
リリース 6.14 以降、 アマゾンEMRスタジオ インタラクティブ分析をサポート Amazon EMR サーバーレス。 EC2 クラスター上の Amazon EMR に加えて、EMR サーバーレス アプリケーションをコンピューティングとして使用できるようになりました。 EKS上のAmazonEMR 仮想クラスター。EMR Studio ワークスペースから JupyterLab ノートブックを実行します。
EMR Studio は、データ サイエンティストやデータ エンジニアが PySpark、Python、Scala で記述された分析アプリケーションを簡単に開発、視覚化、デバッグできるようにする統合開発環境 (IDE) です。 EMR サーバーレスは、次のサーバーレス オプションです。 アマゾンEMR これにより、クラスターやサーバーを構成、管理、スケーリングすることなく、Apache Spark などのオープンソースのビッグ データ分析フレームワークを簡単に実行できるようになります。
この投稿では、次の方法を説明します。
- インタラクティブ アプリケーション用の EMR サーバーレス エンドポイントを作成する
- エンドポイントを既存の EMR Studio 環境に接続する
- ノートブックを作成して対話型アプリケーションを実行する
- EMR Studio 内からインタラクティブ アプリケーションをシームレスに診断
前提条件
一般的な組織では、AWS アカウント管理者は次のような AWS リソースをセットアップします。 AWS ID とアクセス管理 (IAM) ロール、 Amazon シンプル ストレージ サービス (Amazon S3) バケット、および アマゾン バーチャル プライベート クラウド インターネット アクセスおよび VPC 内の他のリソースへのアクセスのための (Amazon VPC) リソース。 EMR Studio のセットアップと特定の EMR Studio へのユーザーの割り当てを管理する EMR Studio 管理者を割り当てます。割り当てが完了すると、EMR Studio 開発者は EMR Studio を使用してワークロードの開発と監視を行うことができます。
S3 バケット、VPC サブネット、EMR Studio などのリソースは必ず同じ AWS リージョンに設定してください。
これらの前提条件を展開するには、次の手順を実行します。
- 以下を起動します AWS CloudFormation スタック。

- 値を入力してください 管理者のパスワード & 開発者パスワード 作成したパスワードをメモします。
- 選択する Next.
- 設定をデフォルトのままにして選択します Next 再び。
- 選択 AWS CloudFormationがカスタム名でIAMリソースを作成する可能性があることを認めます.
- 送信を選択します.
また、サンプル IAM ポリシーを使用してこれらのリソースを手動でデプロイする手順も提供しています。 GitHubレポ.
EMR Studio とサーバーレス対話型アプリケーションをセットアップする
AWS アカウント管理者が前提条件を完了すると、EMR Studio 管理者は AWSマネジメントコンソール EMR Studio、Workspace、EMR Serverless アプリケーションを作成します。
EMR スタジオとワークスペースを作成する
EMR Studio 管理者は、次のコマンドを使用してコンソールにログインする必要があります。 emrs-interactive-app-admin-user ユーザーの資格情報。提供された CloudFormation テンプレートを使用して前提条件リソースをデプロイした場合は、入力パラメーターとして指定したパスワードを使用します。
- Amazon EMRコンソールで、 EMR サーバーレス ナビゲーションペインに表示されます。

- 選択する 始める.
