
U kunt nu machine learning-modellen (ML) opnieuw trainen en batchvoorspellingsworkflows automatiseren met bijgewerkte datasets Amazon SageMaker-canvas, waardoor het gemakkelijker wordt om voortdurend de modelprestaties en de rijefficiëntie te leren en te verbeteren. De effectiviteit van een ML-model hangt af van de kwaliteit en relevantie van de gegevens waarop het is getraind. Naarmate de tijd vordert, kunnen de onderliggende patronen, trends en verdelingen in de gegevens veranderen. Door de dataset bij te werken, zorgt u ervoor dat het model leert van de meest recente en representatieve gegevens, waardoor het beter in staat is nauwkeurige voorspellingen te doen. Canvas ondersteunt nu het automatisch en handmatig bijwerken van datasets, zodat je de nieuwste versie van de tabel-, afbeeldings- en documentdataset kunt gebruiken voor het trainen van ML-modellen.
Nadat het model is getraind, wilt u er mogelijk voorspellingen op uitvoeren. Door batchvoorspellingen uit te voeren op een ML-model kunnen meerdere datapunten tegelijkertijd worden verwerkt in plaats van voorspellingen één voor één te doen. Het automatiseren van dit proces zorgt voor efficiëntie, schaalbaarheid en tijdige besluitvorming. Nadat de voorspellingen zijn gegenereerd, kunnen ze verder worden geanalyseerd, geaggregeerd of gevisualiseerd om inzichten te verkrijgen, patronen te identificeren of weloverwogen beslissingen te nemen op basis van de voorspelde uitkomsten. Canvas ondersteunt nu het opzetten van een geautomatiseerde batchvoorspellingsconfiguratie en het daaraan koppelen van een dataset. Wanneer de bijbehorende dataset handmatig of volgens een schema wordt vernieuwd, wordt automatisch een batchvoorspellingsworkflow geactiveerd voor het overeenkomstige model. De resultaten van de voorspellingen kunnen inline worden bekeken of gedownload voor latere beoordeling.
In dit bericht laten we zien hoe u ML-modellen opnieuw kunt trainen en batchvoorspellingen kunt automatiseren met behulp van bijgewerkte datasets in Canvas.
Overzicht van de oplossing
Voor onze use case spelen we de rol van bedrijfsanalist voor een e-commercebedrijf. Ons productteam wil dat we de meest kritische statistieken bepalen die de aankoopbeslissing van een klant beïnvloeden. Hiervoor trainen we een ML-model in Canvas met een online sessiedataset van de website van de klant van het bedrijf. We evalueren de prestaties van het model en trainen het model indien nodig opnieuw met aanvullende gegevens om te zien of dit de prestaties van het bestaande model verbetert of niet. Om dit te doen, gebruiken we de mogelijkheid om de dataset automatisch bij te werken in Canvas en trainen we ons bestaande ML-model opnieuw met de nieuwste versie van de trainingsdataset. Vervolgens configureren we automatische batchvoorspellingsworkflows: wanneer de bijbehorende voorspellingsgegevensset wordt bijgewerkt, wordt automatisch de batchvoorspellingstaak op het model geactiveerd en worden de resultaten beschikbaar gemaakt voor beoordeling.
De workflowstappen zijn als volgt:
- Upload de gedownloade online sessiegegevens van de website van de klant naar Amazon eenvoudige opslagservice (Amazon S3) en maak een nieuwe trainingsgegevensset Canvas. Voor de volledige lijst met ondersteunde gegevensbronnen raadpleegt u Gegevens importeren in Amazon SageMaker Canvas.
- Bouw ML-modellen en analyseer hun prestatiestatistieken. Raadpleeg de stappen voor meer informatie bouw een aangepast ML-model in Canvas en de prestaties van een model evalueren.
- Stel automatische updates in voor de bestaande trainingsdataset en upload nieuwe gegevens naar de Amazon S3-locatie die deze dataset ondersteunt. Na voltooiing moet er een nieuwe datasetversie worden gemaakt.
- Gebruik de nieuwste versie van de gegevensset om het ML-model opnieuw te trainen en de prestaties ervan te analyseren.
- Instellen automatische batchvoorspellingen op de beter presterende modelversie en bekijk de voorspellingsresultaten.
Je kunt deze stappen in Canvas uitvoeren zonder ook maar één regel code te schrijven.
Overzicht van gegevens
De dataset bestaat uit kenmerkvectoren die behoren tot 12,330 sessies. De dataset is zo samengesteld dat elke sessie binnen een periode van één jaar aan een andere gebruiker toebehoort, om elke neiging tot een specifieke campagne, speciale dag, gebruikersprofiel of periode te vermijden. De volgende tabel geeft een overzicht van het gegevensschema.
| Kolomnaam | Data type | Omschrijving |
Administrative |
Numerieke | Aantal pagina's dat door de gebruiker is bezocht voor activiteiten gerelateerd aan gebruikersaccountbeheer. |
Administrative_Duration |
Numerieke | De hoeveelheid tijd die in deze categorie pagina's is doorgebracht. |
Informational |
Numerieke | Aantal pagina's van dit type (informatief) dat de gebruiker heeft bezocht. |
Informational_Duration |
Numerieke | De hoeveelheid tijd die in deze categorie pagina's is doorgebracht. |
ProductRelated |
Numerieke | Aantal pagina's van dit type (productgerelateerd) dat de gebruiker heeft bezocht. |
ProductRelated_Duration |
Numerieke | De hoeveelheid tijd die in deze categorie pagina's is doorgebracht. |
BounceRates |
Numerieke | Percentage bezoekers dat via die pagina de website betreedt en verlaat zonder extra taken te activeren. |
ExitRates |
Numerieke | Gemiddeld uitstappercentage van de door de gebruiker bezochte pagina's. Dit is het percentage mensen dat uw site vanaf die pagina heeft verlaten. |
Page Values |
Numerieke | Gemiddelde paginawaarde van de door de gebruiker bezochte pagina's. Dit is de gemiddelde waarde voor een pagina die een gebruiker heeft bezocht voordat hij op de doelpagina terechtkwam of een e-commercetransactie voltooide (of beide). |
SpecialDay |
binair | De functie 'Speciale dag' geeft aan hoe dicht de bezoektijd van de site ligt bij een specifieke speciale dag (zoals Moederdag of Valentijnsdag) waarop de kans groter is dat de sessies worden afgerond met een transactie. |
Month |
categorisch | Maand van het bezoek. |
OperatingSystems |
categorisch | Besturingssystemen van de bezoeker. |
Browser |
categorisch | Browser die door de gebruiker wordt gebruikt. |
Region |
categorisch | Geografische regio van waaruit de sessie door de bezoeker is gestart. |
TrafficType |
categorisch | Verkeersbron via welke de gebruiker de website heeft betreden. |
VisitorType |
categorisch | Of de klant nu een nieuwe gebruiker, een terugkerende gebruiker of een andere gebruiker is. |
Weekend |
binair | Als de klant de website in het weekend heeft bezocht. |
Revenue |
binair | Als er een aankoop is gedaan. |
Opbrengst is de doelkolom, die ons helpt te voorspellen of een klant een product wel of niet zal kopen.
De eerste stap is om download de dataset die we zullen gebruiken. Merk op dat deze dataset afkomstig is van de UCI Machine Learning Repository.
Voorwaarden
Voer voor dit overzicht de volgende vereiste stappen uit:
- Splits het gedownloade CSV-bestand dat 20,000 rijen bevat, in meerdere kleinere deelbestanden.
Dit is zodat we de functionaliteit voor het bijwerken van gegevenssets kunnen demonstreren. Zorg ervoor dat alle CSV-bestanden dezelfde headers hebben, anders kunt u fouten in het schema tegenkomen tijdens het maken van een trainingsgegevensset in Canvas.

