
概要
機械学習 (ML) は、データから自動的に学習し、その方法を明示的に指示されずに予測やパターンの推論を行うアルゴリズムの開発に焦点を当てた研究分野です。 経験とデータによって自動的に改善されるシステムを作成することを目指しています。
これは、ラベル付きデータを使用してモデルをトレーニングして予測を行う教師あり学習、または予測する特定のターゲット出力を持たずにモデルがデータ内のパターンや相関関係を明らかにしようとする教師なし学習を通じて実現できます。
ML は、コンピューター サイエンス、生物学、金融、マーケティングなど、さまざまな分野で不可欠なツールとして広く使用されています。 画像分類、自然言語処理、不正行為検出などのさまざまなアプリケーションでその有用性が証明されています。
機械学習タスク
機械学習は、大きく次の XNUMX つの主要なタスクに分類できます。
- 教師あり学習
- 教師なし学習
- 強化学習
ここでは、最初の XNUMX つのケースに焦点を当てます。
教師あり学習
教師あり学習には、ラベル付きデータでモデルをトレーニングすることが含まれます。入力データは、対応する出力変数またはターゲット変数とペアになります。 目標は、入力データを正しい出力にマッピングできる関数を学習することです。 一般的な教師あり学習アルゴリズムには、線形回帰、ロジスティック回帰、デシジョン ツリー、サポート ベクター マシンなどがあります。
Python を使用した教師あり学習コードの例:
from sklearn.linear_model import LinearRegression model = LinearRegression() model.fit(X_train, y_train) predictions = model.predict(X_test)
この簡単なコード例では、 LinearRegression scikit-learn のアルゴリズムをトレーニング データに適用し、それを適用してテスト データの予測を取得します。
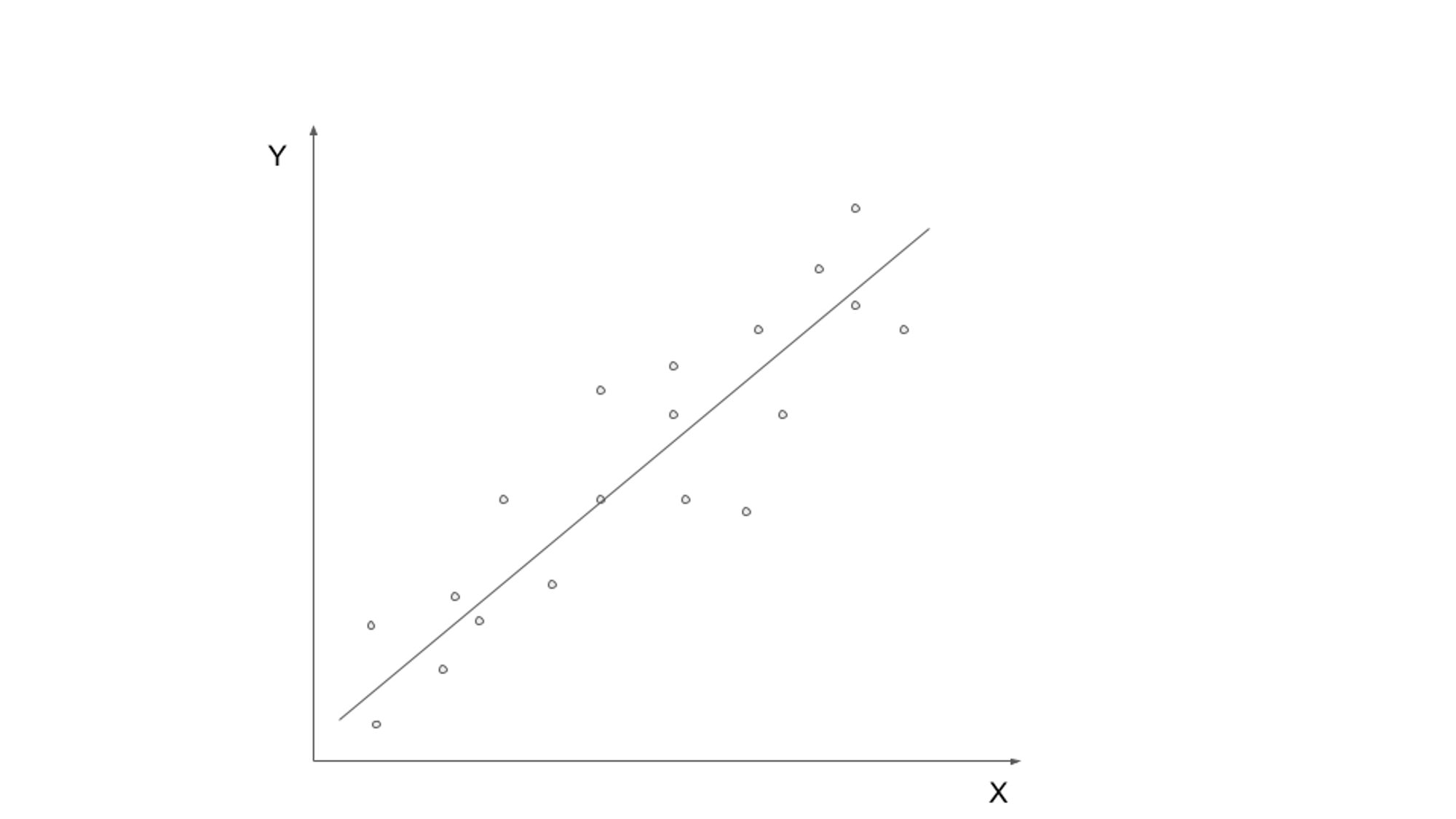
教師あり学習の実際の使用例の XNUMX つは、電子メールのスパム分類です。 電子メール通信の急激な増加に伴い、スパム電子メールの識別とフィルタリングが重要になってきています。 教師あり学習アルゴリズムを利用すると、ラベル付きデータに基づいて正規の電子メールとスパムを区別するモデルをトレーニングできます。
教師あり学習モデルは、「スパム」または「スパムではない」とラベル付けされた電子メールを含むデータセットでトレーニングできます。 モデルは、特定のキーワードの存在、電子メールの構造、電子メール送信者情報など、ラベル付きデータからパターンと特徴を学習します。 モデルがトレーニングされると、受信メールをスパムまたは非スパムとして自動的に分類し、不要なメッセージを効率的にフィルタリングするために使用できます。
