
Dit is een gastpost die mede is geschreven door Maik Leuthold en Nick Harmening van BMW Group.
De BMW Group heeft zijn hoofdkantoor in München, Duitsland, waar het bedrijf toezicht houdt op 149,000 werknemers en auto's en motorfietsen produceert in meer dan 30 productielocaties in 15 landen. Deze multinationale productiestrategie volgt een nog internationaler en uitgebreider leveranciersnetwerk.
Zoals veel autobedrijven over de hele wereld heeft de BMW Group te maken gehad met uitdagingen in zijn toeleveringsketen als gevolg van het wereldwijde tekort aan halfgeleiders. Het creëren van transparantie over de huidige en toekomstige vraag naar halfgeleiders van BMW Group is een belangrijk strategisch aspect om samen met leveranciers en fabrikanten van halfgeleiders tekorten op te lossen. De fabrikanten moeten de exacte huidige en toekomstige halfgeleidervolume-informatie van BMW Group kennen, wat effectief zal helpen bij het sturen van het beschikbare wereldwijde aanbod.
De belangrijkste vereiste is om een geautomatiseerde, transparante en langetermijnvoorspelling van de vraag naar halfgeleiders te hebben. Bovendien moet dit prognosesysteem gegevensverrijkingsstappen bieden, inclusief bijproducten, dienen als de masterdata rond het halfgeleiderbeheer en verdere gebruiksscenario's bij de BMW Group mogelijk maken.
Om deze use case mogelijk te maken, gebruikten we het cloud-native dataplatform van de BMW Group, de Cloud Data Hub. In 2019 besloot de BMW Group om haar on-premises data lake opnieuw te ontwerpen en te verplaatsen naar de AWS Cloud om datagestuurde innovatie mogelijk te maken en tegelijkertijd te schalen met de dynamische behoeften van de organisatie. De Cloud Data Hub verwerkt en combineert geanonimiseerde gegevens van voertuigsensoren en andere bronnen in de hele onderneming om deze gemakkelijk toegankelijk te maken voor interne teams die klantgerichte en interne applicaties maken. Raadpleeg voor meer informatie over de Cloud Data Hub BMW Group gebruikt op AWS gebaseerd datameer om de kracht van data te ontsluiten.
In dit bericht delen we hoe de BMW Group de vraag naar halfgeleiders analyseert met behulp van AWS lijm.
Logica en systemen achter de vraagprognose
De eerste stap op weg naar de vraagprognose is de identificatie van halfgeleiderrelevante componenten van een voertuigtype. Elk onderdeel wordt beschreven door een uniek onderdeelnummer, dat in alle systemen als sleutel dient om dit onderdeel te identificeren. Een onderdeel kan bijvoorbeeld een koplamp of een stuurwiel zijn.
Om historische redenen zijn de vereiste gegevens voor deze aggregatiestap geïsoleerd en verschillend weergegeven in diverse systemen. Omdat elk bronsysteem en gegevenstype zijn eigen schema en indeling heeft, is het bijzonder moeilijk om analyses uit te voeren op basis van deze gegevens. Sommige bronsystemen zijn al beschikbaar in de Cloud Data Hub (bijvoorbeeld deelstamgegevens), daarom is het eenvoudig om te consumeren vanuit ons AWS-account. Om toegang te krijgen tot de resterende gegevensbronnen, moeten we specifieke opnametaken bouwen die gegevens uit het betreffende systeem lezen.
Het volgende schema illustreert de aanpak.
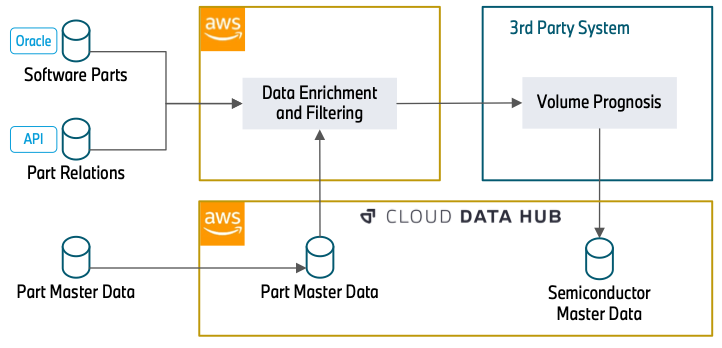
De dataverrijking begint met een Oracle Database (Software Parts) die onderdeelnummers bevat die gerelateerd zijn aan software. Dit kan de besturingseenheid van een koplamp zijn of een camerasysteem voor geautomatiseerd rijden. Omdat halfgeleiders de basis vormen voor het draaien van software, vormt deze database de basis van onze gegevensverwerking.
