
Introductie
Kunstmatige intelligentie (AI) heeft aanzienlijke vooruitgang geboekt in verschillende sectoren, en de gezondheidszorg vormt hierop geen uitzondering. Een van de meest veelbelovende gebieden binnen AI in de gezondheidszorg is Natural Language Processing (NLP), dat het potentieel heeft om een revolutie teweeg te brengen in de patiëntenzorg door efficiëntere en nauwkeurigere data-analyse en communicatie mogelijk te maken.
NLP heeft bewezen een gamechanger te zijn op het gebied van de gezondheidszorg. NLP transformeert de manier waarop zorgverleners patiëntenzorg leveren. Van het beheer van de volksgezondheid tot de detectie van ziekten: NLP helpt professionals in de gezondheidszorg weloverwogen beslissingen te nemen en betere behandelresultaten te bieden.
leerdoelen
- Het gebruik van NLP en AI in de gezondheidszorg begrijpen en analyseren
- Grip krijgen op de basisprincipes van NLP
- Kennismaken met enkele veelgebruikte NLP-bibliotheken in de gezondheidszorg
- Leren over de use cases van NLP in de gezondheidszorg
Dit artikel is gepubliceerd als onderdeel van het Data Science-blogathon.
Inhoudsopgave
- De motivatie voor het gebruik van AI en NLP in de gezondheidszorg
- Wat is natuurlijke taalverwerking?
- Verschillende technieken gebruikt in NLP
3.1 Op regels gebaseerde technieken
3.2 Statistische technieken met behulp van Machine Learning-modellen
3.3 Leren overdragen - Verschillende NLP-bibliotheken en hun raamwerken
- Wat zijn grote taalmodellen (LLM)?
- NLP in klinische tekst – De noodzaak van een andere aanpak
- Sommige NLP-bibliotheken die in de gezondheidszorg worden gebruikt
- Inzicht in de klinische datasets
- Wat zijn verschillende soorten klinische gegevens?
- Use Cases en toepassingen van NLP in de gezondheidszorg
- Hoe bouw je een NLP-pijplijn op met klinische tekst?
11.1 Oplossingsontwerp
11.2 Stapsgewijze code - Conclusie
De motivatie voor het gebruik van AI en NLP in de gezondheidszorg
De motivatie voor het gebruik AI en NLP in de gezondheidszorg is geworteld in het verbeteren van de patiëntenzorg en behandelresultaten en het verlagen van de zorgkosten. De zorgsector genereert enorme hoeveelheden gegevens, waaronder EPD’s, klinische aantekeningen en gezondheidsgerelateerde posts op sociale media, die waardevolle inzichten kunnen verschaffen in de gezondheid van patiënten en de behandelresultaten. Veel van deze gegevens zijn echter ongestructureerd en moeilijk handmatig te analyseren.
Bovendien wordt de gezondheidszorgsector geconfronteerd met verschillende uitdagingen, zoals een vergrijzende bevolking, een toenemend aantal chronische ziekten en een tekort aan beroepsbeoefenaren in de gezondheidszorg.
Deze uitdagingen hebben geleid tot een groeiende behoefte aan een efficiëntere en effectievere gezondheidszorg.
Door waardevolle inzichten uit ongestructureerde medische gegevens te verschaffen, kan NLP helpen de patiëntenzorg en behandelresultaten te verbeteren en zorgverleners te ondersteunen bij het nemen van beter geïnformeerde klinische beslissingen.
Wat is natuurlijke taalverwerking?
Natural Language Processing (NLP) is een deelgebied van de kunstmatige intelligentie (AI) dat zich bezighoudt met de interactie tussen computers en menselijke talen. Het maakt gebruik van computationele technieken om menselijke taal te analyseren, begrijpen en genereren. NLP wordt in veel toepassingen gebruikt, waaronder spraakherkenning, automatische vertaling, sentimentanalyse en tekstsamenvatting.
We zullen nu de verschillende NLP-technieken, bibliotheken en raamwerken verkennen.
Verschillende technieken gebruikt in NLP
Er zijn twee veelgebruikte technieken die in de NLP-industrie worden gebruikt.