- Maak een S3-bucket en upload deze
online_shoppers_intentions1-3.csvnaar de S3-bak.

- Reserveer 1,500 rijen uit het gedownloade CSV om batchvoorspellingen op uit te voeren nadat het ML-model is getraind.
- Verwijder
Revenuekolom uit deze bestanden, zodat wanneer u batchvoorspellingen uitvoert op het ML-model, dit de waarde is die uw model zal voorspellen.
Zorg ervoor dat alle predict*.csv bestanden hebben dezelfde headers, anders kunt u fouten in schema-mismatch tegenkomen tijdens het maken van een voorspellingsgegevensset (inferentie) in Canvas.

- Voer de nodige stappen uit om een SageMaker-domein en Canvas-app instellen.
Een gegevensset maken
Om een dataset in Canvas aan te maken, voer je de volgende stappen uit:
- Kies in Canvas datasets in het navigatievenster.
- Kies creëren En kies tabellarisch.

- Geef uw dataset een naam. Voor dit bericht noemen we onze trainingsdataset
OnlineShoppersIntentions. - Kies creëren.

- Kies uw gegevensbron (voor dit bericht is onze gegevensbron Amazon S3).
Houd er rekening mee dat op het moment van schrijven de functionaliteit voor het bijwerken van gegevenssets alleen wordt ondersteund voor Amazon S3 en lokaal geüploade gegevensbronnen.
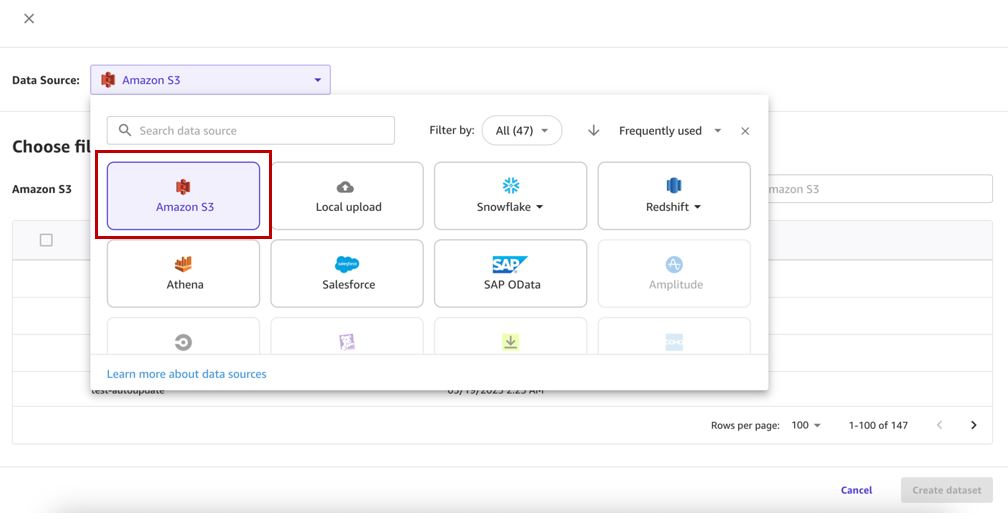
- Selecteer de bijbehorende bucket en upload de CSV-bestanden voor de dataset.
U kunt nu een dataset maken met meerdere bestanden.

