
אימון מודלים של שפה גדולה (LLMs) עם מיליארדי פרמטרים יכול להיות מאתגר. בנוסף לתכנון ארכיטקטורת המודל, החוקרים צריכים להגדיר טכניקות אימון מתקדמות לאימון מבוזר כמו תמיכה דיוק מעורבת, צבירת שיפועים ונקודות ביקורת. עם דגמים גדולים, מערך האימון מאתגר אפילו יותר מכיוון שהזיכרון הזמין בהתקן מאיץ יחיד מגביל את גודלם של דגמים שאומנו באמצעות מקביליות נתונים בלבד, ושימוש באימון מקביל למודל דורש רמה נוספת של שינויים בקוד האימון. ספריות כגון DeepSpeed (ספריית אופטימיזציה של למידה עמוקה בקוד פתוח עבור PyTorch) נותנת מענה לכמה מהאתגרים הללו, ויכולה לסייע בהאצת פיתוח והדרכה של מודלים.
בפוסט הזה, הגדרנו הדרכה על אינטל הבנה מבוסס גאודי ענן מחשוב אלסטי של אמזון (אמזון EC2) DL1 מופעים ולכמת את היתרונות של שימוש במסגרת קנה מידה כגון DeepSpeed. אנו מציגים תוצאות קנה מידה עבור מודל שנאי מסוג מקודד (BERT עם 340 מיליון עד 1.5 מיליארד פרמטרים). עבור המודל של 1.5 מיליארד פרמטרים, השגנו יעילות קנה מידה של 82.7% על פני 128 מאיצים (16 dl1.24xlarge מופעים) באמצעות DeepSpeed ZeRO אופטימיזציות שלב 1. מצבי האופטימיזציה חולקו על ידי DeepSpeed כדי לאמן מודלים גדולים באמצעות פרדיגמת הנתונים המקבילים. גישה זו הורחבה להכשרת מודל של 5 מיליארד פרמטרים באמצעות מקביליות נתונים. השתמשנו גם בתמיכה המקורית של גאודי בסוג הנתונים BF16 להפחתת נפח הזיכרון והגברת ביצועי האימון בהשוואה לשימוש בסוג הנתונים FP32. כתוצאה מכך, השגנו התכנסות מודל טרום אימון (שלב 1) תוך 16 שעות (היעד שלנו היה להכשיר מודל גדול תוך יום) עבור מודל BERT של 1.5 מיליארד פרמטרים באמצעות wikicorpus-en מערך נתונים.
הגדרת הדרכה
הקצאנו אשכול מחשוב מנוהל המורכב מ-16 מופעים dl1.24xlarge באמצעות אצווה AWS. פיתחנו א סדנת אצווה של AWS הממחיש את השלבים להגדרת אשכול ההדרכה המבוזר עם AWS Batch. לכל מופע dl1.24xlarge יש שמונה מאיצים של Habana Gaudi, כל אחד עם זיכרון של 32 GB ורשת RoCE מלאה בין כרטיסים ברוחב פס כולל דו-כיווני של 700 Gbps כל אחד (ראה Amazon EC2 DL1 מציג Deep Dive למידע נוסף). האשכול dl1.24xlarge השתמש גם בארבעה מתאמי בד אלסטי של AWS (EFA), עם חיבור בין צמתים בסך 400 Gbps.
סדנת ההדרכה המבוזרת ממחישה את השלבים להקמת אשכול ההכשרה המבוזרת. הסדנה מציגה את מערך ההדרכה המבוזר באמצעות AWS Batch ובמיוחד, תכונת המשרות המקבילות מרובות צמתים כדי להשיק עבודות הדרכה מכולות בקנה מידה גדול באשכולות מנוהלים במלואם. ליתר דיוק, סביבת מחשוב AWS Batch מנוהלת במלואה נוצרת עם מופעי DL1. המכולות נמשכות מהן מרשם מיכל אלסטי של אמזון (Amazon ECR) והושק אוטומטית למופעים באשכול בהתבסס על הגדרת העבודה המקבילה מרובת צמתים. הסדנה מסתיימת בהפעלת אימון מקביל לנתונים מרובים צמתים מרובים HPU של מודל BERT (340 מיליון עד 1.5 מיליארד פרמטרים) באמצעות PyTorch ו-DeepSpeed.