教師なし学習
教師なし学習では、入力データにラベルが付けられておらず、目標はデータ内のパターンや構造を発見することです。 教師なし学習アルゴリズムは、データ内で意味のある表現またはクラスターを見つけることを目的としています。
教師なし学習アルゴリズムの例には次のものがあります。 k-クラスタリングを意味します, 階層的クラスタリング, 主成分分析 (PCA).
教師なし学習コードの例:
from sklearn.cluster import KMeans model = KMeans(n_clusters=3) model.fit(X) predictions = model.predict(X_new)
この簡単なコード例では、 KMeans scikit-learn のアルゴリズムを使用して、データ内の XNUMX つのクラスターを特定し、新しいデータをそれらのクラスターに適合させます。
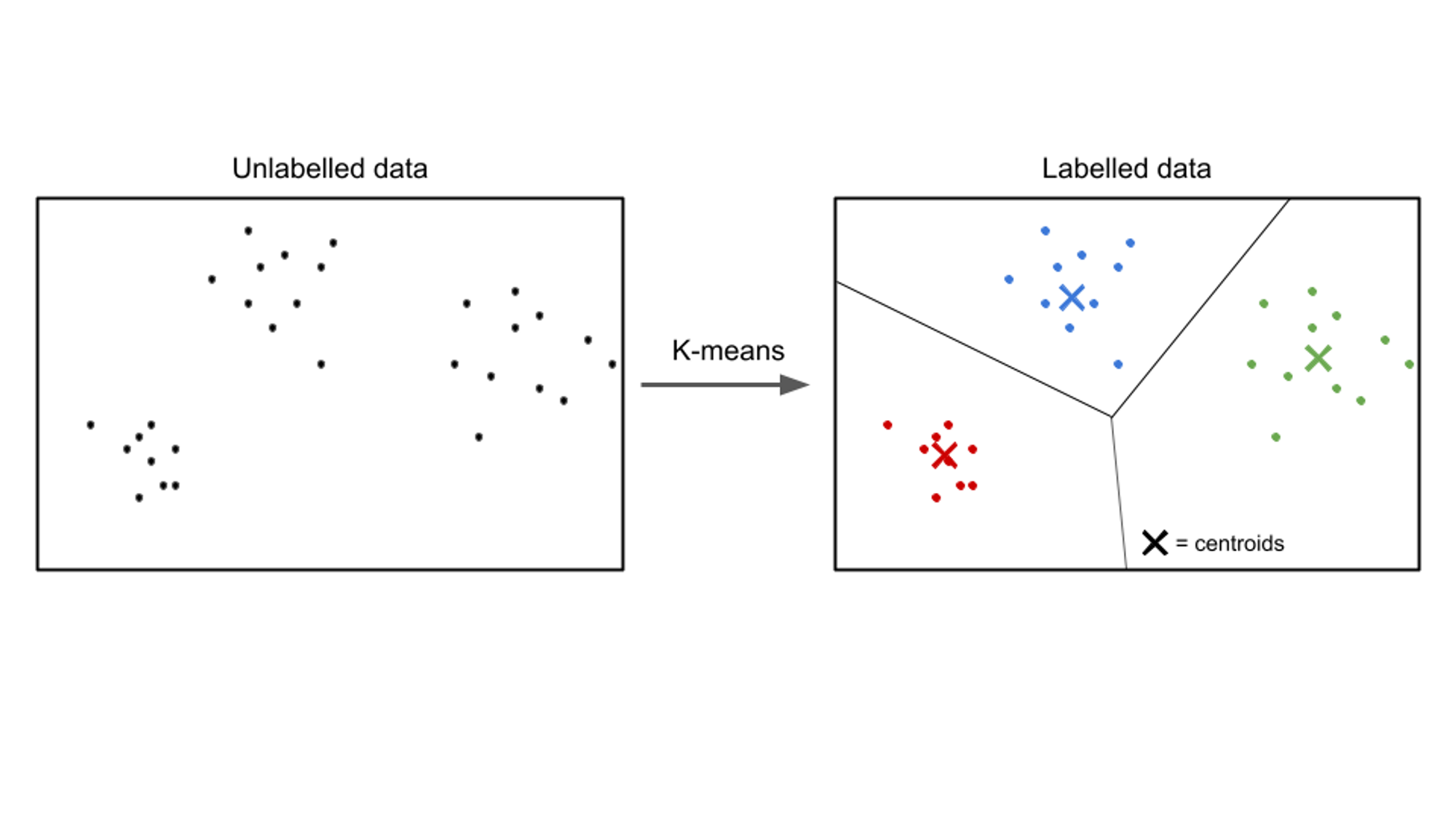
教師なし学習のユースケースの例は、顧客のセグメンテーションです。 さまざまな業界で、企業は顧客ベースをより深く理解し、マーケティング戦略を調整し、提供するサービスをパーソナライズし、顧客エクスペリエンスを最適化することを目指しています。 教師なし学習アルゴリズムを使用すると、顧客を共通の特性や行動に基づいて異なるグループに分類できます。
ベストプラクティス、業界で認められた標準、および含まれているチートシートを含む、Gitを学習するための実践的で実用的なガイドを確認してください。 グーグルGitコマンドを停止し、実際に 学ぶ それ!
クラスタリングなどの教師なし学習手法を適用することで、企業は顧客データ内の意味のあるパターンやグループを発見できます。 たとえば、クラスタリング アルゴリズムは、同様の購入習慣、人口統計、または好みを持つ顧客のグループを識別できます。 この情報を活用して、ターゲットを絞ったマーケティング キャンペーンを作成し、製品の推奨を最適化し、顧客満足度を向上させることができます。
主なアルゴリズムクラス
教師あり学習アルゴリズム
-
線形モデル: 特徴とターゲット変数の間の線形関係に基づいて連続変数を予測するために使用されます。
-
ツリーベースのモデル: 予測または分類を行うための一連の二分決定を使用して構築されます。
-
アンサンブル モデル: 複数のモデル (ツリーベースまたは線形) を組み合わせて、より正確な予測を行う方法。
-
ニューラル ネットワーク モデル: 人間の脳に大まかに基づいた方法。複数の機能がネットワークのノードとして機能します。
