
この投稿は、Bosch Center for Artificial Intelligence (BCAI) の Goktug Cinar、Michael Binder、および Adrian Horvath によって共同執筆されました。
収益予測は、ほとんどの組織において、戦略的なビジネス上の意思決定と財政計画にとって困難でありながら重要なタスクです。 多くの場合、収益予測は財務アナリストによって手動で実行され、時間がかかり、主観的です。 このような手動の作業は、さまざまなレベルの粒度で幅広い製品グループと地理的領域にわたる収益予測を必要とする大規模な多国籍企業にとって特に困難です。 これには、精度だけでなく、予測の階層的な一貫性も必要です。
ボッシュ は、自動車、産業用ソリューション、消費財など、複数のセクターで事業を展開する多国籍企業です。 正確で首尾一貫した収益予測が健全な事業運営に与える影響を考えると、 ボッシュ人工知能センター (BCAI) は、財務計画プロセスの効率と精度を向上させるために、機械学習 (ML) の使用に多額の投資を行ってきました。 目標は、ML を介して合理的なベースライン収益予測を提供することにより、手動プロセスを軽減することです。金融アナリストは、業界およびドメインの知識を使用して、時折の調整のみを必要とします。
この目標を達成するために、BCAI は、幅広い基本モデルのカスタマイズされたアンサンブルを介して大規模な階層予測を提供できる内部予測フレームワークを開発しました。 メタ学習者は、各時系列から抽出された特徴に基づいて、最もパフォーマンスの高いモデルを選択します。 次に、選択したモデルからの予測を平均して、集計された予測を取得します。 アーキテクチャ設計はモジュール化されており、追加のモデルを含めることで継続的なパフォーマンスの向上を可能にする REST スタイル インターフェイスの実装を通じて拡張可能です。
BCAIは Amazon MLソリューションラボ (MLSL) は、収益予測のためのディープ ニューラル ネットワーク (DNN) ベースのモデルに最新の進歩を組み込みます。 ニューラル予測の最近の進歩により、多くの実用的な予測問題に対して最先端のパフォーマンスが実証されています。 従来の予測モデルと比較して、多くのニューラル予測では、追加の共変量または時系列のメタデータを組み込むことができます。 CNN-QR と DeepAR+ の XNUMX つの既製モデルが含まれています。 アマゾン予測、および以下を使用してトレーニングされたカスタム Transformer モデル アマゾンセージメーカー. XNUMX つのモデルは、畳み込みニューラル ネットワーク (CNN)、逐次再帰型ニューラル ネットワーク (RNN)、および変換器ベースのエンコーダーである、ニューラル予測でよく使用されるエンコーダー バックボーンの代表的なセットをカバーしています。
BCAI と MLSL のパートナーシップが直面する主な課題の 19 つは、COVID-XNUMX の影響下で堅牢で合理的な予測を提供することでした。COVID-XNUMX は、世界の企業の財務結果に大きな変動をもたらす前例のない世界的なイベントです。 ニューラル予測は過去のデータに基づいてトレーニングされているため、変動の激しい期間の分布外のデータに基づいて生成された予測は、不正確で信頼できないものになる可能性があります。 したがって、この問題に対処するために、Transformer アーキテクチャにマスクされた注意メカニズムを追加することを提案しました。
ニューラル フォーキャスターは、単一のアンサンブル モデルとしてバンドルすることも、Bosch のモデル ユニバースに個別に組み込むこともでき、REST API エンドポイントを介して簡単にアクセスできます。 バックテストの結果を通じてニューラル予測をアンサンブルするアプローチを提案します。これにより、時間の経過とともに競争力のある堅牢なパフォーマンスが得られます。 さらに、製品グループ、地域、およびビジネス組織全体で予測が一貫して集計されるように、多くの従来の階層調整手法を調査および評価しました。
この投稿では、次のことを示します。
- 階層的で大規模な時系列予測問題に Forecast および SageMaker カスタムモデルトレーニングを適用する方法
- カスタム モデルを Forecast の既製モデルでアンサンブルする方法
- COVID-19 などの破壊的なイベントが予測の問題に与える影響を軽減する方法
- AWS でエンドツーエンドの予測ワークフローを構築する方法
課題
階層的で大規模な収益予測の作成と、長期予測に対する COVID-19 パンデミックの影響という XNUMX つの課題に取り組みました。
階層的で大規模な収益予測
財務アナリストは、収益、運用コスト、研究開発費などの主要な財務数値を予測する任務を負っています。 これらのメトリクスは、さまざまな集計レベルで事業計画の洞察を提供し、データ駆動型の意思決定を可能にします。 自動化された予測ソリューションは、事業分野の集計の任意のレベルで予測を提供する必要があります。 ボッシュでは、集計は、階層構造のより一般的な形式として、グループ化された時系列として想像できます。 次の図は、ボッシュの階層的な収益予測構造を模倣した XNUMX レベル構造の単純化された例を示しています。 総収益は、製品と地域に基づいて複数の集計レベルに分割されます。
ボッシュで予測する必要がある時系列の総数は数百万規模です。 最上位の時系列を製品または地域で分割して、最下位レベルの予測への複数のパスを作成できることに注意してください。 収益は、階層内のすべてのノードで、12 か月先の予測範囲で予測する必要があります。 毎月の履歴データが利用可能です。
階層構造は、加算行列の表記法で次の形式を使用して表すことができます。 S (ハインドマンとアタナソプロス):
![]()
この方程式では、 Y 以下に等しい:

ここでは、 b 時間における最下位レベルの時系列を表します t.
