
Er wordt mij vaak gevraagd naar de rol van intercepts in lineaire regressiemodellen – vooral de negatieve intercepts. Hier is mijn blogpost over dat onderwerp, in eenvoudige woorden en met minimale statistische termen.
Om voorspellingen te doen, worden regressiemodellen gebruikt. De coëfficiënten in de vergelijking definieer de relatie tussen elke onafhankelijke variabele en de afhankelijke variabele. Het snijpunt of de constante in het regressiemodel vertegenwoordigt de gemiddelde waarde van de responsvariabele wanneer alle voorspellende variabelen in het model gelijk zijn aan nul. Bij lineaire regressie is het snijpunt de waarde van de afhankelijke variabele, dat wil zeggen Y wanneer alle waarden onafhankelijke variabelen zijn en Xs nul zijn. Als X soms gelijk is aan 0, is het snijpunt eenvoudigweg de verwachte waarde van Y bij die waarde. Wiskundig en picturaal wordt hieronder een eenvoudig lineair regressiemodel (SLR) weergegeven.

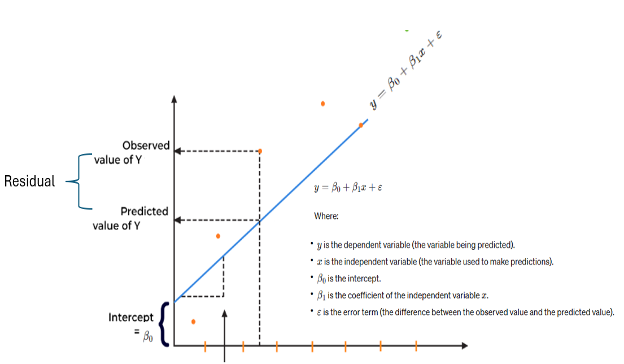
Maar wat is de zakelijke interpretatie van intercept in het regressiemodel? In zakelijke termen vertegenwoordigt een snijpunt een basislijn of startpunt voor de afhankelijke variabele, als de onafhankelijke variabelen op nul zijn ingesteld. Het snijpunt dient als startpunt voor het evalueren van de effecten van de onafhankelijke variabelen op de afhankelijke variabele. Het weerspiegelt het deel van de afhankelijke variabele dat niet wordt beïnvloed door de onafhankelijke variabelen die in het model zijn opgenomen. Het helpt bij het kwantificeren van de impact van veranderingen in de onafhankelijke variabelen ten opzichte van deze basiswaarde. In een verkoopvoorspellingsmodel kan het snijpunt bijvoorbeeld de verwachte omzet vertegenwoordigen wanneer alle marketinginspanningen, dwz de voorspellers, op nul staan. In de financiële sector kan het intercept vaste of overheadkosten vertegenwoordigen die worden gemaakt ongeacht het activiteitenniveau of andere factoren.
Technisch gezien kan het snijpunt in het lineaire regressiemodel positief, negatief of zelfs nul zijn.
- Positief onderscheppen: Als het snijpunt in het regressiemodel positief is, betekent dit dat de voorspelde waarde van de afhankelijke variabele (Y) wanneer de onafhankelijke variabele (X) nul is, positief is. Dit impliceert dat de regressielijn de y-as boven de nulwaarde kruist.
- Negatief snijpunt: Omgekeerd, als het snijpunt in een lineair regressiemodel negatief is, betekent dit dat de voorspelde waarde van Y wanneer X nul is, negatief is. In dit geval kruist de regressielijn de y-as onder de nulwaarde.
- Nul onderscheppen: Als het snijpunt in een regressiemodel nul is, betekent dit dat de regressielijn door de oorsprong (0,0) in de grafiek gaat. Dit betekent dat de voorspelde waarde van de afhankelijke variabele nul is als alle onafhankelijke variabelen ook nul zijn. Met andere woorden: er is geen extra constante term in de regressievergelijking. Deze situatie is extreem snel en zeer theoretisch.
Kortom, je gaat om met negatieve of positieve intercepts, en als je het negatieve intercept tegenkomt, ga je met het negatieve intercept op dezelfde manier om als met een positieve intercept. Maar in praktische termen kan een negatieve intercept wel of niet zinvol zijn, afhankelijk van de context van de gegevens die worden geanalyseerd. Als u bijvoorbeeld de temperatuur van de dag (X) en de verkoop van ijs (Y) analyseert, zou een negatieve onderschepping geen betekenis hebben, omdat het onmogelijk is om negatieve verkopen te hebben. Op andere domeinen, zoals de financiële analyse, zou een negatieve onderschepping echter zinvol kunnen zijn.
Hieronder staan enkele benaderingen die u kunt overwegen als u negatieve intercepts heeft:
- Controleer op gegevensfouten en aannames: Voordat u aanpassingen doorvoert, moet u ervoor zorgen dat aan de regressieaannames wordt voldaan. Dit omvat lineariteit, onafhankelijkheid, homoscedasticiteit (met betrekking tot residuen), normaliteit van de gegevensvariabelen en residuen, uitbijters en meer. Als deze aannames worden geschonden, moeten ze eerst worden aangepakt.
- Pas zakelijk inzicht en gezond verstand toe en controleer of de interpretatie van het negatieve intercept praktisch zinvol is. Een negatief intercept kan zinvol zijn, afhankelijk van wat het intercept vertegenwoordigt. In financiële gegevens zou een negatieve intercept bijvoorbeeld een startpunt onder nul kunnen aangeven, wat volkomen redelijk kan zijn. Maar als u gegevens over de temperatuur en de verkoop van ijs analyseert, zou een negatieve onderschepping geen betekenis hebben, aangezien het onmogelijk is om negatieve verkopen te hebben.
- Centreer de variabelen. Regressiemodellen zijn alleen geldig voor een bepaald bereik van gegevenswaarden. Maar soms kunnen de waarden van de onafhankelijke en afhankelijke variabelen buiten het gegeven bereik liggen. In dit opzicht houdt centreren in dat een constante waarde of een rekenkundig gemiddelde van een variabele (onafhankelijk) wordt afgetrokken van elk van zijn waarden. Dit kan de interpretatie vergemakkelijken, vooral als de onafhankelijke variabelen (Xs) nulwaarden hebben. Door de variabelen rond hun gemiddelden te centreren, vertegenwoordigt het snijpunt in principe de voorspelde waarde van de afhankelijke variabele wanneer de onafhankelijke variabelen hun gemiddelde waarden hebben bereikt. Ook kunnen extreme waarden of uitschieters in de gegevens in sommige gevallen leiden tot numerieke instabiliteit in de regressiemodellen. Het centreren van variabelen kan deze problemen verzachten door de schaal van de variabelen te verkleinen en het regressiemodel stabieler te maken.
- Zorg ervoor dat verstorende variabelen in het regressiemodel voorkomen. Het toevoegen van aanvullende verklarende variabelen of verstorende variabelen aan het regressiemodel kan het negatieve snijpunt helpen verklaren.
Over het algemeen is het belangrijk op te merken dat lineaire regressiemodellen gebaseerd zijn op aannames. Ten eerste gaan ze uit van een lineair verband tussen variabelen, wat in praktijkscenario's misschien niet altijd opgaat. Bovendien is lineaire regressie afhankelijk van normaal verdeelde gegevens en is deze zeer gevoelig voor uitschieters. Last but not least presteert lineaire regressie mogelijk niet goed met niet-lineaire relaties, en in dergelijke gevallen kunnen complexere modellen zoals polynomiale regressie of niet-lineaire regressie geschikter zijn.
Referentie
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://www.dataversity.net/understanding-linear-regression-intercepts-in-plain-language/