
מבוא
Machine Learning (ML) הוא תחום מחקר המתמקד בפיתוח אלגוריתמים ללמידה אוטומטית מנתונים, ביצוע תחזיות והסקת דפוסים מבלי שיאמרו לו במפורש כיצד לעשות זאת. המטרה היא ליצור מערכות המשתפרות אוטומטית עם ניסיון ונתונים.
ניתן להשיג זאת באמצעות למידה מפוקחת, שבה המודל מאומן באמצעות נתונים מסומנים לביצוע תחזיות, או באמצעות למידה ללא פיקוח, כאשר המודל מבקש לחשוף דפוסים או מתאמים בתוך הנתונים ללא תפוקות יעד ספציפיות שניתן לצפות מראש.
ML התגלה ככלי הכרחי ושימוש נרחב על פני דיסציפלינות שונות, כולל מדעי המחשב, ביולוגיה, פיננסים ושיווק. זה הוכיח את השימושיות שלו ביישומים מגוונים כגון סיווג תמונות, עיבוד שפה טבעית וזיהוי הונאה.
משימות למידת מכונה
למידת מכונה ניתן לסווג באופן רחב לשלוש משימות עיקריות:
- למידה בפיקוח
- למידה ללא פיקוח
- לימוד עם חיזוקים
כאן נתמקד בשני המקרים הראשונים.
למידה מפוקחת
למידה מפוקחת כרוכה באימון מודל על נתונים מסומנים, כאשר נתוני הקלט משויכים למשתנה הפלט או היעד המקביל. המטרה היא ללמוד פונקציה שיכולה למפות נתוני קלט לפלט הנכון. אלגוריתמי למידה מפוקחים נפוצים כוללים רגרסיה לינארית, רגרסיה לוגיסטית, עצי החלטה ומכונות וקטור תמיכה.
דוגמה לקוד למידה בפיקוח באמצעות Python:
from sklearn.linear_model import LinearRegression model = LinearRegression() model.fit(X_train, y_train) predictions = model.predict(X_test)
בדוגמא הקוד הפשוטה הזו, אנו מאמנים את LinearRegression אלגוריתם מ-skit-learn על נתוני האימון שלנו, ולאחר מכן יישם אותו כדי לקבל תחזיות עבור נתוני המבחן שלנו.
מקרה אחד של שימוש בעולם האמיתי של למידה בפיקוח הוא סיווג דואר זבל. עם הצמיחה האקספוננציאלית של תקשורת דוא"ל, זיהוי וסינון דואר זבל הפך להיות חיוני. על ידי שימוש באלגוריתמי למידה מפוקחים, ניתן לאמן מודל להבחין בין אימיילים לגיטימיים לספאם על סמך נתונים מסומנים.
ניתן לאמן את מודל הלמידה המפוקחת על מערך נתונים המכיל הודעות דוא"ל המסומנות כ"ספאם" או "לא דואר זבל". המודל לומד דפוסים ותכונות מהנתונים המסומנים, כגון נוכחות של מילות מפתח מסוימות, מבנה דוא"ל או מידע של שולח הדוא"ל. לאחר הכשרה של המודל, ניתן להשתמש בו כדי לסווג אוטומטית הודעות דוא"ל נכנסות כדואר זבל או לא כספאם, ולסנן ביעילות הודעות לא רצויות.
למידה ללא פיקוח
בלמידה לא מפוקחת, נתוני הקלט אינם מסומנים, והמטרה היא לגלות דפוסים או מבנים בתוך הנתונים. אלגוריתמי למידה ללא פיקוח מטרתם למצוא ייצוגים או אשכולות משמעותיים בנתונים.
דוגמאות של אלגוריתמי למידה ללא פיקוח כוללות k- פירושו אשכולות, אשכול היררכי, ו ניתוח רכיבים עיקריים (PCA).
דוגמה לקוד למידה ללא פיקוח:
from sklearn.cluster import KMeans model = KMeans(n_clusters=3) model.fit(X) predictions = model.predict(X_new)
בדוגמא הקוד הפשוטה הזו, אנו מאמנים את KMeans אלגוריתם מ-skit-learn לזהות שלושה אשכולות בנתונים שלנו ואז להתאים נתונים חדשים לאותם אשכולות.