In de volgende stap gebruiken we REST API's (Part Relations) om de data te verrijken met verdere attributen. Dit omvat hoe onderdelen aan elkaar gerelateerd zijn (bijvoorbeeld een specifieke regeleenheid die in een koplamp wordt geïnstalleerd) en over welke tijdspanne een onderdeelnummer in een voertuig wordt ingebouwd. De kennis over de onderdeelrelaties is essentieel om te begrijpen hoe een specifieke halfgeleider, in dit geval de besturingseenheid, relevant is voor een meer algemeen onderdeel, de koplamp. De tijdelijke informatie over het gebruik van onderdeelnummers stelt ons in staat om verouderde onderdeelnummers uit te filteren, die in de toekomst niet meer zullen worden gebruikt en daarom niet relevant zijn in de prognose.
De data (Part Master Data) kan direct worden geconsumeerd vanuit de Cloud Data Hub. Deze database bevat attributen over de status en materiaalsoorten van een onderdeelnummer. Deze informatie is vereist om onderdeelnummers uit te filteren die we in de vorige stappen hebben verzameld, maar is niet relevant voor halfgeleiders. Met de informatie die is verzameld uit de API's, worden deze gegevens ook opgevraagd om verdere onderdeelnummers te extraheren die niet zijn opgenomen in de vorige stappen.
Na gegevensverrijking en filtering leest een systeem van derden de gefilterde onderdeelgegevens en verrijkt de halfgeleiderinformatie. Vervolgens voegt het de volume-informatie van de componenten toe. Ten slotte levert het de algehele prognose van de vraag naar halfgeleiders centraal aan de Cloud Data Hub.
Toegepaste diensten
Onze oplossing maakt gebruik van de serverless services AWS lijm en Amazon eenvoudige opslagservice (Amazon S3) om ETL-workflows (extraheren, transformeren en laden) uit te voeren zonder een infrastructuur te beheren. Het verlaagt ook de kosten door alleen te betalen voor de tijd dat taken worden uitgevoerd. De serverloze aanpak past heel goed in het schema van onze workflow, omdat we de werklast maar één keer per week uitvoeren.
Omdat we verschillende gegevensbronsystemen gebruiken, evenals complexe verwerking en aggregatie, is het belangrijk om ETL-taken te ontkoppelen. Hierdoor kunnen we elke gegevensbron onafhankelijk verwerken. We hebben de datatransformatie ook opgesplitst in verschillende modules (Dataggregatie, Datafiltering en Datavoorbereiding) om het systeem transparanter en gemakkelijker te onderhouden te maken. Deze aanpak helpt ook bij uitbreiding of wijziging van bestaande arbeidsplaatsen.
Hoewel elke module specifiek is voor een gegevensbron of een bepaalde gegevenstransformatie, gebruiken we herbruikbare blokken in elke taak. Dit stelt ons in staat om elk type bewerking te verenigen en vereenvoudigt de procedure voor het toevoegen van nieuwe gegevensbronnen en transformatiestappen in de toekomst.
In onze opzet volgen we de beste beveiligingspraktijk van het principe van de minste bevoegdheden, om ervoor te zorgen dat de informatie wordt beschermd tegen onbedoelde of onnodige toegang. Daarom heeft elke module AWS Identiteits- en toegangsbeheer (IAM)-rollen met alleen de benodigde machtigingen, namelijk toegang tot alleen gegevensbronnen en buckets waarmee de taak te maken heeft. Raadpleeg voor meer informatie over best practices voor beveiliging Best practices voor beveiliging in IAM.
Overzicht oplossingen
Het volgende diagram toont de algehele workflow waarin verschillende AWS Glue-taken opeenvolgend met elkaar communiceren.

Zoals we eerder vermeldden, gebruikten we de Cloud Data Hub, Oracle DB en andere gegevensbronnen waarmee we communiceren via de REST API. De eerste stap van de oplossing is de Data Source Ingest-module, die de gegevens uit verschillende gegevensbronnen opneemt. Voor dat doel lezen AWS Glue-taken informatie uit verschillende gegevensbronnen en schrijven ze naar de S3-bronbuckets. Opgenomen gegevens worden opgeslagen in de versleutelde buckets en sleutels worden beheerd door AWS Sleutelbeheerservice (AWS KMS).
Na de stap Gegevensbronopname verzamelen en verrijken tussenliggende taken de tabellen met andere gegevensbronnen, zoals de versie en categorieën van componenten, productiedatums van modellen, enzovoort. Vervolgens schrijven ze ze in de tussenliggende buckets in de Data Aggregation-module, waardoor een uitgebreide en overvloedige datarepresentatie ontstaat. Bovendien creëren de modules Gegevensfiltering en Gegevensvoorbereiding, volgens de bedrijfslogica-workflow, de definitieve stamgegevenstabel met alleen actuele en productierelevante informatie.
De AWS Glue-workflow beheert al deze opnametaken en filtertaken end-to-end. Een AWS Glue-workflowschema wordt wekelijks geconfigureerd om de workflow op woensdag uit te voeren. Terwijl de werkstroom wordt uitgevoerd, schrijft elke taak uitvoeringslogboeken (info of fout). Amazon eenvoudige meldingsservice (Amazon SNS) en Amazon Cloud Watch voor bewakingsdoeleinden. Amazon SNS stuurt de uitvoeringsresultaten door naar de monitoringtools, zoals Mail, Teams of Slack-kanalen. In het geval van een fout in de taken, waarschuwt Amazon SNS de luisteraars ook over het resultaat van de taakuitvoering om actie te ondernemen.
