
予知保全は、機器の故障につながる可能性のある機器の動作や状態の異常を検出するために、産業用資産を監視するためのデータ駆動型のメンテナンス戦略です。 資産の状態を積極的に監視することで、問題が発生する前にメンテナンス担当者に警告を発することができるため、費用のかかる計画外のダウンタイムを回避でき、総合設備効率 (OEE) の向上につながります。
ただし、予知保全に必要な機械学習 (ML) モデルの構築は複雑で時間がかかります。 データの前処理、ビルド、トレーニング、評価、アセットのデータの異常を確実に予測できる複数の ML モデルの微調整など、いくつかの手順が必要です。 次に、完成した ML モデルをデプロイし、オンライン予測 (推論) 用のライブ データを提供する必要があります。 このプロセスをさまざまなタイプと運用プロファイルの複数のアセットにスケーリングすると、多くの場合、リソースが集中しすぎて、予知保全をより広く採用することができなくなります。
機器のAmazonルックアウトを使用すると、産業用機器のセンサー データをシームレスに分析して、マシンの異常な動作を検出できます。機械学習の経験は必要ありません。
お客様が Lookout for Equipment を使用して予知保全のユースケースを実装する場合、通常、プロジェクトを提供するための XNUMX つのオプション (自分で構築する、AWS パートナーと協力する、または AWS プロフェッショナル サービスを使用する) から選択します。 このようなプロジェクトに取り組む前に、プラント管理者、信頼性または保守管理者、およびライン リーダーなどの意思決定者は、予知保全が自分たちの事業分野で明らかにする潜在的な価値の証拠を見たいと考えています。 このような評価は通常、概念実証 (POC) の一部として実行され、ビジネス ケースの基礎となります。
この投稿は、技術ユーザーと非技術ユーザーの両方を対象としています。これは、Lookout for Equipment を独自のデータで評価するための効果的なアプローチを提供し、予知保全活動が提供するビジネス価値を測定できるようにします。
ソリューションの概要
この投稿では、Lookout for Equipment でデータセットを取り込み、センサー データの品質を確認し、モデルをトレーニングし、モデルを評価する手順について説明します。 これらの手順を完了すると、機器の状態を把握するのに役立ちます。
前提条件
開始するために必要なのは、AWS アカウントと、予知保全アプローチの恩恵を受けることができるアセットのセンサー データの履歴だけです。 センサー データは、CSV ファイルとして保存する必要があります。 Amazon シンプル ストレージ サービス アカウントからの (Amazon S3) バケット。 IT チームは、以下を参照してこれらの前提条件を満たすことができるはずです。 データのフォーマット. 単純にするために、すべてのセンサー データを 300 つの CSV ファイルに保存することをお勧めします。行はタイムスタンプで、列は個々のセンサー (最大 XNUMX) です。
Amazon S3 でデータセットを利用できるようになったら、この投稿の残りの部分を進めることができます。
データセットを追加する
Lookout for Equipment はプロジェクトを使用して、産業用機器を評価するためのリソースを編成します。 新しいプロジェクトを作成するには、次の手順を実行します。
- Lookout for Equipment コンソールで、 プロジェクトを作成する.
![サービスのホームページで [Create Project] ボタンをクリックします。](https://xlera8.com/wp-content/uploads/2023/03/enable-predictive-maintenance-for-line-of-business-users-with-amazon-lookout-for-equipment.png)
- プロジェクト名を入力して選択します プロジェクトを作成する.
プロジェクトが作成されたら、異常検出用のモデルのトレーニングと評価に使用されるデータセットを取り込むことができます。
- プロジェクトページで、 データセットを追加する.