- Bekijk een voorbeeld van alle bestanden in de gegevensset en kies Maak een dataset.

We hebben nu versie 1 van de OnlineShoppersIntentions dataset met drie gemaakte bestanden.
- Kies de dataset om de details te bekijken.

De Data tabblad toont een voorbeeld van de dataset.
- Kies Gegevenssetdetails om de bestanden te bekijken die de gegevensset bevat.
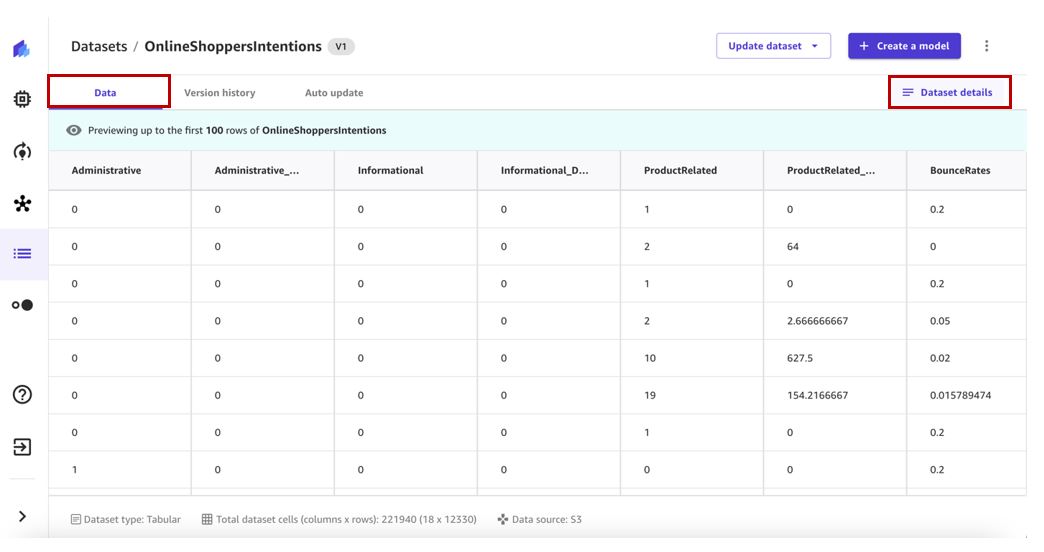
De Gegevenssetbestanden deelvenster toont de beschikbare bestanden.

- Kies de versie Geschiedenis tabblad om alle versies voor deze dataset te bekijken.
We kunnen zien dat onze eerste datasetversie drie bestanden heeft. Elke volgende versie zal alle bestanden van eerdere versies bevatten en een cumulatief overzicht van de gegevens bieden.
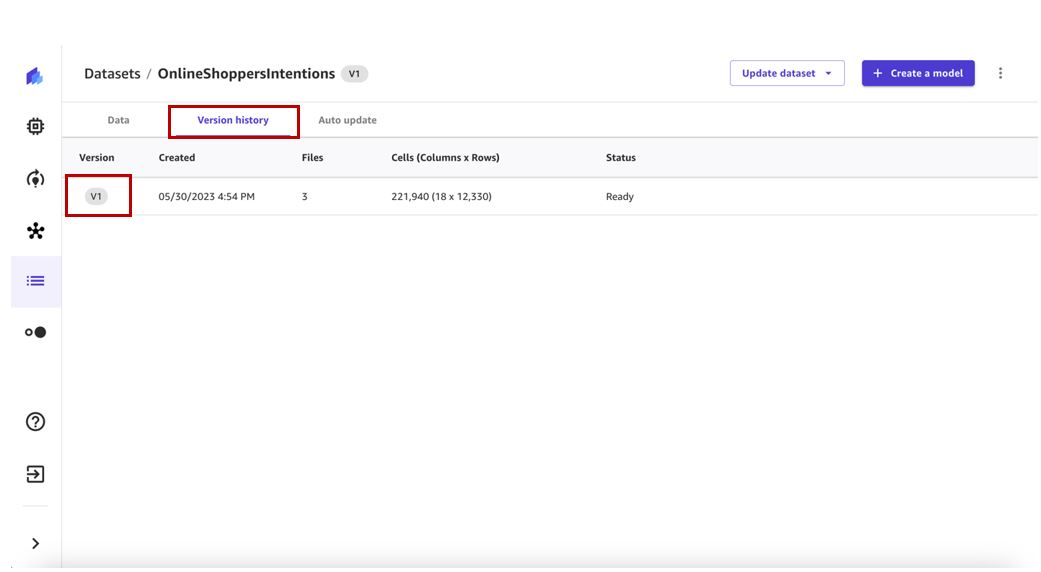
Train een ML-model met versie 1 van de gegevensset
Laten we een ML-model trainen met versie 1 van onze dataset.
- Kies in Canvas Mijn modellen in het navigatievenster.
- Kies Nieuw model.
- Voer een modelnaam in (bijvoorbeeld
OnlineShoppersIntentionsModel), selecteer het probleemtype en kies creëren.
- Selecteer de gegevensset. Voor dit bericht selecteren we de
OnlineShoppersIntentionsgegevensset.
Standaard haalt Canvas de meest recente datasetversie op voor training.

