche con un ordine di 1,800 furgoni elettrici da [L'azienda B]" consentirebbe ad Amazon Bedrock di identificare quanto segue:
- [Azienda A] come cliente
- [Società B] come fornitore
- Una relazione di fornitore tra [Azienda A] e [Azienda B]
- Dettagli del rapporto di "fornitore di furgoni elettrici per la consegna"
Per estrarre tali dati strutturati da documenti non strutturati è necessario fornire suggerimenti attentamente elaborati a modelli linguistici di grandi dimensioni (LLM) in modo che possano analizzare il testo per estrarre entità come aziende e persone, nonché relazioni come clienti, fornitori e altro ancora. Le richieste contengono istruzioni chiare su cosa cercare e sulla struttura in cui restituire i dati. Ripetendo questo processo nell'intero report annuale, è possibile estrarre le entità e le relazioni rilevanti per costruire un ricco grafico della conoscenza.
Tuttavia, prima di inserire le informazioni estratte nel grafico della conoscenza, è necessario innanzitutto chiarire le ambiguità delle entità. Ad esempio, potrebbe già esserci un'altra entità "[Azienda A]" nel grafico della conoscenza, ma potrebbe rappresentare un'organizzazione diversa con lo stesso nome. Amazon Bedrock può ragionare e confrontare attributi quali area di interesse aziendale, settore e settori generatori di entrate e relazioni con altre entità per determinare se le due entità sono effettivamente distinte. Ciò impedisce la fusione imprecisa di società non collegate in un'unica entità.
Una volta completata la disambiguazione, puoi aggiungere in modo affidabile nuove entità e relazioni nel tuo grafico della conoscenza di Nettuno, arricchendolo con i fatti estratti dai rapporti annuali. Nel corso del tempo, l'acquisizione di dati affidabili e l'integrazione di origini dati più affidabili contribuiranno a creare un grafico della conoscenza completo in grado di supportare la rivelazione di approfondimenti attraverso query e analisi sui grafici.
Questa automazione resa possibile dall’intelligenza artificiale generativa rende possibile l’elaborazione di migliaia di report annuali e sblocca una risorsa inestimabile per la cura del knowledge graph che altrimenti rimarrebbe inutilizzata a causa dello sforzo manuale proibitivo necessario.
Lo screenshot seguente mostra un esempio dell'esplorazione visiva possibile in un database a grafo di Neptune utilizzando il file Esplora grafico strumento.

Elaborare articoli di notizie

Il passo successivo della soluzione è l'arricchimento automatico dei feed di notizie dei gestori di portafoglio e l'evidenziazione di articoli rilevanti per i loro interessi e investimenti. Per il feed di notizie, i gestori di portafoglio possono abbonarsi a qualsiasi fornitore di notizie di terze parti tramite Scambio di dati AWS o un'altra API di notizie di loro scelta.
Quando un articolo di notizie entra nel sistema, viene richiamata una pipeline di acquisizione per elaborare il contenuto. Utilizzando tecniche simili all'elaborazione dei report annuali, Amazon Bedrock viene utilizzato per estrarre entità, attributi e relazioni dall'articolo di notizie, che vengono poi utilizzati per chiarire le ambiguità rispetto al knowledge graph per identificare l'entità corrispondente nel knowledge graph.
Il grafico della conoscenza contiene connessioni tra aziende e persone e, collegando le entità articolo ai nodi esistenti, puoi identificare se qualche soggetto si trova a due passi dalle società in cui il gestore di portafoglio ha investito o in cui è interessato. Trovare tale connessione indica la L'articolo può essere rilevante per il gestore del portafoglio e, poiché i dati sottostanti sono rappresentati in un grafico della conoscenza, possono essere visualizzati per aiutare il gestore del portafoglio a capire perché e come questo contesto è rilevante. Oltre a identificare le connessioni al portafoglio, puoi anche utilizzare Amazon Bedrock per eseguire analisi del sentiment sulle entità a cui viene fatto riferimento.