![プロジェクト ダッシュボードで [データセットの追加] をクリックします。](https://xlera8.com/wp-content/uploads/2023/03/enable-predictive-maintenance-for-line-of-business-users-with-amazon-lookout-for-equipment.jpg)
- S3の場所で、データの S3 の場所 (ファイル名を除く) を入力します。
- スキーマ検出方法選択 ファイル名別これは、アセットのすべてのセンサー データが、指定された S3 の場所にある XNUMX つの CSV ファイルに含まれていることを前提としています。
- 他の設定はデフォルトのままにして、 摂取開始 取り込みプロセスを開始します。
![データ ソースの詳細を構成し、[取り込みの開始] をクリックします。](https://xlera8.com/wp-content/uploads/2023/03/enable-predictive-maintenance-for-line-of-business-users-with-amazon-lookout-for-equipment-1.png)
取り込みが完了するまでに約 10 ~ 20 分かかる場合があります。 バックグラウンドで、Lookout for Equipment は次のタスクを実行します。
- センサー名やデータ型など、データの構造を検出します。
- センサー間のタイムスタンプが調整され、欠損値が埋められます (最新の既知の値を使用)。
- 重複するタイムスタンプは削除されます (各タイムスタンプの最後の値のみが保持されます)。
- Lookout for Equipment は、ML 異常検出モデルを構築するために複数のタイプのアルゴリズムを使用します。 取り込みフェーズでは、さまざまなアルゴリズムのトレーニングに使用できるようにデータを準備します。
- 測定値を分析し、各センサーを高品質、中品質、または低品質に分類します。
- データセットの取り込みが完了したら、選択して検査します データセットを表示 プロジェクト ページのステップ 2 の下。
![プロジェクト ダッシュボードで [データセットを表示] をクリックします。](https://xlera8.com/wp-content/uploads/2023/03/enable-predictive-maintenance-for-line-of-business-users-with-amazon-lookout-for-equipment-2.png)