1. Op regels gebaseerde technieken: vertrouw op vooraf gedefinieerde grammaticaregels en woordenboeken
2. Statistische technieken: gebruik machine learning-algoritmen om taal te analyseren en te begrijpen
3. Groot taalmodel gebruiken Transfer leren
Hier is een standaard NLP Pipeline met verschillende NLP-taken
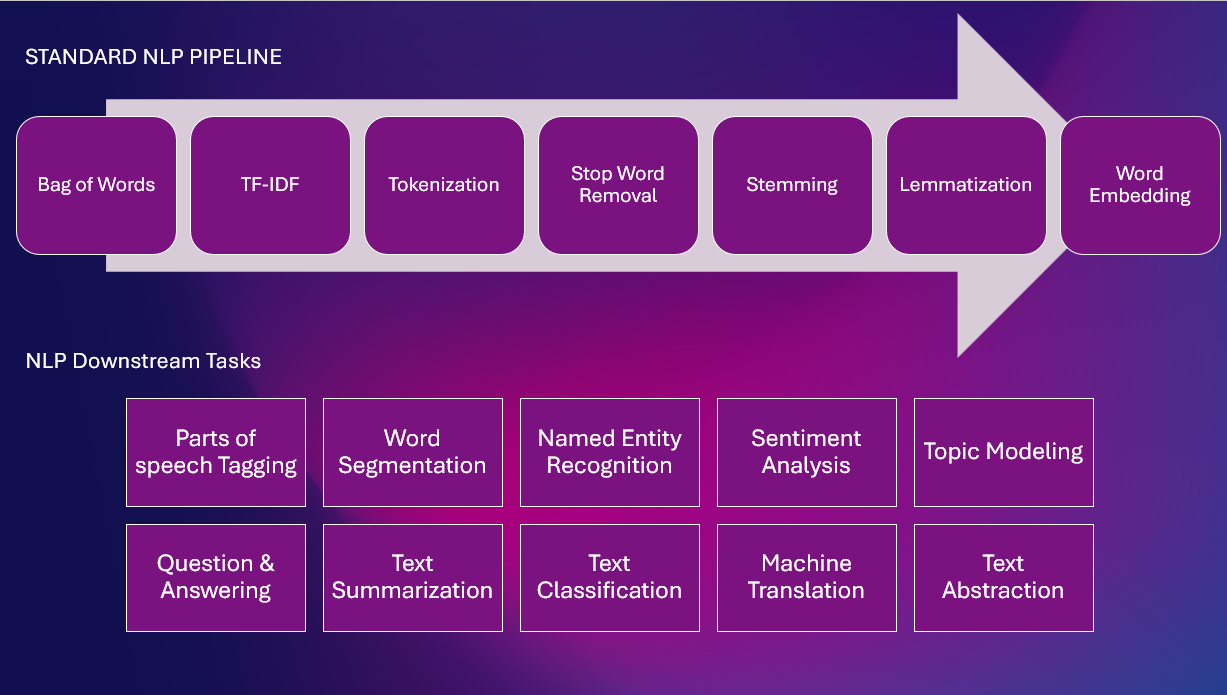
Op regels gebaseerde technieken
Deze technieken omvatten het creëren van een reeks handgemaakte regels of patronen om betekenisvolle informatie uit tekst te halen. Op regels gebaseerde systemen werken doorgaans door specifieke patronen te definiëren die overeenkomen met de doelinformatie, zoals benoemde entiteiten of specifieke trefwoorden, en vervolgens die informatie te extraheren op basis van die patronen. Op regels gebaseerde systemen zijn snel, betrouwbaar en eenvoudig, maar worden beperkt door de kwaliteit en het aantal gedefinieerde regels, en kunnen moeilijk te onderhouden en bij te werken zijn.
Er zou bijvoorbeeld een op regels gebaseerd systeem voor de herkenning van benoemde entiteiten kunnen worden ontworpen om eigennamen in tekst te identificeren en deze te categoriseren in vooraf gedefinieerde entiteitstypen, zoals een persoon, locatie, organisatie, ziekte, medicijnen, enz. Het systeem zou een reeks gebruiken van regels om patronen in de tekst te identificeren die overeenkomen met de criteria voor elk entiteitstype, zoals hoofdlettergebruik voor persoonsnamen of specifieke trefwoorden voor organisaties.
Statistische technieken met behulp van machine learning-modellen
Deze technieken maken gebruik van statistische algoritmen om patronen in de gegevens te leren en op basis van die patronen voorspellingen te doen. Machine learning-modellen kunnen worden getraind op grote hoeveelheden geannoteerde gegevens, waardoor ze flexibeler en schaalbaarder worden dan op regels gebaseerde systemen. Er worden verschillende soorten machine learning-modellen gebruikt in NLP, waaronder Beslissingsbomen, willekeurige bossen, ondersteuning van vectormachines en neurale netwerken.
Een machine learning-model voor sentimentanalyse kan bijvoorbeeld worden getraind op een groot corpus van geannoteerde tekst, waarbij elke tekst wordt getagd als positief, negatief of neutraal. Het model zou de statistische patronen in de gegevens leren kennen die onderscheid maken tussen positieve en negatieve tekst en die patronen vervolgens gebruiken om voorspellingen te doen over nieuwe, onzichtbare tekst. Het voordeel van deze aanpak is dat het model sentimentpatronen kan leren identificeren die niet expliciet in de regels zijn gedefinieerd.
Transfer leren
Deze technieken vormen een hybride aanpak die de sterke punten van op regels gebaseerde en machine-learning-modellen combineert. Transfer learning maakt gebruik van een vooraf getraind machine learning-model, zoals een taalmodel dat is getraind op een groot tekstcorpus, als uitgangspunt voor het verfijnen van een specifieke taak of domein. Deze aanpak maakt gebruik van de algemene kennis die is geleerd uit het vooraf getrainde model, waardoor de hoeveelheid gelabelde gegevens die nodig zijn voor training wordt verminderd en snellere en nauwkeurigere voorspellingen over een specifieke taak mogelijk worden gemaakt.
Een transfer learning-aanpak voor de herkenning van benoemde entiteiten zou bijvoorbeeld een vooraf getraind taalmodel kunnen verfijnen op een kleiner corpus van geannoteerde medische teksten. Het model zou beginnen met de algemene kennis die is geleerd van het vooraf getrainde model en vervolgens de gewichten aanpassen om beter aan te sluiten bij de patronen van de medische tekst. Deze aanpak zou de hoeveelheid gelabelde gegevens die nodig zijn voor training verminderen en resulteren in een nauwkeuriger model voor herkenning van benoemde entiteiten in het medische domein.
