
Dit bericht is mede geschreven door Goktug Cinar, Michael Binder en Adrian Horvath van Bosch Center for Artificial Intelligence (BCAI).
Inkomstenprognoses zijn een uitdagende maar cruciale taak voor strategische zakelijke beslissingen en fiscale planning in de meeste organisaties. Inkomstenprognoses worden vaak handmatig uitgevoerd door financiële analisten en zijn zowel tijdrovend als subjectief. Dergelijke handmatige inspanningen zijn vooral een uitdaging voor grootschalige, multinationale bedrijfsorganisaties die omzetprognoses nodig hebben voor een breed scala aan productgroepen en geografische gebieden op meerdere granulariteitsniveaus. Dit vereist niet alleen nauwkeurigheid, maar ook hiërarchische samenhang van de prognoses.
Bosch is een multinationale onderneming met entiteiten die actief zijn in meerdere sectoren, waaronder de automobielindustrie, industriële oplossingen en consumptiegoederen. Gezien de impact van nauwkeurige en coherente omzetprognoses op een gezonde bedrijfsvoering, Bosch Centrum voor Kunstmatige Intelligentie (BCAI) heeft zwaar geïnvesteerd in het gebruik van machine learning (ML) om de efficiëntie en nauwkeurigheid van financiële planningsprocessen te verbeteren. Het doel is om de handmatige processen te verlichten door redelijke basisinkomstenprognoses te bieden via ML, met slechts incidentele aanpassingen die nodig zijn door de financiële analisten die hun branche- en domeinkennis gebruiken.
Om dit doel te bereiken, heeft BCAI een intern prognoseraamwerk ontwikkeld dat in staat is om grootschalige hiërarchische prognoses te bieden via aangepaste ensembles van een breed scala aan basismodellen. Een meta-leerling selecteert de best presterende modellen op basis van kenmerken die uit elke tijdreeks zijn geëxtraheerd. De prognoses van de geselecteerde modellen worden vervolgens gemiddeld om de geaggregeerde prognose te verkrijgen. Het architecturale ontwerp is modulair en uitbreidbaar door de implementatie van een REST-achtige interface, die continue prestatieverbetering mogelijk maakt door het opnemen van extra modellen.
BCAI werkt samen met de Amazon ML Solutions-lab (MLSL) om de nieuwste ontwikkelingen in op deep neural network (DNN) gebaseerde modellen voor inkomstenprognoses op te nemen. Recente ontwikkelingen in neurale voorspellers hebben state-of-the-art prestaties aangetoond voor veel praktische prognoseproblemen. In vergelijking met traditionele voorspellingsmodellen kunnen veel neurale voorspellers extra covariaten of metadata van de tijdreeksen opnemen. We hebben CNN-QR en DeepAR+, twee kant-en-klare modellen in Amazon voorspelling, evenals een aangepast Transformer-model dat is getraind met behulp van Amazon Sage Maker. De drie modellen dekken een representatieve set van de encoder-backbones die vaak worden gebruikt in neurale voorspellers: convolutioneel neuraal netwerk (CNN), sequentieel terugkerend neuraal netwerk (RNN) en op transformatoren gebaseerde encoders.
Een van de belangrijkste uitdagingen voor het BCAI-MLSL-partnerschap was om robuuste en redelijke voorspellingen te doen onder de impact van COVID-19, een ongekende wereldwijde gebeurtenis die grote volatiliteit veroorzaakt op de wereldwijde financiële bedrijfsresultaten. Omdat neurale voorspellers zijn getraind op historische gegevens, kunnen de prognoses die worden gegenereerd op basis van niet-distributiegegevens uit de meer volatiele perioden onnauwkeurig en onbetrouwbaar zijn. Daarom hebben we de toevoeging van een gemaskeerd aandachtsmechanisme in de Transformer-architectuur voorgesteld om dit probleem aan te pakken.
De neurale voorspellers kunnen worden gebundeld als een enkel ensemble-model, of afzonderlijk worden opgenomen in het Bosch-modeluniversum, en zijn eenvoudig toegankelijk via REST API-eindpunten. We stellen een benadering voor om de neurale voorspellers te bundelen door middel van backtest-resultaten, die in de loop van de tijd competitieve en robuuste prestaties bieden. Daarnaast hebben we een aantal klassieke hiërarchische afstemmingstechnieken onderzocht en geëvalueerd om ervoor te zorgen dat prognoses coherent aggregeren over productgroepen, geografische gebieden en bedrijfsorganisaties.