COVID-19 パンデミックの影響
COVID-19 パンデミックは、仕事と社会生活のほぼすべての側面に破壊的かつ前例のない影響を与えるため、予測に大きな課題をもたらしました。 長期的な収益予測に関しては、混乱は予想外のダウンストリームへの影響ももたらしました。 この問題を説明するために、次の図は、パンデミックの開始時に製品収益が大幅に減少し、その後徐々に回復したサンプルの時系列を示しています。 典型的なニューラル予測モデルは、モデル トレーニングのグラウンド トゥルースだけでなく、配布外 (OOD) の COVID 期間を含む収益データを履歴コンテキストの入力として取得します。 その結果、作成された予測は信頼できなくなります。

モデリングのアプローチ
このセクションでは、さまざまなモデリング手法について説明します。
アマゾン予測
Forecast は、事前設定された最先端の時系列予測モデルを提供する AWS の完全マネージド型の AI/ML サービスです。 これらのオファリングを、自動化されたハイパーパラメーター最適化、アンサンブル モデリング (Forecast によって提供されるモデル用)、および確率的予測生成のための内部機能と組み合わせます。 これにより、カスタム データセットの取り込み、データの前処理、予測モデルのトレーニング、堅牢な予測の生成を簡単に行うことができます。 さらに、サービスのモジュール設計により、並行して開発された追加のカスタム モデルからの予測を簡単に照会して組み合わせることができます。
Forecast の XNUMX つのニューラル予測機能 (CNN-QR と DeepAR+) を組み込みます。 どちらも、時系列データセット全体のグローバル モデルをトレーニングする教師ありディープ ラーニング手法です。 CNNQR モデルと DeepAR+ モデルはどちらも、各時系列に関する静的メタデータ情報を取り込むことができます。これは、この場合、対応する製品、地域、および事業組織です。 また、モデルへの入力の一部として、月などの一時的な特徴も自動的に追加します。
COVID 用アテンション マスク付きトランスフォーマー
Transformer アーキテクチャ (バスワニ等。) は、もともと自然言語処理 (NLP) 用に設計されたもので、最近、時系列予測の一般的なアーキテクチャの選択肢として登場しました。 ここでは、 で説明されている Transformer アーキテクチャを使用しました。 周他 確率的なログのまばらな注意なし。 このモデルは、エンコーダーとデコーダーを組み合わせた典型的なアーキテクチャ設計を使用しています。 収益予測の場合、自己回帰方式で月ごとの予測を生成するのではなく、12 か月の期間の予測を直接出力するようにデコーダーを構成します。 時系列の頻度に基づいて、月などの時間関連の特徴が入力変数として追加されます。 メタ情報 (製品、地域、事業組織) を記述する追加のカテゴリ変数は、トレーニング可能な埋め込みレイヤーを介してネットワークに供給されます。
次の図は、Transformer アーキテクチャとアテンション マスキング メカニズムを示しています。 OOD データが予測に影響を与えるのを防ぐために、オレンジ色で強調表示されているように、すべてのエンコーダーおよびデコーダー レイヤーにアテンション マスキングが適用されます。

アテンション マスクを追加することで、OOD コンテキスト ウィンドウの影響を軽減します。 このモデルは、マスキングによって外れ値を含む COVID 期間にほとんど注意を払わないようにトレーニングされており、マスキングされた情報を使用して予測を実行します。 アテンション マスクは、デコーダーおよびエンコーダー アーキテクチャのすべてのレイヤーに適用されます。 マスクされたウィンドウは、手動で指定するか、外れ値検出アルゴリズムを使用して指定できます。 さらに、外れ値を含む時間ウィンドウをトレーニング ラベルとして使用する場合、損失は逆伝播されません。 このアテンション マスキング ベースの方法を適用して、他のまれなイベントによってもたらされる混乱や OOD ケースを処理し、予測の堅牢性を向上させることができます。
モデルアンサンブル