Verschillende NLP-bibliotheken en hun raamwerken
Verschillende bibliotheken bieden een breed scala aan NLP-functionaliteiten. Zoals :

Natural Language Processing (NLP)-bibliotheken en -frameworks zijn softwaretools die helpen bij het ontwikkelen en implementeren van NLP-applicaties. Er zijn verschillende NLP-bibliotheken en -frameworks beschikbaar, elk met sterke en zwakke punten en aandachtsgebieden.
Deze tools variëren in termen van de complexiteit van de algoritmen die ze ondersteunen, de omvang van de modellen die ze aankunnen, het gebruiksgemak en de mate van aanpassing die ze mogelijk maken.
Wat zijn grote taalmodellen (LLM)?
Grote taalmodellen worden getraind op enorme hoeveelheden gegevens. Kan mensachtige tekst genereren en een breed scala aan NLP-taken met hoge nauwkeurigheid uitvoeren.
Hier zijn enkele voorbeelden van grote taalmodellen en een korte beschrijving van elk:
GPT-3 (Generatieve voorgetrainde transformator 3): GPT-3, ontwikkeld door OpenAI, is een groot, op transformatoren gebaseerd taalmodel dat deep learning-algoritmen gebruikt om mensachtige tekst te genereren. Het is getraind op een enorm corpus aan tekstgegevens, waardoor het op basis van een prompt coherente en contextueel passende tekstreacties kan genereren.
BERT (Bidirectionele encoderrepresentaties van transformatoren): BERT is ontwikkeld door Google en is een op transformatoren gebaseerd taalmodel dat vooraf is getraind op een groot corpus aan tekstgegevens. Het is ontworpen om goed te presteren bij een breed scala aan NLP-taken, zoals herkenning van benoemde entiteiten, het beantwoorden van vragen en tekstclassificatie, door de context en relaties tussen woorden in een zin te coderen.
RoBERTa (Robuust geoptimaliseerde BERT-aanpak): RoBERTa is ontwikkeld door Facebook AI en is een variant van BERT die is verfijnd en geoptimaliseerd voor NLP-taken. Het is getraind op een groter corpus tekstgegevens en gebruikt een andere trainingsstrategie dan BERT, wat leidt tot betere prestaties op NLP-benchmarks.
ELMo (inbedding van taalmodellen): ELMo is ontwikkeld door het Allen Institute for AI en is een diep gecontextualiseerd woordrepresentatiemodel dat een bidirectioneel LSTM-netwerk (Long Short-Term Memory) gebruikt om taalrepresentaties te leren uit een groot corpus aan tekstgegevens. ELMo kan worden verfijnd voor specifieke NLP-taken of worden gebruikt als feature-extractor voor andere machine-learning-modellen.
ULMFiT (verfijning van het universele taalmodel): ULMFiT, ontwikkeld door FastAI, is een overdrachtsleermethode die een vooraf getraind taalmodel verfijnt op een specifieke NLP-taak met behulp van een kleine hoeveelheid taakspecifieke geannoteerde gegevens. ULMFiT heeft state-of-the-art prestaties geleverd op een breed scala aan NLP-benchmarks en wordt beschouwd als een toonaangevend voorbeeld van transferleren in NLP.
NLP in klinische tekst: de noodzaak van een andere aanpak
Klinische teksten zijn vaak ongestructureerd en bevatten veel medisch jargon en acroniemen, waardoor traditionele NLP-modellen moeilijk te begrijpen en te verwerken zijn. Bovendien bevat klinische tekst vaak belangrijke informatie, zoals ziekte, medicijnen, patiëntinformatie, diagnoses en behandelplannen, waarvoor gespecialiseerde NLP-modellen nodig zijn die deze medische informatie nauwkeurig kunnen extraheren en begrijpen.
Een andere reden waarom klinische teksten verschillende NLP-modellen nodig hebben, is dat deze een grote hoeveelheid gegevens bevatten, verspreid over verschillende bronnen, zoals EPD's, klinische aantekeningen en radiologische rapporten, die geïntegreerd moeten worden. Dit vereist modellen die de tekst kunnen verwerken en begrijpen en de gegevens uit verschillende bronnen kunnen koppelen en integreren en klinisch aanvaardbare relaties kunnen leggen.
Ten slotte bevat klinische tekst vaak gevoelige patiëntinformatie en moet deze worden beschermd door strikte regelgeving zoals HIPAA. NLP-modellen die worden gebruikt om klinische tekst te verwerken, moeten gevoelige patiëntinformatie kunnen identificeren en beschermen en tegelijkertijd nuttige inzichten kunnen bieden.
Sommige NLP-bibliotheken die in de gezondheidszorg worden gebruikt
De tekstuele gegevens binnen de geneeskunde vereisen een gespecialiseerd Natural Language Processing (NLP)-systeem dat medische informatie uit verschillende bronnen kan halen, zoals klinische teksten en andere medische documenten.
Hier is een lijst met NLP-bibliotheken en -modellen die specifiek zijn voor het medische domein:
ruim: Het is een open-source NLP-bibliotheek die kant-en-klare modellen biedt voor verschillende domeinen, waaronder het medische domein.