In dit bericht laten we het volgende zien:
- Hoe Forecast en SageMaker aangepaste modeltraining toe te passen voor hiërarchische, grootschalige tijdreeksvoorspellingsproblemen
- Aangepaste modellen combineren met kant-en-klare modellen van Forecast
- Hoe de impact van ontwrichtende gebeurtenissen zoals COVID-19 op prognoseproblemen te verminderen?
- Een end-to-end prognoseworkflow bouwen op AWS
Uitdagingen
We hebben twee uitdagingen aangepakt: het creëren van hiërarchische, grootschalige inkomstenprognoses en de impact van de COVID-19-pandemie op langetermijnprognoses.
Hiërarchische, grootschalige omzetprognose
Financiële analisten zijn belast met het voorspellen van belangrijke financiële cijfers, waaronder inkomsten, operationele kosten en R&D-uitgaven. Deze statistieken bieden inzichten in bedrijfsplanning op verschillende aggregatieniveaus en maken datagestuurde besluitvorming mogelijk. Elke geautomatiseerde prognoseoplossing moet prognoses bieden op elk willekeurig niveau van bedrijfsgroepaggregatie. Bij Bosch kunnen de aggregaties worden voorgesteld als gegroepeerde tijdreeksen als een meer algemene vorm van hiërarchische structuur. De volgende afbeelding toont een vereenvoudigd voorbeeld met een structuur met twee niveaus, die de hiërarchische structuur voor inkomstenprognose bij Bosch nabootst. De totale omzet is opgesplitst in meerdere aggregatieniveaus op basis van product en regio.
Het totale aantal tijdreeksen dat bij Bosch moet worden voorspeld, loopt in de miljoenen. Merk op dat de tijdreeksen op het hoogste niveau kunnen worden opgesplitst in producten of regio's, waardoor meerdere paden naar prognoses op het laagste niveau worden gecreëerd. De omzet moet worden voorspeld op elk knooppunt in de hiërarchie met een prognosehorizon van 12 maanden in de toekomst. Maandelijkse historische gegevens zijn beschikbaar.
De hiërarchische structuur kan worden weergegeven met behulp van de volgende vorm met de notatie van een optelmatrix S (Hyndman en Athanasopoulos):
![]()
In deze vergelijking, Y komt overeen met het volgende:

Hier b vertegenwoordigt de tijdreeks op het laagste niveau op tijd t.
Gevolgen van de COVID-19-pandemie
De COVID-19-pandemie bracht aanzienlijke uitdagingen met zich mee voor prognoses vanwege de ontwrichtende en ongekende effecten op bijna alle aspecten van het werk en het sociale leven. Voor de langetermijnprognoses van inkomsten bracht de verstoring ook onverwachte downstream-effecten met zich mee. Om dit probleem te illustreren, toont de volgende afbeelding een voorbeeldtijdreeks waarin de productinkomsten aan het begin van de pandemie aanzienlijk daalden en daarna geleidelijk herstelden. Een typisch neuraal voorspellingsmodel zal inkomstengegevens gebruiken, waaronder de COVID-periode buiten distributie (OOD) als de historische contextinvoer, evenals de grondwaarheid voor modeltraining. Als gevolg hiervan zijn de geproduceerde prognoses niet langer betrouwbaar.

Modelleringsbenaderingen
In deze sectie bespreken we onze verschillende modelleringsbenaderingen.
Amazon voorspelling
Forecast is een volledig beheerde AI/ML-service van AWS die vooraf geconfigureerde, ultramoderne voorspellingsmodellen voor tijdreeksen biedt. Het combineert dit aanbod met zijn interne mogelijkheden voor geautomatiseerde hyperparameteroptimalisatie, ensemblemodellering (voor de modellen geleverd door Forecast) en het genereren van probabilistische voorspellingen. Hierdoor kunt u eenvoudig aangepaste datasets opnemen, gegevens voorverwerken, prognosemodellen trainen en robuuste prognoses genereren. Het modulaire ontwerp van de service stelt ons verder in staat om gemakkelijk voorspellingen op te vragen en te combineren van aanvullende, parallel ontwikkelde aangepaste modellen.
