
릴리스 6.14부터 Amazon EMR 스튜디오 대화형 분석을 지원합니다. Amazon EMR 서버리스. 이제 EC2 클러스터의 Amazon EMR 외에도 EMR 서버리스 애플리케이션을 컴퓨팅으로 사용할 수 있습니다. EKS의 Amazon EMR EMR Studio 작업 공간에서 JupyterLab 노트북을 실행하기 위한 가상 클러스터.
EMR Studio는 데이터 과학자와 데이터 엔지니어가 PySpark, Python 및 Scala로 작성된 분석 애플리케이션을 쉽게 개발, 시각화 및 디버깅할 수 있게 해주는 IDE(통합 개발 환경)입니다. EMR 서버리스는 다음을 위한 서버리스 옵션입니다. 아마존 EMR 따라서 클러스터나 서버를 구성, 관리, 확장하지 않고도 Apache Spark와 같은 오픈 소스 빅 데이터 분석 프레임워크를 간단하게 실행할 수 있습니다.
이 게시물에서는 다음을 수행하는 방법을 보여줍니다.
- 대화형 애플리케이션을 위한 EMR 서버리스 엔드포인트 생성
- 기존 EMR Studio 환경에 엔드포인트 연결
- Notebook 생성 및 대화형 애플리케이션 실행
- EMR Studio 내에서 대화형 애플리케이션을 원활하게 진단
사전 조건
일반적인 조직에서는 AWS 계정 관리자가 다음과 같은 AWS 리소스를 설정합니다. AWS 자격 증명 및 액세스 관리 (IAM) 역할, 아마존 단순 스토리지 서비스 (Amazon S3) 버킷 및 아마존 가상 프라이빗 클라우드 (Amazon VPC) 인터넷 액세스 및 VPC의 다른 리소스에 대한 액세스를 위한 리소스입니다. EMR Studio 설정을 관리하고 특정 EMR Studio에 사용자를 할당하는 EMR Studio 관리자를 할당합니다. 할당되면 EMR Studio 개발자는 EMR Studio를 사용하여 워크로드를 개발하고 모니터링할 수 있습니다.
S3 버킷, VPC 서브넷, EMR Studio와 같은 리소스를 동일한 AWS 리전에 설정했는지 확인하세요.
이러한 필수 구성 요소를 배포하려면 다음 단계를 완료하세요.
- 다음을 실행 AWS 클라우드 포메이션 스택.

- 에 대한 값을 입력하십시오 관리자 비밀번호 와 개발자 비밀번호 생성한 비밀번호를 기록해 두세요.
- 왼쪽 메뉴에서 다음 보기.
- 설정을 기본값으로 유지하고 다음을 선택하세요. 다음 보기 또.
- 선택 AWS CloudFormation이 사용자 지정 이름으로 IAM 리소스를 생성 할 수 있음을 인정합니다.
- 제출을 선택하세요.
또한 샘플 IAM 정책을 사용하여 이러한 리소스를 수동으로 배포하는 방법에 대한 지침도 제공했습니다. GitHub 레포.
EMR Studio 및 서버리스 대화형 애플리케이션 설정
AWS 계정 관리자가 사전 조건을 완료한 후 EMR Studio 관리자는 AWS 관리 콘솔 EMR Studio, Workspace 및 EMR Serverless 애플리케이션을 생성합니다.
EMR Studio 및 작업 공간 생성
EMR Studio 관리자는 다음을 사용하여 콘솔에 로그인해야 합니다. emrs-interactive-app-admin-user 사용자 자격 증명. 제공된 CloudFormation 템플릿을 사용하여 필수 리소스를 배포한 경우 입력 매개변수로 제공한 암호를 사용합니다.
- Amazon EMR 콘솔에서 다음을 선택합니다. EMR 서버리스 탐색 창에서

- 왼쪽 메뉴에서 시작하기.
