
Afbeelding door redacteur
We zien elke week grote taalmodellen (LLM's) verschijnen, met steeds meer chatbots die we kunnen gebruiken. Het kan echter moeilijk zijn om erachter te komen welke de beste is, wat de voortgang is bij elk ervan en welke het nuttigst is.
KnuffelenGezicht heeft een Open LLM Leaderboard dat LLM's volgt, evalueert en rangschikt zodra ze worden vrijgegeven. Ze gebruiken een uniek raamwerk dat wordt gebruikt om generatieve taalmodellen te testen op verschillende evaluatietaken.
Recentelijk stond LLaMA (Large Language Model Meta AI) bovenaan het klassement en is onlangs onttroond door een nieuwe, vooraf getrainde LLM – Falcon 40B.
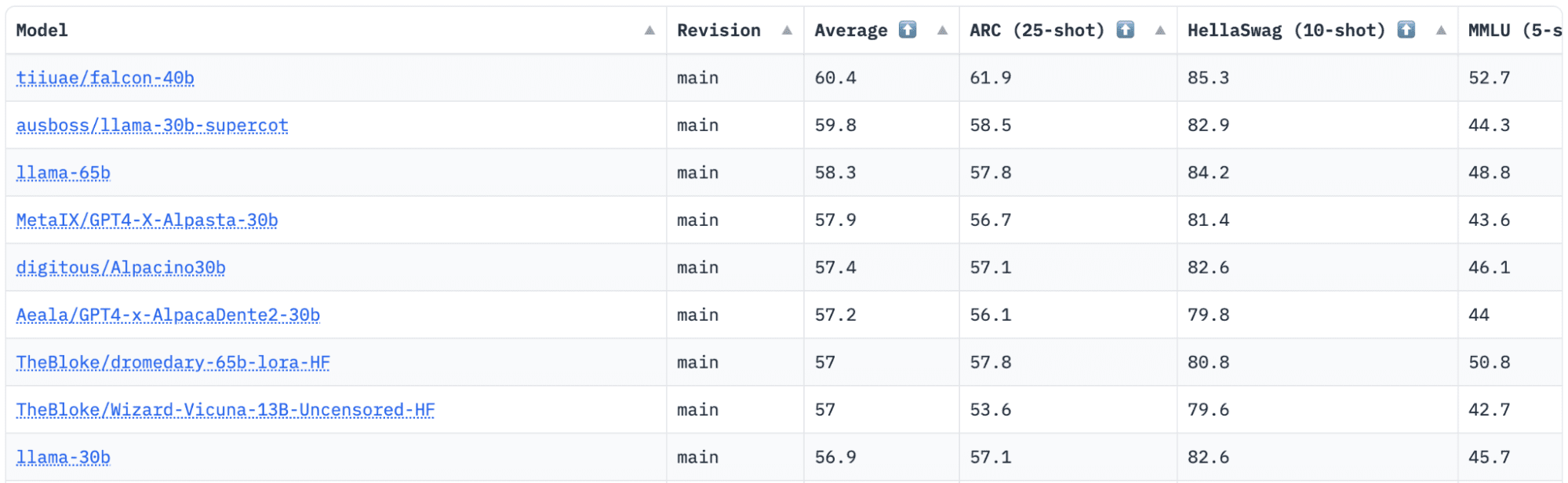
Afbeelding door HuggingFace Open LLM-klassement
Falcon LLM werd opgericht en gebouwd door de Instituut voor technologie-innovatie (TII), een bedrijf dat deel uitmaakt van de Advanced Technology Research Council van de regering van Abu Dhabi. De regering houdt toezicht op technologisch onderzoek in de hele Verenigde Arabische Emiraten, waar het team van wetenschappers, onderzoekers en ingenieurs zich richt op het leveren van transformatieve technologieën en ontdekkingen in de wetenschap.
Valk-40B is een fundamentele LLM met 40B-parameters, die traint op één biljoen tokens. Falcon 40B is een autoregressief decodermodel. Een autoregressief decodermodel betekent dat het model is getraind om het volgende token in een reeks te voorspellen op basis van de voorgaande tokens. Het GPT-model is hiervan een goed voorbeeld.
Het is aangetoond dat de architectuur van Falcon aanzienlijk beter presteert dan GPT-3 voor slechts 75% van het computerbudget voor training, en dat het slechts ? van de berekening op het tijdstip van de inferentie.