Il risultato finale è un feed di notizie arricchito che presenta articoli che potrebbero avere un impatto sulle aree di interesse e sugli investimenti del gestore di portafoglio.
Panoramica della soluzione
L'architettura complessiva della soluzione è simile al diagramma seguente.

Il flusso di lavoro è costituito dai seguenti passaggi:
- Un utente carica i rapporti ufficiali (in formato PDF) su un file Servizio di archiviazione semplice Amazon (Amazon S3) secchio. I rapporti dovrebbero essere rapporti pubblicati ufficialmente per ridurre al minimo l'inclusione di dati imprecisi nel grafico della conoscenza (al contrario di notizie e tabloid).
- La notifica dell'evento S3 richiama un AWS Lambda funzione, che invia il bucket S3 e il nome del file a un file Servizio Amazon Simple Queue (Amazon SQS). La coda FIFO (First-In-First-Out) garantisce che il processo di inserimento del report venga eseguito in sequenza per ridurre la probabilità di introdurre dati duplicati nel grafico della conoscenza.
- An Amazon EventBridge l'evento basato sul tempo viene eseguito ogni minuto per avviare la corsa di un Funzioni AWS Step macchina statale in modo asincrono.
- La macchina a stati Step Functions esegue una serie di attività per elaborare il documento caricato estraendo le informazioni chiave e inserendole nel grafico della conoscenza:
- Ricevi il messaggio in coda da Amazon SQS.
- Scarica il file di report PDF da Amazon S3, dividilo in più parti di testo più piccole (circa 1,000 parole) per l'elaborazione e archivia le parti di testo in Amazon DynamoDB.
- Utilizza Claude v3 Sonnet di Anthropic su Amazon Bedrock per elaborare i primi blocchi di testo per determinare l'entità principale a cui si riferisce il report, insieme agli attributi rilevanti (come l'industria).
- Recupera i blocchi di testo da DynamoDB e per ogni blocco di testo, invoca una funzione Lambda per estrarre le entità (come un'azienda o una persona) e la sua relazione (cliente, fornitore, partner, concorrente o direttore) con l'entità principale utilizzando Amazon Bedrock .
- Consolida tutte le informazioni estratte.
- Filtra rumore ed entità irrilevanti (ad esempio, termini generici come "consumatori") utilizzando Amazon Bedrock.
- Utilizza Amazon Bedrock per risolvere le ambiguità ragionando utilizzando le informazioni estratte rispetto all'elenco di entità simili dal grafico della conoscenza. Se l'entità non esiste, inserirla. Altrimenti, utilizza l'entità già esistente nel grafico della conoscenza. Inserisci tutte le relazioni estratte.
- Eseguire la pulizia eliminando il messaggio della coda SQS e il file S3.
- Un utente accede a un'applicazione Web basata su React per visualizzare gli articoli di notizie integrati con le informazioni su entità, sentiment e percorso di connessione.
- Utilizzando l'applicazione web, l'utente specifica il numero di hop (default N=2) sul percorso di connessione da monitorare.
- Utilizzando l'applicazione web, l'utente specifica l'elenco delle entità da monitorare.
- Per generare notizie di fantasia, l'utente sceglie Genera notizie di esempio per generare 10 articoli di notizie finanziarie campione con contenuti casuali da inserire nel processo di inserimento delle notizie. Il contenuto viene generato utilizzando Amazon Bedrock ed è puramente fittizio.
- Per scaricare le notizie attuali, l'utente sceglie Scarica le ultime notizie per scaricare le principali notizie del giorno (con tecnologia NewsAPI.org).
- Il file delle notizie (formato TXT) viene caricato su un bucket S3. I passaggi 8 e 9 caricano automaticamente le notizie nel bucket S3, ma puoi anche creare integrazioni con il tuo fornitore di notizie preferito come AWS Data Exchange o qualsiasi fornitore di notizie di terze parti per inserire articoli di notizie come file nel bucket S3. Il contenuto del file di dati delle notizie deve essere formattato come
<date>{dd mmm yyyy}</date><title>{title}</title><text>{news content}</text>. - La notifica degli eventi S3 invia il bucket S3 o il nome del file ad Amazon SQS (standard), che richiama più funzioni Lambda per elaborare i dati delle notizie in parallelo:
- Utilizza Amazon Bedrock per estrarre le entità menzionate nelle notizie insieme a qualsiasi informazione, relazione e sentimento correlato dell'entità menzionata.