異常検出モデルを作成する場合、実用的な洞察を提供するモデルをトレーニングするには、最適なセンサー (最高のデータ品質を含むセンサー) を選択することが重要な場合がよくあります。 の データセットの詳細 セクションにはセンサー グレーディングの分布 (高、中、低) が表示され、テーブルには各センサーの情報 (センサー名、日付範囲、センサー データのグレーディングなど) が個別に表示されます。 この詳細なレポートを使用すると、モデルのトレーニングに使用するセンサーについて十分な情報に基づいた決定を下すことができます。 データセット内のセンサーの大部分が中または低と評価されている場合、調査が必要なデータの問題がある可能性があります。 必要に応じて、データ ファイルを Amazon S3 に再アップロードし、データを再度取り込むことができます。 データセットを置き換える.
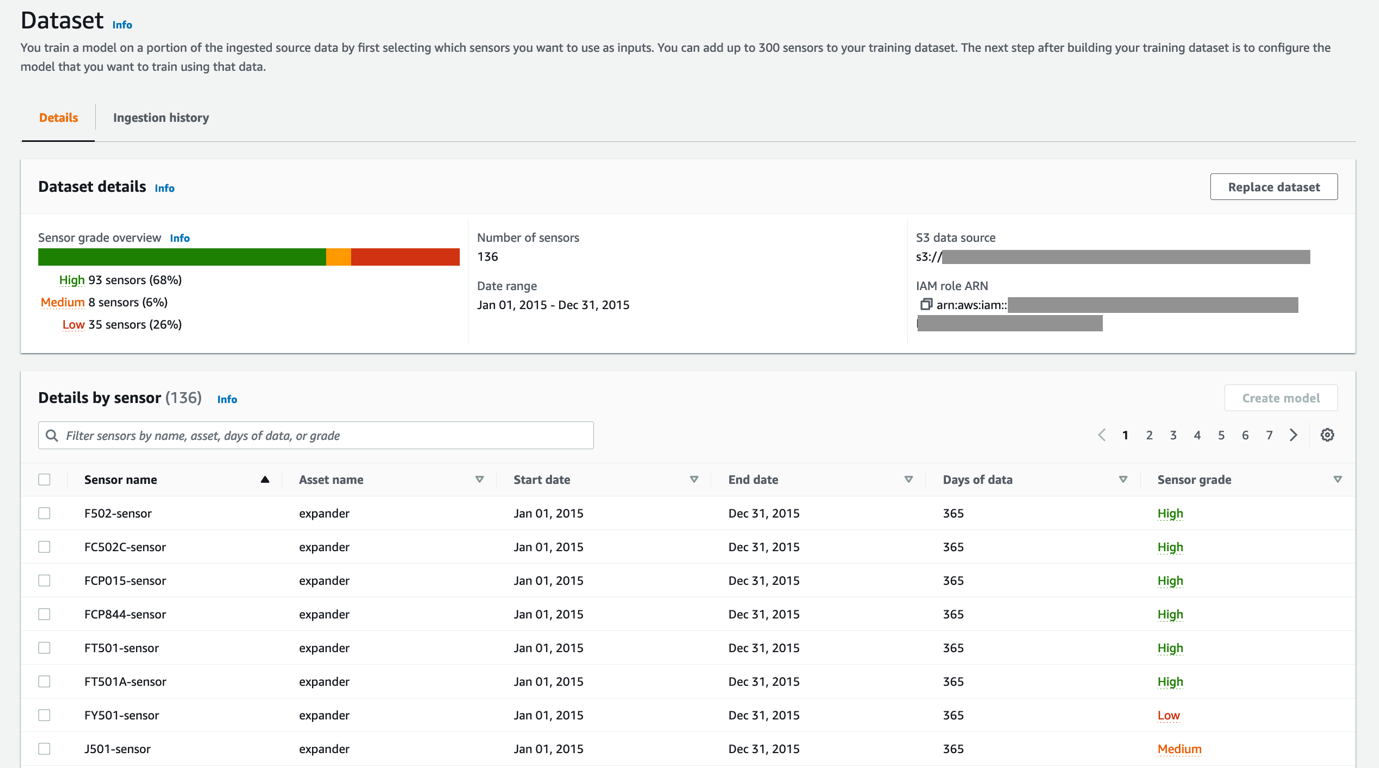
詳細テーブルでセンサー グレード エントリを選択すると、特定のグレードにつながる検証エラーの詳細を確認できます。 これらの詳細を表示して対処することで、モデルに提供される情報が高品質であることを確認できます。 たとえば、信号に欠損値の予期しない大きなチャンクがある場合があります。 これはデータ転送の問題ですか、それともセンサーの誤動作ですか? データを深く掘り下げる時が来ました!

さまざまなタイプのセンサーの問題の詳細については、センサーをグレーディングする際の機器アドレスの参照を参照してください。 センサーグレードの評価. 開発者は、 ListSensorStatistics API.
データセットに満足したら、異常を予測するためのモデルのトレーニングの次のステップに進むことができます。
モデルをトレーニングする
Lookout for Equipment を使用すると、特定のセンサーのモデルをトレーニングできます。 これにより、さまざまなセンサーの組み合わせを試したり、グレードの低いセンサーを除外したりできる柔軟性が得られます。 次の手順を完了します。
- センサー別詳細 データセット ページのセクションで、モデルに含めるセンサーを選択し、 モデルを作成する.
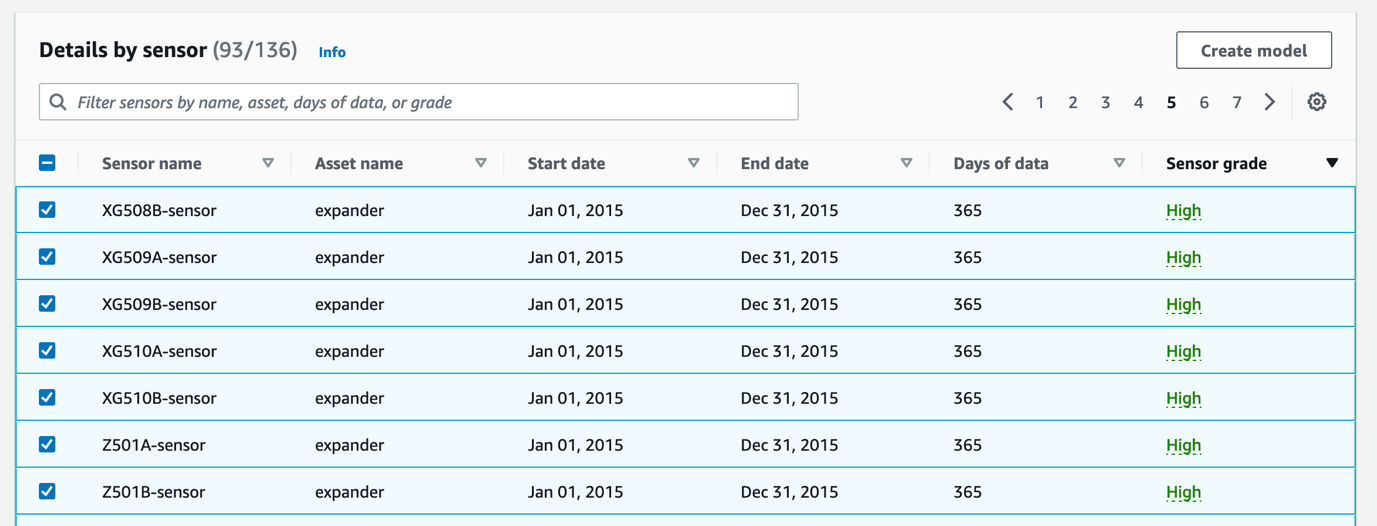
- モデル名、モデル名を入力してから、 Next.