Gegevenskwaliteit op grote schaal was een belangrijk aandachtspunt van het team van het Technology Innovation Institute, omdat we weten dat LLM's zeer gevoelig zijn voor de kwaliteit van trainingsgegevens. Het team bouwde een datapijplijn die kon worden opgeschaald naar tienduizenden CPU-kernen voor snelle verwerking en was in staat hoogwaardige inhoud van het internet te extraheren met behulp van uitgebreide filtering en deduplicatie.
Ze hebben ook nog een kleinere versie: Valk-7B die 7B-parameters heeft, getraind op 1,500B-tokens. Evenals een Falcon-40B-Instrueer en Falcon-7B-Instrueer modellen beschikbaar, als u op zoek bent naar een kant-en-klaar chatmodel.
Wat kan Falcon 40B doen?
Net als andere LLM's kan Falcon 40B:
- Genereer creatieve inhoud
- Los complexe problemen op
- Klantenservice activiteiten
- Virtuele assistenten
- Vertaling
- Sentiment analyse.
- Verminder en automatiseer “repetitief” werk.
- Help bedrijven uit de Emiraten efficiënter te worden
Hoe werd Falcon 40B getraind?
Omdat het werd getraind op 1 biljoen tokens, waren er gedurende twee maanden 384 GPU's op AWS nodig. Getraind op 1,000 miljard tokens van VerfijndWeb, een enorme Engelse webdataset gebouwd door TII.
Gegevens vóór de training bestonden uit een verzameling openbare gegevens van internet, met behulp van CommonCrawl. Het team doorliep een grondige filterfase om door de machine gegenereerde tekst te verwijderen, en er werd inhoud voor volwassenen en eventuele deduplicatie verzameld om een pre-trainingsdataset van bijna vijf biljoen tokens te produceren.
De RefinedWeb-dataset is gebouwd bovenop CommonCrawl en heeft aangetoond dat modellen betere prestaties leveren dan modellen die zijn getraind op samengestelde datasets. RefinedWeb is ook multimodaalvriendelijk.
Toen het eenmaal klaar was, werd Falcon gevalideerd aan de hand van open-source benchmarks zoals EAI Harness, HELM en BigBench.
Ze hebben open source Falcon LLM voor het publiek, waardoor Falcon 40B en 7B toegankelijker worden voor onderzoekers en ontwikkelaars, aangezien het gebaseerd is op de Apache License Versie 2.0-release.
De LLM, die ooit alleen voor onderzoek en commercieel gebruik bedoeld was, is nu open-source geworden om tegemoet te komen aan de mondiale vraag naar inclusieve toegang tot AI. Het is nu vrij van royalty's voor beperkingen op commercieel gebruik, omdat de VAE zich inzetten voor het veranderen van de uitdagingen en grenzen binnen AI en de manier waarop het een belangrijke rol speelt in de toekomst.
Met het doel een ecosysteem van samenwerking, innovatie en kennisdeling in de wereld van AI te cultiveren, zorgt Apache 2.0 voor beveiliging en veilige open-sourcesoftware.
Als je een eenvoudigere versie van Falcon-40B wilt uitproberen die beter geschikt is voor generieke instructies in de stijl van een chatbot, dan wil je Falcon-7B gebruiken.
Dus laten we beginnen…
Installeer de volgende pakketten als u dat nog niet heeft gedaan:
!pip install transformers
!pip install einops
!pip install accelerate
!pip install xformers
Zodra u deze pakketten hebt geïnstalleerd, kunt u doorgaan met het uitvoeren van de meegeleverde code Falcon 7-B Instrueer:
from transformers import AutoTokenizer, AutoModelForCausalLM
import transformers
import torch model = "tiiuae/falcon-7b-instruct" tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline( "text-generation", model=model, tokenizer=tokenizer, torch_dtype=torch.bfloat16, trust_remote_code=True, device_map="auto",
)
sequences = pipeline( "Girafatron is obsessed with giraffes, the most glorious animal on the face of this Earth. Giraftron believes all other animals are irrelevant when compared to the glorious majesty of the giraffe.nDaniel: Hello, Girafatron!nGirafatron:", max_length=200, do_sample=True, top_k=10, num_return_sequences=1, eos_token_id=tokenizer.eos_token_id,
)
for seq in sequences: print(f"Result: {seq['generated_text']}")
Falcon staat bekend als het beste beschikbare open-sourcemodel en heeft de LLaMA-kroon veroverd, en mensen zijn verbaasd over de sterk geoptimaliseerde architectuur, open-source met een unieke licentie, en het is beschikbaar in twee formaten: 40B- en 7B-parameters.