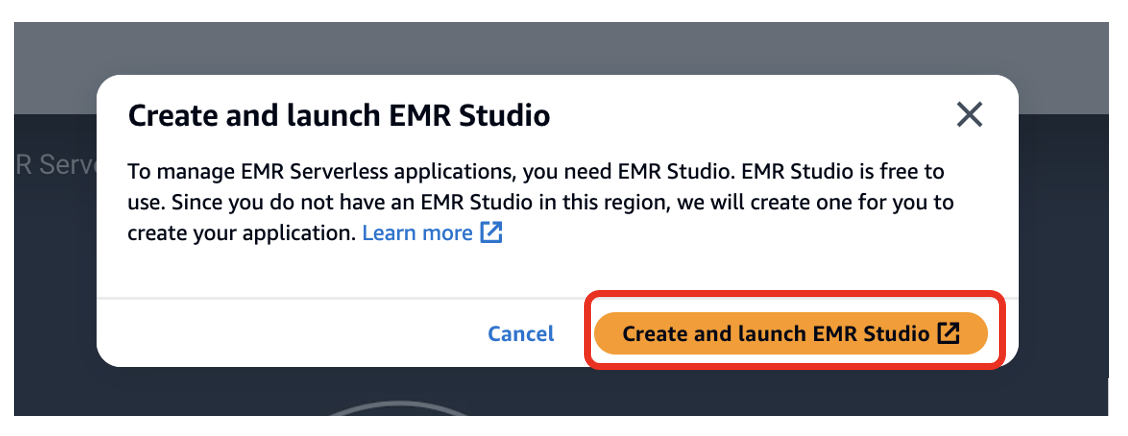
- 選択 EMR Studioを作成して起動する.
これにより、デフォルトの名前でスタジオが作成されます studio_1 およびデフォルト名のワークスペース My_First_Workspace。新しいブラウザタブが開きます。 Studio_1 ユーザーインターフェース。
EMR サーバーレス アプリケーションを作成する
EMR サーバーレス アプリケーションを作成するには、次の手順を実行します。
- EMR Studio コンソールで、 アプリケーション ナビゲーションペインに表示されます。
- 新しいアプリケーションを作成します。
- 名前 、名前を入力します(たとえば、
my-serverless-interactive-application). - アプリケーション設定オプション選択 カスタム設定を使用する インタラクティブなワークロード向け。
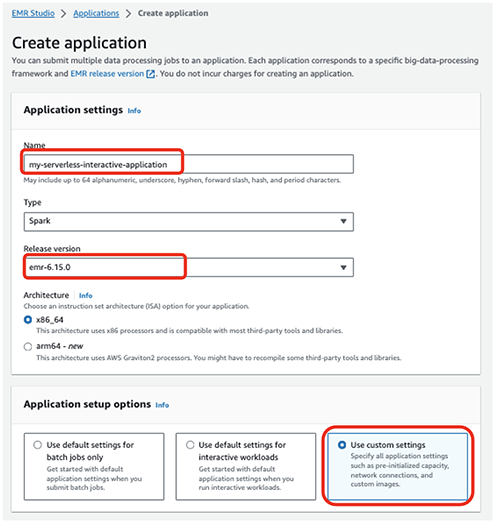
対話型アプリケーションの場合、ベスト プラクティスとして、ドライバーとワーカーを事前に初期化した状態に保つことをお勧めします。 初期化済み容量 アプリケーション作成時。これにより、アプリケーション用のワーカーのウォーム プールが効果的に作成され、リソースをいつでも使用できる状態に保つことができるため、アプリケーションは数秒で応答できるようになります。 EMR サーバーレス アプリケーションを作成するためのその他のベスト プラクティスについては、次を参照してください。 Amazon EMR サーバーレスを使用してビッグデータワークロードのチームごとのリソース制限を定義する.
- インタラクティブなエンドポイント セクション、選択 インタラクティブエンドポイントを有効にする.
- ネットワーク接続 セクションで、前に作成した VPC、プライベート サブネット、セキュリティ グループを選択します。
この投稿で提供されている CloudFormation スタックをデプロイした場合は、 emr-serverless-sg セキュリティグループとして。
ワークロードが外部 Python パッケージをダウンロードするために EMR サーバーレス アプリケーション内からインターネットにアクセスできるようにするには、VPC が必要です。 VPC を使用すると、次のようなリソースにアクセスすることもできます。 Amazon リレーショナル データベース サービス (Amazon RDS)および Amazonレッドシフト このアプリケーションの VPC 内にあるもの。サーバーレス アプリケーションを VPC に接続すると、サブネットで IP が枯渇する可能性があるため、サブネットに十分な IP アドレスがあることを確認してください。
- 選択する アプリケーションを作成して開始する.

アプリケーション ページで、サーバーレス アプリケーションのステータスが次のように変化することを確認できます。 開始.
- アプリケーションを選択して選択してください 機能.
- 選択する ワークスペースの表示と起動.