- Op de Bouw tabblad, kies de doelkolom die u wilt voorspellen. Voor dit bericht kiezen we de kolom Opbrengst.
- Kies Snel gebouwd.

De modeltraining duurt 2 tot 5 minuten. In ons geval geeft het getrainde model ons een score van 89%.

Automatische gegevenssetupdates instellen
Laten we onze dataset updaten met behulp van de automatische update-functionaliteit en meer gegevens binnenhalen en kijken of de modelprestaties verbeteren met de nieuwe versie van de dataset. Gegevenssets kunnen ook handmatig worden bijgewerkt.
- Op de datasets pagina, selecteert u de
OnlineShoppersIntentionsgegevensset en kies Gegevensset bijwerken. - Je kunt kiezen Handmatige update, wat een eenmalige updateoptie is, of Automatische update, waarmee u uw dataset automatisch volgens een schema kunt bijwerken. Voor dit bericht laten we de automatische updatefunctie zien.

U wordt doorgestuurd naar de Auto update tabblad voor de bijbehorende dataset. Dat kunnen we zien Automatische update inschakelen is momenteel uitgeschakeld.

- Toggle Automatische update inschakelen aan en specificeer de gegevensbron (vanaf dit schrijven worden Amazon S3-gegevensbronnen ondersteund voor automatische updates).
- Selecteer een frequentie en voer een starttijd in.
- Sla de configuratie-instellingen op.

Er is een gegevenssetconfiguratie voor automatisch bijwerken gemaakt. Het kan op elk moment worden bewerkt. Wanneer een overeenkomstige taak voor het bijwerken van gegevenssets volgens het opgegeven schema wordt geactiveerd, verschijnt de taak in het Werk geschiedenis pagina.

- Laten we vervolgens de
online_shoppers_intentions4.csv,online_shoppers_intentions5.csvenonline_shoppers_intentions6.csvbestanden naar onze S3-bucket.

Wij kunnen onze bestanden bekijken in de dataset-update-demo S3 emmer.

De updatetaak voor de gegevensset wordt volgens het opgegeven schema geactiveerd en er wordt een nieuwe versie van de gegevensset gemaakt.

Wanneer de taak is voltooid, bevat gegevenssetversie 2 alle bestanden van versie 1 en de aanvullende bestanden die zijn verwerkt door de gegevenssetupdatetaak. In ons geval heeft versie 1 drie bestanden en heeft de updatetaak drie extra bestanden opgehaald, zodat de uiteindelijke gegevenssetversie zes bestanden heeft.
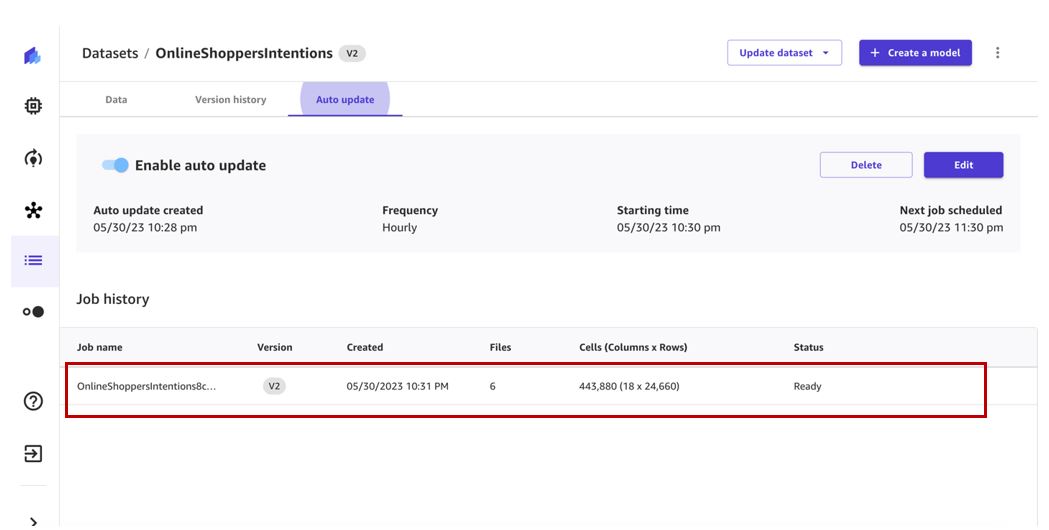
We kunnen de nieuwe versie bekijken die is gemaakt op de Versiegeschiedenis Tab.

De Data tabblad bevat een voorbeeld van de dataset en biedt een lijst met alle bestanden in de nieuwste versie van de dataset.