Heb je het geprobeerd? Als dat zo is, laat ons dan in de reacties weten wat je ervan vindt.
Nisha Arja is een datawetenschapper, freelance technisch schrijver en communitymanager bij KDnuggets. Ze is met name geïnteresseerd in het geven van loopbaanadvies of tutorials over Data Science en op theorie gebaseerde kennis rond Data Science. Ze wil ook de verschillende manieren onderzoeken waarop kunstmatige intelligentie de levensduur van de mens ten goede komt/kan komen. Een enthousiaste leerling, die haar technische kennis en schrijfvaardigheid wil verbreden, terwijl ze anderen helpt te begeleiden.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- EVM Financiën. Uniforme interface voor gedecentraliseerde financiën. Toegang hier.
- Quantum Media Groep. IR/PR versterkt. Toegang hier.
- PlatoAiStream. Web3 gegevensintelligentie. Kennis versterkt. Toegang hier.
- Bron: https://www.kdnuggets.com/2023/06/falcon-llm-new-king-llms.html?utm_source=rss&utm_medium=rss&utm_campaign=falcon-llm-the-new-king-of-open-source-llms
Falcon LLM: de nieuwe koning van open-source LLM's - KDnuggets
Heruitgegeven door Plato
Afbeelding door redacteur
We zien elke week grote taalmodellen (LLM's) verschijnen, met steeds meer chatbots die we kunnen gebruiken. Het kan echter moeilijk zijn om erachter te komen welke de beste is, wat de voortgang is bij elk ervan en welke het nuttigst is.
KnuffelenGezicht heeft een Open LLM Leaderboard dat LLM's volgt, evalueert en rangschikt zodra ze worden vrijgegeven. Ze gebruiken een uniek raamwerk dat wordt gebruikt om generatieve taalmodellen te testen op verschillende evaluatietaken.
Recentelijk stond LLaMA (Large Language Model Meta AI) bovenaan het klassement en is onlangs onttroond door een nieuwe, vooraf getrainde LLM – Falcon 40B.
Afbeelding door HuggingFace Open LLM-klassement
Falcon LLM werd opgericht en gebouwd door de Instituut voor technologie-innovatie (TII), een bedrijf dat deel uitmaakt van de Advanced Technology Research Council van de regering van Abu Dhabi. De regering houdt toezicht op technologisch onderzoek in de hele Verenigde Arabische Emiraten, waar het team van wetenschappers, onderzoekers en ingenieurs zich richt op het leveren van transformatieve technologieën en ontdekkingen in de wetenschap.
Valk-40B is een fundamentele LLM met 40B-parameters, die traint op één biljoen tokens. Falcon 40B is een autoregressief decodermodel. Een autoregressief decodermodel betekent dat het model is getraind om het volgende token in een reeks te voorspellen op basis van de voorgaande tokens. Het GPT-model is hiervan een goed voorbeeld.
Het is aangetoond dat de architectuur van Falcon aanzienlijk beter presteert dan GPT-3 voor slechts 75% van het computerbudget voor training, en dat het slechts ? van de berekening op het tijdstip van de inferentie.
Gegevenskwaliteit op grote schaal was een belangrijk aandachtspunt van het team van het Technology Innovation Institute, omdat we weten dat LLM's zeer gevoelig zijn voor de kwaliteit van trainingsgegevens. Het team bouwde een datapijplijn die kon worden opgeschaald naar tienduizenden CPU-kernen voor snelle verwerking en was in staat hoogwaardige inhoud van het internet te extraheren met behulp van uitgebreide filtering en deduplicatie.
Ze hebben ook nog een kleinere versie: Valk-7B die 7B-parameters heeft, getraind op 1,500B-tokens. Evenals een Falcon-40B-Instrueer en Falcon-7B-Instrueer modellen beschikbaar, als u op zoek bent naar een kant-en-klaar chatmodel.
Wat kan Falcon 40B doen?
Net als andere LLM's kan Falcon 40B:
Hoe werd Falcon 40B getraind?