- トレーニングと評価の設定 セクションで、モデルの入力データを構成します。
モデルを効果的にトレーニングするには、データを個別のトレーニング セットと評価セットに分割する必要があります。 このセクションでは、この分割の日付範囲と、センサーのサンプリング レートを定義できます。 この分割をどのように選択しますか? 次の点を考慮してください。
- Lookout for Equipment は、トレーニング範囲で少なくとも 3 か月のデータを想定していますが、最適なデータ量はユース ケースによって決まります。 あらゆるタイプの季節性または生産が通過する運用サイクルを説明するには、より多くのデータが必要になる場合があります。
- 評価範囲に制限はありません。 ただし、既知の異常を含む評価範囲を設定することをお勧めします。 このようにして、Lookout for Equipment がこれらの異常につながる関心のあるイベントをキャプチャできるかどうかをテストできます。
サンプル レートを指定することにより、Lookout for Equipment はセンサー データを効果的にダウンサンプリングし、トレーニング時間を大幅に短縮できます。 理想的なサンプリング レートは、データ内で疑われる異常の種類によって異なります。傾向が遅い異常の場合、通常は 1 ~ 10 分のサンプリング レートを選択するのが適切な出発点です。 低い値を選択すると (サンプリング レートが高くなります)、トレーニング時間が長くなりますが、高い値を選択すると (サンプリング レートが低くなる)、トレーニング時間が短縮されますが、異常の予測に関連する先行指標がデータから除外されるリスクがあります。
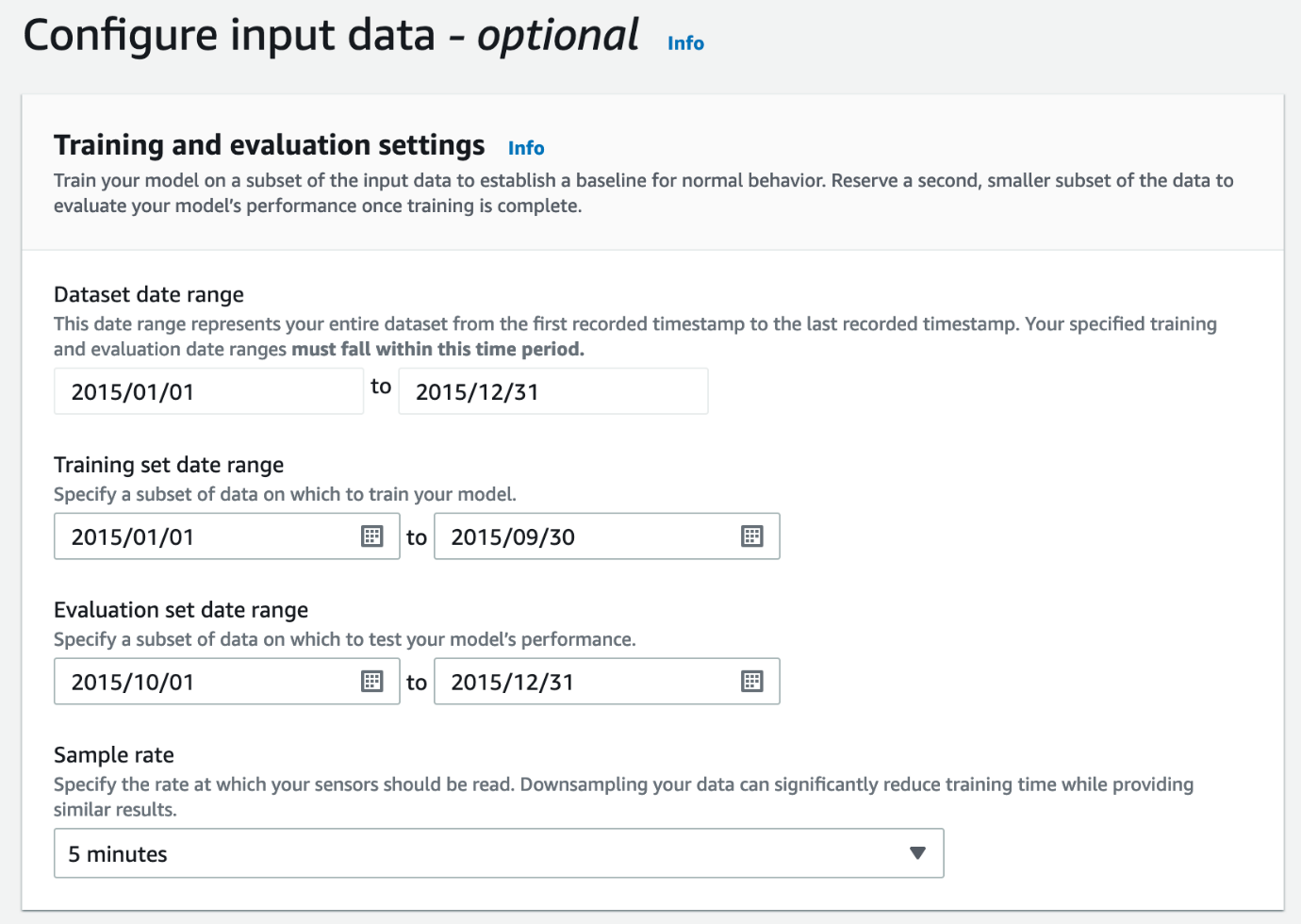
産業用機器が稼働していたデータの関連部分のみをトレーニングする場合は、センサーを選択し、機器がオン状態かオフ状態かを示すしきい値を定義することで、オフタイム検出を実行できます。 これは重要です。マシンがオフになっているときに、Lookout for Equipment がトレーニングの期間を除外できるようにするためです。 これは、モデルがマシンがオフのときだけでなく、関連する動作状態のみを学習することを意味します。