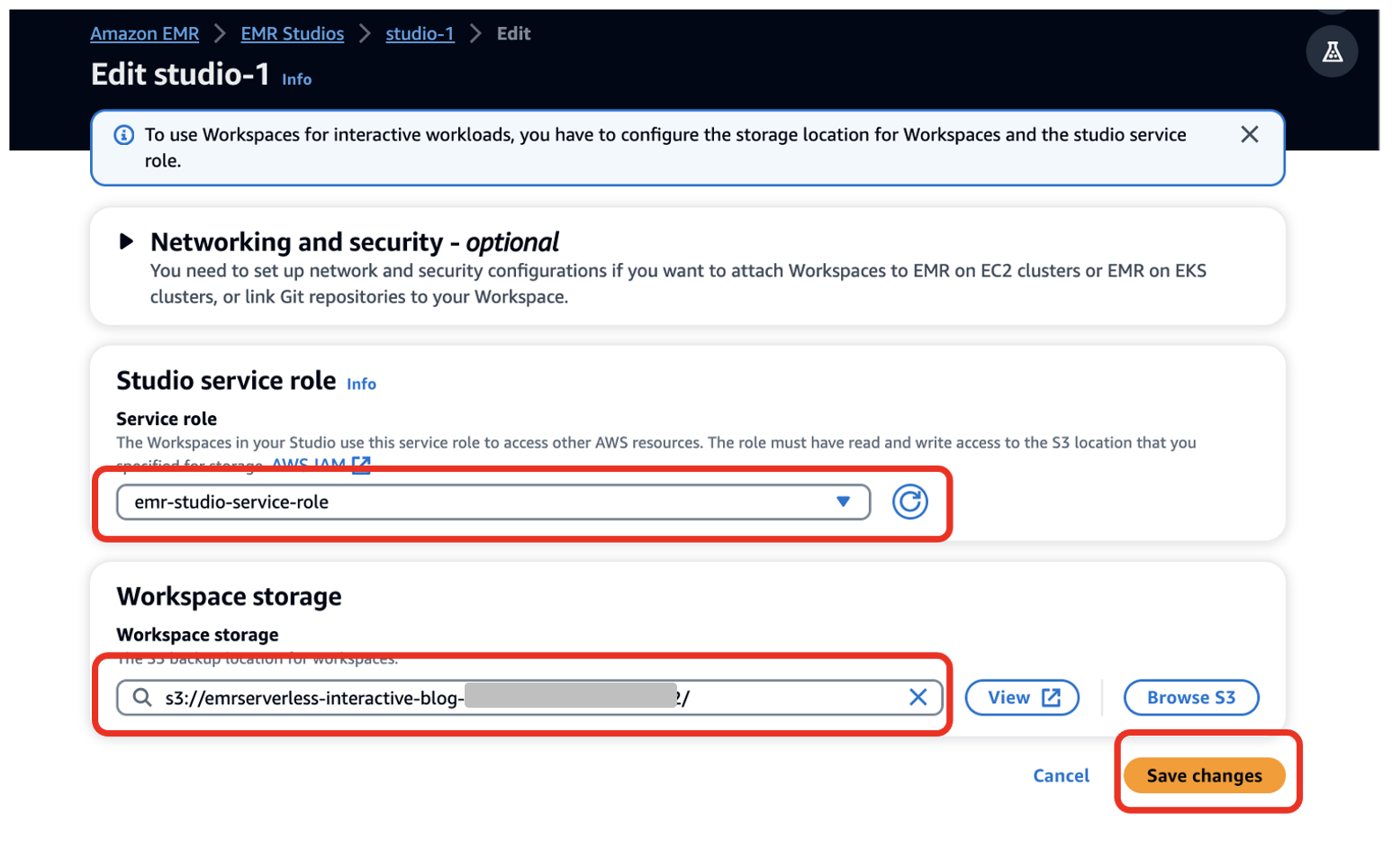
- 選択する スタジオを構成する.

- サービスの役割¸ 前提条件として作成した EMR Studio サービス ロールを提供します (
emr-studio-service-role). - ワークスペースストレージ、前提条件として作成した S3 バケットのパスを入力します (
emrserverless-interactive-blog-<account-id>-<region-name>). - 選択する 変更を保存します.