Omdat het werd getraind op 1 biljoen tokens, waren er gedurende twee maanden 384 GPU's op AWS nodig. Getraind op 1,000 miljard tokens van VerfijndWeb, een enorme Engelse webdataset gebouwd door TII.
Gegevens vóór de training bestonden uit een verzameling openbare gegevens van internet, met behulp van CommonCrawl. Het team doorliep een grondige filterfase om door de machine gegenereerde tekst te verwijderen, en er werd inhoud voor volwassenen en eventuele deduplicatie verzameld om een pre-trainingsdataset van bijna vijf biljoen tokens te produceren.
De RefinedWeb-dataset is gebouwd bovenop CommonCrawl en heeft aangetoond dat modellen betere prestaties leveren dan modellen die zijn getraind op samengestelde datasets. RefinedWeb is ook multimodaalvriendelijk.
Toen het eenmaal klaar was, werd Falcon gevalideerd aan de hand van open-source benchmarks zoals EAI Harness, HELM en BigBench.
Ze hebben open source Falcon LLM voor het publiek, waardoor Falcon 40B en 7B toegankelijker worden voor onderzoekers en ontwikkelaars, aangezien het gebaseerd is op de Apache License Versie 2.0-release.
De LLM, die ooit alleen voor onderzoek en commercieel gebruik bedoeld was, is nu open-source geworden om tegemoet te komen aan de mondiale vraag naar inclusieve toegang tot AI. Het is nu vrij van royalty's voor beperkingen op commercieel gebruik, omdat de VAE zich inzetten voor het veranderen van de uitdagingen en grenzen binnen AI en de manier waarop het een belangrijke rol speelt in de toekomst.
Met het doel een ecosysteem van samenwerking, innovatie en kennisdeling in de wereld van AI te cultiveren, zorgt Apache 2.0 voor beveiliging en veilige open-sourcesoftware.
Als je een eenvoudigere versie van Falcon-40B wilt uitproberen die beter geschikt is voor generieke instructies in de stijl van een chatbot, dan wil je Falcon-7B gebruiken.
Dus laten we beginnen…
Installeer de volgende pakketten als u dat nog niet heeft gedaan:
Zodra u deze pakketten hebt geïnstalleerd, kunt u doorgaan met het uitvoeren van de meegeleverde code Falcon 7-B Instrueer:
Falcon staat bekend als het beste beschikbare open-sourcemodel en heeft de LLaMA-kroon veroverd, en mensen zijn verbaasd over de sterk geoptimaliseerde architectuur, open-source met een unieke licentie, en het is beschikbaar in twee formaten: 40B- en 7B-parameters.
Heb je het geprobeerd? Als dat zo is, laat ons dan in de reacties weten wat je ervan vindt.
Nisha Arja is een datawetenschapper, freelance technisch schrijver en communitymanager bij KDnuggets. Ze is met name geïnteresseerd in het geven van loopbaanadvies of tutorials over Data Science en op theorie gebaseerde kennis rond Data Science. Ze wil ook de verschillende manieren onderzoeken waarop kunstmatige intelligentie de levensduur van de mens ten goede komt/kan komen. Een enthousiaste leerling, die haar technische kennis en schrijfvaardigheid wil verbreden, terwijl ze anderen helpt te begeleiden.
Meer over dit onderwerp
Nigeria geeft entiteiten opdracht om degenen te identificeren die in crypto handelen met Bybit, KuCoin, OKX en Binance
Bitcoin Bulls vestigen de hoop op een zwakkere dollar om de rally te verlengen
Bitcoin en Ethereum blijven stabiel in Azië, terwijl handelaren aarzelen om zich in te zetten voor een bullish of bearish houding – CryptoInfoNet
Hong Kong Crypto ETF's krijgen een lanceringsdatum in april – Unchained
Hoe u beter kunt presteren in Crypto: de 'Left Curve'-strategie van Arthur Hayes
Revolut wil het wereldwijde personeelsbestand in 40 met 2024% vergroten
SEC stelt Ethereum ETF-beslissingen uit
CMC Markets verheft langetermijnmanager tot hoofd van institutionele APAC en Canada
Base Chain verwelkomt inaugurele Meme Coin Launchpad: een baken tegen oplichting en tapijttrekkingen
Deze Amerikaanse vermogensbeheerders hebben zojuist Bitcoin gekocht via de ETF van Fidelity