- オフタイム検出を指定し、選択します Next.

必要に応じて、メンテナンス期間または既知の機器の故障時期を示すデータ ラベルを提供できます。 そのようなデータが利用可能な場合は、データを使用して CSV ファイルを作成できます。 文書化された形式、Amazon S3 にアップロードし、モデルのトレーニングに使用します。 ラベルを提供すると、Lookout for Equipment に既知の異常を検出できる場所を伝えることで、トレーニング済みモデルの精度を向上させることができます。
- 任意のデータ ラベルを指定してから、 Next.
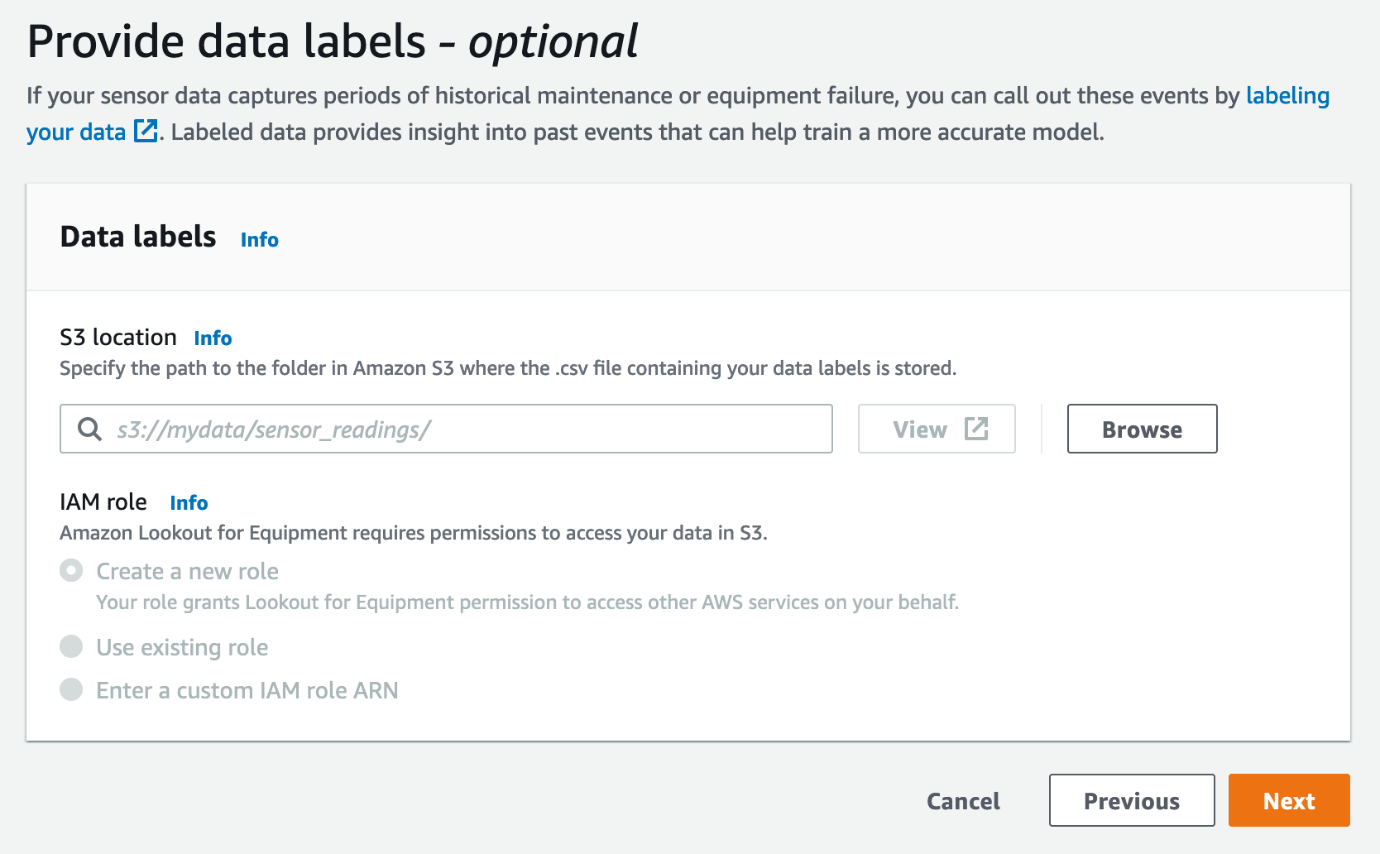
- 最後のステップで設定を確認します。 すべてが正常に見える場合は、トレーニングを開始できます。
データセットのサイズ、センサーの数、サンプリング レートによっては、モデルのトレーニングに数分から数時間かかる場合があります。 たとえば、1 個のセンサーとラベルなしで 5 分のサンプリング レートで 100 年間のデータを使用する場合、モデルのトレーニングにかかる時間は 15 分未満です。 一方、データに多数のラベルが含まれている場合、トレーニング時間が大幅に増加する可能性があります。 このような状況では、隣接するラベル期間をマージしてその数を減らすことで、トレーニング時間を短縮できます。
機械学習の知識がなくても、最初の異常検出モデルをトレーニングできました! 次に、トレーニング済みのモデルから得られる洞察を見てみましょう。
訓練されたモデルを評価する
モデルのトレーニングが終了したら、選択してモデルの詳細を表示できます。 モデルを見る プロジェクト ページで、モデルの名前を選択します。