We gebruiken twee neurale voorspellers van Forecast: CNN-QR en DeepAR+. Beide zijn begeleide deep learning-methoden die een globaal model trainen voor de volledige tijdreeksdataset. Zowel CNNQR- als DeepAR+-modellen kunnen statische metadata-informatie opnemen over elke tijdreeks, wat in ons geval het overeenkomstige product, de regio en de bedrijfsorganisatie is. Ze voegen ook automatisch tijdelijke kenmerken toe, zoals de maand van het jaar, als onderdeel van de invoer voor het model.
Transformator met aandachtsmaskers voor COVID
De Transformer-architectuur (Vaswani et al.), oorspronkelijk ontworpen voor natuurlijke taalverwerking (NLP), is onlangs naar voren gekomen als een populaire architecturale keuze voor het voorspellen van tijdreeksen. Hier hebben we de Transformer-architectuur gebruikt die wordt beschreven in Zhou et al. zonder probabilistische log spaarzame aandacht. Het model gebruikt een typisch architectuurontwerp door een encoder en een decoder te combineren. Voor omzetprognoses configureren we de decoder om de prognose van de 12-maandshorizon direct uit te voeren in plaats van de prognose van maand tot maand op een autoregressieve manier te genereren. Op basis van de frequentie van de tijdreeksen worden aanvullende tijdgerelateerde kenmerken, zoals de maand van het jaar, als invoervariabele toegevoegd. Aanvullende categorische variabelen die de meta-informatie beschrijven (product, regio, bedrijfsorganisatie) worden via een trainbare inbeddingslaag in het netwerk ingevoerd.
Het volgende diagram illustreert de Transformer-architectuur en het aandachtsmaskeringsmechanisme. Aandachtsmaskering wordt toegepast in alle lagen van de encoder en decoder, zoals oranje gemarkeerd, om te voorkomen dat OOD-gegevens de prognoses beïnvloeden.

We verminderen de impact van OOD-contextvensters door aandachtsmaskers toe te voegen. Het model is getraind om zeer weinig aandacht te schenken aan de COVID-periode die uitbijters bevat via maskering, en voert voorspellingen uit met gemaskeerde informatie. Het aandachtsmasker wordt toegepast in elke laag van de decoder- en encoderarchitectuur. Het gemaskeerde venster kan handmatig of via een algoritme voor uitbijterdetectie worden gespecificeerd. Bovendien, wanneer een tijdvenster wordt gebruikt met uitbijters als trainingslabels, worden de verliezen niet teruggepropageerd. Deze op aandachtsmaskering gebaseerde methode kan worden toegepast om verstoringen en OOD-gevallen veroorzaakt door andere zeldzame gebeurtenissen aan te pakken en de robuustheid van de voorspellingen te verbeteren.
Modelensemble
Modelensemble presteert vaak beter dan afzonderlijke modellen voor prognoses - het verbetert de generaliseerbaarheid van het model en is beter in het omgaan met tijdreeksgegevens met variërende kenmerken in periodiciteit en intermitterendheid. We nemen een reeks modelensemble-strategieën op om de modelprestaties en robuustheid van voorspellingen te verbeteren. Een veelgebruikte vorm van deep learning-modelensemble is het samenvoegen van resultaten van modelruns met verschillende initialisaties van willekeurig gewicht of van verschillende trainingsperioden. We gebruiken deze strategie om prognoses voor het Transformer-model te verkrijgen.
Om een ensemble verder te bouwen bovenop verschillende modelarchitecturen, zoals Transformer, CNNQR en DeepAR+, gebruiken we een pan-model-ensemblestrategie die de top-k best presterende modellen voor elke tijdreeks selecteert op basis van de backtestresultaten en hun gemiddelden. Omdat backtestresultaten rechtstreeks kunnen worden geëxporteerd vanuit getrainde Forecast-modellen, stelt deze strategie ons in staat om te profiteren van kant-en-klare services zoals Forecast met verbeteringen die zijn verkregen uit aangepaste modellen zoals Transformer. Een dergelijke end-to-end benadering van het modelensemble vereist geen training van een meta-leerling of het berekenen van tijdreeksfuncties voor modelselectie.