אימון קדם BERT 1.5B עם DeepSpeed
הבנה SynapseAI v1.5 ו v1.6 תומך באופטימיזציות של DeepSpeed ZeRO1. ה מזלג Habana של מאגר DeepSpeed GitHub כולל את השינויים הדרושים לתמיכה במאיצים של גאודי. יש תמיכה מלאה בנתונים מבוזרים במקביל (רב-כרטיסים, ריבוי מופעים), אופטימיזציות של ZeRO1 וסוגי נתונים BF16.
כל התכונות הללו מופעלות ב- מאגר התייחסות למודל BERT 1.5B, אשר מציגה מודל של 48 שכבות, 1600 ממד מוסתר ומודל מקודד דו-כיווני בעל 25 ראשים, הנגזר מימוש BERT. המאגר מכיל גם את היישום הבסיסי של מודל BERT Large: ארכיטקטורת רשת עצבית בעלת 24 שכבות, 1024 מוסתרות, 16 ראשים, של 340 מיליון פרמטרים. תסריטי הדוגמנות שלפני האימון נגזרים מה- מאגר דוגמאות למידה עמוקה של NVIDIA כדי להוריד את הנתונים של wikicorpus_en, עבדו מראש את הנתונים הגולמיים לאסימונים, ושפצו את הנתונים לתוך מערכי נתונים קטנים יותר של h5 לאימון מקביל של נתונים מבוזרים. אתה יכול לאמץ גישה גנרית זו כדי לאמן את ארכיטקטורות המודל המותאמות אישית של PyTorch באמצעות מערכי הנתונים שלך באמצעות מופעי DL1.
תוצאות קנה מידה לפני אימון (שלב 1).
להכשרה מוקדמת של דגמים גדולים בקנה מידה, התמקדנו בעיקר בשני היבטים של הפתרון: ביצועי האימון, כפי שנמדדו לפי זמן ההכשרה, והעלות-תועלת של הגעה לפתרון מתכנס לחלוטין. לאחר מכן, אנו צוללים עמוק יותר לתוך שני המדדים הללו עם אימון קדם BERT 1.5B כדוגמה.
קנה מידה של ביצועים וזמן לאימון
אנו מתחילים במדידת הביצועים של יישום BERT Large כקו בסיס להרחבה. הטבלה הבאה מפרטת את התפוקה הנמדדת של רצפים בשנייה ממופעים גדולים של 1-8 dl1.24xlarge (עם שמונה התקני מאיץ לכל מופע). באמצעות התפוקה של מופע בודד כבסיס, מדדנו את היעילות של קנה מידה על פני מספר מופעים, שהוא מנוף חשוב להבנת מדד ההדרכה של מחיר-ביצועים.
| מספר מופעים | מספר מאיצים | רצפים לשנייה | רצפים לשנייה לכל מאיץ | יעילות קנה מידה |
| 1 | 8 | 1,379.76 | 172.47 | 100.0% |
| 2 | 16 | 2,705.57 | 169.10 | 98.04% |
| 4 | 32 | 5,291.58 | 165.36 | 95.88% |
| 8 | 64 | 9,977.54 | 155.90 | 90.39% |
האיור הבא ממחיש את יעילות קנה המידה.