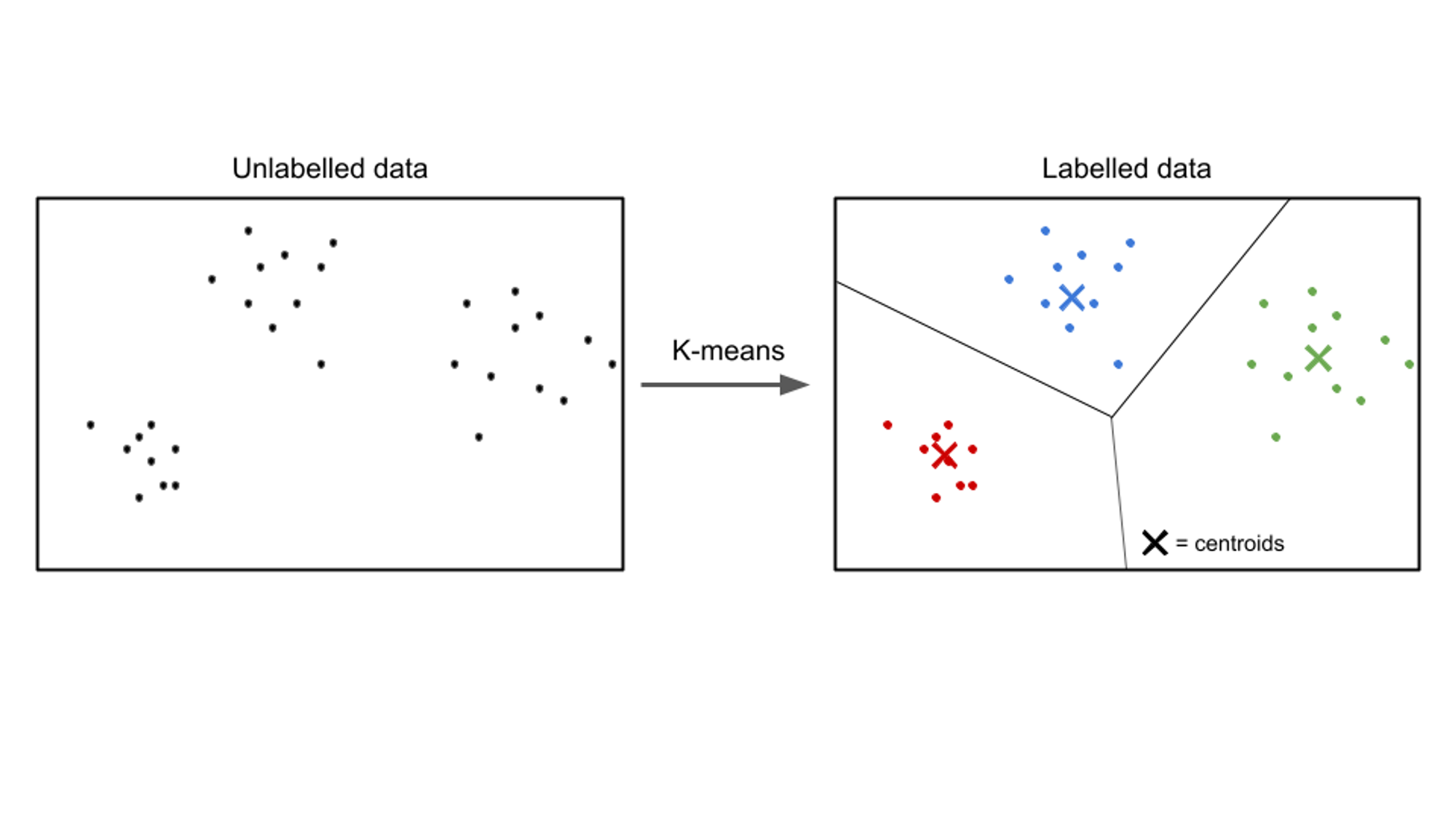
דוגמה למקרה שימוש בלמידה ללא פיקוח היא פילוח לקוחות. בתעשיות שונות, עסקים שואפים להבין טוב יותר את בסיס הלקוחות שלהם כדי להתאים את אסטרטגיות השיווק שלהם, להתאים אישית את ההצעות שלהם ולמטב את חוויות הלקוחות. ניתן להשתמש באלגוריתמי למידה ללא פיקוח כדי לפלח לקוחות לקבוצות נפרדות על סמך המאפיינים וההתנהגויות המשותפים שלהם.