Hiërarchische afstemming
Het raamwerk is adaptief om een breed scala aan technieken op te nemen als nabewerkingsstappen voor hiërarchische afstemming van prognoses, waaronder bottom-up (BU), top-down afstemming met prognoseverhoudingen (TDFP), gewone kleinste kwadraten (OLS) en gewogen kleinste kwadraten ( WLS). Alle experimentele resultaten in dit bericht worden gerapporteerd met behulp van top-down afstemming met prognoseverhoudingen.
Architectuur overzicht
We hebben een geautomatiseerde end-to-end workflow op AWS ontwikkeld om omzetprognoses te genereren met behulp van services zoals Forecast, SageMaker, Amazon eenvoudige opslagservice (Amazone S3), AWS Lambda, AWS Stap Functies en AWS Cloud-ontwikkelingskit (AWS CDK). De geïmplementeerde oplossing biedt individuele tijdreeksvoorspellingen via een REST API met behulp van Amazon API-gateway, door de resultaten in vooraf gedefinieerde JSON-indeling te retourneren.
Het volgende diagram illustreert de end-to-end prognoseworkflow.

Belangrijke ontwerpoverwegingen voor de architectuur zijn veelzijdigheid, prestaties en gebruiksvriendelijkheid. Het systeem moet voldoende veelzijdig zijn om tijdens de ontwikkeling en implementatie een diverse reeks algoritmen op te nemen, met minimale vereiste wijzigingen, en kan eenvoudig worden uitgebreid wanneer in de toekomst nieuwe algoritmen worden toegevoegd. Het systeem moet ook minimale overhead toevoegen en parallelle training ondersteunen voor zowel Forecast als SageMaker om de trainingstijd te verkorten en sneller de nieuwste prognose te verkrijgen. Ten slotte moet het systeem eenvoudig te gebruiken zijn voor experimentele doeleinden.
De end-to-end workflow doorloopt achtereenvolgens de volgende modules:
- Een preprocessing-module voor het opnieuw formatteren en transformeren van gegevens
- Een modeltrainingsmodule met zowel het Forecast-model als het aangepaste model op SageMaker (beide worden parallel uitgevoerd)
- Een module voor nabewerking die modelensemble, hiërarchische afstemming, metrieken en het genereren van rapporten ondersteunt
Step Functions organiseert en orkestreert de workflow van begin tot eind als een statusmachine. De uitvoering van de statusmachine is geconfigureerd met een JSON-bestand dat alle benodigde informatie bevat, inclusief de locatie van de CSV-bestanden met historische inkomsten in Amazon S3, de starttijd van de prognose en modelhyperparameterinstellingen om de end-to-end-workflow uit te voeren. Asynchrone oproepen worden gemaakt om modeltraining in de statusmachine parallel te laten lopen met behulp van Lambda-functies. Alle historische gegevens, configuratiebestanden, prognoseresultaten en tussentijdse resultaten zoals backtesting-resultaten worden opgeslagen in Amazon S3. De REST API is bovenop Amazon S3 gebouwd om een doorzoekbare interface te bieden voor het opvragen van prognoseresultaten. Het systeem kan worden uitgebreid met nieuwe prognosemodellen en ondersteunende functies zoals het genereren van prognosevisualisatierapporten.
Evaluatie
In deze sectie beschrijven we de opzet van het experiment. Belangrijke componenten zijn onder meer de dataset, evaluatiestatistieken, backtest-vensters en modelconfiguratie en -training.
dataset
Om de financiële privacy van Bosch te beschermen bij het gebruik van een zinvolle dataset, hebben we een synthetische dataset gebruikt die vergelijkbare statistische kenmerken heeft als een real-world omzetdataset van een business unit bij Bosch. De dataset bevat in totaal 1,216 tijdreeksen met inkomsten geregistreerd in een maandelijkse frequentie, van januari 2016 tot april 2022. De dataset wordt geleverd met 877 tijdreeksen op het meest gedetailleerde niveau (onderste tijdreeksen), met een overeenkomstige gegroepeerde tijdreeksstructuur weergegeven als een optelmatrix S. Elke tijdreeks wordt geassocieerd met drie statische categorische attributen, die overeenkomen met productcategorie, regio en organisatie-eenheid in de echte dataset (geanonimiseerd in de synthetische data).