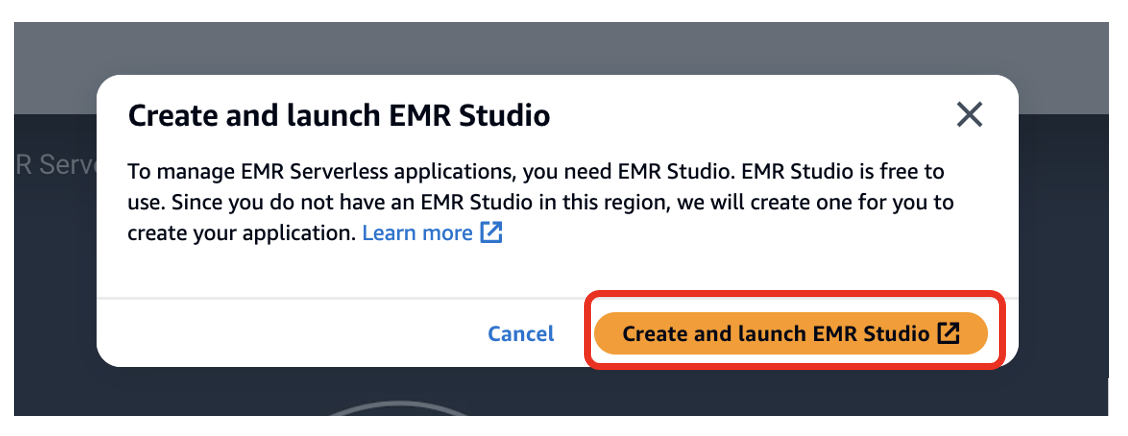
- 선택 EMR Studio 생성 및 실행.
그러면 기본 이름으로 Studio가 생성됩니다. studio_1 기본 이름을 가진 작업공간 My_First_Workspace. 새 브라우저 탭이 열립니다. Studio_1 사용자 인터페이스.
EMR 서버리스 애플리케이션 생성
EMR 서버리스 애플리케이션을 생성하려면 다음 단계를 완료하십시오.
- EMR Studio 콘솔에서 다음을 선택합니다. 어플리케이션 탐색 창에서
- 새 응용 프로그램을 만듭니다.
- 럭셔리 성함, 이름을 입력하십시오 (예 :
my-serverless-interactive-application). - 럭셔리 애플리케이션 설정 옵션, 고르다 맞춤 설정 사용 대화형 워크로드용.
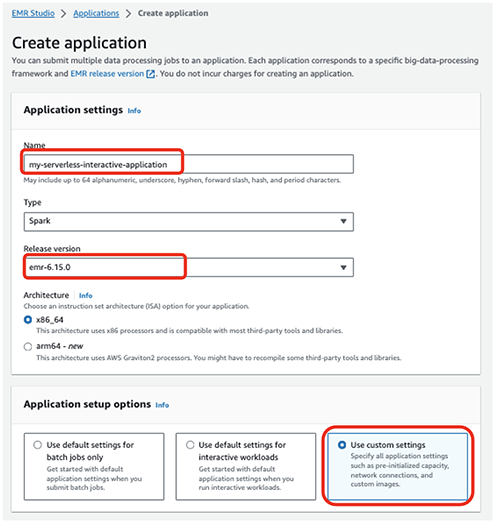
대화형 애플리케이션의 경우 모범 사례로 다음을 구성하여 드라이버와 작업자를 사전 초기화된 상태로 유지하는 것이 좋습니다. 사전 초기화 용량 애플리케이션 생성 시. 이는 애플리케이션을 위한 따뜻한 작업자 풀을 효과적으로 생성하고 리소스를 사용할 준비를 유지하여 애플리케이션이 몇 초 안에 응답할 수 있도록 합니다. EMR 서버리스 애플리케이션 생성에 대한 추가 모범 사례는 다음을 참조하세요. Amazon EMR 서버리스를 사용하여 빅 데이터 워크로드에 대한 팀별 리소스 제한 정의.
- . 대화형 엔드포인트 섹션에서 선택 대화형 끝점 활성화.