- Confrontalo con il grafico della conoscenza e utilizza Amazon Bedrock per risolvere le ambiguità ragionando utilizzando le informazioni disponibili nelle notizie e all'interno del grafico della conoscenza per identificare l'entità corrispondente.
- Dopo aver individuato l'entità, cercare e restituire eventuali percorsi di connessione che si connettono alle entità contrassegnate con
INTERESTED=YESnel grafico della conoscenza che si trovano entro N=2 salti di distanza.
- L'applicazione Web si aggiorna automaticamente ogni secondo per estrarre l'ultima serie di notizie elaborate da visualizzare sull'applicazione Web.
Distribuire il prototipo
Puoi distribuire la soluzione prototipo e iniziare a sperimentare tu stesso. Il prototipo è disponibile da GitHub e include dettagli su quanto segue:
- Prerequisiti per la distribuzione
- Fasi di distribuzione
- Passaggi di pulizia
Sommario
Questo post ha dimostrato una soluzione dimostrativa per aiutare i gestori di portafoglio a rilevare i rischi di secondo e terzo ordine derivanti da eventi di cronaca, senza riferimenti diretti alle società che monitorano. Combinando un grafico della conoscenza delle complesse relazioni aziendali con l’analisi delle notizie in tempo reale utilizzando l’intelligenza artificiale generativa, è possibile evidenziare gli impatti a valle, come i ritardi di produzione dovuti a intoppi dei fornitori.
Sebbene sia solo un prototipo, questa soluzione mostra la promessa di grafici della conoscenza e modelli linguistici per collegare punti e ricavare segnali dal rumore. Queste tecnologie possono aiutare i professionisti degli investimenti rivelando i rischi più rapidamente attraverso mappature e ragionamenti delle relazioni. Nel complesso, si tratta di un’applicazione promettente dei database grafici e dell’intelligenza artificiale che merita di essere esplorata per migliorare l’analisi degli investimenti e il processo decisionale.
Se questo esempio di intelligenza artificiale generativa nei servizi finanziari interessa alla tua azienda o hai un'idea simile, contatta il tuo account manager AWS e saremo lieti di approfondire l'analisi con te.
L'autore
 Xan Huang è un Senior Solutions Architect presso AWS e ha sede a Singapore. Collabora con i principali istituti finanziari per progettare e realizzare soluzioni sicure, scalabili e altamente disponibili nel cloud. Al di fuori del lavoro, Xan trascorre la maggior parte del suo tempo libero con la famiglia e viene comandato dalla figlia di 3 anni. Puoi trovare Xan su LinkedIn.
Xan Huang è un Senior Solutions Architect presso AWS e ha sede a Singapore. Collabora con i principali istituti finanziari per progettare e realizzare soluzioni sicure, scalabili e altamente disponibili nel cloud. Al di fuori del lavoro, Xan trascorre la maggior parte del suo tempo libero con la famiglia e viene comandato dalla figlia di 3 anni. Puoi trovare Xan su LinkedIn.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- PlatoData.Network Generativo verticale Ai. Potenzia te stesso. Accedi qui.
- PlatoAiStream. Intelligenza Web3. Conoscenza amplificata. Accedi qui.
- PlatoneESG. Carbonio, Tecnologia pulita, Energia, Ambiente, Solare, Gestione dei rifiuti. Accedi qui.
- Platone Salute. Intelligence sulle biotecnologie e sulle sperimentazioni cliniche. Accedi qui.
- Fonte: https://aws.amazon.com/blogs/machine-learning/uncover-hidden-connections-in-unstructured-financial-data-with-amazon-bedrock-and-amazon-neptune/