Evaluatiestatistieken
We gebruiken mediaan-Mean Arctangent Absolute Percentage Error (mediaan-MAAPE) en gewogen-MAAPE om de prestaties van het model te evalueren en vergelijkende analyses uit te voeren, de standaard metrieken die bij Bosch worden gebruikt. MAAPE pakt de tekortkomingen aan van de Mean Absolute Percentage Error (MAPE)-statistiek die vaak wordt gebruikt in de zakelijke context. Mediaan-MAAPE geeft een overzicht van de modelprestaties door de mediaan te berekenen van de MAAPE's die afzonderlijk voor elke tijdreeks zijn berekend. Weighted-MAAPE meldt een gewogen combinatie van de individuele MAAPE's. De gewichten zijn het aandeel van de omzet voor elke tijdreeks in vergelijking met de geaggregeerde omzet van de gehele dataset. Gewogen MAAPE weerspiegelt beter de downstream-bedrijfseffecten van de prognosenauwkeurigheid. Beide statistieken worden gerapporteerd over de volledige dataset van 1,216 tijdreeksen.
Backtest-vensters
We gebruiken voortschrijdende backtest-vensters van 12 maanden om de modelprestaties te vergelijken. De volgende afbeelding illustreert de backtest-vensters die in de experimenten zijn gebruikt en benadrukt de bijbehorende gegevens die worden gebruikt voor training en hyperparameteroptimalisatie (HPO). Voor backtest-vensters nadat COVID-19 is gestart, wordt het resultaat beïnvloed door OOD-invoer van april tot mei 2020, op basis van wat we hebben waargenomen in de tijdreeksen van inkomsten.

Modelopstelling en training
Voor Transformer-training hebben we kwantielverlies gebruikt en elke tijdreeks geschaald met behulp van de historische gemiddelde waarde voordat we deze in Transformer hebben ingevoerd en het trainingsverlies hebben berekend. De definitieve prognoses worden teruggeschaald om de nauwkeurigheidsstatistieken te berekenen, met behulp van de MeanScaler die is geïmplementeerd in GluonTS. We gebruiken een contextvenster met maandelijkse omzetgegevens van de afgelopen 18 maanden, geselecteerd via HPO in het backtestvenster van juli 2018 tot juni 2019. Aanvullende metadata over elke tijdreeks in de vorm van statische categorische variabelen worden via een inbedding in het model ingevoerd laag voordat u het naar de transformatorlagen voert. We trainen de Transformer met vijf verschillende initialisaties van willekeurig gewicht en nemen het gemiddelde van de voorspellingsresultaten van de laatste drie tijdperken voor elke run, in totaal gemiddeld 15 modellen. De vijf modeltrainingsruns kunnen parallel worden geschakeld om de trainingstijd te verkorten. Voor de gemaskeerde Transformer geven we de maanden april t/m mei 2020 als uitbijters aan.
Voor alle Forecast-modeltraining hebben we automatische HPO ingeschakeld, die het model en de trainingsparameters kan selecteren op basis van een door de gebruiker gespecificeerde backtestperiode, die is ingesteld op de laatste 12 maanden in het gegevensvenster dat wordt gebruikt voor training en HPO.
Experiment resultaten
We trainen gemaskerde en ontmaskerde Transformers met dezelfde set hyperparameters en vergeleken hun prestaties voor backtest-vensters onmiddellijk na de COVID-19-schok. In de gemaskeerde Transformer zijn de twee gemaskeerde maanden april en mei 2020. De volgende tabel toont de resultaten van een reeks backtest-periodes met prognosevensters van 12 maanden vanaf juni 2020. We kunnen constateren dat de gemaskeerde Transformer consequent beter presteert dan de niet-gemaskeerde versie .