- . 네트워크 연결 섹션에서 이전에 생성한 VPC, 프라이빗 서브넷 및 보안 그룹을 선택합니다.
이 게시물에 제공된 CloudFormation 스택을 배포한 경우 다음을 선택하세요. emr-serverless-sg 보안 그룹으로.
외부 Python 패키지를 다운로드하기 위해 워크로드가 EMR 서버리스 애플리케이션 내에서 인터넷에 액세스할 수 있으려면 VPC가 필요합니다. VPC를 사용하면 다음과 같은 리소스에 액세스할 수도 있습니다. Amazon 관계형 데이터베이스 서비스 (아마존 RDS) 및 아마존 레드 시프트 이 애플리케이션의 VPC에 있는 것입니다. 서버리스 애플리케이션을 VPC에 연결하면 서브넷의 IP가 고갈될 수 있으므로 서브넷에 충분한 IP 주소가 있는지 확인하세요.
- 왼쪽 메뉴에서 애플리케이션 생성 및 시작.

애플리케이션 페이지에서 서버리스 애플리케이션의 상태가 다음으로 변경되는지 확인할 수 있습니다. 시작.
- 귀하의 애플리케이션을 선택하고 전달 방법.
- 왼쪽 메뉴에서 작업공간 보기 및 실행.
- 왼쪽 메뉴에서 스튜디오 구성.

- 럭셔리 서비스 역할¸ 전제 조건으로 생성한 EMR Studio 서비스 역할을 제공합니다(
emr-studio-service-role). - 럭셔리 작업 공간 스토리지, 전제 조건으로 생성한 S3 버킷의 경로를 입력합니다(
emrserverless-interactive-blog-<account-id>-<region-name>). - 왼쪽 메뉴에서 변경 사항을 저장.
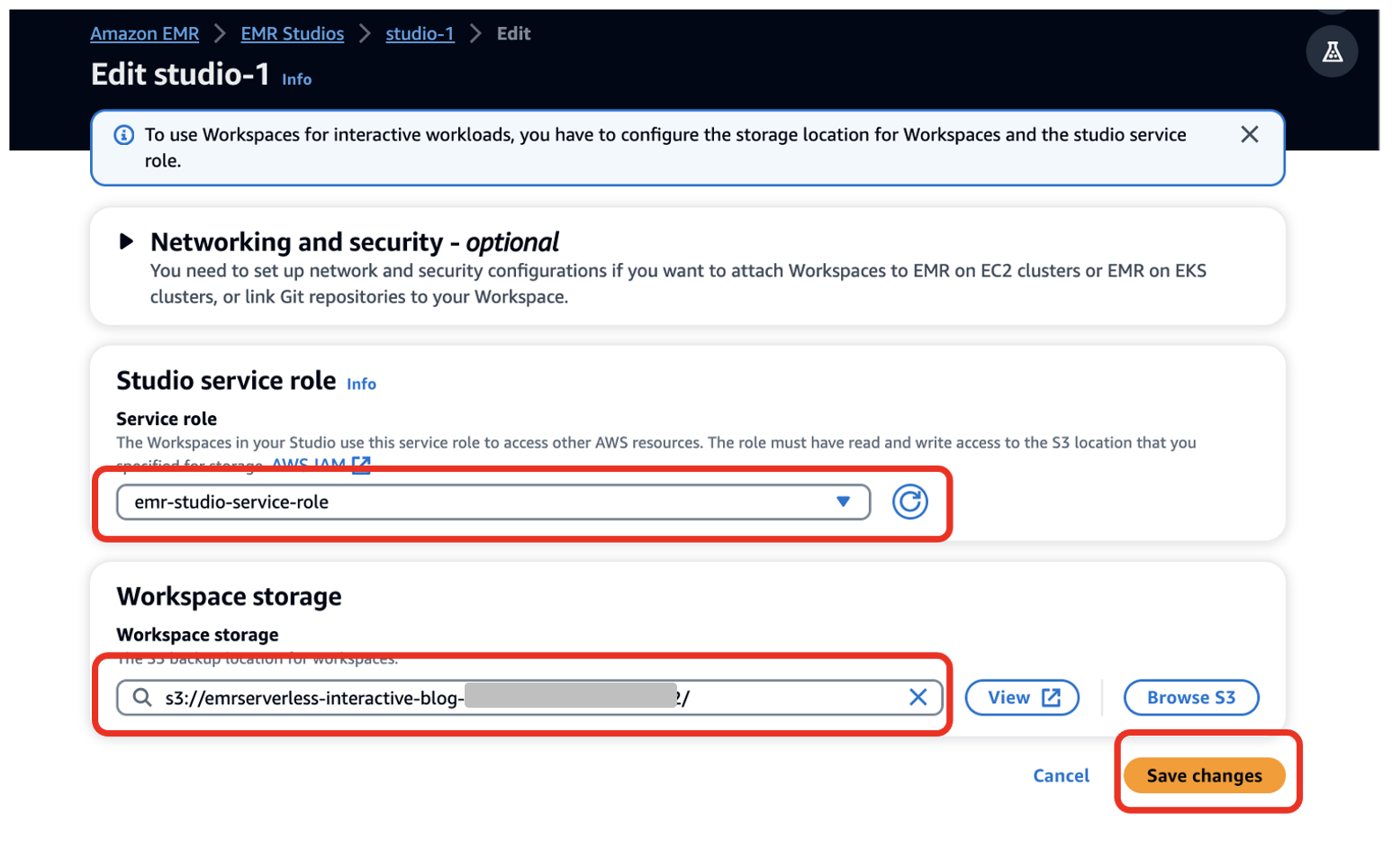
14. 다음을 선택하여 Studios 콘솔로 이동합니다. 스튜디오 왼쪽 탐색 메뉴에서 EMR 스튜디오 부분. 참고하세요 스튜디오 접속 URL Studios 콘솔에서 개발자에게 제공하여 Spark 애플리케이션을 실행할 수 있습니다.
첫 번째 Spark 애플리케이션 실행