Train het ML-model opnieuw met een bijgewerkte gegevensset
Laten we ons ML-model opnieuw trainen met de nieuwste versie van de dataset.
- Op de Mijn modellen pagina, kies uw model.
- Kies Versie toevoegen.
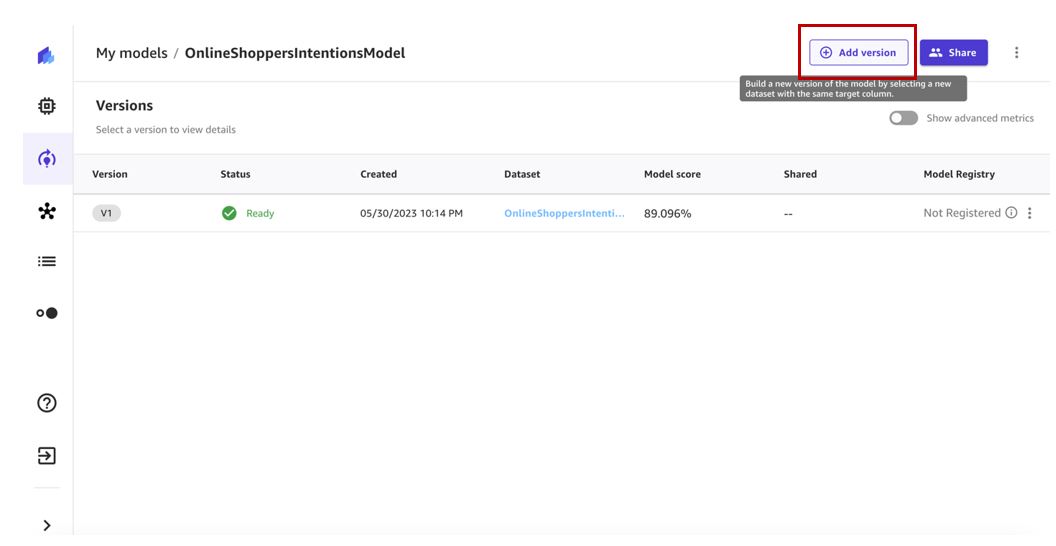
- Selecteer de nieuwste datasetversie (v2 in ons geval) en kies Selecteer dataset.
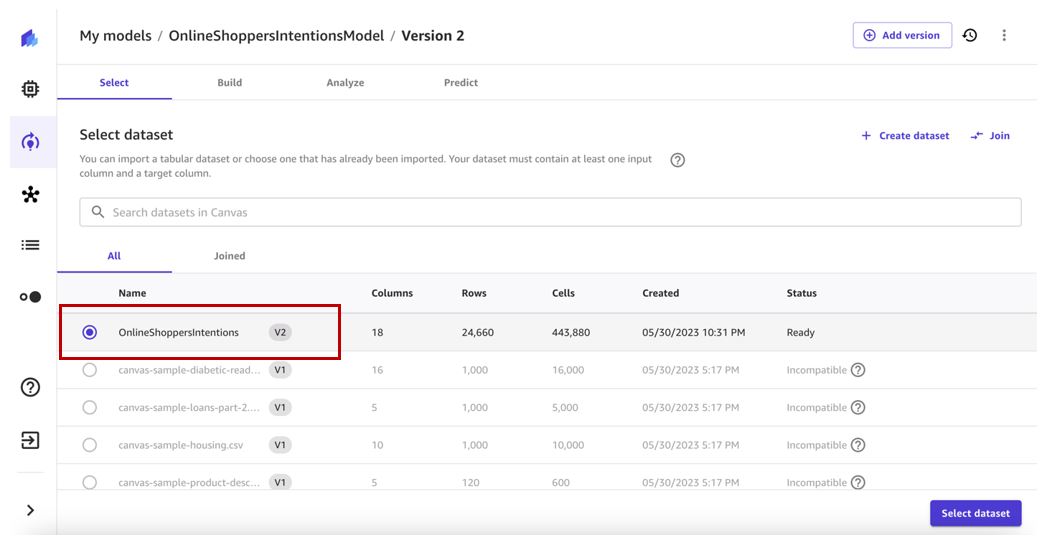
- Houd de doelkolom en bouwconfiguratie vergelijkbaar met de vorige modelversie.

Wanneer de training is voltooid, gaan we de prestaties van het model evalueren. De volgende schermafbeelding laat zien dat het toevoegen van extra gegevens en het opnieuw trainen van ons ML-model heeft bijgedragen aan het verbeteren van de prestaties van ons model.

Maak een voorspellingsgegevensset
Laten we, met een getraind ML-model, een gegevensset voor voorspellingen maken en er batchvoorspellingen op uitvoeren.
- Op de datasets pagina, maak een gegevensset in tabelvorm.
- Voer een naam in en kies creëren.

- Upload in onze S3-bucket één bestand met 500 rijen om te voorspellen.