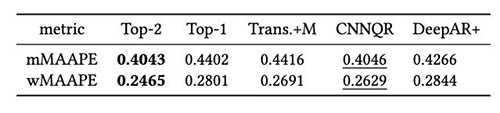
We hebben verder een evaluatie uitgevoerd van de modelensemble-strategie op basis van backtest-resultaten. In het bijzonder vergelijken we de twee gevallen waarin alleen het best presterende model wordt geselecteerd versus wanneer de twee best presterende modellen worden geselecteerd, en modelmiddeling wordt uitgevoerd door de gemiddelde waarde van de voorspellingen te berekenen. We vergelijken de prestaties van de basismodellen en de ensemblemodellen in de volgende figuren. Merk op dat geen van de neurale voorspellers consequent beter presteert dan anderen voor de rollende backtest-vensters.


De volgende tabel laat zien dat ensemblemodellering van de twee topmodellen gemiddeld de beste prestaties geeft. CNNQR levert het op één na beste resultaat.
Conclusie
Deze post demonstreerde hoe je een end-to-end ML-oplossing bouwt voor grootschalige prognoseproblemen door Forecast te combineren met een aangepast model dat is getraind op SageMaker. Afhankelijk van uw zakelijke behoeften en ML-kennis, kunt u een volledig beheerde service zoals Forecast gebruiken om het bouw-, trainings- en implementatieproces van een prognosemodel te ontlasten; bouw uw eigen model met specifieke afstemmingsmechanismen met SageMaker; of voer modelensembling uit door de twee services te combineren.
Als u hulp wilt bij het versnellen van het gebruik van ML in uw producten en diensten, neem dan contact op met de Amazon ML Solutions-lab programma.
Referenties
Hyndman RJ, Athanasopoulos G. Prognose: principes en praktijk. OTeksten; 2018 mei 8
Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez AN, Kaiser Ł, Polosukhin I. Aandacht is alles wat je nodig hebt. Vooruitgang in neurale informatieverwerkingssystemen. 2017;30.
Zhou H, Zhang S, Peng J, Zhang S, Li J, Xiong H, Zhang W. Informer: meer dan een efficiënte transformator voor het voorspellen van lange reeksen van tijdreeksen. InProceedings van AAAI 2021 2 februari.
Over de auteurs
 Goktug Cinar is een leidende ML-wetenschapper en de technische leider van de ML en op statistieken gebaseerde prognoses bij Robert Bosch LLC en Bosch Center for Artificial Intelligence. Hij leidt het onderzoek naar de voorspellingsmodellen, hiërarchische consolidatie en modelcombinatietechnieken, evenals het softwareontwikkelingsteam dat deze modellen schaalt en bedient als onderdeel van de interne end-to-end financiële voorspellingssoftware.
Goktug Cinar is een leidende ML-wetenschapper en de technische leider van de ML en op statistieken gebaseerde prognoses bij Robert Bosch LLC en Bosch Center for Artificial Intelligence. Hij leidt het onderzoek naar de voorspellingsmodellen, hiërarchische consolidatie en modelcombinatietechnieken, evenals het softwareontwikkelingsteam dat deze modellen schaalt en bedient als onderdeel van de interne end-to-end financiële voorspellingssoftware.
 Michaël Binder is product owner bij Bosch Global Services, waar hij de ontwikkeling, implementatie en implementatie coördineert van de bedrijfsbrede predictive analytics-applicatie voor de grootschalige geautomatiseerde datagedreven forecasting van financiële kengetallen.
Michaël Binder is product owner bij Bosch Global Services, waar hij de ontwikkeling, implementatie en implementatie coördineert van de bedrijfsbrede predictive analytics-applicatie voor de grootschalige geautomatiseerde datagedreven forecasting van financiële kengetallen.
 Adriaan Horvath is Software Developer bij Bosch Center for Artificial Intelligence, waar hij systemen ontwikkelt en onderhoudt om voorspellingen te maken op basis van verschillende voorspellingsmodellen.
Adriaan Horvath is Software Developer bij Bosch Center for Artificial Intelligence, waar hij systemen ontwikkelt en onderhoudt om voorspellingen te maken op basis van verschillende voorspellingsmodellen.