EMR Studio 관리자가 Studio, Workspace 및 서버리스 애플리케이션을 생성한 후 Studio 사용자는 Workspace 및 애플리케이션을 사용하여 Spark 워크로드를 개발하고 모니터링할 수 있습니다.
Workspace를 실행하고 서버리스 애플리케이션을 연결합니다.
다음 단계를 완료하십시오.
- EMR Studio 관리자가 제공한 Studio URL을 사용하여 로그인합니다.
emrs-interactive-app-dev-userAWS 계정 관리자가 공유한 사용자 자격 증명.
제공된 CloudFormation 템플릿을 사용하여 필수 리소스를 배포한 경우 입력 매개변수로 제공한 암호를 사용합니다.
에 워크스페이스 페이지에서 Workspace의 상태를 확인할 수 있습니다. 작업공간이 시작되면 상태가 다음으로 변경되는 것을 볼 수 있습니다. 준비된.
- 작업 영역 이름(
My_First_Workspace).
새 탭이 열립니다. 브라우저가 팝업을 허용하는지 확인하세요.
- 작업공간에서 다음을 선택합니다. 계산 (클러스터 아이콘)을 탐색 창에 표시합니다.
- 럭셔리 EMR 서버리스 애플리케이션, 애플리케이션을 선택하세요(
my-serverless-interactive-application). - 럭셔리 대화형 런타임 역할, 대화형 런타임 역할을 선택합니다(이 게시물에서는
emr-serverless-runtime-role). - 왼쪽 메뉴에서 연결 이 작업 공간의 모든 노트북에 대한 컴퓨팅 유형으로 서버리스 애플리케이션을 연결합니다.

Spark 애플리케이션을 대화형으로 실행
다음 단계를 완료하십시오.
- 선택 노트북 샘플 (점 3개 아이콘)을 탐색 창에서 열고 엽니다.
Getting-started-with-emr-serverless공책. - 왼쪽 메뉴에서 작업공간에 저장.
우리 노트북에는 Python 3, PySpark 및 Spark(Scala용)의 세 가지 커널 선택이 있습니다.
