
編集者による画像
私たちは毎週、大規模言語モデル (LLM) が吐き出され、使用できるチャットボットがますます増えているのを目にしてきました。 ただし、どれが最適なのか、それぞれの進捗状況、どれが最も役立つのかを判断するのは難しい場合があります。
抱き合う顔 には、リリースされる LLM を追跡、評価、ランク付けする Open LLM Leaderboard があります。 彼らは、さまざまな評価タスクで生成言語モデルをテストするために使用される独自のフレームワークを使用します。
最近では、LLaMA (Large Language Model Meta AI) がリーダーボードのトップにありましたが、最近、新しい事前トレーニングされた LLM – Falcon 40B にその座を奪われています。
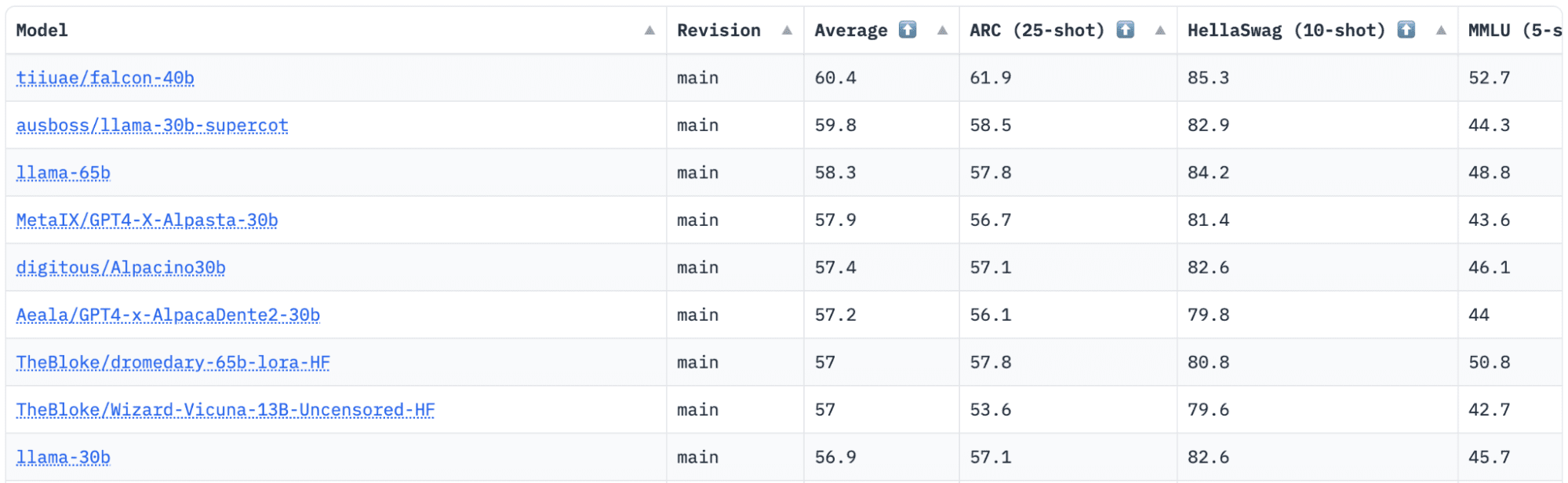
による画像 HuggingFace オープン LLM リーダーボード
ファルコンLLM によって設立され、建設されました。 技術革新研究所 (TII) は、アブダビ政府の先端技術研究評議会の一員である企業です。 政府はアラブ首長国連邦全土の技術研究を監督しており、科学者、研究者、エンジニアのチームが革新的な技術や科学の発見を提供することに重点を置いています。
ファルコン-40B は 40B のパラメータを備えた基本的な LLM で、40 兆のトークンでトレーニングされます。 Falcon XNUMXB は自己回帰デコーダ専用モデルです。 自己回帰デコーダ専用モデルとは、前のトークンが与えられたシーケンス内の次のトークンを予測するようにモデルがトレーニングされていることを意味します。 GPT モデルはその良い例です。
Falcon のアーキテクチャは、トレーニング コンピューティング予算のわずか 3% で GPT-75 を大幅に上回っており、必要なのは ? のみであることが示されています。 推論時の計算の。
LLM はトレーニング データの品質に非常に敏感であることがわかっているため、Technology Innovation Institute のチームは大規模なデータ品質に重点を置いています。 チームは高速処理のために数万の CPU コアにスケールするデータ パイプラインを構築し、広範なフィルタリングと重複排除を使用して Web から高品質のコンテンツを抽出することができました。
別の小さいバージョンもあります。 ファルコン-7B これには 7 億のパラメータがあり、1,500 億のトークンでトレーニングされています。 同様に Falcon-40B-命令, Falcon-7B-命令 すぐに使用できるチャット モデルをお探しの場合は、さまざまなモデルが利用可能です。
ファルコン 40B では何ができるのでしょうか?
