
Introductie
Machine Learning (ML) is een studiegebied dat zich richt op het ontwikkelen van algoritmen om automatisch te leren van gegevens, voorspellingen te doen en patronen af te leiden zonder dat expliciet wordt verteld hoe dat moet. Het doel is om systemen te creëren die automatisch verbeteren met ervaring en gegevens.
Dit kan worden bereikt door middel van gesuperviseerd leren, waarbij het model wordt getraind met behulp van gelabelde gegevens om voorspellingen te doen, of door ongecontroleerd leren, waarbij het model patronen of correlaties binnen de gegevens probeert te ontdekken zonder specifieke doeloutputs om op te anticiperen.
ML is uitgegroeid tot een onmisbaar en veelgebruikt hulpmiddel in verschillende disciplines, waaronder informatica, biologie, financiën en marketing. Het heeft zijn nut bewezen in diverse toepassingen, zoals beeldclassificatie, natuurlijke taalverwerking en fraudedetectie.
Taken voor machinaal leren
Machine learning kan grofweg worden ingedeeld in drie hoofdtaken:
- Leren onder toezicht
- Niet-gecontroleerd leren
- Versterking leren
Hier zullen we ons concentreren op de eerste twee gevallen.
Leren onder toezicht
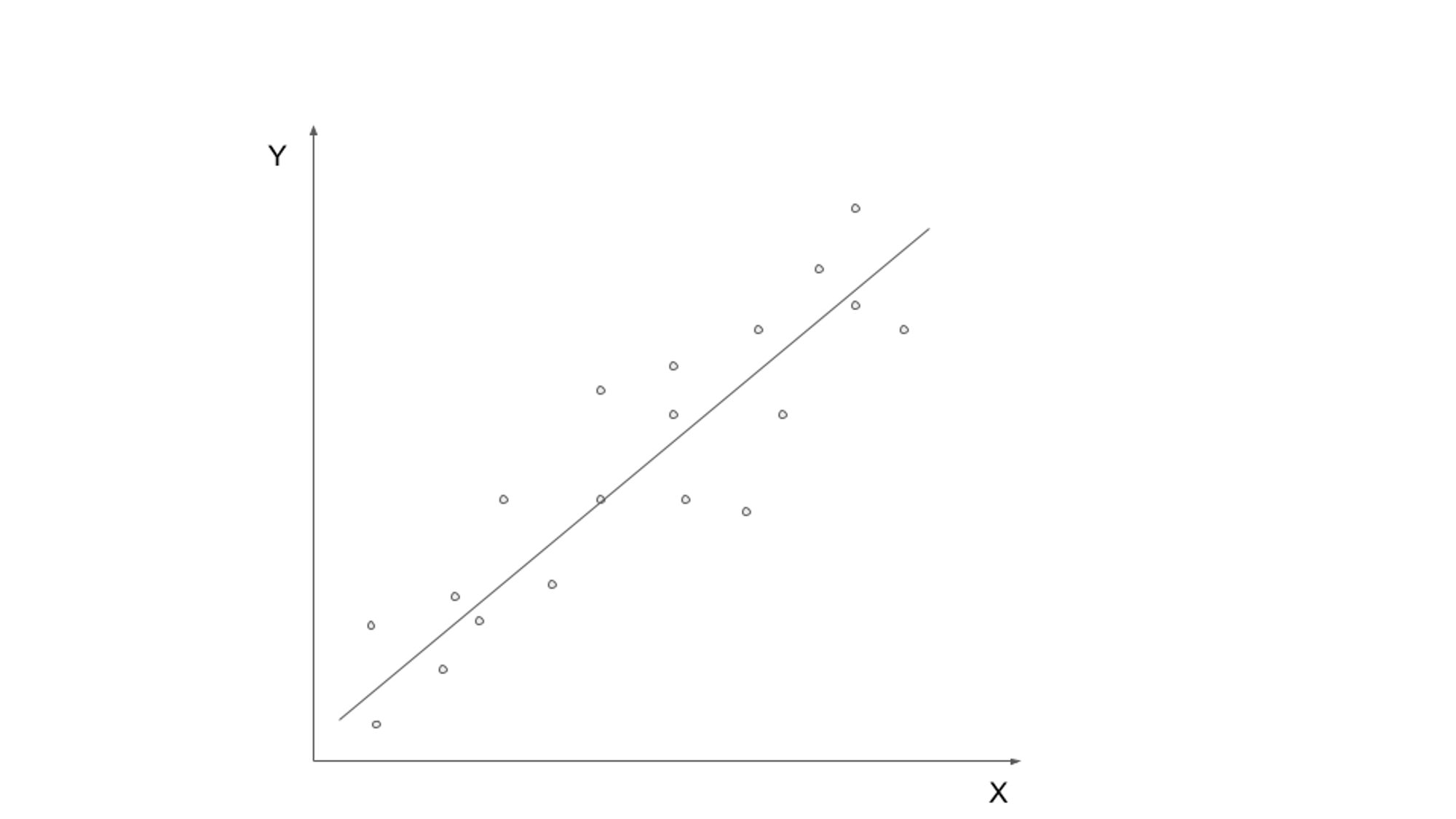
Gesuperviseerd leren omvat het trainen van een model op gelabelde gegevens, waarbij de invoergegevens worden gekoppeld aan de overeenkomstige uitvoer- of doelvariabele. Het doel is een functie te leren die invoergegevens kan toewijzen aan de juiste uitvoer. Veelgebruikte algoritmen voor gesuperviseerd leren zijn onder meer lineaire regressie, logistische regressie, beslissingsbomen en ondersteunende vectormachines.
Voorbeeld van begeleide leercode met behulp van Python:
from sklearn.linear_model import LinearRegression model = LinearRegression() model.fit(X_train, y_train) predictions = model.predict(X_test)