14. を選択して Studio コンソールに移動します。 ·スタジオ 左側のナビゲーション メニューで、 EMR スタジオ セクション。注意してください スタジオアクセスURL Studios コンソールからダウンロードし、開発者が Spark アプリケーションを実行できるように提供します。
最初の Spark アプリケーションを実行する
EMR Studio 管理者が Studio、ワークスペース、サーバーレス アプリケーションを作成した後、Studio ユーザーはワークスペースとアプリケーションを使用して Spark ワークロードを開発および監視できます。
ワークスペースを起動し、サーバーレス アプリケーションをアタッチします。
次の手順を完了します。
- EMR Studio 管理者から提供された Studio URL を使用してログインします。
emrs-interactive-app-dev-userAWS アカウント管理者によって共有されるユーザー認証情報。
提供された CloudFormation テンプレートを使用して前提条件リソースをデプロイした場合は、入力パラメーターとして指定したパスワードを使用します。
ソフトウェア設定ページで、下図のように ワークスペース ページで、ワークスペースのステータスを確認できます。ワークスペースが起動すると、ステータスが次のように変化します。 準備ができました。
- ワークスペース名 (
My_First_Workspace).
新しいタブが開きます。ブラウザでポップアップが許可されていることを確認してください。
- ワークスペースで、 計算 ナビゲーション ペインの (クラスター アイコン)。
- EMRサーバーレスアプリケーション、アプリケーションを選択してください (
my-serverless-interactive-application). - インタラクティブなランタイムの役割、対話型ランタイム ロールを選択します (この投稿では、
emr-serverless-runtime-role). - 選択する 添付する このワークスペース内のすべてのノートブックのコンピューティング タイプとしてサーバーレス アプリケーションをアタッチします。

Spark アプリケーションを対話的に実行する
次の手順を完了します。
- 選択する ノートブックのサンプル ナビゲーション ペインで (3 つの点のアイコン) を選択して開きます
Getting-started-with-emr-serverlessノート。 - 選択する ワークスペースに保存.
このノートブックのカーネルには、Python 3、PySpark、および Spark (Scala 用) の XNUMX つの選択肢があります。
- プロンプトが表示されたら、を選択します。 パイスパーク カーネルとして。
- 選択する 選択.