名前、ステータス、トレーニング時間などの一般的な情報に加えて、モデル ページには、検出されたラベル付きイベントの数 (ラベルを提供したと仮定)、平均事前警告時間、外部で検出された異常な機器イベントの数などのモデル パフォーマンス データが要約されます。ラベル範囲。 次のスクリーンショットは例を示しています。 見やすくするために、検出されたイベント (リボンの上部にある赤いバー) とラベル付きのイベント (リボンの下部にある青いバー) が視覚化されます。

タイムライン ビューで異常を表す赤い領域を選択して、検出されたイベントを選択し、追加情報を取得できます。 これも:
- イベントの開始時間と終了時間、およびその期間。
- 異常が発生した理由に最も関連しているとモデルが判断したセンサーを示す棒グラフ。 パーセンテージ スコアは、計算された全体的な貢献度を表します。
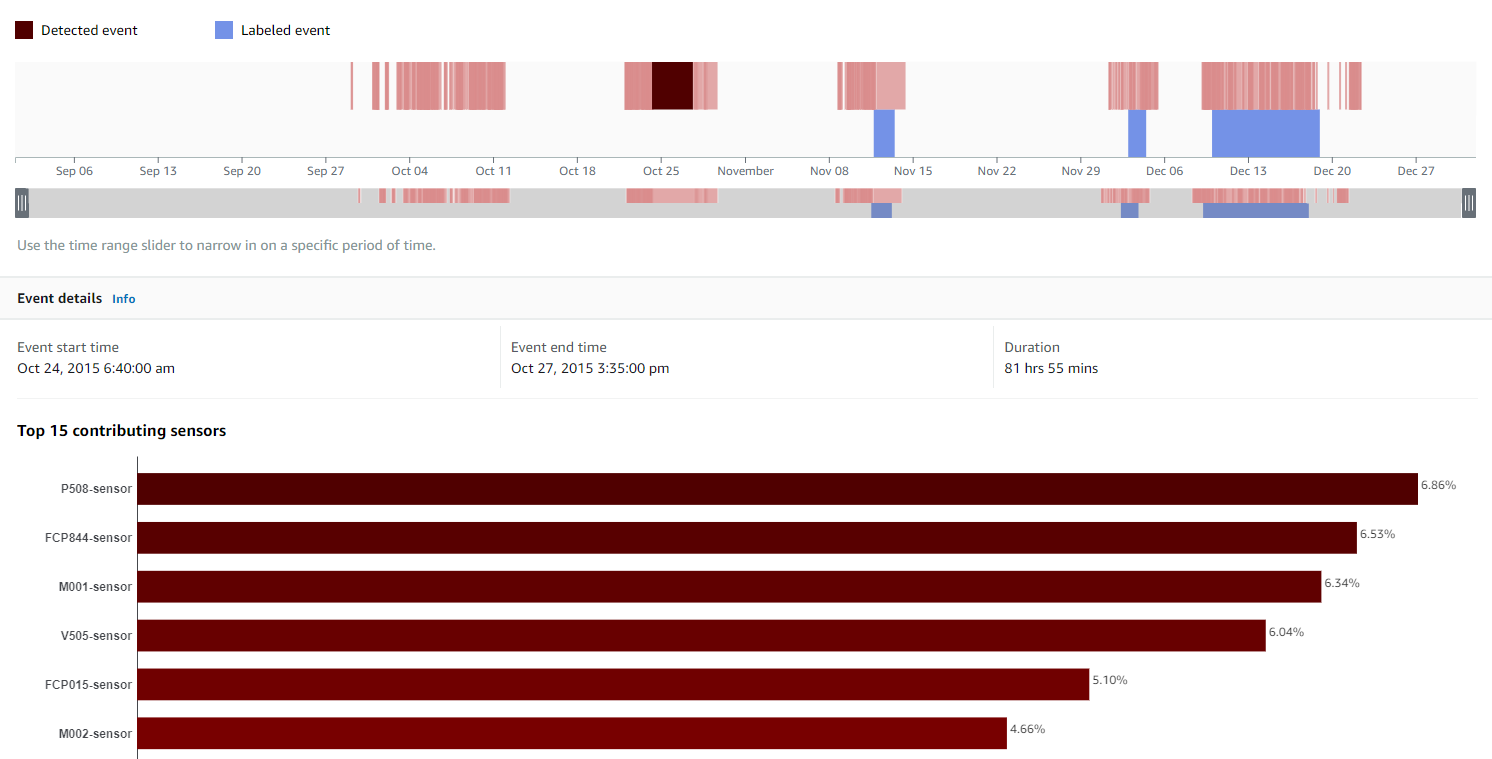
これらの洞察により、プロセスまたは信頼性エンジニアと協力して、イベントの根本原因をさらに評価し、最終的にメンテナンス活動を最適化し、計画外のダウンタイムを削減し、最適ではない動作条件を特定することができます。
リアルタイムの洞察 (推論) による予知保全をサポートするために、Lookout for Equipment は推論スケジュールによるオンライン データのライブ評価をサポートしています。 これには、センサー データを Amazon S3 に定期的にアップロードする必要があります。次に、Lookout for Equipment がトレーニング済みモデルを使用してデータの推論を実行し、リアルタイムの異常スコアリングを提供します。 検出された異常イベントの履歴を含む推論結果は、Lookout for Equipment コンソールで表示できます。

結果は Amazon S3 のファイルにも書き込まれるため、コンピュータ化された保守管理システム (CMMS) などの他のシステムと統合したり、運用および保守担当者にリアルタイムで通知したりできます。
Lookout for Equipment の採用が増えるにつれて、より多くのモデルと推論スケジュールを管理する必要があります。 このプロセスを簡単にするために、 推論スケジュール ページには、プロジェクト用に現在構成されているすべてのスケジューラが XNUMX つのビューに一覧表示されます。

