
Het trainen van grote taalmodellen (LLM's) met miljarden parameters kan een uitdaging zijn. Naast het ontwerpen van de modelarchitectuur, moeten onderzoekers state-of-the-art trainingstechnieken opzetten voor gedistribueerde training, zoals ondersteuning met gemengde precisie, gradiëntaccumulatie en checkpointing. Bij grote modellen is de trainingsopstelling zelfs nog uitdagender omdat het beschikbare geheugen in een enkel versnellerapparaat de grootte beperkt van modellen die alleen worden getraind met behulp van gegevensparallellisme, en het gebruik van modelparallelle training vereist extra aanpassingen aan de trainingscode. Bibliotheken zoals diepe snelheid (een open-source deep learning-optimalisatiebibliotheek voor PyTorch) pakt een aantal van deze uitdagingen aan en kan de ontwikkeling en training van modellen helpen versnellen.
In deze post hebben we een training opgezet op basis van Intel Habana Gaudi Amazon Elastic Compute-cloud (Amazone EC2) DL1 instanties en kwantificeer de voordelen van het gebruik van een schaalmodel zoals DeepSpeed. We presenteren schaalresultaten voor een transformatormodel van het encodertype (BERT met 340 miljoen tot 1.5 miljard parameters). Voor het model met 1.5 miljard parameters bereikten we een schaalefficiëntie van 82.7% over 128 versnellers (16 dl1.24xlarge instanties) met DeepSpeed ZeRO fase 1 optimalisaties. De optimalisatiestatussen werden door DeepSpeed gepartitioneerd om grote modellen te trainen met behulp van het gegevensparallelle paradigma. Deze benadering is uitgebreid om een model met 5 miljard parameters te trainen met behulp van gegevensparallellisme. We hebben ook Gaudi's eigen ondersteuning van het BF16-gegevenstype gebruikt voor kleinere geheugengrootte en betere trainingsprestaties in vergelijking met het gebruik van het FP32-gegevenstype. Als resultaat bereikten we pre-training (fase 1) modelconvergentie binnen 16 uur (ons doel was om binnen een dag een groot model te trainen) voor het BERT-model met 1.5 miljard parameters met behulp van de wikicorpus-nl dataset.
Trainingsopstelling
We hebben een beheerd rekencluster ingericht dat bestaat uit 16 dl1.24xlarge instanties met behulp van AWS-batch. We ontwikkelden een AWS Batch-workshop dat de stappen illustreert om het gedistribueerde trainingscluster met AWS Batch in te stellen. Elke dl1.24xlarge-instantie heeft acht Habana Gaudi-versnellers, elk met 32 GB geheugen en een volledig mesh RoCE-netwerk tussen kaarten met een totale bidirectionele interconnect-bandbreedte van elk 700 Gbps (zie Amazon EC2 DL1 instanties Deep Dive voor meer informatie). De dl1.24xlarge-cluster gebruikte er ook vier AWS Elastic Fabric-adapters (EFA), met in totaal 400 Gbps interconnectie tussen knooppunten.
De gedistribueerde trainingsworkshop illustreert de stappen voor het instellen van het gedistribueerde trainingscluster. De workshop toont de gedistribueerde trainingsopstelling met behulp van AWS Batch en in het bijzonder de functie voor parallelle taken met meerdere knooppunten om grootschalige gecontaineriseerde trainingstaken op volledig beheerde clusters te starten. Meer specifiek wordt een volledig beheerde AWS Batch-rekenomgeving gecreëerd met DL1-instanties. De containers worden uitgetrokken Amazon Elastic Container-register (Amazon ECR) en automatisch gelanceerd in de instanties in het cluster op basis van de parallelle taakdefinitie met meerdere knooppunten. De workshop wordt afgesloten met het uitvoeren van een multi-node, multi-HPU data parallelle training van een BERT-model (340 miljoen tot 1.5 miljard parameters) met behulp van PyTorch en DeepSpeed.
BERT 1.5B pre-training met DeepSpeed
Havana SynapseAI v1.5 en v1.6 ondersteuning voor DeepSpeed ZeRO1-optimalisaties. De Habana-vork van de DeepSpeed GitHub-repository bevat de aanpassingen die nodig zijn om de Gaudi-versnellers te ondersteunen. Er is volledige ondersteuning van gedistribueerde gegevensparallel (meerdere kaarten, meerdere instanties), ZeRO1-optimalisaties en BF16-gegevenstypen.