עיין במדריך המעשי והמעשי שלנו ללימוד Git, עם שיטות עבודה מומלצות, סטנדרטים מקובלים בתעשייה ודף רמאות כלול. תפסיק לגוגל פקודות Git ולמעשה ללמוד זה!
על ידי יישום טכניקות למידה ללא פיקוח, כגון אשכולות, עסקים יכולים לחשוף דפוסים וקבוצות משמעותיות בתוך נתוני הלקוחות שלהם. לדוגמה, אלגוריתמי מקבץ יכולים לזהות קבוצות של לקוחות עם הרגלי רכישה, נתונים דמוגרפיים או העדפות דומות. ניתן למנף מידע זה ליצירת קמפיינים שיווקיים ממוקדים, אופטימיזציה של המלצות מוצרים ושיפור שביעות רצון הלקוחות.
שיעורי אלגוריתמים עיקריים
אלגוריתמי למידה מפוקחים
-
מודלים ליניאריים: משמשים לחיזוי משתנים רציפים בהתבסס על קשרים ליניאריים בין תכונות למשתנה היעד.
-
מודלים מבוססי עץ: נבנו באמצעות סדרה של החלטות בינאריות לביצוע תחזיות או סיווגים.
-
אנסמבל מודלים: שיטה המשלבת מודלים מרובים (מבוסס עצים או ליניאריים) כדי ליצור חיזויים מדויקים יותר.
-
מודלים של רשתות עצביות: שיטות המבוססות באופן רופף על המוח האנושי, כאשר פונקציות מרובות פועלות כצמתים של רשת.
אלגוריתמי למידה ללא פיקוח
-
אשכול היררכי: בונה היררכיה של אשכולות על ידי מיזוג או פיצול איטרטיבי שלהם.
-
אשכול לא היררכי: מחלק נתונים לאשכולות נפרדים על סמך דמיון.
-
הפחתת מימדיות: מפחיתה את הממדיות של הנתונים תוך שמירה על המידע החשוב ביותר.
הערכת מודל
למידה מפוקחת
כדי להעריך את הביצועים של מודלים של למידה בפיקוח, נעשה שימוש במדדים שונים, כולל דיוק, דיוק, זכירה, ציון F1 ו-ROC-AUC. טכניקות אימות צולב, כגון אימות צולב פי קפל, יכולות לעזור להעריך את ביצועי ההכללה של המודל.
למידה ללא פיקוח
הערכת אלגוריתמי למידה ללא פיקוח היא לרוב מאתגרת יותר מכיוון שאין אמת בסיסית. ניתן להשתמש במדדים כגון ציון צללית או אינרציה כדי להעריך את האיכות של תוצאות מקבץ. טכניקות ויזואליזציה יכולות גם לספק תובנות לגבי המבנה של אשכולות.
טיפים וטריקים
למידה מפוקחת
- עבד מראש ונרמל נתוני קלט כדי לשפר את ביצועי המודל.
- טפל כראוי בערכים חסרים, על ידי זקיפה או הסרה.
- הנדסת תכונות יכולה לשפר את יכולתו של הדגם ללכוד דפוסים רלוונטיים.
למידה ללא פיקוח
- בחר את המספר המתאים של אשכולות בהתבסס על ידע בתחום או באמצעות טכניקות כמו שיטת המרפק.
- שקול מדדי מרחק שונים כדי למדוד דמיון בין נקודות נתונים.
- סדיר את תהליך הקיבוץ כדי למנוע התאמת יתר.
לסיכום, למידת מכונה כוללת מספר רב של משימות, טכניקות, אלגוריתמים, שיטות הערכת מודלים ורמזים מועילים. על ידי הבנת ההיבטים הללו, מתרגלים יכולים ליישם ביעילות למידת מכונה על בעיות בעולם האמיתי ולהפיק תובנות משמעותיות מנתונים. דוגמאות הקוד הנתונות מציגות את השימוש באלגוריתמי למידה מפוקחים ובלתי מפוקחים, תוך הדגשת היישום המעשי שלהם.
- הפצת תוכן ויחסי ציבור מופעל על ידי SEO. קבל הגברה היום.
- EVM Finance. ממשק מאוחד למימון מבוזר. גישה כאן.
- Quantum Media Group. IR/PR מוגבר. גישה כאן.
- PlatoAiStream. Web3 Data Intelligence. הידע מוגבר. גישה כאן.
- מקור: https://stackabuse.com/supervised-learning-vs-unsupervised-learning-algorithms/