- 메시지가 표시되면 파이 스파크 커널로.
- 왼쪽 메뉴에서 선택.

이제 Spark 애플리케이션을 실행할 수 있습니다. 그렇게 하려면 다음을 사용하십시오. %%configure 스파크매직 세션 생성 매개변수를 구성하는 명령입니다. 대화형 애플리케이션은 Python 가상 환경을 지원합니다. 다음을 사용하여 실행기 환경에 대해 다른 Python 런타임에 대한 경로를 지정함으로써 작업자 노드에서 사용자 정의 환경을 사용합니다. spark.executorEnv.PYSPARK_PYTHON. 다음 코드를 참조하십시오.
외부 패키지 설치
이제 작업자를 위한 독립적인 가상 환경이 있으므로 EMR Studio 노트북을 사용하면 Spark를 사용하여 서버리스 애플리케이션 내에서 외부 패키지를 설치할 수 있습니다. install_pypi_package Spark 컨텍스트를 통해 작동합니다. 이 기능을 사용하면 모든 EMR 서버리스 작업자가 패키지를 사용할 수 있습니다.
먼저 PyPi에서 Python 패키지인 matplotlib를 설치합니다.
이전 단계에서 응답하지 않으면 VPC 설정을 확인하고 인터넷 액세스가 올바르게 구성되었는지 확인하십시오.
이제 데이터 세트를 사용하고 데이터를 시각화할 수 있습니다.
시각화 만들기
시각화를 만들기 위해 NYC 노란색 택시에 대한 공개 데이터 세트를 사용합니다.
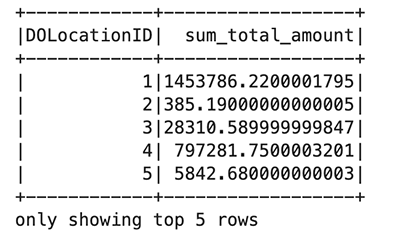
이전 코드 블록에서는 Amazon S3의 퍼블릭 버킷에서 Parquet 파일을 읽었습니다. 파일에는 헤더가 있으며 Spark가 스키마를 추론하기를 원합니다. 그런 다음 Spark 데이터프레임을 사용하여 특정 열을 그룹화하고 계산합니다. taxi_df:
%%display 결과를 테이블 형식으로 보는 마법:

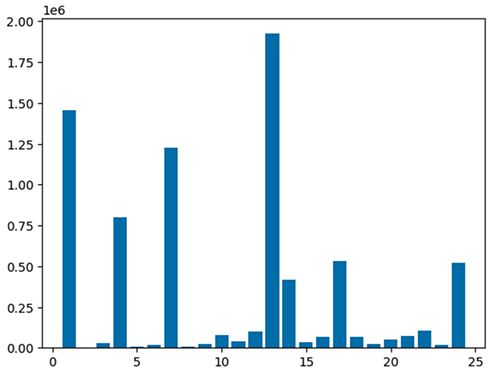
또한 5가지 유형의 차트를 사용하여 데이터를 빠르게 시각화할 수 있습니다. 표시 유형을 선택할 수 있으며 그에 따라 차트가 변경됩니다. 다음 스크린샷에서는 막대 차트를 사용하여 데이터를 시각화합니다.

Spark SQL을 사용하여 EMR 서버리스와 상호 작용
다음에서 테이블과 상호 작용할 수 있습니다. AWS Glue 데이터 카탈로그 EMR 서버리스에서 Spark SQL을 사용합니다. 샘플 노트북에서는 Spark 데이터 프레임을 사용하여 데이터를 변환하는 방법을 보여줍니다.
먼저 택시라는 새 임시 뷰를 만듭니다. 이를 통해 Spark SQL을 사용하여 이 뷰에서 데이터를 선택할 수 있습니다. 그런 다음 추가 처리를 위해 택시 데이터 프레임을 만듭니다.