ScispaCy: Een gespecialiseerde versie van spaCy die specifiek is getraind op wetenschappelijke en biomedische tekst, waardoor deze ideaal is voor het verwerken van medische tekst.
BioBERT: Een vooraf getraind, op transformatoren gebaseerd model, speciaal ontworpen voor het biomedische domein. Het is vooraf getraind met Wiki + Boeken + PubMed + PMC.
KlinischBERT: Een ander vooraf getraind model dat is ontworpen om klinische aantekeningen en ontslagsamenvattingen uit de MIMIC-III-database te verwerken.
Med7: Een op transformatoren gebaseerd model dat is getraind in elektronische medische dossiers (EPD) om zeven belangrijke klinische concepten te extraheren, waaronder diagnose, medicatie en laboratoriumtests.
DisMod-ML: Een probabilistisch modelleringsraamwerk voor ziektemodellering dat NLP-technieken gebruikt om medische tekst te verwerken.
MEDISCH: Een op regels gebaseerd NLP-systeem voor het extraheren van medische informatie uit tekst.
Dit zijn enkele van de populaire NLP-bibliotheken en -modellen die specifiek zijn ontworpen voor het medische domein. Ze bieden een scala aan functies, van vooraf getrainde modellen tot op regels gebaseerde systemen, en kunnen zorgorganisaties helpen medische tekst effectief te verwerken.
In ons NER-model zullen we spaCy en Scispacy gebruiken. Deze bibliotheken zijn relatief eenvoudig te gebruiken op Google Colab of op de lokale infrastructuur.
De BioBERT en ClinicalBERT resource-intensieve grote taalmodellen hebben GPU's en een hogere infrastructuur nodig.
Inzicht in de klinische datasets
Medische tekstgegevens kunnen worden verkregen uit verschillende bronnen, zoals elektronische medische dossiers (EPD's), medische tijdschriften, klinische aantekeningen, medische websites en databases. Sommige van deze bronnen bieden openbaar beschikbare datasets die kunnen worden gebruikt voor het trainen van NLP-modellen, terwijl andere mogelijk goedkeuring en ethische overwegingen vereisen voordat toegang tot de gegevens wordt verkregen. De bronnen van medische tekstgegevens zijn onder meer:
1. Open-source medische corpora zoals de MIMIC-III-database is een grote, openlijk toegankelijke database met elektronische medische dossiers (EPD's) van patiënten die tussen 2001 en 2012 zorg hebben ontvangen in het Beth Israel Deaconess Medical Center. De database bevat informatie zoals demografische gegevens van patiënten, vitale functies, laboratoriumtests, medicijnen, procedures en aantekeningen van beroepsbeoefenaren in de gezondheidszorg, zoals verpleegkundigen en artsen. Daarnaast bevat de database informatie over het verblijf van patiënten op de IC, inclusief het type ICU, de duur van het verblijf en de uitkomsten. De gegevens in MIMIC-III zijn geanonimiseerd en kunnen worden gebruikt voor onderzoeksdoeleinden ter ondersteuning van de ontwikkeling van voorspellende modellen en klinische beslissingsondersteunende systemen.
2. De Nationale Bibliotheek voor Geneeskunde ClinicalTrials.gov website bevat klinische onderzoeksgegevens en ziektesurveillancegegevens.
3. National Institutes of Health's National Library of Medicine, Nationale Centra voor Biotechnologische Informatie (NCBI), en de Wereldgezondheidsorganisatie (WIE)
4. Zorginstellingen en organisaties zoals ziekenhuizen, klinieken en farmaceutische bedrijven genereren grote hoeveelheden medische tekstgegevens via elektronische medische dossiers, klinische aantekeningen, medische transcripties en medische rapporten.
5. Medische onderzoekstijdschriften en databases, zoals PubMed en CINAHL, bevatten enorme hoeveelheden gepubliceerde medische onderzoeksartikelen en samenvattingen.
6. Socialemediaplatforms zoals Twitter kunnen realtime inzicht bieden in de perspectieven van patiënten, medicijnrecensies en ervaringen.
Om NLP-modellen te trainen met behulp van medische tekstgegevens, is het belangrijk om rekening te houden met de kwaliteit en relevantie van de gegevens en ervoor te zorgen dat deze op de juiste manier worden voorbewerkt en opgemaakt. Bovendien is het belangrijk om ethische en juridische overwegingen in acht te nemen bij het werken met gevoelige medische informatie.
Wat zijn verschillende soorten klinische gegevens?
In de gezondheidszorg worden verschillende soorten klinische gegevens vaak gebruikt:

Klinische gegevens verwijzen naar informatie over de gezondheidszorg van individuen, waaronder de medische geschiedenis van de patiënt, diagnoses, behandelingen, laboratoriumresultaten, beeldvormende onderzoeken en andere relevante gezondheidsinformatie.
EPD/EMR-gegevens zijn gekoppeld aan demografische gegevens (dit omvat persoonlijke informatie zoals leeftijd, geslacht, etniciteit en contactgegevens). Door patiënten gegenereerde gegevens (dit soort gegevens wordt door patiënten zelf gegenereerd, inclusief informatie verzameld via door de patiënt gerapporteerde uitkomstmaten en patiëntgegevens). -gegenereerde gezondheidsgegevens.)