クリーンアップ
Lookout for Equipment の評価が終了したら、すべてのリソースをクリーンアップすることをお勧めします。 Lookout for Equipment プロジェクトは、プロジェクトを選択して作成されたデータセットおよびモデルとともに削除できます。 削除、およびアクションを確認します。
まとめ
この投稿では、Lookout for Equipment でデータセットを取り込み、モデルをトレーニングし、そのパフォーマンスを評価して、個々の資産について明らかにできる価値を理解する手順について説明しました。 具体的には、Lookout for Equipment が予測メンテナンス プロセスにどのように情報を提供できるかを調査しました。これにより、計画外のダウンタイムが短縮され、OEE が向上します。
独自のデータを追跡し、Lookout for Equipment を使用する可能性に興奮している場合、次のステップは、IT 組織、主要なパートナー、または AWS プロフェッショナル サービス チームのサポートを受けて、パイロット プロジェクトを開始することです。 このパイロットは、限られた数の産業機器を対象とし、最終的にすべての資産を予知保全の範囲に含めるようにスケールアップする必要があります。
著者について
 ヨハン・フュークスル アマゾン ウェブ サービスのソリューション アーキテクトです。 AI/ML ユースケースの実装、最新のデータ アーキテクチャの設計、具体的なビジネス価値を提供するクラウドネイティブ ソリューションの構築において、製造業の企業顧客をガイドしています。 Johann は、数学と定量モデリングのバックグラウンドを持ち、IT での 10 年の経験を兼ね備えています。 仕事以外では、家族と過ごしたり、自然の中で過ごすことを楽しんでいます。