これで、Spark アプリケーションを実行できるようになりました。これを行うには、 %%configure スパークマジック コマンド。セッション作成パラメータを構成します。インタラクティブなアプリケーションは Python 仮想環境をサポートします。以下を使用してエグゼキューター環境の別の Python ランタイムのパスを指定することで、ワーカー ノードでカスタム環境を使用します。 spark.executorEnv.PYSPARK_PYTHON。 次のコードを参照してください。
外部パッケージをインストールする
ワーカー用に独立した仮想環境ができたので、EMR Studio ノートブックでは、Spark を使用してサーバーレス アプリケーション内から外部パッケージをインストールできます。 install_pypi_package Spark コンテキストを介して機能します。この機能を使用すると、すべての EMR サーバーレス ワーカーがパッケージを利用できるようになります。
まず、Python パッケージである matplotlib を PyPi からインストールします。
前の手順が応答しない場合は、VPC 設定をチェックし、インターネット アクセス用に正しく設定されていることを確認してください。
これで、データセットを使用してデータを視覚化できるようになりました。
ビジュアライゼーションの作成
ビジュアライゼーションを作成するために、ニューヨーク市の黄色いタクシーに関する公開データセットを使用します。
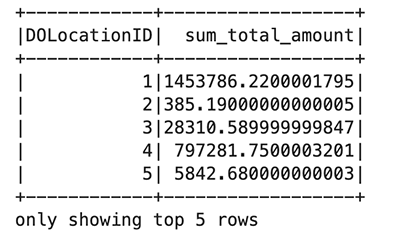
前述のコード ブロックでは、Amazon S3 のパブリック バケットから Parquet ファイルを読み取ります。ファイルにはヘッダーがあり、Spark にスキーマを推測させたいと考えています。次に、Spark データフレームを使用して、特定の列をグループ化してカウントします。 taxi_df:
%%display 結果を表形式で表示するマジック:

5 種類のグラフを使用してデータをすばやく視覚化することもできます。表示タイプを選択すると、それに応じてチャートが変わります。次のスクリーンショットでは、棒グラフを使用してデータを視覚化しています。

Spark SQL を使用して EMR サーバーレスと対話する
テーブルを操作できます。 AWSGlueデータカタログ EMR サーバーレスで Spark SQL を使用する。サンプル ノートブックでは、Spark データフレームを使用してデータを変換する方法を示します。
まず、タクシーという新しい一時ビューを作成します。これにより、Spark SQL を使用してこのビューからデータを選択できるようになります。次に、さらに処理するためにタクシー データフレームを作成します。
EMR Studio ノートブックの各セルで、次の内容を展開できます。 スパークジョブの進行状況 この特定のセルの実行中に EMR サーバーレスに送信されたジョブのさまざまな段階を表示します。各ステージの完了にかかる時間を確認できます。次の例では、ジョブのステージ 14 には 12 個の完了したタスクがあります。さらに、障害が発生した場合はログを確認できるため、トラブルシューティングがスムーズになります。これについては次のセクションで詳しく説明します。