Andere gegevenssets zijn:
Genomische gegevens: Dit type heeft betrekking op de genetische informatie van een individu, inclusief DNA-sequenties en markers.
Gegevens van draagbare apparaten: Deze gegevens omvatten informatie die is verzameld via draagbare apparaten zoals fitnesstrackers en hartmonitors.
Elk type klinische gegevens speelt een unieke rol bij het bieden van een alomvattend beeld van de gezondheid van een patiënt en wordt op verschillende manieren door zorgverleners en onderzoekers gebruikt om de patiëntenzorg te verbeteren en behandelbeslissingen te onderbouwen.
Use Cases en toepassingen van NLP in de gezondheidszorg
Natural Language Processing (NLP) is op grote schaal toegepast in de gezondheidszorg en kent verschillende gebruiksscenario's. Enkele van de prominente zijn onder meer:
Bevolking Gezondheid: NLP kan worden gebruikt om grote hoeveelheden ongestructureerde medische gegevens, zoals medische dossiers, enquêtes en claimgegevens, te verwerken om patronen, correlaties en inzichten te identificeren. Dit helpt bij het monitoren van de volksgezondheid en het vroegtijdig opsporen van ziekten.
Patiëntenzorg: NLP kan worden gebruikt om de elektronische medische dossiers (EPD's) van patiënten te verwerken om essentiële informatie zoals diagnose, medicijnen en symptomen te extraheren. Deze informatie kan worden gebruikt om de patiëntenzorg te verbeteren en een gepersonaliseerde behandeling te bieden.
Ziekte Detectie: NLP kan worden gebruikt om grote hoeveelheden tekstgegevens, zoals wetenschappelijke artikelen, nieuwsartikelen en posts op sociale media, te verwerken om uitbraken van infectieziekten op te sporen.
Klinisch beslissingsondersteuningssysteem (CDSS): NLP kan worden gebruikt om de elektronische medische dossiers van patiënten te analyseren om zorgverleners realtime beslissingsondersteuning te bieden. Dit helpt bij het bieden van de best mogelijke behandelingsopties en het verbeteren van de algehele kwaliteit van de zorg.
Klinische proef: NLP kan klinische onderzoeksgegevens verwerken om correlaties en potentiële nieuwe behandelingen te identificeren.
Bijwerkingen van medicijnen: NLP kan worden gebruikt om grote hoeveelheden gegevens over de veiligheid van geneesmiddelen te verwerken om bijwerkingen en geneesmiddelinteracties te identificeren.
Precisiegezondheid: NLP kan worden gebruikt om genomische gegevens en medische dossiers te verwerken om gepersonaliseerde behandelingsopties voor individuele patiënten te identificeren.
Verbetering van de efficiëntie van medische professionals: NLP kan routinetaken zoals medische codering, gegevensinvoer en claimverwerking automatiseren, waardoor medische professionals zich kunnen concentreren op het bieden van betere patiëntenzorg.
Dit zijn slechts enkele voorbeelden van hoe NLP een revolutie teweegbrengt in de gezondheidszorg. Naarmate de NLP-technologie zich blijft ontwikkelen, kunnen we in de toekomst meer innovatieve toepassingen van NLP in de gezondheidszorg verwachten.
Hoe bouw je een NLP-pijplijn op met klinische tekst?
We zullen stapsgewijs een Spacy-pijplijn ontwikkelen met behulp van het SciSpacy NER-model voor klinische tekst.
Objectief: Dit project heeft tot doel een NLP-pijplijn te bouwen met behulp van SciSpacy om op maat gemaakte Named Entity Recognition uit te voeren op klinische teksten.
Resultaat: Het resultaat is het extraheren van informatie over ziekten, medicijnen en medicijndoses uit klinische tekst, die vervolgens kan worden gebruikt in verschillende NLP-downstream-toepassingen.
Oplossingsontwerp:
Hier is de oplossing op hoog niveau om entiteitsinformatie uit klinische tekst te extraheren. NER-extractie is een belangrijke NLP-taak die in de meeste NLP-pijplijnen wordt gebruikt.