他の LLM と同様に、Falcon 40B は次のことができます。
- クリエイティブなコンテンツを生成する
- 複雑な問題を解決する
- カスタマーサービス業務
- 仮想アシスタント
- 言語変換
- 感情分析。
- 「繰り返しの」作業を削減し、自動化します。
- エミレーツ企業の効率化を支援
Falcon 40B はどのように訓練されましたか?
1 兆のトークンでトレーニングされるため、384 か月にわたって AWS 上に 1,000 個の GPU が必要でした。 XNUMXB トークンでトレーニング済み 洗練されたウェブ、TII によって構築された大規模な英語の Web データセット。
事前トレーニング データは、Web からの公開データのコレクションで構成されています。 コモンクロール。 チームは徹底的なフィルタリング フェーズを経て、機械生成テキスト、アダルト コンテンツ、および重複排除を除去して、XNUMX 兆近くのトークンの事前トレーニング データセットを作成しました。
CommonCrawl 上に構築された RefinedWeb データセットは、厳選されたデータセットでトレーニングされたモデルよりも優れたパフォーマンスを達成するモデルを示しています。 RefinedWeb はマルチモーダルにも対応しています。
準備が完了すると、Falcon は EAI Harness、HELM、BigBench などのオープンソース ベンチマークに対して検証されました。
彼らが持っている オープンソースの Falcon LLM Falcon 40B および 7B は、Apache License Version 2.0 リリースに基づいているため、研究者や開発者にとってよりアクセスしやすくなりました。
LLM は、かつては研究および商用利用のみを目的としていたが、AI への包括的なアクセスを求める世界的な需要に応えるために、現在はオープンソースとなっている。 UAE は AI 内の課題と境界を変え、AI が将来どのように重要な役割を果たすかに注力しているため、現在は商用利用制限によるロイヤルティが免除されています。
AI の世界でコラボレーション、イノベーション、知識共有のエコシステムを育成することを目的とした Apache 2.0 は、セキュリティと安全なオープンソース ソフトウェアを保証します。
チャットボットのスタイルで一般的な命令に適した、よりシンプルなバージョンの Falcon-40B を試したい場合は、Falcon-7B を使用することをお勧めします。
それでは始めましょう…
まだインストールしていない場合は、次のパッケージをインストールします。
!pip install transformers
!pip install einops
!pip install accelerate
!pip install xformers
これらのパッケージをインストールしたら、提供されているコードの実行に進むことができます。 ファルコン 7-B 指示:
from transformers import AutoTokenizer, AutoModelForCausalLM
import transformers
import torch model = "tiiuae/falcon-7b-instruct" tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline( "text-generation", model=model, tokenizer=tokenizer, torch_dtype=torch.bfloat16, trust_remote_code=True, device_map="auto",
)
sequences = pipeline( "Girafatron is obsessed with giraffes, the most glorious animal on the face of this Earth. Giraftron believes all other animals are irrelevant when compared to the glorious majesty of the giraffe.nDaniel: Hello, Girafatron!nGirafatron:", max_length=200, do_sample=True, top_k=10, num_return_sequences=1, eos_token_id=tokenizer.eos_token_id,