In dit eenvoudige codevoorbeeld trainen we de LinearRegression algoritme van scikit-learn op onze trainingsgegevens en pas het vervolgens toe om voorspellingen voor onze testgegevens te krijgen.
Een real-world use case van begeleid leren is de classificatie van e-mailspam. Met de exponentiële groei van e-mailcommunicatie is het identificeren en filteren van spam-e-mails cruciaal geworden. Door gesuperviseerde leeralgoritmen te gebruiken, is het mogelijk om een model te trainen om onderscheid te maken tussen legitieme e-mails en spam op basis van gelabelde gegevens.
Het begeleide leermodel kan worden getraind op een dataset met e-mails die zijn gelabeld als 'spam' of 'geen spam'. Het model leert patronen en kenmerken van de gelabelde gegevens, zoals de aanwezigheid van bepaalde trefwoorden, e-mailstructuur of informatie over de e-mailafzender. Zodra het model is getraind, kan het worden gebruikt om binnenkomende e-mails automatisch te classificeren als spam of niet-spam, waardoor ongewenste berichten efficiënt worden gefilterd.
Niet-gecontroleerd leren
Bij onbewaakt leren zijn de ingevoerde gegevens niet gelabeld en het doel is om patronen of structuren binnen de gegevens te ontdekken. Unsupervised learning-algoritmen zijn gericht op het vinden van betekenisvolle representaties of clusters in de gegevens.
Voorbeelden van leeralgoritmen zonder toezicht zijn onder meer k-betekent clustering, hiërarchische clustering en hoofdcomponentenanalyse (PCA).
Voorbeeld van onbewaakte leercode:
from sklearn.cluster import KMeans model = KMeans(n_clusters=3) model.fit(X) predictions = model.predict(X_new)
In dit eenvoudige codevoorbeeld trainen we de KMeans algoritme van scikit-learn om drie clusters in onze gegevens te identificeren en vervolgens nieuwe gegevens in die clusters in te passen.