EMR Studio 노트북의 각 셀에서 다음을 확장할 수 있습니다. 스파크 작업 진행 이 특정 셀을 실행하는 동안 EMR Serverless에 제출된 작업의 다양한 단계를 확인합니다. 각 단계를 완료하는 데 걸린 시간을 확인할 수 있습니다. 다음 예에서 작업의 14단계에는 12개의 완료된 작업이 있습니다. 또한, 장애가 발생한 경우 로그를 볼 수 있으므로 문제 해결이 원활하게 이루어집니다. 이에 대해서는 다음 섹션에서 더 자세히 논의합니다.
![Job[14]: NativeMethodAccessorImpl.java:0의 showString 및 Job[15]: NativeMethodAccessorImpl.java:0의 showString](https://xlera8.com/wp-content/uploads/2024/04/run-interactive-workloads-on-amazon-emr-serverless-from-amazon-emr-studio-amazon-web-services-11.png)
matplotlib 패키지를 사용하여 처리된 데이터 프레임을 시각화하려면 다음 코드를 사용하세요. maptplotlib 라이브러리를 사용하여 하차 위치와 총량을 막대 차트로 표시합니다.
대화형 애플리케이션 진단
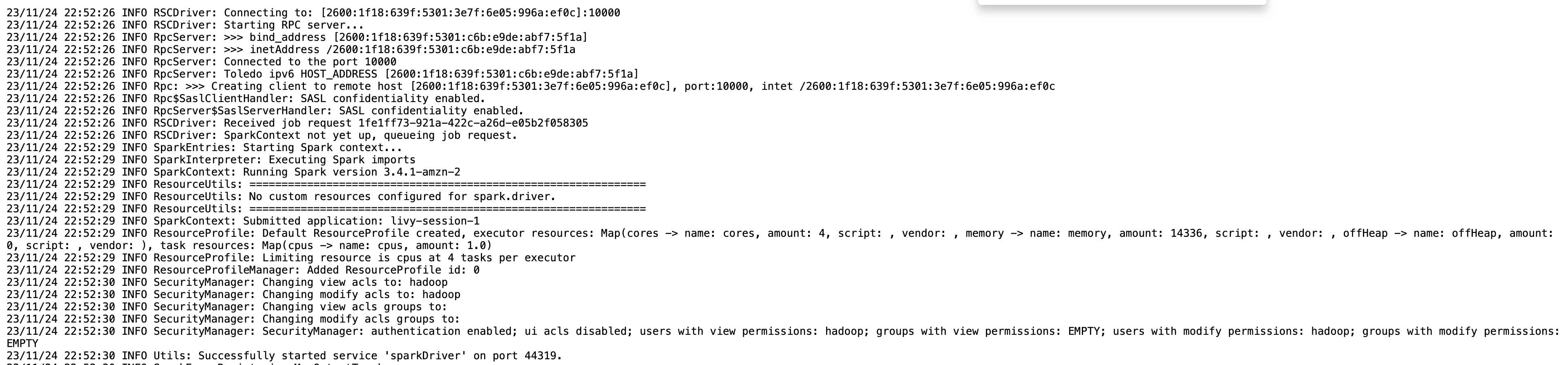
다음을 사용하여 Livy 엔드포인트에 대한 세션 정보를 얻을 수 있습니다. %%info 스파크매직. 그러면 노트북에서 바로 드라이버 로그는 물론 Spark UI에 액세스할 수 있는 링크가 제공됩니다.

다음 스크린샷은 노트북의 링크를 통해 열었던 애플리케이션의 드라이버 로그 조각입니다.