モデル アンサンブルは、多くの場合、予測に関して単一モデルよりも優れています。これにより、モデルの一般化可能性が向上し、周期性と間欠性のさまざまな特性を持つ時系列データの処理に優れています。 モデルのパフォーマンスと予測の堅牢性を向上させるために、一連のモデル アンサンブル戦略を取り入れています。 深層学習モデル アンサンブルの一般的な形式の XNUMX つは、さまざまなランダムな重みの初期化を使用したモデル実行からの結果、またはさまざまなトレーニング エポックからの結果を集計することです。 この戦略を利用して、Transformer モデルの予測を取得します。
Transformer、CNNQR、DeepAR+ などのさまざまなモデル アーキテクチャの上にアンサンブルをさらに構築するために、バックテストの結果に基づいて各時系列の上位 k の最高のパフォーマンス モデルを選択し、それらのモデルを取得するパンモデル アンサンブル戦略を使用します。平均。 バックテストの結果はトレーニング済みの Forecast モデルから直接エクスポートできるため、この戦略により、Transformer などのカスタム モデルから得られる改善を備えた Forecast などのターンキー サービスを活用できます。 このようなエンドツーエンドのモデル アンサンブル アプローチでは、メタ学習者をトレーニングしたり、モデル選択のために時系列の特徴を計算したりする必要はありません。
階層調整
このフレームワークは、ボトムアップ (BU)、予測比率によるトップダウン調整 (TDFP)、通常の最小二乗 (OLS)、加重最小二乗 ( WLS)。 この投稿のすべての実験結果は、予測比率によるトップダウン調整を使用して報告されています。
アーキテクチャの概要
AWS で自動化されたエンドツーエンドのワークフローを開発し、Forecast、SageMaker、 Amazon シンプル ストレージ サービス (Amazon S3)、 AWSラムダ, AWSステップ関数, AWSクラウド開発キット (AWS CDK)。 デプロイされたソリューションは、REST API を使用して個々の時系列予測を提供します。 アマゾンAPIゲートウェイ、定義済みの JSON 形式で結果を返します。
次の図は、エンド ツー エンドの予測ワークフローを示しています。

アーキテクチャの重要な設計上の考慮事項は、汎用性、パフォーマンス、および使いやすさです。 システムは、必要な変更を最小限に抑えて、開発および展開中にさまざまなアルゴリズムのセットを組み込むのに十分な汎用性があり、将来新しいアルゴリズムを追加するときに簡単に拡張できる必要があります。 また、システムは最小限のオーバーヘッドを追加し、Forecast と SageMaker の両方の並列トレーニングをサポートして、トレーニング時間を短縮し、最新の予測をより迅速に取得する必要があります。 最後に、システムは実験目的で簡単に使用できる必要があります。
エンド ツー エンドのワークフローは、次のモジュールを順番に実行します。
- データの再フォーマットと変換のための前処理モジュール
- SageMaker で Forecast モデルとカスタム モデルの両方を組み込んだモデル トレーニング モジュール (両方とも並行して実行されます)
- モデル アンサンブル、階層調整、メトリック、およびレポート生成をサポートする後処理モジュール
Step Functions は、ワークフローをエンドツーエンドでステート マシンとして編成および調整します。 ステート マシンの実行は、必要なすべての情報を含む JSON ファイルで構成されます。これには、Amazon S3 の過去の収益 CSV ファイルの場所、予測の開始時間、エンドツーエンドのワークフローを実行するためのモデルのハイパーパラメータ設定が含まれます。 非同期呼び出しは、Lambda 関数を使用してステート マシンでモデル トレーニングを並列化するために作成されます。 すべての履歴データ、構成ファイル、予測結果、およびバックテスト結果などの中間結果は Amazon S3 に保存されます。 REST API は Amazon S3 の上に構築され、予測結果をクエリするためのクエリ可能なインターフェイスを提供します。 システムを拡張して、新しい予測モデルや、予測可視化レポートの生成などのサポート機能を組み込むことができます。
評価
このセクションでは、実験のセットアップについて詳しく説明します。 主要なコンポーネントには、データセット、評価指標、バックテスト ウィンドウ、モデルのセットアップとトレーニングが含まれます。
データセット