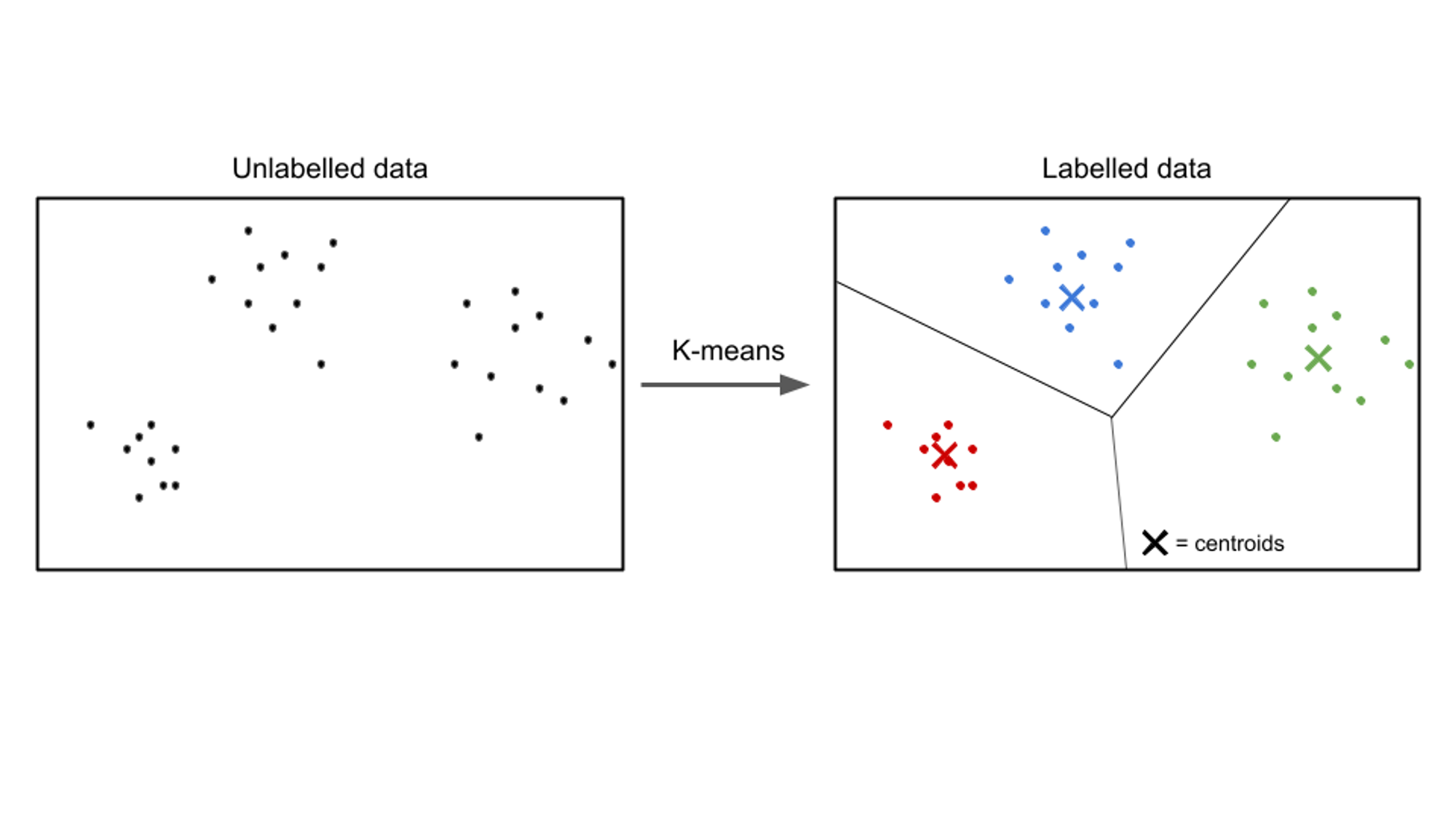
Een voorbeeld van een use-case voor leren zonder toezicht is klantsegmentatie. In verschillende sectoren proberen bedrijven hun klantenbestand beter te begrijpen om hun marketingstrategieën op maat te maken, hun aanbod te personaliseren en klantervaringen te optimaliseren. Algoritmen voor leren zonder toezicht kunnen worden gebruikt om klanten in verschillende groepen te segmenteren op basis van hun gedeelde kenmerken en gedragingen.