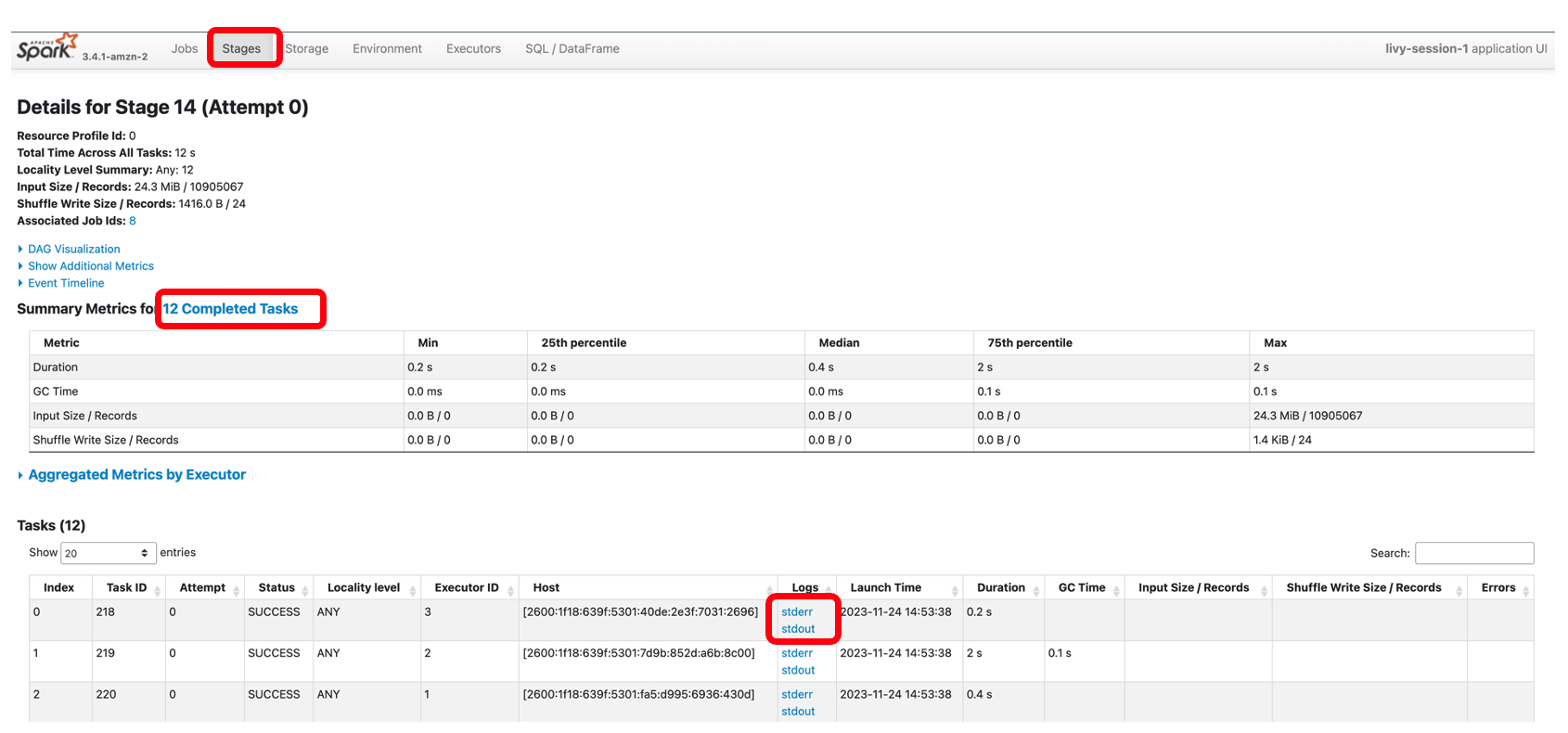
마찬가지로 아래 링크를 선택하시면 됩니다 스파크 UI UI를 엽니다. 다음 스크린샷은 집행자 드라이버 및 실행기 로그에 대한 액세스를 제공하는 탭입니다.

다음 스크린샷은 앞서 본 Spark SQL 단계에 해당하는 14단계를 보여줍니다. 여기서 총 택시 수집의 위치별 합계를 계산했으며 이는 12개 작업으로 분류되었습니다. Spark UI를 통해 대화형 애플리케이션은 세분화된 작업 수준 상태, I/O 및 셔플 세부 정보를 제공할 뿐만 아니라 노트북에서 바로 이 단계의 각 작업에 대한 해당 로그에 대한 링크를 제공하여 원활한 문제 해결 환경을 지원합니다.