教師なし学習アルゴリズム
-
階層的クラスタリング: クラスターのマージまたは分割を繰り返して、クラスターの階層を構築します。
-
非階層クラスタリング: 類似性に基づいてデータを個別のクラスターに分割します。
-
次元削減: 最も重要な情報を維持しながら、データの次元を削減します。
モデル評価
教師あり学習
教師あり学習モデルのパフォーマンスを評価するには、精度、適合率、再現率、F1 スコア、ROC-AUC などのさまざまな指標が使用されます。 k 分割交差検証などの交差検証手法は、モデルの汎化パフォーマンスを推定するのに役立ちます。
教師なし学習
教師なし学習アルゴリズムの評価は、グランドトゥルースがないため、多くの場合より困難です。 シルエット スコアや慣性などのメトリクスを使用して、クラスタリング結果の品質を評価できます。 視覚化手法を使用すると、クラスターの構造についての洞察も得られます。
ヒントとテクニック
教師あり学習
- 入力データを前処理および正規化して、モデルのパフォーマンスを向上させます。
- 欠損値を代入または削除によって適切に処理します。
- 特徴エンジニアリングにより、関連するパターンを捕捉するモデルの能力を強化できます。
教師なし学習
- ドメインの知識に基づいて、またはエルボー手法などの手法を使用して、適切なクラスターの数を選択します。
- データ ポイント間の類似性を測定するために、さまざまな距離メトリックを考慮します。
- クラスタリング プロセスを正規化して、過剰適合を回避します。
要約すると、機械学習には多数のタスク、テクニック、アルゴリズム、モデル評価方法、役立つヒントが含まれます。 これらの側面を理解することで、実務者は機械学習を現実世界の問題に効率的に適用し、データから重要な洞察を引き出すことができます。 与えられたコード例は、教師あり学習アルゴリズムと教師なし学習アルゴリズムの利用法を示し、その実際の実装を強調しています。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- EVMファイナンス。 分散型金融のための統一インターフェイス。 こちらからアクセスしてください。
- クォンタムメディアグループ。 IR/PR増幅。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 データ インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- 情報源: https://stackabuse.com/supervised-learning-vs-unsupervised-learning-algorithms/