 Panpan Xu is Senior Applied Scientist en Manager bij het Amazon ML Solutions Lab bij AWS. Ze werkt aan onderzoek en ontwikkeling van Machine Learning-algoritmen voor klanttoepassingen met een grote impact in verschillende industriële branches om hun AI- en cloudadoptie te versnellen. Haar onderzoeksinteresse omvat de interpreteerbaarheid van modellen, causale analyse, human-in-the-loop AI en interactieve datavisualisatie.
Panpan Xu is Senior Applied Scientist en Manager bij het Amazon ML Solutions Lab bij AWS. Ze werkt aan onderzoek en ontwikkeling van Machine Learning-algoritmen voor klanttoepassingen met een grote impact in verschillende industriële branches om hun AI- en cloudadoptie te versnellen. Haar onderzoeksinteresse omvat de interpreteerbaarheid van modellen, causale analyse, human-in-the-loop AI en interactieve datavisualisatie.
 Jasleen Grewal is een Applied Scientist bij Amazon Web Services, waar ze samenwerkt met AWS-klanten om problemen in de echte wereld op te lossen met behulp van machine learning, met speciale aandacht voor precisiegeneeskunde en genomica. Ze heeft een sterke achtergrond in bio-informatica, oncologie en klinische genomica. Ze is gepassioneerd door het gebruik van AI/ML en clouddiensten om de patiëntenzorg te verbeteren.
Jasleen Grewal is een Applied Scientist bij Amazon Web Services, waar ze samenwerkt met AWS-klanten om problemen in de echte wereld op te lossen met behulp van machine learning, met speciale aandacht voor precisiegeneeskunde en genomica. Ze heeft een sterke achtergrond in bio-informatica, oncologie en klinische genomica. Ze is gepassioneerd door het gebruik van AI/ML en clouddiensten om de patiëntenzorg te verbeteren.
 Selvan Senthivel is een Senior ML Engineer bij het Amazon ML Solutions Lab bij AWS, gericht op het helpen van klanten op het gebied van machine learning, deep learning-problemen en end-to-end ML-oplossingen. Hij was een van de oprichters van de technische leiding van Amazon Comprehend Medical en droeg bij aan het ontwerp en de architectuur van meerdere AWS AI-services.
Selvan Senthivel is een Senior ML Engineer bij het Amazon ML Solutions Lab bij AWS, gericht op het helpen van klanten op het gebied van machine learning, deep learning-problemen en end-to-end ML-oplossingen. Hij was een van de oprichters van de technische leiding van Amazon Comprehend Medical en droeg bij aan het ontwerp en de architectuur van meerdere AWS AI-services.
 Ruilin Zhang is een SDE bij het Amazon ML Solutions Lab bij AWS. Hij helpt klanten bij het adopteren van AWS AI-services door oplossingen te bouwen om veelvoorkomende zakelijke problemen aan te pakken.
Ruilin Zhang is een SDE bij het Amazon ML Solutions Lab bij AWS. Hij helpt klanten bij het adopteren van AWS AI-services door oplossingen te bouwen om veelvoorkomende zakelijke problemen aan te pakken.
 Shan Rai is een Sr. ML Strategist bij het Amazon ML Solutions Lab bij AWS. Hij werkt samen met klanten in een breed spectrum van industrieën om hun meest dringende en innovatieve zakelijke behoeften op te lossen met behulp van AWS' brede cloudgebaseerde AI/ML-services.
Shan Rai is een Sr. ML Strategist bij het Amazon ML Solutions Lab bij AWS. Hij werkt samen met klanten in een breed spectrum van industrieën om hun meest dringende en innovatieve zakelijke behoeften op te lossen met behulp van AWS' brede cloudgebaseerde AI/ML-services.
 Lin Lee Cheong is een Applied Science Manager bij het Amazon ML Solutions Lab-team bij AWS. Ze werkt samen met strategische AWS-klanten om kunstmatige intelligentie en machine learning te verkennen en toe te passen om nieuwe inzichten te ontdekken en complexe problemen op te lossen.
Lin Lee Cheong is een Applied Science Manager bij het Amazon ML Solutions Lab-team bij AWS. Ze werkt samen met strategische AWS-klanten om kunstmatige intelligentie en machine learning te verkennen en toe te passen om nieuwe inzichten te ontdekken en complexe problemen op te lossen.