意味のあるデータセットを使用しながらボッシュの財務上のプライバシーを保護するために、ボッシュの 1,216 つのビジネス ユニットからの実際の収益データセットと同様の統計的特性を持つ合成データセットを使用しました。 データセットには合計 2016 の時系列が含まれ、2022 年 877 月から XNUMX 年 XNUMX 月までをカバーする月次頻度で収益が記録されます。総和行列 S として。各時系列は、実際のデータセット (合成データで匿名化されている) の製品カテゴリ、地域、および組織単位に対応する XNUMX つの静的なカテゴリ属性に関連付けられています。
評価指標
中央値逆正接絶対パーセント誤差 (中央値-MAAPE) と重み付き-MAAPE を使用して、モデルのパフォーマンスを評価し、ボッシュで使用される標準的な測定基準である比較分析を実行します。 MAAPE は、ビジネス コンテキストで一般的に使用される平均絶対誤差率 (MAPE) メトリックの欠点に対処します。 Median-MAAPE は、各時系列で個別に計算された MAAPE の中央値を計算することにより、モデルのパフォーマンスの概要を示します。 Weighted-MAAPE は、個々の MAAPE の重み付けされた組み合わせを報告します。 重みは、データセット全体の集計収益と比較した各時系列の収益の割合です。 Weighted-MAAPE は、予測精度のダウンストリーム ビジネスへの影響をより適切に反映します。 両方のメトリックは、1,216 の時系列のデータセット全体について報告されます。
バックテスト ウィンドウ
モデルのパフォーマンスを比較するために、ローリング 12 か月のバックテスト ウィンドウを使用します。 次の図は、実験で使用されたバックテスト ウィンドウを示しており、トレーニングとハイパーパラメーターの最適化 (HPO) に使用された対応するデータを強調しています。 COVID-19 が始まった後のバックテスト ウィンドウの場合、結果は、収益の時系列から観察したことに基づいて、2020 年 XNUMX 月から XNUMX 月までの OOD 入力の影響を受けます。

モデルのセットアップとトレーニング
Transformer トレーニングでは、分位損失を使用し、Transformer に入力してトレーニング損失を計算する前に、過去の平均値を使用して各時系列をスケーリングしました。 に実装されている MeanScaler を使用して、最終的な予測が再スケーリングされ、精度指標が計算されます。 グルオンTS. 18 年 2018 月から 2019 年 15 月までのバックテスト ウィンドウで HPO を介して選択された、過去 2020 か月の月次収益データを含むコンテキスト ウィンドウを使用します。各時系列に関する追加のメタデータは、静的カテゴリ変数の形式で、埋め込みを介してモデルに供給されます。トランス層に供給する前に層。 XNUMX つの異なるランダムな重みの初期化を使用して Transformer をトレーニングし、実行ごとに最後の XNUMX つのエポックからの予測結果を平均し、合計で XNUMX のモデルを平均します。 XNUMX つのモデル トレーニングの実行を並列化して、トレーニング時間を短縮できます。 マスクされた Transformer については、XNUMX 年 XNUMX 月から XNUMX 月までの月を異常値として示しています。
すべての予測モデル トレーニングで、自動 HPO を有効にしました。これにより、トレーニングと HPO に使用されるデータ ウィンドウで過去 12 か月に設定された、ユーザー指定のバックテスト期間に基づいてモデルとトレーニング パラメーターを選択できます。
実験結果
同じ一連のハイパーパラメーターを使用して、マスクされたトランスフォーマーとマスクされていないトランスフォーマーをトレーニングし、COVID-19 ショック直後のバックテスト ウィンドウでパフォーマンスを比較しました。 マスクされた Transformer では、マスクされた 2020 つの月は 12 年 2020 月と XNUMX 月です。次の表は、XNUMX 年 XNUMX 月から始まる XNUMX か月の予測ウィンドウを使用した一連のバックテスト期間の結果を示しています。マスクされた Transformer は、マスクされていないバージョンより一貫して優れていることがわかります。 .