עבור BERT 1.5B, שינינו את הפרמטרים ההיפר-פרמטרים של המודל במאגר הייחוס כדי להבטיח התכנסות. גודל האצווה האפקטיבי לכל מאיץ נקבע ל-384 (לניצול מקסימלי של זיכרון), עם מיקרו-אצטות של 16 לכל שלב ו-24 שלבים של צבירת שיפוע. שיעורי למידה של 0.0015 ו-0.003 שימשו עבור 8 ו-16 צמתים, בהתאמה. עם תצורות אלה, השגנו התכנסות של אימון שלב 1 של BERT 1.5B על פני 8 מופעים dl1.24xlarge (64 מאיצים) תוך כ-25 שעות, ו-15 שעות על פני 16 dl1.24xlarge מופעים (128 מאיצים). האיור הבא מציג את ההפסד הממוצע כפונקציה של מספר תקופות האימון, כאשר אנו מגדילים את מספר המאיצים.

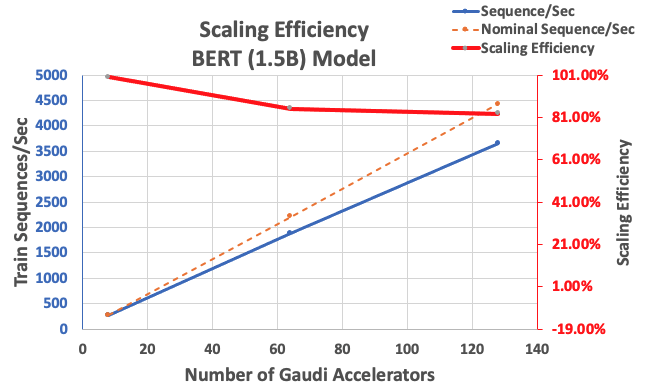
עם התצורה שתוארה קודם לכן, השגנו יעילות קנה מידה חזקה של 85% עם 64 מאיצים ו-83% עם 128 מאיצים, מקו הבסיס של 8 מאיצים במופע אחד. הטבלה הבאה מסכמת את הפרמטרים.
| מספר מופעים | מספר מאיצים | רצפים לשנייה | רצפים לשנייה לכל מאיץ | יעילות קנה מידה |
| 1 | 8 | 276.66 | 34.58 | 100.0% |
| 8 | 64 | 1,883.63 | 29.43 | 85.1% |
| 16 | 128 | 3,659.15 | 28.59 | 82.7% |
האיור הבא ממחיש את יעילות קנה המידה.
סיכום
בפוסט זה, הערכנו את התמיכה ב-DeepSpeed של Habana SynapseAI v1.5/v1.6 וכיצד זה עוזר להגדיל את אימון ה-LLM במאיצים של Habana Gaudi. אימון מקדים של דגם BERT של 1.5 מיליארד פרמטרים ארך 16 שעות כדי להתכנס למקבץ של 128 מאיצי גאודי, עם קנה מידה חזק של 85%. אנו ממליצים לך להסתכל על הארכיטקטורה המודגמת ב- סדנת AWS ושקול לאמץ אותו כדי להכשיר ארכיטקטורות מותאמות אישית של מודל PyTorch באמצעות מופעי DL1.
על המחברים
 מהדבן באלאסוברמניאם הוא ארכיטקט פתרונות עיקרי למחשוב אוטונומי עם כמעט 20 שנות ניסיון בתחום הלמידה העמוקה המושקעת בפיזיקה, בנייה ופריסה של תאומים דיגיטליים למערכות תעשייתיות בקנה מידה. Mahadevan השיג את הדוקטורט שלו בהנדסת מכונות מהמכון הטכנולוגי של מסצ'וסטס ולזכותו למעלה מ-25 פטנטים ופרסומים.
מהדבן באלאסוברמניאם הוא ארכיטקט פתרונות עיקרי למחשוב אוטונומי עם כמעט 20 שנות ניסיון בתחום הלמידה העמוקה המושקעת בפיזיקה, בנייה ופריסה של תאומים דיגיטליים למערכות תעשייתיות בקנה מידה. Mahadevan השיג את הדוקטורט שלו בהנדסת מכונות מהמכון הטכנולוגי של מסצ'וסטס ולזכותו למעלה מ-25 פטנטים ופרסומים.