)
for seq in sequences: print(f"Result: {seq['generated_text']}")
Falcon は、利用可能な最高のオープンソース モデルとして LLaMA の栄冠を獲得しました。人々は、その強力に最適化されたアーキテクチャ、独自のライセンスを持つオープンソース、および 40B と 7B パラメータの XNUMX つのサイズで利用できることに驚きました。
試してみたことがありますか? もしそうなら、コメントであなたの意見を教えてください。
ニシャ・アリア KDnuggets のデータ サイエンティスト、フリーランス テクニカル ライター、およびコミュニティ マネージャーです。 彼女は特に、データ サイエンスに関するキャリア アドバイスやチュートリアル、およびデータ サイエンスに関する理論に基づく知識を提供することに関心を持っています。 彼女はまた、人工知能が人間の寿命を延ばすためのさまざまな方法を探求したいと考えています。 熱心な学習者であり、他の人を導く手助けをしながら、技術知識とライティング スキルを広げようとしています。
Falcon LLM: オープンソース LLM の新たな王様 – KDnuggets
プラトン再発行
編集者による画像
私たちは毎週、大規模言語モデル (LLM) が吐き出され、使用できるチャットボットがますます増えているのを目にしてきました。 ただし、どれが最適なのか、それぞれの進捗状況、どれが最も役立つのかを判断するのは難しい場合があります。
抱き合う顔 には、リリースされる LLM を追跡、評価、ランク付けする Open LLM Leaderboard があります。 彼らは、さまざまな評価タスクで生成言語モデルをテストするために使用される独自のフレームワークを使用します。
最近では、LLaMA (Large Language Model Meta AI) がリーダーボードのトップにありましたが、最近、新しい事前トレーニングされた LLM – Falcon 40B にその座を奪われています。
による画像 HuggingFace オープン LLM リーダーボード
ファルコンLLM によって設立され、建設されました。 技術革新研究所 (TII) は、アブダビ政府の先端技術研究評議会の一員である企業です。 政府はアラブ首長国連邦全土の技術研究を監督しており、科学者、研究者、エンジニアのチームが革新的な技術や科学の発見を提供することに重点を置いています。
ファルコン-40B は 40B のパラメータを備えた基本的な LLM で、40 兆のトークンでトレーニングされます。 Falcon XNUMXB は自己回帰デコーダ専用モデルです。 自己回帰デコーダ専用モデルとは、前のトークンが与えられたシーケンス内の次のトークンを予測するようにモデルがトレーニングされていることを意味します。 GPT モデルはその良い例です。
Falcon のアーキテクチャは、トレーニング コンピューティング予算のわずか 3% で GPT-75 を大幅に上回っており、必要なのは ? のみであることが示されています。 推論時の計算の。
LLM はトレーニング データの品質に非常に敏感であることがわかっているため、Technology Innovation Institute のチームは大規模なデータ品質に重点を置いています。 チームは高速処理のために数万の CPU コアにスケールするデータ パイプラインを構築し、広範なフィルタリングと重複排除を使用して Web から高品質のコンテンツを抽出することができました。
別の小さいバージョンもあります。 ファルコン-7B これには 7 億のパラメータがあり、1,500 億のトークンでトレーニングされています。 同様に Falcon-40B-命令, Falcon-7B-命令 すぐに使用できるチャット モデルをお探しの場合は、さまざまなモデルが利用可能です。
ファルコン 40B では何ができるのでしょうか?
他の LLM と同様に、Falcon 40B は次のことができます。
Falcon 40B はどのように訓練されましたか?