さらに、バックテストの結果に基づいて、モデル アンサンブル戦略の評価を行いました。 特に、上位 XNUMX つのモデルのみを選択した場合と、上位 XNUMX つのモデルを選択した場合の XNUMX つのケースを比較し、予測の平均値を計算することによってモデルの平均化を実行します。 次の図で、基本モデルとアンサンブル モデルのパフォーマンスを比較します。 ローリング バックテスト ウィンドウで一貫して他のニューラル予測を上回るパフォーマンスを発揮するニューラル予測は存在しないことに注意してください。


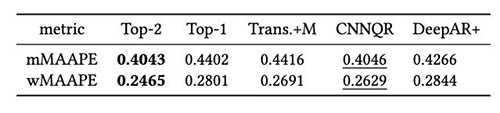
次の表は、平均して、上位 XNUMX つのモデルのアンサンブル モデリングが最高のパフォーマンスを発揮することを示しています。 CNNQR は XNUMX 番目に良い結果を提供します。
まとめ
この投稿では、Forecast と SageMaker でトレーニングされたカスタムモデルを組み合わせて、大規模な予測問題のためのエンドツーエンドの ML ソリューションを構築する方法を示しました。 ビジネス ニーズと ML の知識に応じて、Forecast などのフル マネージド サービスを使用して、予測モデルのビルド、トレーニング、デプロイ プロセスをオフロードできます。 SageMaker で特定の調整メカニズムを使用してカスタムモデルを構築します。 または、XNUMX つのサービスを組み合わせてモデルのアンサンブルを実行します。
製品やサービスでの ML の使用を促進するための支援が必要な場合は、 Amazon MLソリューションラボ プログラム。
参考文献
Hyndman RJ、Athanasopoulos G. 予測: 原則と実践。 Oテキスト; 2018 年 8 月 XNUMX 日。
Vaswani A、Shazeer N、Parmar N、Uszkoreit J、Jones L、Gomez AN、Kaiser Ł、Polosukhin I. 注意が必要なすべてです。 神経情報処理システムの進歩。 2017;30.
Zhou H、Zhang S、Peng J、Zhang S、Li J、Xiong H、Zhang W. Informer: 長いシーケンスの時系列予測のための効率的なトランスフォーマーを超えて。 AAAI 2021 の議事録 2 月 XNUMX 日。
著者について
 ゴクトゥグ シナール は、Robert Bosch LLC および Bosch Center for Artificial Intelligence のリード ML サイエンティストであり、ML および統計ベースの予測のテクニカル リーダーです。 彼は、予測モデル、階層的統合、およびモデル結合手法の研究を主導し、これらのモデルをスケーリングして社内のエンドツーエンドの財務予測ソフトウェアの一部として提供するソフトウェア開発チームを率いています。
ゴクトゥグ シナール は、Robert Bosch LLC および Bosch Center for Artificial Intelligence のリード ML サイエンティストであり、ML および統計ベースの予測のテクニカル リーダーです。 彼は、予測モデル、階層的統合、およびモデル結合手法の研究を主導し、これらのモデルをスケーリングして社内のエンドツーエンドの財務予測ソフトウェアの一部として提供するソフトウェア開発チームを率いています。
 マイケル・バインダー は、Bosch Global Services のプロダクト オーナーであり、大規模な自動化されたデータ駆動型の財務キー フィギュアの予測のための全社的な予測分析アプリケーションの開発、展開、および実装を調整しています。
マイケル・バインダー は、Bosch Global Services のプロダクト オーナーであり、大規模な自動化されたデータ駆動型の財務キー フィギュアの予測のための全社的な予測分析アプリケーションの開発、展開、および実装を調整しています。
 エイドリアン・ホーバス Bosch Center for Artificial Intelligence のソフトウェア開発者であり、さまざまな予測モデルに基づいて予測を作成するシステムを開発および保守しています。
エイドリアン・ホーバス Bosch Center for Artificial Intelligence のソフトウェア開発者であり、さまざまな予測モデルに基づいて予測を作成するシステムを開発および保守しています。