Als laatste stap van de oplossing leest het externe systeem de hoofdtabel uit de voorbereide databucket via Amazone Athene. Na verdere data-engineeringstappen zoals verrijking van halfgeleiderinformatie en integratie van volume-informatie, wordt het uiteindelijke masterdata-item in de Cloud Data Hub geschreven. Met de gegevens die nu in de Cloud Data Hub worden geleverd, kunnen andere use cases deze halfgeleiderstamgegevens gebruiken zonder meerdere interfaces naar verschillende bronsystemen te hoeven bouwen.
Zakelijk resultaat
De projectresultaten bieden de BMW Group een substantiële transparantie over hun vraag naar halfgeleiders voor hun gehele voertuigportfolio in het heden en in de toekomst. De oprichting van een database van die omvang stelt de BMW Group in staat om nog meer gebruiksscenario's vast te stellen ten voordele van meer transparantie in de toeleveringsketen en een duidelijkere en diepere uitwisseling met eerstelijnsleveranciers en fabrikanten van halfgeleiders. Het helpt niet alleen om de huidige veeleisende marktsituatie op te lossen, maar ook om in de toekomst veerkrachtiger te zijn. Daarom is het een grote stap naar een digitale, transparante toeleveringsketen.
Conclusie
Dit bericht beschrijft hoe de vraag naar halfgeleiders uit veel gegevensbronnen met big data-taken in een AWS Glue-workflow kan worden geanalyseerd. Een serverloze architectuur met minimale diversiteit aan services maakt de codebasis en architectuur eenvoudig te begrijpen en te onderhouden. Ga voor meer informatie over het gebruik van AWS Glue-workflows en -taken voor serverloze orkestratie naar de AWS lijm service pagina.
Over de auteurs
 Maik Leuthold is projectleider bij de BMW Group voor geavanceerde analyses op het gebied van toeleveringsketen en inkoop, en leidt de digitaliseringsstrategie voor het beheer van halfgeleiders.
Maik Leuthold is projectleider bij de BMW Group voor geavanceerde analyses op het gebied van toeleveringsketen en inkoop, en leidt de digitaliseringsstrategie voor het beheer van halfgeleiders.
 Nick Harmening is een IT-projectleider bij de BMW Group en een AWS-gecertificeerde Solutions Architect. Hij bouwt en exploiteert cloud-native applicaties met een focus op data-engineering en machine learning.
Nick Harmening is een IT-projectleider bij de BMW Group en een AWS-gecertificeerde Solutions Architect. Hij bouwt en exploiteert cloud-native applicaties met een focus op data-engineering en machine learning.
 Goksel Sarikaya is Senior Cloud Application Architect bij AWS Professional Services. Hij stelt klanten in staat om schaalbare, kosteneffectieve en concurrerende applicaties te ontwerpen door middel van de innovatieve productie van het AWS-platform. Hij helpt hen om de bedrijfsresultaten van klanten en partners te versnellen tijdens hun digitale transformatietraject.
Goksel Sarikaya is Senior Cloud Application Architect bij AWS Professional Services. Hij stelt klanten in staat om schaalbare, kosteneffectieve en concurrerende applicaties te ontwerpen door middel van de innovatieve productie van het AWS-platform. Hij helpt hen om de bedrijfsresultaten van klanten en partners te versnellen tijdens hun digitale transformatietraject.
 Alexander Tselikov is een Data Architect bij AWS Professional Services die gepassioneerd is om klanten te helpen bij het bouwen van schaalbare data-, analyse- en ML-oplossingen om tijdige inzichten mogelijk te maken en cruciale zakelijke beslissingen te nemen.
Alexander Tselikov is een Data Architect bij AWS Professional Services die gepassioneerd is om klanten te helpen bij het bouwen van schaalbare data-, analyse- en ML-oplossingen om tijdige inzichten mogelijk te maken en cruciale zakelijke beslissingen te nemen.
 Rahul Shaurya is Senior Big Data Architect bij Amazon Web Services. Hij helpt en werkt nauw samen met klanten bij het bouwen van dataplatforms en analytische applicaties op AWS. Buiten zijn werk houdt Rahul ervan lange wandelingen te maken met zijn hond Barney.
Rahul Shaurya is Senior Big Data Architect bij Amazon Web Services. Hij helpt en werkt nauw samen met klanten bij het bouwen van dataplatforms en analytische applicaties op AWS. Buiten zijn werk houdt Rahul ervan lange wandelingen te maken met zijn hond Barney.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoAiStream. Web3 gegevensintelligentie. Kennis versterkt. Toegang hier.
- De toekomst slaan met Adryenn Ashley. Toegang hier.
- Bron: https://aws.amazon.com/blogs/big-data/how-the-bmw-group-analyses-semiconductor-demand-with-aws-glue/