1 兆のトークンでトレーニングされるため、384 か月にわたって AWS 上に 1,000 個の GPU が必要でした。 XNUMXB トークンでトレーニング済み 洗練されたウェブ、TII によって構築された大規模な英語の Web データセット。
事前トレーニング データは、Web からの公開データのコレクションで構成されています。 コモンクロール。 チームは徹底的なフィルタリング フェーズを経て、機械生成テキスト、アダルト コンテンツ、および重複排除を除去して、XNUMX 兆近くのトークンの事前トレーニング データセットを作成しました。
CommonCrawl 上に構築された RefinedWeb データセットは、厳選されたデータセットでトレーニングされたモデルよりも優れたパフォーマンスを達成するモデルを示しています。 RefinedWeb はマルチモーダルにも対応しています。
準備が完了すると、Falcon は EAI Harness、HELM、BigBench などのオープンソース ベンチマークに対して検証されました。
彼らが持っている オープンソースの Falcon LLM Falcon 40B および 7B は、Apache License Version 2.0 リリースに基づいているため、研究者や開発者にとってよりアクセスしやすくなりました。
LLM は、かつては研究および商用利用のみを目的としていたが、AI への包括的なアクセスを求める世界的な需要に応えるために、現在はオープンソースとなっている。 UAE は AI 内の課題と境界を変え、AI が将来どのように重要な役割を果たすかに注力しているため、現在は商用利用制限によるロイヤルティが免除されています。
AI の世界でコラボレーション、イノベーション、知識共有のエコシステムを育成することを目的とした Apache 2.0 は、セキュリティと安全なオープンソース ソフトウェアを保証します。
チャットボットのスタイルで一般的な命令に適した、よりシンプルなバージョンの Falcon-40B を試したい場合は、Falcon-7B を使用することをお勧めします。
それでは始めましょう…
まだインストールしていない場合は、次のパッケージをインストールします。
これらのパッケージをインストールしたら、提供されているコードの実行に進むことができます。 ファルコン 7-B 指示:
Falcon は、利用可能な最高のオープンソース モデルとして LLaMA の栄冠を獲得しました。人々は、その強力に最適化されたアーキテクチャ、独自のライセンスを持つオープンソース、および 40B と 7B パラメータの XNUMX つのサイズで利用できることに驚きました。
試してみたことがありますか? もしそうなら、コメントであなたの意見を教えてください。
ニシャ・アリア KDnuggets のデータ サイエンティスト、フリーランス テクニカル ライター、およびコミュニティ マネージャーです。 彼女は特に、データ サイエンスに関するキャリア アドバイスやチュートリアル、およびデータ サイエンスに関する理論に基づく知識を提供することに関心を持っています。 彼女はまた、人工知能が人間の寿命を延ばすためのさまざまな方法を探求したいと考えています。 熱心な学習者であり、他の人を導く手助けをしながら、技術知識とライティング スキルを広げようとしています。
このトピックの詳細
ランド・ノリスがハミルトンからF1中国GPのスプリントポールを奪取 – Autoblog
仮想通貨トレーダー、マンゴー市場搾取110億XNUMX万ドル詐欺罪で有罪判決 – CryptoInfoNet
ビットコインのパイオニア、ハル・フィニー氏の死後、自身の名を冠した新たな賞を受賞
信頼と進歩を継承する大手仮想通貨取引所Bitalplus
トップの仮想通貨取引所バイナンスが1,000,000,000億ドルの安全資産ファンドをビットコインとBNBからステーブルコインUSDCに変換 – The Daily Hodl
BitwiseのCIOは、市場は半減期後のビットコインの将来の需要を織り込んでいないと考えている
ETHが370ドルを回収し、イーサリアムネットワークは第1四半期に3億XNUMX万ドルの利益を生み出した
最初のビットコイン ルーンの 1 つを鋳造する競争が始まります – 復号化
仮想通貨市場トップ上昇企業の中でレールガン: RAIL が 53% 上昇しているのはなぜですか?