![Job[14]: NativeMethodAccessorImpl.java:0 の showString および Job[15]: NativeMethodAccessorImpl.java:0 の showString](https://xlera8.com/wp-content/uploads/2024/04/run-interactive-workloads-on-amazon-emr-serverless-from-amazon-emr-studio-amazon-web-services-11.png)
matplotlib パッケージを使用して処理されたデータフレームを視覚化するには、次のコードを使用します。 maptplotlib ライブラリを使用して、ドロップオフの場所と合計金額を棒グラフとしてプロットします。
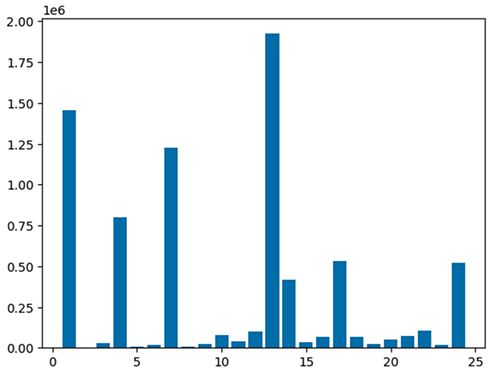
インタラクティブなアプリケーションを診断する
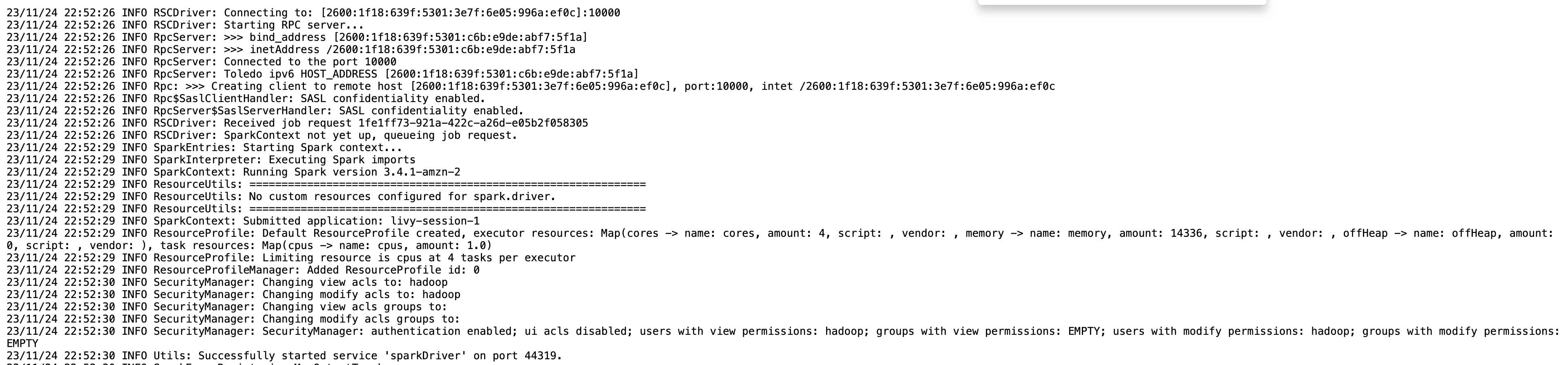
Livy エンドポイントのセッション情報を取得するには、 %%info スパークマジック。これにより、ノートブック内の Spark UI およびドライバー ログにアクセスするためのリンクが提供されます。

次のスクリーンショットは、ノートブック内のリンクから開いたアプリケーションのドライバー ログ スニペットです。
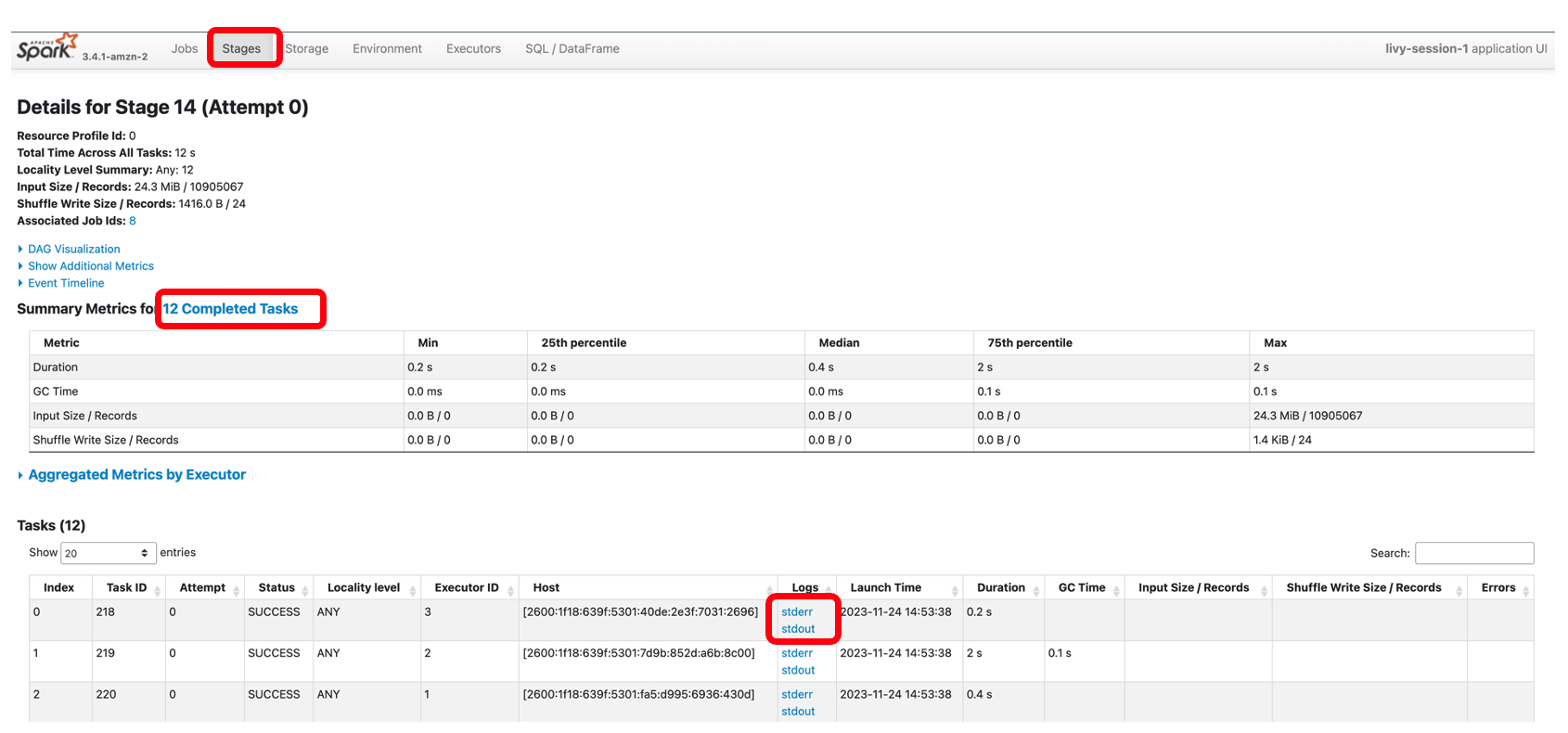
同様に、以下のリンクを選択できます スパークUI をクリックして UI を開きます。次のスクリーンショットは、 執行者 タブからドライバーとエグゼキューターのログにアクセスできます。

次のスクリーンショットはステージ 14 を示しています。これは、前に見た Spark SQL ステップに対応します。このステップでは、12 のタスクに分割されたタクシーの総回収数の場所ごとの合計を計算しました。 Spark UI を介して、インタラクティブ アプリケーションは、きめ細かいタスク レベルのステータス、I/O、およびシャッフルの詳細に加えて、このステージの各タスクに対応するログへのリンクをノートブックから直接提供し、シームレスなトラブルシューティング エクスペリエンスを可能にします。
クリーンアップ
この投稿で作成したリソースを保持したくない場合は、次のクリーンアップ手順を実行してください。
- EMR サーバーレス アプリケーションを削除する.
- EMR Studio と関連するワークスペースとノートブックを削除します。.
- 残りのリソースを削除するには、CloudFormation コンソールに移動し、スタックを選択して、 削除.
S3 バケットを除くすべてのリソースが削除されます。SXNUMX バケットの削除ポリシーは保持するように設定されています。