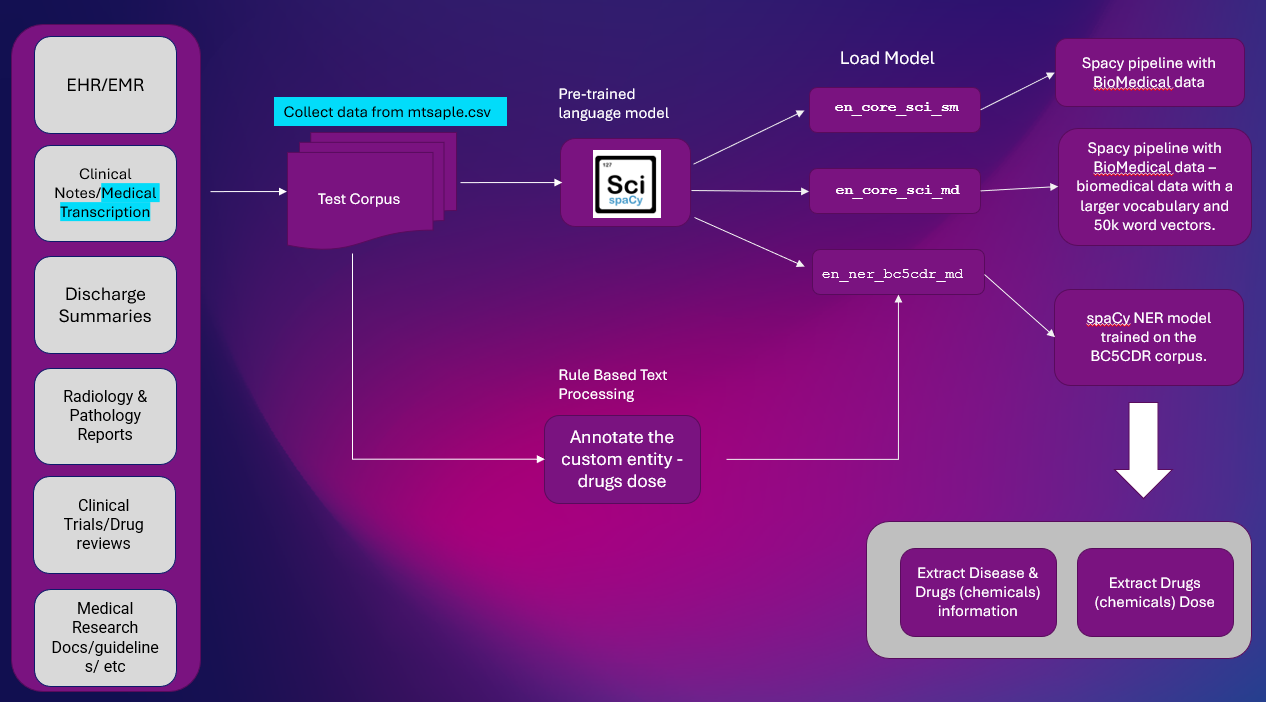
Platform: Google Colab
NLP-bibliotheken: spaCy & SciSpacy
Gegevensset: mtsample.csv (gegevens verwijderd van mtsample).
We hebben gebruikt ScispaCy vooraf getraind NER-model nl_ner_bc5cdr_md-0.5.1 om ziekten en medicijnen te extraheren. Geneesmiddelen worden gewonnen als chemicaliën.
en_ner_bc5cdr_md-0.5.1 is een spaCy-model voor herkenning van benoemde entiteiten (NER) in het biomedische domein.
De “bc5cdr” verwijst naar de BC5CDR corpus, een biomedisch tekstcorpus dat wordt gebruikt om het model te trainen. De ‘md’ in de naam verwijst naar het biomedische domein. De “0.5.1” in de naam verwijst naar de versie van het model.
We zullen de voorbeeldtranscriptietekst van mtsample.csv gebruiken en aantekeningen maken met behulp van een op regels gebaseerd patroon om medicijndoses te extraheren.
Stapsgewijze code:
Installeer spacy- en scispacy-pakketten. spaCy-modellen zijn ontworpen om specifieke NLP-taken uit te voeren, zoals tokenisatie, tagging van deel-van-spraak en herkenning van benoemde entiteiten.
!pip install -U spacy !pip install scispacy
Installeer scispacy-basismodellen en NER-modellen
Het en_ner_bc5cdr_md-0.5.1-model is specifiek ontworpen om genoemde entiteiten in biomedische teksten, zoals ziekten, genen en medicijnen, als chemicaliën te herkennen.
Dit model kan nuttig zijn voor NLP-taken in het biomedische domein, zoals informatie-extractie, tekstclassificatie en het beantwoorden van vragen.
!pip install https://s3-us-west-2.amazonaws.com/ai2-s2-scispacy/releases/v0.5.1/en_core_sci_sm-0.5.1.tar.gz !pip install https://s3-us-west-2.amazonaws.com/ai2-s2-scispacy/releases/v0.5.1/en_core_sci_md-0.5.1.tar.gz !pip install https://s3-us-west-2.amazonaws.com/ai2-s2-scispacy/releases/v0.5.1/en_ner_bc5cdr_md-0.5.1.tar.gz
Installeer andere pakketten
pip installatie render
Pakketten importeren
import scispacy import spacy #Core-modellen import en_core_sci_sm importeer en_core_sci_md
#NER specifieke modellen importeren en_ner_bc5cdr_md #Tools voor het extraheren en weergeven van gegevens uit spacy import displacy import panda's als pd
Python-code:
Test de modellen met voorbeeldgegevens
# Kies de specifieke transcriptie die u wilt gebruiken (rij 3, kolom "transcriptie") en test de scispacy NER-modeltekst = mtsample_df.loc[10, "transcriptie"]

Laad specifiek model: en_core_sci_sm en geef tekst door
nlp_sm = en_core_sci_sm.load() doc = nlp_sm(tekst)
#Displayresultaat
entiteitsextractie displacy_image = displacy.render(doc, jupyter=True,style='ent')

Let op: de entiteit is hier getagd. Meestal medische termen. Dit zijn echter generieke entiteiten.
Laad nu het specifieke model: en_core_sci_md en geef tekst door
nlp_md = en_core_sci_md.load() doc = nlp_md(tekst)
#Geef resulterende entiteitsextractie weer
displacy_image = displacy.render(doc, jupyter=True,style='ent')

Deze keer worden de getallen ook als entiteiten getagd door en_core_sci_md.