Bekijk onze praktische, praktische gids voor het leren van Git, met best-practices, door de industrie geaccepteerde normen en bijgevoegd spiekbriefje. Stop met Googlen op Git-commando's en eigenlijk leren het!
Door onbewaakte leertechnieken toe te passen, zoals clustering, kunnen bedrijven betekenisvolle patronen en groepen binnen hun klantgegevens ontdekken. Clusteringalgoritmen kunnen bijvoorbeeld groepen klanten identificeren met vergelijkbare koopgewoonten, demografische gegevens of voorkeuren. Deze informatie kan worden gebruikt om gerichte marketingcampagnes op te zetten, productaanbevelingen te optimaliseren en de klanttevredenheid te verbeteren.
Belangrijkste algoritmeklassen
Begeleide leeralgoritmen
-
Lineaire modellen: gebruikt voor het voorspellen van continue variabelen op basis van lineaire relaties tussen kenmerken en de doelvariabele.
-
Op bomen gebaseerde modellen: geconstrueerd met behulp van een reeks binaire beslissingen om voorspellingen of classificaties te maken.
-
Ensemble-modellen: methode die meerdere modellen combineert (op een boom gebaseerd of lineair) om nauwkeurigere voorspellingen te doen.
-
Neurale netwerkmodellen: methoden die losjes gebaseerd zijn op het menselijk brein, waarbij meerdere functies werken als knooppunten van een netwerk.
Algoritmen voor leren zonder toezicht
-
Hiërarchische clustering: Bouwt een hiërarchie van clusters door ze iteratief samen te voegen of te splitsen.
-
Niet-hiërarchische clustering: Verdeelt gegevens in verschillende clusters op basis van gelijkenis.
-
Dimensionaliteitsreductie: vermindert de dimensionaliteit van gegevens met behoud van de belangrijkste informatie.
Modelevaluatie
Leren onder toezicht
Om de prestaties van gesuperviseerde leermodellen te evalueren, worden verschillende statistieken gebruikt, waaronder nauwkeurigheid, precisie, herinnering, F1-score en ROC-AUC. Kruisvalidatietechnieken, zoals k-voudige kruisvalidatie, kunnen helpen bij het schatten van de generalisatieprestaties van het model.
Niet-gecontroleerd leren
Het evalueren van leeralgoritmen zonder toezicht is vaak een grotere uitdaging omdat er geen grondwaarheid is. Metrieken zoals silhouetscore of traagheid kunnen worden gebruikt om de kwaliteit van clusterresultaten te beoordelen. Visualisatietechnieken kunnen ook inzicht geven in de structuur van clusters.
Tips en trucs
Leren onder toezicht
- Voorverwerk en normaliseer invoergegevens om de modelprestaties te verbeteren.
- Ga op de juiste manier om met ontbrekende waarden, hetzij door imputatie of verwijdering.
- Feature engineering kan het vermogen van het model om relevante patronen vast te leggen verbeteren.
Niet-gecontroleerd leren
- Kies het juiste aantal clusters op basis van domeinkennis of met behulp van technieken zoals de elleboogmethode.
- Overweeg verschillende afstandsstatistieken om de overeenkomst tussen gegevenspunten te meten.
- Regel het clusteringproces om overfitting te voorkomen.
Samenvattend omvat machine learning tal van taken, technieken, algoritmen, modelevaluatiemethoden en handige hints. Door deze aspecten te begrijpen, kunnen beoefenaars machinaal leren efficiënt toepassen op problemen uit de echte wereld en belangrijke inzichten uit gegevens halen. De gegeven codevoorbeelden demonstreren het gebruik van algoritmen voor leren onder toezicht en zonder toezicht, en benadrukken hun praktische implementatie.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- EVM Financiën. Uniforme interface voor gedecentraliseerde financiën. Toegang hier.
- Quantum Media Groep. IR/PR versterkt. Toegang hier.
- PlatoAiStream. Web3 gegevensintelligentie. Kennis versterkt. Toegang hier.
- Bron: https://stackabuse.com/supervised-learning-vs-unsupervised-learning-algorithms/