 パンパン・シュー AWS の Amazon ML Solutions Lab の上級応用科学者兼マネージャーです。 彼女は、AI とクラウドの採用を加速するために、さまざまな業界で影響力の大きい顧客アプリケーション向けの機械学習アルゴリズムの研究開発に取り組んでいます。 彼女の研究対象には、モデルの解釈可能性、因果分析、ヒューマン イン ザ ループ AI、インタラクティブなデータ視覚化が含まれます。
パンパン・シュー AWS の Amazon ML Solutions Lab の上級応用科学者兼マネージャーです。 彼女は、AI とクラウドの採用を加速するために、さまざまな業界で影響力の大きい顧客アプリケーション向けの機械学習アルゴリズムの研究開発に取り組んでいます。 彼女の研究対象には、モデルの解釈可能性、因果分析、ヒューマン イン ザ ループ AI、インタラクティブなデータ視覚化が含まれます。
 ジャスリーン・グレワル アマゾン ウェブ サービスの応用科学者であり、AWS のお客様と協力して機械学習を使用して現実世界の問題を解決し、特に精密医療とゲノミクスに重点を置いています。 彼女は、バイオインフォマティクス、腫瘍学、および臨床ゲノミクスに強いバックグラウンドを持っています。 彼女は AI/ML とクラウド サービスを使用して患者ケアを改善することに情熱を注いでいます。
ジャスリーン・グレワル アマゾン ウェブ サービスの応用科学者であり、AWS のお客様と協力して機械学習を使用して現実世界の問題を解決し、特に精密医療とゲノミクスに重点を置いています。 彼女は、バイオインフォマティクス、腫瘍学、および臨床ゲノミクスに強いバックグラウンドを持っています。 彼女は AI/ML とクラウド サービスを使用して患者ケアを改善することに情熱を注いでいます。
 セルバン・センティベル は、AWSのAmazon ML Solutions LabのシニアMLエンジニアであり、機械学習、ディープラーニングの問題、エンドツーエンドのMLソリューションについてお客様を支援することに重点を置いています。 彼はAmazonComprehendMedicalの創設エンジニアリングリーダーであり、複数のAWSAIサービスの設計とアーキテクチャに貢献しました。
セルバン・センティベル は、AWSのAmazon ML Solutions LabのシニアMLエンジニアであり、機械学習、ディープラーニングの問題、エンドツーエンドのMLソリューションについてお客様を支援することに重点を置いています。 彼はAmazonComprehendMedicalの創設エンジニアリングリーダーであり、複数のAWSAIサービスの設計とアーキテクチャに貢献しました。
 ルイリン・チャン AWS の Amazon ML Solutions Lab の SDE です。 彼は、一般的なビジネス上の問題に対処するソリューションを構築することで、顧客が AWS AI サービスを採用するのを支援しています。
ルイリン・チャン AWS の Amazon ML Solutions Lab の SDE です。 彼は、一般的なビジネス上の問題に対処するソリューションを構築することで、顧客が AWS AI サービスを採用するのを支援しています。
 シェーンライ AWS の Amazon ML Solutions Lab のシニア ML ストラテジストです。 彼は、さまざまな業界の顧客と協力して、AWS の幅広いクラウドベースの AI/ML サービスを使用して、最も差し迫った革新的なビジネス ニーズを解決しています。
シェーンライ AWS の Amazon ML Solutions Lab のシニア ML ストラテジストです。 彼は、さまざまな業界の顧客と協力して、AWS の幅広いクラウドベースの AI/ML サービスを使用して、最も差し迫った革新的なビジネス ニーズを解決しています。
 リン・リーチョン AWS の Amazon ML Solutions Lab チームの応用科学マネージャーです。 彼女は戦略的な AWS の顧客と協力して、人工知能と機械学習を調査および適用して、新しい洞察を発見し、複雑な問題を解決しています。
リン・リーチョン AWS の Amazon ML Solutions Lab チームの応用科学マネージャーです。 彼女は戦略的な AWS の顧客と協力して、人工知能と機械学習を調査および適用して、新しい洞察を発見し、複雑な問題を解決しています。