ヨハン・フュークスル アマゾン ウェブ サービスのソリューション アーキテクトです。 AI/ML ユースケースの実装、最新のデータ アーキテクチャの設計、具体的なビジネス価値を提供するクラウドネイティブ ソリューションの構築において、製造業の企業顧客をガイドしています。 Johann は、数学と定量モデリングのバックグラウンドを持ち、IT での 10 年の経験を兼ね備えています。 仕事以外では、家族と過ごしたり、自然の中で過ごすことを楽しんでいます。
 ミハエル・ホアラウ AWS の産業用 AI/ML スペシャリスト ソリューション アーキテクトであり、状況に応じてデータ サイエンティストと機械学習アーキテクトを交互に担当しています。 彼は AI/ML の力を産業顧客の製造現場にもたらすことに情熱を傾けており、異常検出から製品品質の予測や製造の最適化まで、幅広い ML ユースケースに取り組んできました。 顧客が次善の機械学習エクスペリエンスを開発するのを支援していないときは、星を観察したり、旅行したり、ピアノを弾いたりしています。
ミハエル・ホアラウ AWS の産業用 AI/ML スペシャリスト ソリューション アーキテクトであり、状況に応じてデータ サイエンティストと機械学習アーキテクトを交互に担当しています。 彼は AI/ML の力を産業顧客の製造現場にもたらすことに情熱を傾けており、異常検出から製品品質の予測や製造の最適化まで、幅広い ML ユースケースに取り組んできました。 顧客が次善の機械学習エクスペリエンスを開発するのを支援していないときは、星を観察したり、旅行したり、ピアノを弾いたりしています。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- Platoblockchain。 Web3メタバースインテリジェンス。 知識の増幅。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/machine-learning/enable-predictive-maintenance-for-line-of-business-users-with-amazon-lookout-for-equipment/