Al deze functies zijn ingeschakeld op de BERT 1.5B modelreferentierepository, dat een bidirectioneel encodermodel met 48 lagen, 1600 verborgen dimensies en 25 koppen introduceert, afgeleid van een BERT-implementatie. De repository bevat ook de baseline BERT Large-modelimplementatie: een neurale netwerkarchitectuur met 24 lagen, 1024 verborgen, 16 koppen en 340 miljoen parameters. De pre-training modelleringsscripts zijn afgeleid van het NVIDIA Deep Learning Voorbeelden-repository om de wikicorpus_en-gegevens te downloaden, de onbewerkte gegevens voor te verwerken tot tokens en de gegevens in kleinere h5-gegevenssets te verdelen voor gedistribueerde gegevensparallelle training. U kunt deze generieke benadering gebruiken om uw aangepaste PyTorch-modelarchitecturen te trainen met behulp van uw datasets met behulp van DL1-instanties.
Pre-training (fase 1) schaalresultaten
Voor het vooraf trainen van grote modellen op schaal hebben we ons voornamelijk gericht op twee aspecten van de oplossing: trainingsprestaties, gemeten aan de hand van de tijd die nodig is om te trainen, en kosteneffectiviteit om tot een volledig geconvergeerde oplossing te komen. Vervolgens gaan we dieper in op deze twee statistieken met BERT 1.5B pre-training als voorbeeld.
Schaalprestaties en tijd om te trainen
We beginnen met het meten van de prestaties van de BERT Large-implementatie als basis voor schaalbaarheid. De volgende tabel geeft een overzicht van de gemeten doorvoer van sequenties per seconde van 1-8 dl1.24xlarge instanties (met acht versnellerapparaten per instantie). Met de single-instance doorvoer als baseline hebben we de efficiëntie gemeten van het schalen over meerdere instances, wat een belangrijke hefboom is om inzicht te krijgen in de prijs-prestatie-trainingsmetriek.
| Aantal instanties | Aantal versnellers | Reeksen per seconde | Sequenties per seconde per versneller | Schaalefficiëntie |
| 1 | 8 | 1,379.76 | 172.47 | 100.0% |
| 2 | 16 | 2,705.57 | 169.10 | 98.04% |
| 4 | 32 | 5,291.58 | 165.36 | 95.88% |
| 8 | 64 | 9,977.54 | 155.90 | 90.39% |
De volgende afbeelding illustreert de schaalefficiëntie.

Voor BERT 1.5B hebben we de hyperparameters voor het model in de referentierepository aangepast om convergentie te garanderen. De effectieve batchgrootte per versneller was ingesteld op 384 (voor maximaal geheugengebruik), met microbatches van 16 per stap en 24 stappen van gradiëntaccumulatie. Leersnelheden van 0.0015 en 0.003 werden gebruikt voor respectievelijk 8 en 16 knooppunten. Met deze configuraties bereikten we convergentie van de fase 1 pre-training van BERT 1.5B over 8 dl1.24xlarge instanties (64 versnellers) in ongeveer 25 uur, en 15 uur over 16 dl1.24xlarge instanties (128 versnellers). De volgende afbeelding toont het gemiddelde verlies als functie van het aantal trainingsperioden, terwijl we het aantal versnellers opschalen.

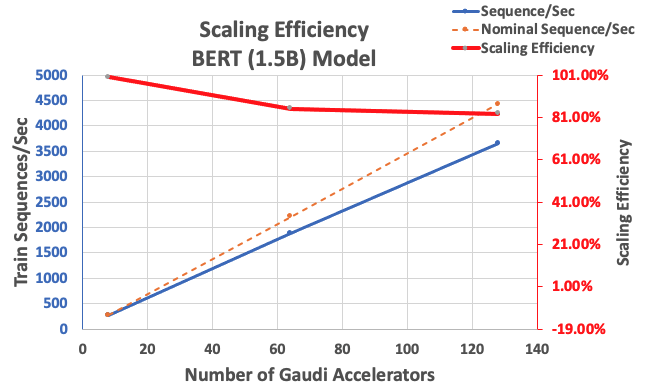
Met de eerder beschreven configuratie behaalden we 85% sterke schaalefficiëntie met 64 versnellers en 83% met 128 versnellers, uitgaande van een basislijn van 8 versnellers in één instantie. De volgende tabel vat de parameters samen.
| Aantal instanties | Aantal versnellers | Reeksen per seconde | Sequenties per seconde per versneller | Schaalefficiëntie |
| 1 | 8 | 276.66 | 34.58 | 100.0% |
| 8 | 64 | 1,883.63 | 29.43 | 85.1% |
| 16 | 128 | 3,659.15 | 28.59 | 82.7% |
De volgende afbeelding illustreert de schaalefficiëntie.