まとめ
この投稿では、EMR サーバーレスをコンピューティングとして使用して、EMR Studio でインタラクティブな PySpark ワークロードを実行する方法を示しました。インタラクティブな JupyterLab ワークスペースで Spark アプリケーションを構築および監視することもできます。
今後の投稿では、EMR サーバーレス インタラクティブ アプリケーションの次のような追加機能について説明します。
- VPC 内の Amazon RDS や Amazon Redshift などのリソースの操作 (JDBC/ODBC 接続など)
- サーバーレス エンドポイントを使用したトランザクション ワークロードの実行
EMR Studio を初めて使用する場合は、次の内容を確認することをお勧めします。 Amazon EMR ワークショップ と参照して EMRスタジオを作成する.
著者について
 セカール・スリニバサン AWS のプリンシパル スペシャリスト ソリューション アーキテクトであり、データ分析と AI に重点を置いています。 Sekar は、データを扱う 20 年以上の経験があります。彼は、顧客がアーキテクチャを最新化し、データから洞察を生成するスケーラブルなソリューションを構築できるよう支援することに情熱を注いでいます。余暇には、恵まれない子どもたちの教育に焦点を当てた非営利プロジェクトに取り組むことが好きです。
セカール・スリニバサン AWS のプリンシパル スペシャリスト ソリューション アーキテクトであり、データ分析と AI に重点を置いています。 Sekar は、データを扱う 20 年以上の経験があります。彼は、顧客がアーキテクチャを最新化し、データから洞察を生成するスケーラブルなソリューションを構築できるよう支援することに情熱を注いでいます。余暇には、恵まれない子どもたちの教育に焦点を当てた非営利プロジェクトに取り組むことが好きです。
 ディシャ・ウマルワニ グローバル ヘルスケアおよびライフサイエンス分野における Amazon プロフェッショナル サービスのシニア データ アーキテクトです。彼女は顧客と協力して、大規模なデータ戦略を設計、構築、実装してきました。彼女はエンタープライズ プラットフォーム向けのデータ メッシュ アーキテクチャの設計を専門としています。
ディシャ・ウマルワニ グローバル ヘルスケアおよびライフサイエンス分野における Amazon プロフェッショナル サービスのシニア データ アーキテクトです。彼女は顧客と協力して、大規模なデータ戦略を設計、構築、実装してきました。彼女はエンタープライズ プラットフォーム向けのデータ メッシュ アーキテクチャの設計を専門としています。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/big-data/run-interactive-workloads-on-amazon-emr-serverless-from-amazon-emr-studio/