Vervolgens stellen we automatische updates in voor de voorspellingsdataset.
- Toggle Automatische update inschakelen aan en geef de gegevensbron op.
- Selecteer de frequentie en geef een starttijd op.
- Sla de configuratie op.
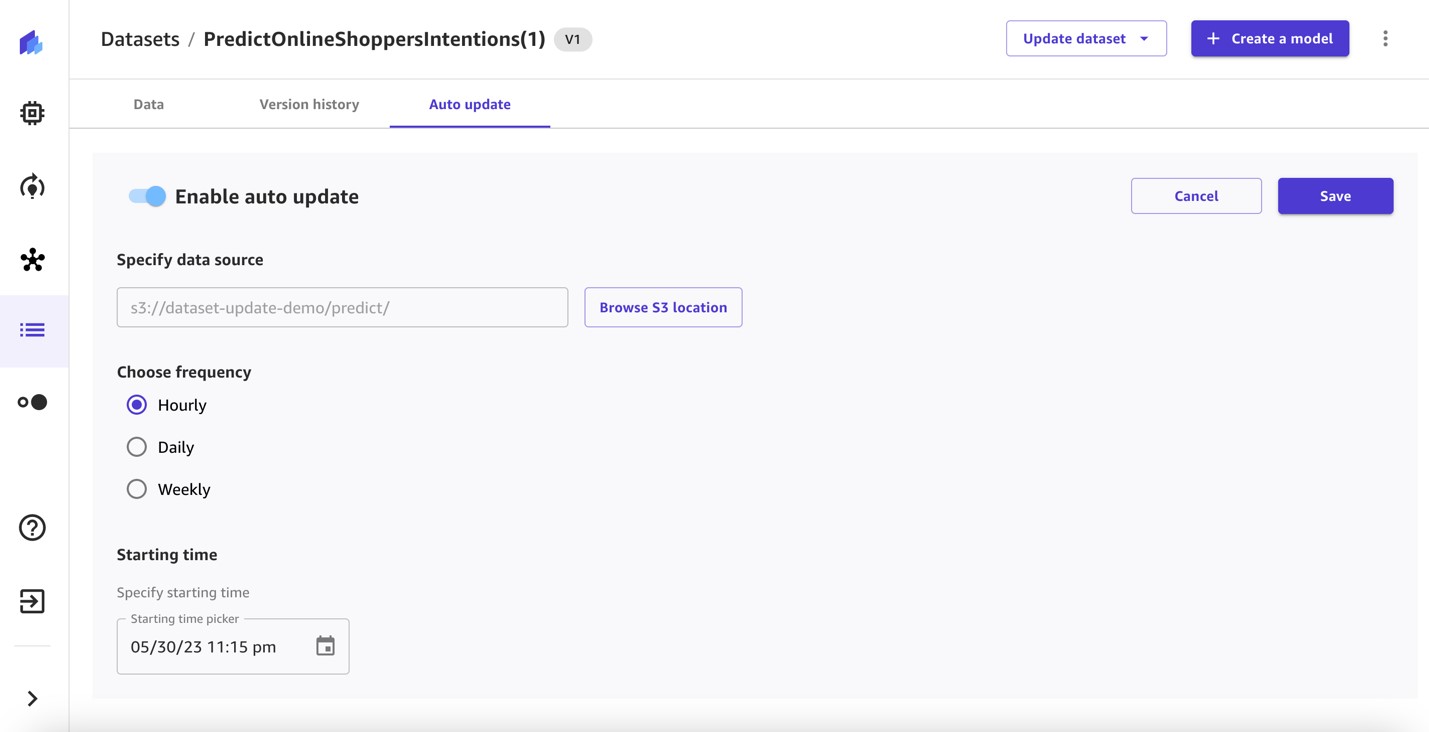
Automatiseer de batchvoorspellingsworkflow op een automatisch bijgewerkte dataset met voorspellingen
In deze stap configureren we onze automatische batchvoorspellingsworkflows.
- Op de Mijn modellen pagina, navigeer naar versie 2 van uw model.
- Op de Voorspellen tabblad, kies Batchvoorspelling en Automatisch.
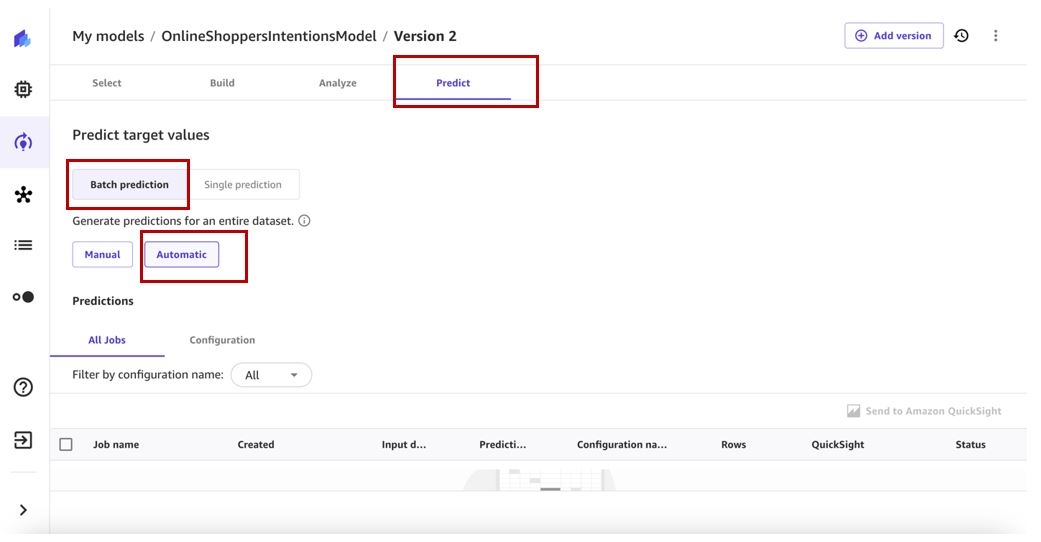
- Kies Selecteer dataset om de gegevensset op te geven waarvoor voorspellingen moeten worden gegenereerd.