Conclusie
In dit bericht evalueerden we de ondersteuning voor DeepSpeed door Habana SynapseAI v1.5/v1.6 en hoe dit helpt bij het opschalen van LLM-training op Habana Gaudi-versnellers. Pre-training van een BERT-model met 1.5 miljard parameters duurde 16 uur om te convergeren op een cluster van 128 Gaudi-versnellers, met 85% sterke schaling. We moedigen u aan om de architectuur te bekijken die wordt gedemonstreerd in de AWS-werkplaats en overweeg het te gebruiken om aangepaste PyTorch-modelarchitecturen te trainen met behulp van DL1-instanties.
Over de auteurs
 Mahadevan Balasubramaniam is een Principal Solutions Architect voor Autonomous Computing met bijna 20 jaar ervaring op het gebied van door fysica doordrenkt deep learning, het bouwen en implementeren van digitale tweelingen voor industriële systemen op grote schaal. Mahadevan behaalde zijn doctoraat in werktuigbouwkunde aan het Massachusetts Institute of Technology en heeft meer dan 25 patenten en publicaties op zijn naam staan.
Mahadevan Balasubramaniam is een Principal Solutions Architect voor Autonomous Computing met bijna 20 jaar ervaring op het gebied van door fysica doordrenkt deep learning, het bouwen en implementeren van digitale tweelingen voor industriële systemen op grote schaal. Mahadevan behaalde zijn doctoraat in werktuigbouwkunde aan het Massachusetts Institute of Technology en heeft meer dan 25 patenten en publicaties op zijn naam staan.
 RJ is een ingenieur in het Search M5-team dat de inspanningen leidt voor het bouwen van grootschalige deep learning-systemen voor training en inferentie. Buiten zijn werk verkent hij verschillende keukens en speelt hij racketsporten.
RJ is een ingenieur in het Search M5-team dat de inspanningen leidt voor het bouwen van grootschalige deep learning-systemen voor training en inferentie. Buiten zijn werk verkent hij verschillende keukens en speelt hij racketsporten.
 Soendar Ranganathan is het hoofd van Business Development, ML Frameworks in het Amazon EC2-team. Hij richt zich op grootschalige ML-workloads voor AWS-services zoals Amazon EKS, Amazon ECS, Elastic Fabric Adapter, AWS Batch en Amazon SageMaker. Zijn ervaring omvat leidinggevende functies in productbeheer en productontwikkeling bij NetApp, Micron Technology, Qualcomm en Mentor Graphics.
Soendar Ranganathan is het hoofd van Business Development, ML Frameworks in het Amazon EC2-team. Hij richt zich op grootschalige ML-workloads voor AWS-services zoals Amazon EKS, Amazon ECS, Elastic Fabric Adapter, AWS Batch en Amazon SageMaker. Zijn ervaring omvat leidinggevende functies in productbeheer en productontwikkeling bij NetApp, Micron Technology, Qualcomm en Mentor Graphics.
 Abhinanda Patni is Senior Software Engineer bij Amazon Search. Hij richt zich op het bouwen van systemen en tooling voor schaalbare gedistribueerde deep learning-training en realtime inferentie.
Abhinanda Patni is Senior Software Engineer bij Amazon Search. Hij richt zich op het bouwen van systemen en tooling voor schaalbare gedistribueerde deep learning-training en realtime inferentie.
 Pierre Yves Aquilanti is Head of Frameworks ML Solutions bij Amazon Web Services, waar hij helpt bij het ontwikkelen van de beste cloudgebaseerde ML Frameworks-oplossingen in de branche. Zijn achtergrond ligt in High Performance Computing en voordat hij bij AWS kwam, werkte Pierre-Yves in de olie- en gasindustrie. Pierre-Yves komt oorspronkelijk uit Frankrijk en heeft een Ph.D. in computerwetenschappen aan de Universiteit van Lille.
Pierre Yves Aquilanti is Head of Frameworks ML Solutions bij Amazon Web Services, waar hij helpt bij het ontwikkelen van de beste cloudgebaseerde ML Frameworks-oplossingen in de branche. Zijn achtergrond ligt in High Performance Computing en voordat hij bij AWS kwam, werkte Pierre-Yves in de olie- en gasindustrie. Pierre-Yves komt oorspronkelijk uit Frankrijk en heeft een Ph.D. in computerwetenschappen aan de Universiteit van Lille.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- EVM Financiën. Uniforme interface voor gedecentraliseerde financiën. Toegang hier.
- Quantum Media Groep. IR/PR versterkt. Toegang hier.
- PlatoAiStream. Web3 gegevensintelligentie. Kennis versterkt. Toegang hier.
- Bron: https://aws.amazon.com/blogs/machine-learning/accelerate-pytorch-with-deepspeed-to-train-large-language-models-with-intel-habana-gaudi-based-dl1-ec2-instances/