정리
이 게시물에서 생성된 리소스를 더 이상 유지하지 않으려면 다음 정리 단계를 완료하세요.
- EMR 서버리스 애플리케이션 삭제.
- EMR Studio와 관련 작업 영역 및 노트북을 삭제합니다..
- 나머지 리소스를 삭제하려면 CloudFormation 콘솔로 이동하여 스택을 선택한 후 ..
삭제 정책이 유지되도록 설정된 S3 버킷을 제외한 모든 리소스가 삭제됩니다.
결론
이 게시물에서는 EMR Serverless를 컴퓨팅으로 사용하여 EMR Studio에서 대화형 PySpark 워크로드를 실행하는 방법을 보여주었습니다. 대화형 JupyterLab Workspace에서 Spark 애플리케이션을 구축하고 모니터링할 수도 있습니다.
다음 게시물에서는 다음과 같은 EMR Serverless Interactive 애플리케이션의 추가 기능에 대해 논의하겠습니다.
- VPC에서 Amazon RDS 및 Amazon Redshift와 같은 리소스 작업(예: JDBC/ODBC 연결용)
- 서버리스 엔드포인트를 사용하여 트랜잭션 워크로드 실행
EMR Studio를 처음 탐색하는 경우 다음을 확인하는 것이 좋습니다. Amazon EMR 워크숍 그리고 참조 EMR 스튜디오 생성.
저자에 관하여
 세카르 스리니바산 그는 데이터 분석 및 AI에 중점을 둔 AWS의 수석 전문가 솔루션 아키텍트입니다. Sekar는 20년 이상의 데이터 작업 경험을 갖고 있습니다. 그는 고객이 아키텍처를 현대화하고 데이터에서 통찰력을 창출하는 확장 가능한 솔루션을 구축하도록 돕는 데 열정을 쏟고 있습니다. 여가 시간에는 소외 계층 아동 교육에 초점을 맞춘 비영리 프로젝트에 참여하는 것을 좋아합니다.
세카르 스리니바산 그는 데이터 분석 및 AI에 중점을 둔 AWS의 수석 전문가 솔루션 아키텍트입니다. Sekar는 20년 이상의 데이터 작업 경험을 갖고 있습니다. 그는 고객이 아키텍처를 현대화하고 데이터에서 통찰력을 창출하는 확장 가능한 솔루션을 구축하도록 돕는 데 열정을 쏟고 있습니다. 여가 시간에는 소외 계층 아동 교육에 초점을 맞춘 비영리 프로젝트에 참여하는 것을 좋아합니다.
 디샤 우마르와니 글로벌 헬스케어 및 생명과학 분야에서 Amazon 전문 서비스를 담당하는 수석 데이터 설계자입니다. 그녀는 고객과 협력하여 대규모 데이터 전략을 설계, 설계 및 구현했습니다. 그녀는 엔터프라이즈 플랫폼용 데이터 메시 아키텍처 설계를 전문으로 합니다.
디샤 우마르와니 글로벌 헬스케어 및 생명과학 분야에서 Amazon 전문 서비스를 담당하는 수석 데이터 설계자입니다. 그녀는 고객과 협력하여 대규모 데이터 전략을 설계, 설계 및 구현했습니다. 그녀는 엔터프라이즈 플랫폼용 데이터 메시 아키텍처 설계를 전문으로 합니다.
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- PlatoData.Network 수직 생성 Ai. 자신에게 권한을 부여하십시오. 여기에서 액세스하십시오.
- PlatoAiStream. 웹3 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 플라톤ESG. 탄소, 클린테크, 에너지, 환경, 태양광, 폐기물 관리. 여기에서 액세스하십시오.
- PlatoHealth. 생명 공학 및 임상 시험 인텔리전스. 여기에서 액세스하십시오.
- 출처: https://aws.amazon.com/blogs/big-data/run-interactive-workloads-on-amazon-emr-serverless-from-amazon-emr-studio/