 RJ הוא מהנדס בצוות Search M5 שמוביל את המאמצים לבניית מערכות למידה עמוקה בקנה מידה גדול לאימון והסקת הסקה. מחוץ לעבודה הוא חוקר מאכלים שונים של אוכל ועוסק בספורט מחבט.
RJ הוא מהנדס בצוות Search M5 שמוביל את המאמצים לבניית מערכות למידה עמוקה בקנה מידה גדול לאימון והסקת הסקה. מחוץ לעבודה הוא חוקר מאכלים שונים של אוכל ועוסק בספורט מחבט.
 סונדאר רנגנתן הוא ראש הפיתוח העסקי, ML Frameworks בצוות Amazon EC2. הוא מתמקד בעומסי עבודה בקנה מידה גדול של ML בשירותי AWS כמו Amazon EKS, Amazon ECS, Elastic Fabric Adapter, AWS Batch ו-Amazon SageMaker. הניסיון שלו כולל תפקידי מנהיגות בניהול מוצר ופיתוח מוצרים ב-NetApp, Micron Technology, Qualcomm ו-Mentor Graphics.
סונדאר רנגנתן הוא ראש הפיתוח העסקי, ML Frameworks בצוות Amazon EC2. הוא מתמקד בעומסי עבודה בקנה מידה גדול של ML בשירותי AWS כמו Amazon EKS, Amazon ECS, Elastic Fabric Adapter, AWS Batch ו-Amazon SageMaker. הניסיון שלו כולל תפקידי מנהיגות בניהול מוצר ופיתוח מוצרים ב-NetApp, Micron Technology, Qualcomm ו-Mentor Graphics.
 אבהיננדאן פאטני הוא מהנדס תוכנה בכיר ב-Amazon Search. הוא מתמקד בבניית מערכות וכלים לאימון למידה מבוזר ניתנת להרחבה והסקת מסקנות בזמן אמת.
אבהיננדאן פאטני הוא מהנדס תוכנה בכיר ב-Amazon Search. הוא מתמקד בבניית מערכות וכלים לאימון למידה מבוזר ניתנת להרחבה והסקת מסקנות בזמן אמת.
 פייר-איב אקווילנטי הוא ראש פתרונות Frameworks ML ב- Amazon Web Services, שם הוא עוזר לפתח את פתרונות ה-ML Frameworks המבוססים על ענן הטובים ביותר בתעשייה. הרקע שלו הוא ב-High Performance Computing ולפני שהצטרף ל-AWS, פייר-איב עבד בתעשיית הנפט והגז. פייר-איב הוא במקור מצרפת ובעל תואר Ph.D. במדעי המחשב מאוניברסיטת ליל.
פייר-איב אקווילנטי הוא ראש פתרונות Frameworks ML ב- Amazon Web Services, שם הוא עוזר לפתח את פתרונות ה-ML Frameworks המבוססים על ענן הטובים ביותר בתעשייה. הרקע שלו הוא ב-High Performance Computing ולפני שהצטרף ל-AWS, פייר-איב עבד בתעשיית הנפט והגז. פייר-איב הוא במקור מצרפת ובעל תואר Ph.D. במדעי המחשב מאוניברסיטת ליל.
- הפצת תוכן ויחסי ציבור מופעל על ידי SEO. קבל הגברה היום.
- EVM Finance. ממשק מאוחד למימון מבוזר. גישה כאן.
- Quantum Media Group. IR/PR מוגבר. גישה כאן.
- PlatoAiStream. Web3 Data Intelligence. הידע מוגבר. גישה כאן.
- מקור: https://aws.amazon.com/blogs/machine-learning/accelerate-pytorch-with-deepspeed-to-train-large-language-models-with-intel-habana-gaudi-based-dl1-ec2-instances/