Laad nu een specifiek model: importeer en_ner_bc5cdr_md en geef tekst door
nlp_bc = en_ner_bc5cdr_md.load() doc = nlp_bc(text) #Display resulterende entiteitsextractie displacy_image = displacy.render(doc, jupyter=True,style='ent')

Nu zijn twee medische entiteiten getagd: ziekte en chemische (medicijnen).
Geef de entiteit weer
print("TEXT", "START", "END", "ENTITY TYPE") voor ent in doc.ents: print(ent.text, ent.start_char, ent.end_char, ent.label_)
TEKST BEGIN EINDE ENTITEITSTYPE
Morbide obesitas 26 40 ZIEKTE
Morbide obesitas 70 84 ZIEKTE
gewichtsverlies 400 411 ZIEKTE
Marcaine 1256 1264 CHEMISCH
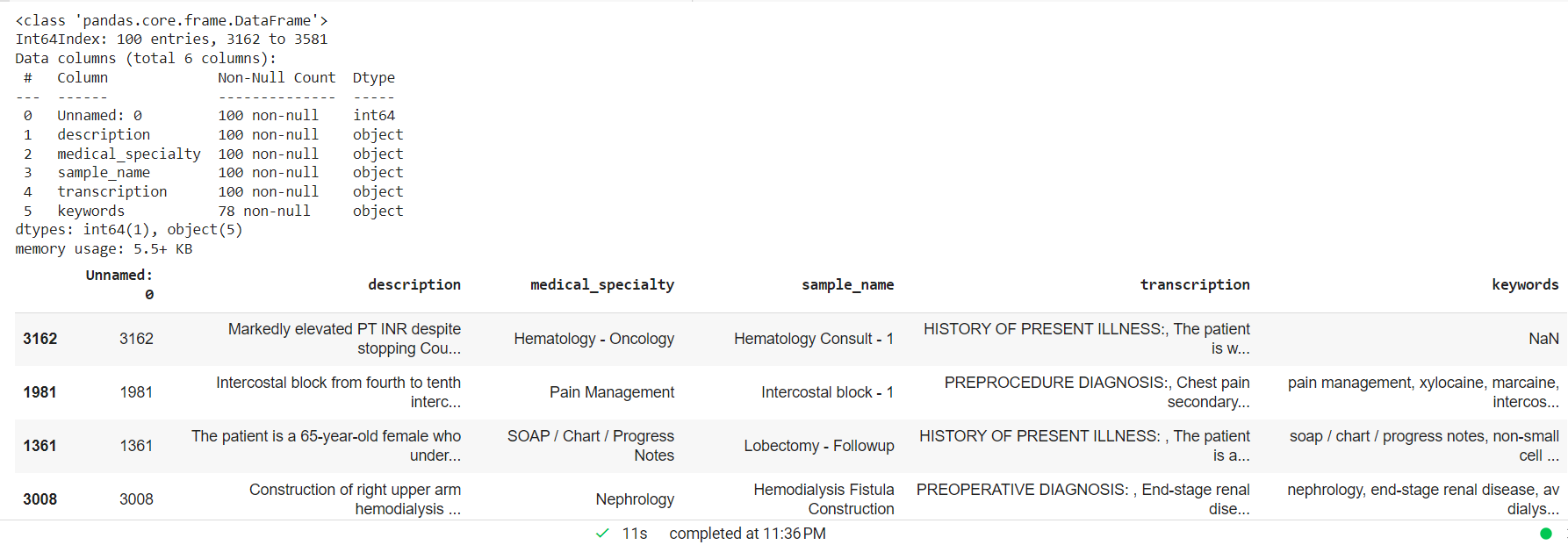
Verwerk de klinische tekst, laat NAN-waarden vallen en maak een willekeurige kleinere steekproef voor het aangepaste entiteitsmodel.
mtsample_df.dropna(subset=['transcriptie'], inplace=True) mtsample_df_subset = mtsample_df.sample(n=100, vervangen=False, random_state=42) mtsample_df_subset.info() mtsample_df_subset.head()
spaCy-matcher – De op regels gebaseerde matching lijkt op het gebruik van reguliere expressies, maar spaCy biedt aanvullende mogelijkheden. Door de tokens en relaties in een document te gebruiken, kunt u met behulp van NER-modellen patronen identificeren die entiteiten omvatten. Het doel is om de namen van medicijnen en hun doseringen uit de tekst te lokaliseren, wat zou kunnen helpen medicatiefouten op te sporen door ze te vergelijken met standaarden en richtlijnen.
Het doel is om de namen van medicijnen en hun doseringen uit de tekst te lokaliseren, wat zou kunnen helpen medicatiefouten op te sporen door ze te vergelijken met standaarden en richtlijnen.
van spacy.matcher importeer Matcher
patroon = [{'ENT_TYPE':'CHEMICAL'}, {'LIKE_NUM': True}, {'IS_ASCII': True}] matcher = Matcher(nlp_bc.vocab) matcher.add("DRUG_DOSE", [patroon])
voor transcriptie in mtsample_df_subset['transcription']: doc = nlp_bc(transcription) matches = matcher(doc) voor match_id, start, end in matches: string_id = nlp_bc.vocab.strings[match_id] # get string representatie span = doc[start :end] # de overeenkomende reeks waarbij medicijndoses worden toegevoegd print(span.text, start, end, string_id,) #Voeg ziekte en medicijnen toe voor ent in doc.ents: print(ent.text, ent.start_char, ent.end_char, ent .etiket_)
In de uitvoer worden de entiteiten weergegeven die uit het klinische tekstvoorbeeld zijn geëxtraheerd.