- Selecteer het
predictdataset die we eerder hebben gemaakt en kiezen Kies dataset.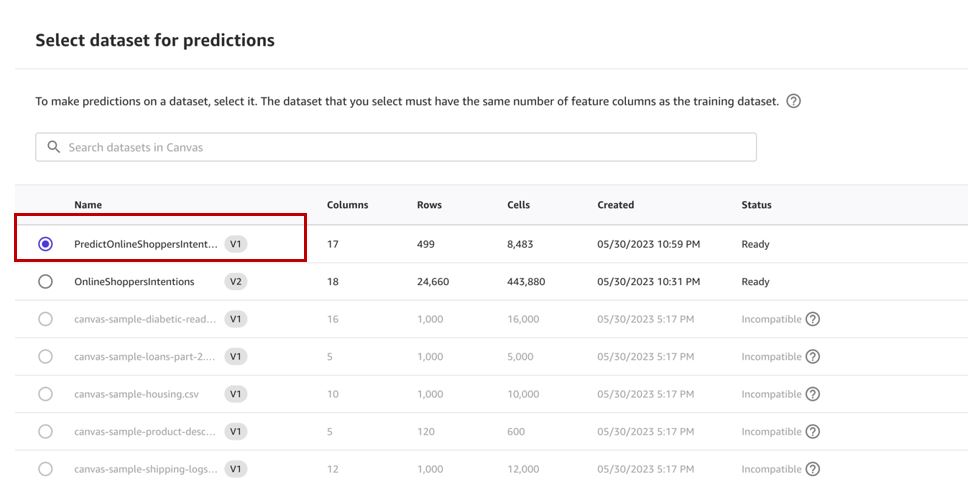
- Kies Instellen.

We hebben nu een automatische batchvoorspellingsworkflow. Dit wordt geactiveerd wanneer de Predict dataset wordt automatisch bijgewerkt.

Laten we nu meer CSV-bestanden uploaden naar het predict S3-map.
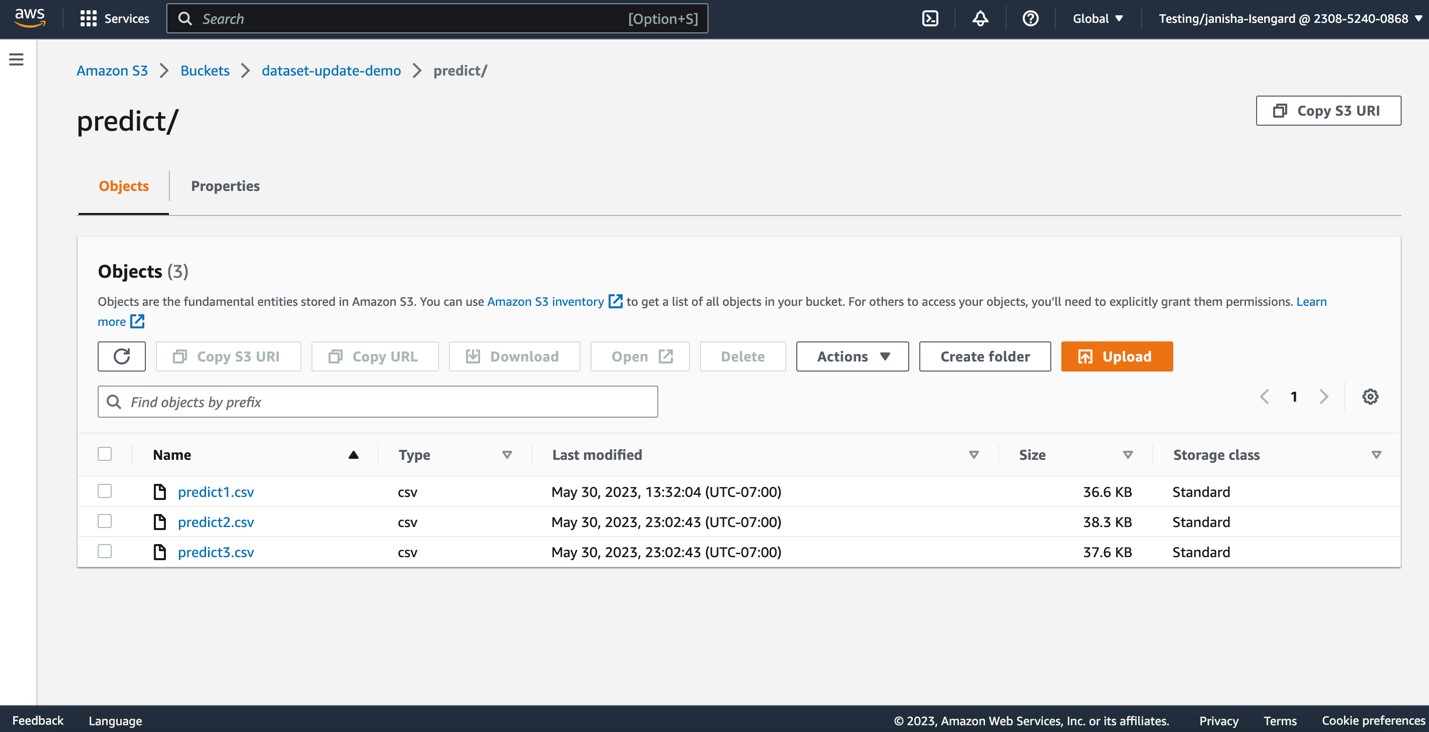
Deze bewerking activeert een automatische update van de predict gegevensset.
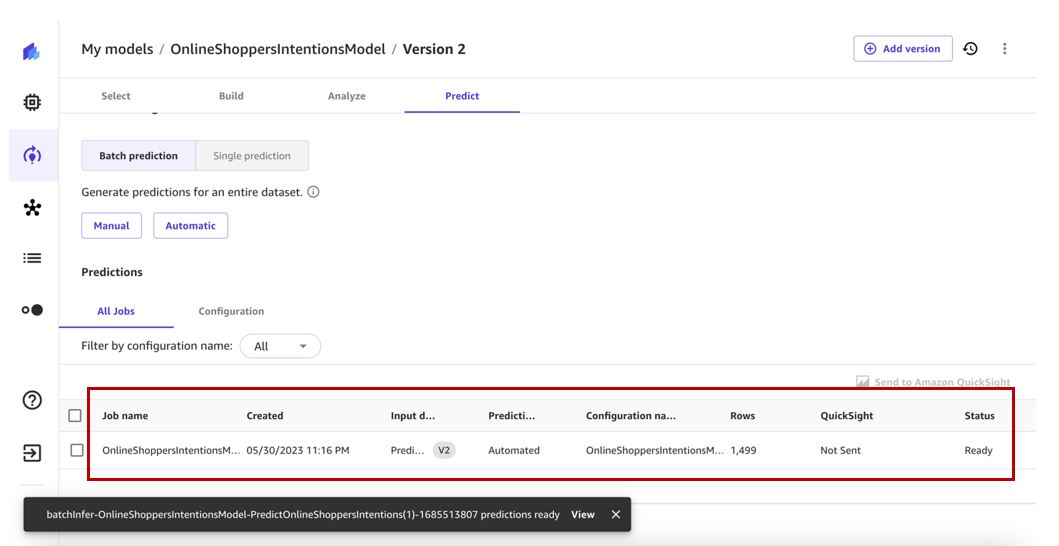
Dit zal op zijn beurt de automatische workflow voor batchvoorspellingen activeren en voorspellingen genereren die we kunnen bekijken.

We kunnen alle automatiseringen bekijken op de Automations pagina.

Dankzij de automatische datasetupdate en automatische batchvoorspellingsworkflows kunnen we de nieuwste versie van de tabel-, afbeeldings- en documentdataset gebruiken voor het trainen van ML-modellen, en batchvoorspellingsworkflows bouwen die automatisch worden geactiveerd bij elke datasetupdate.
Opruimen
Om te voorkomen dat er in de toekomst kosten in rekening worden gebracht, logt u uit bij Canvas. Canvas factureert je voor de duur van de sessie en we raden je aan uit te loggen bij Canvas als je het niet gebruikt. Verwijzen naar Afmelden bij Amazon SageMaker Canvas voor meer details.
Conclusie
In dit bericht hebben we besproken hoe we de nieuwe mogelijkheid voor het bijwerken van gegevenssets kunnen gebruiken om nieuwe gegevenssetversies te bouwen en onze ML-modellen te trainen met de nieuwste gegevens in Canvas. We hebben ook laten zien hoe we het proces van het uitvoeren van batchvoorspellingen op basis van bijgewerkte gegevens efficiënt kunnen automatiseren.
Om uw low-code/no-code ML-traject te starten, raadpleegt u de Handleiding voor Amazon SageMaker Canvas-ontwikkelaars.
Speciale dank aan iedereen die heeft bijgedragen aan de lancering.
Over de auteurs
 Janisha Anand is Senior Product Manager bij het SageMaker No/Low-Code ML-team, waartoe ook SageMaker Canvas en SageMaker Autopilot behoren. Ze houdt van koffie, actief blijven en tijd doorbrengen met haar gezin.
Janisha Anand is Senior Product Manager bij het SageMaker No/Low-Code ML-team, waartoe ook SageMaker Canvas en SageMaker Autopilot behoren. Ze houdt van koffie, actief blijven en tijd doorbrengen met haar gezin.
 Prashanth is Software Development Engineer bij Amazon SageMaker en werkt voornamelijk met SageMaker low-code en no-code producten.
Prashanth is Software Development Engineer bij Amazon SageMaker en werkt voornamelijk met SageMaker low-code en no-code producten.
 Esha Dutta is een Software Development Engineer bij Amazon SageMaker. Ze richt zich op het bouwen van ML-tools en -producten voor klanten. Buiten haar werk houdt ze van het buitenleven, yoga en wandelen.
Esha Dutta is een Software Development Engineer bij Amazon SageMaker. Ze richt zich op het bouwen van ML-tools en -producten voor klanten. Buiten haar werk houdt ze van het buitenleven, yoga en wandelen.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- EVM Financiën. Uniforme interface voor gedecentraliseerde financiën. Toegang hier.
- Quantum Media Groep. IR/PR versterkt. Toegang hier.
- PlatoAiStream. Web3 gegevensintelligentie. Kennis versterkt. Toegang hier.
- Bron: https://aws.amazon.com/blogs/machine-learning/retrain-ml-models-and-automate-batch-predictions-in-amazon-sagemaker-canvas-using-updated-datasets/