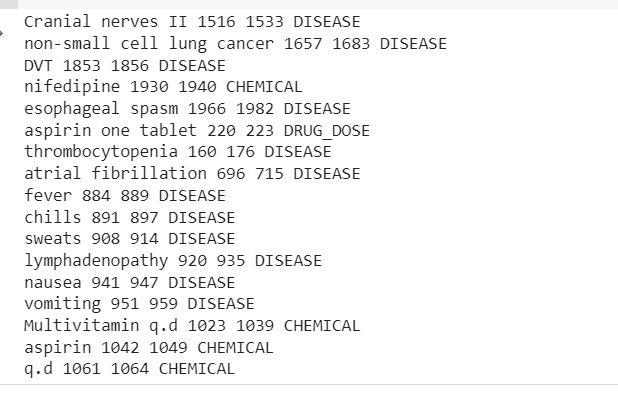
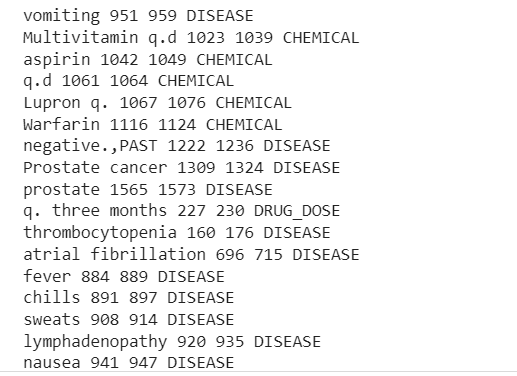
Nu kunnen we zien hoe de pijpleiding wordt uitgegraven Ziekte, medicijnen (chemicaliën) en medicijnendoses informatie uit de klinische tekst.
Er is enige misclassificatie, maar we kunnen de prestaties van het model verbeteren door meer gegevens te gebruiken.
We kunnen deze medische entiteiten nu gebruiken voor verschillende taken, zoals ziektedetectie, voorspellende analyse, ondersteunend systeem voor klinische besluitvorming, classificatie van medische teksten, samenvattingen, het beantwoorden van vragen en nog veel meer.
Conclusie
1. In dit artikel hebben we enkele van de belangrijkste kenmerken van NLP in de gezondheidszorg onderzocht, die zullen helpen de complexe tekstgegevens over de gezondheidszorg te begrijpen.
We hebben ook scispaCy en spaCy geïmplementeerd en een eenvoudig, op maat gemaakt NER-model gebouwd via een vooraf getraind NER-model en op regels gebaseerde matcher. Hoewel we slechts één NER-model hebben besproken, zijn er nog talloze andere beschikbaar en is er een enorme hoeveelheid extra functionaliteit te ontdekken.
2. Binnen het scispaCy-framework zijn er talloze aanvullende technieken om te verkennen, waaronder methoden voor het detecteren van afkortingen, het uitvoeren van afhankelijkheidsanalyse en het identificeren van individuele zinnen.
3. De nieuwste trends in NLP voor de gezondheidszorg omvatten de ontwikkeling van domeinspecifieke modellen zoals BioBERT en ClinicalBert en het gebruik van grote taalmodellen zoals GPT-3. Deze modellen bieden een hoge mate van nauwkeurigheid en efficiëntie, maar het gebruik ervan roept ook zorgen op over vooringenomenheid, privacy en controle over gegevens.
ChatGPT (een geavanceerd conversational AI-model ontwikkeld door OpenAI) maakt nu al een enorme impact in de NLP-wereld. Het model is getraind op een enorme hoeveelheid tekstgegevens van internet en heeft de mogelijkheid om mensachtige tekstreacties te genereren op basis van de invoer die het ontvangt. Het kan worden gebruikt voor verschillende taken, zoals het beantwoorden van vragen, samenvattingen, vertalingen en meer. Het model is ook afgestemd op specifieke gebruiksscenario's, zoals het genereren van code of het schrijven van artikelen, om de prestaties op die specifieke gebieden te verbeteren.
5. Ondanks de talrijke voordelen is NLP in de gezondheidszorg echter niet zonder uitdagingen. Het waarborgen van de nauwkeurigheid en eerlijkheid van NLP-modellen en het overwinnen van zorgen over gegevensprivacy zijn enkele van de uitdagingen die moeten worden aangepakt om het potentieel van NLP in de gezondheidszorg volledig te realiseren.
6. Vanwege de vele voordelen is het essentieel voor professionals in de gezondheidszorg om NLP te omarmen en in hun werkprocessen op te nemen. Hoewel er veel uitdagingen te overwinnen zijn, is NLP in de gezondheidszorg zeker een trend die de moeite waard is om te bekijken en om in te investeren.
De in dit artikel getoonde media zijn geen eigendom van Analytics Vidhya en worden naar goeddunken van de auteur gebruikt.
Verwant
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- Platoblockchain. Web3 Metaverse Intelligentie. Kennis versterkt. Toegang hier.
- Bron: https://www.analyticsvidhya.com/blog/2023/02/extracting-medical-information-from-clinical-text-with-nlp/