
Vanaf versie 6.14, Amazon EMR-studio ondersteunt interactieve analyses op Amazon EMR Serverloos. U kunt nu EMR Serverless-applicaties gebruiken als rekenkracht, naast Amazon EMR op EC2-clusters en Amazon EPD op EKS virtuele clusters, om JupyterLab-notebooks uit te voeren vanuit EMR Studio Workspaces.
EMR Studio is een geïntegreerde ontwikkelomgeving (IDE) waarmee datawetenschappers en data-ingenieurs eenvoudig analysetoepassingen kunnen ontwikkelen, visualiseren en debuggen die zijn geschreven in PySpark, Python en Scala. EMR Serverless is een serverloze optie voor Amazon EMR Dat maakt het eenvoudig om open source big data-analyseframeworks zoals Apache Spark uit te voeren zonder clusters of servers te configureren, beheren en schalen.
In het bericht laten we zien hoe u het volgende kunt doen:
- Creëer een EMR serverloos eindpunt voor interactieve toepassingen
- Koppel het eindpunt aan een bestaande EMR Studio-omgeving
- Maak een notitieboekje en voer een interactieve toepassing uit
- Diagnose naadloos interactieve toepassingen vanuit EMR Studio
Voorwaarden
In een typische organisatie zal een AWS-accountbeheerder AWS-bronnen instellen, zoals AWS Identiteits- en Toegangsbeheer (IAM) rollen, Amazon eenvoudige opslagservice (Amazon S3) emmers, en Amazon virtuele privécloud (Amazon VPC) bronnen voor internettoegang en toegang tot andere bronnen in de VPC. Ze wijzen EMR Studio-beheerders toe die het opzetten van EMR Studios beheren en gebruikers toewijzen aan een specifieke EMR Studio. Zodra ze zijn toegewezen, kunnen EMR Studio-ontwikkelaars EMR Studio gebruiken om werklasten te ontwikkelen en te monitoren.
Zorg ervoor dat u bronnen zoals uw S3-bucket, VPC-subnetten en EMR Studio in dezelfde AWS-regio instelt.
Voer de volgende stappen uit om deze vereisten te implementeren:
- Start het volgende: AWS CloudFormatie stack.

- Voer waarden in voor Administrator wachtwoord en Ontwikkelaarswachtwoord en noteer de wachtwoorden die u maakt.
- Kies Volgende.
- Behoud de instellingen als standaard en kies Volgende weer.
- kies Ik erken dat AWS CloudFormation IAM-bronnen met aangepaste namen kan maken.
- Kies Verzenden.
We hebben ook instructies gegeven om deze bronnen handmatig te implementeren met voorbeeld-IAM-beleid in de GitHub repo.
Zet EMR Studio en een serverloze interactieve applicatie op
Nadat de AWS-accountbeheerder aan de vereisten heeft voldaan, kan de EMR Studio-beheerder inloggen op het AWS-beheerconsole om een EMR Studio-, Workspace- en EMR Serverless-applicatie te maken.
Creëer een EMR-studio en -werkruimte
De EMR Studio-beheerder moet inloggen op de console met behulp van de emrs-interactive-app-admin-user gebruikersgegevens. Als u de vereiste bronnen hebt geïmplementeerd met behulp van de meegeleverde CloudFormation-sjabloon, gebruikt u het wachtwoord dat u als invoerparameter hebt opgegeven.
- Kies op de Amazon EMR-console: EMR-serverloos in het navigatievenster.

- Kies Start.
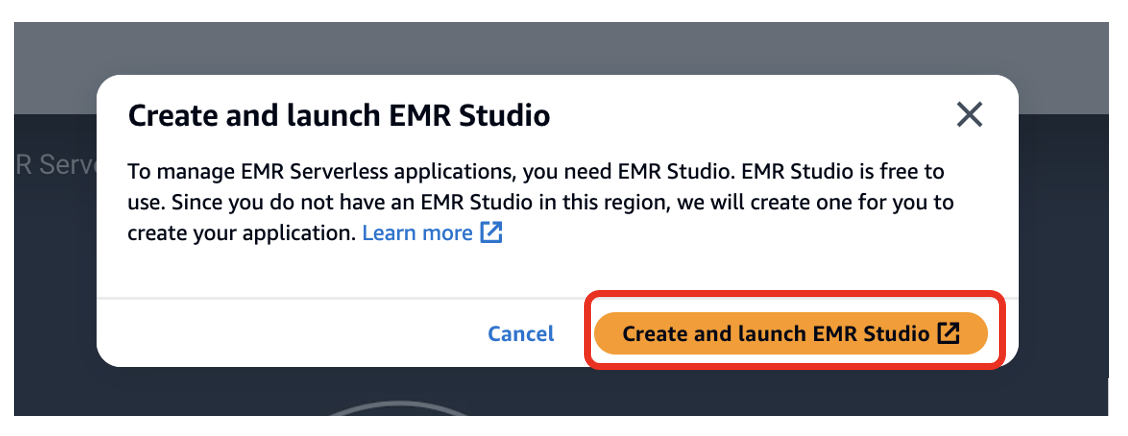
- kies Creëer en start EMR Studio.
Hierdoor wordt een Studio gemaakt met de standaardnaam studio_1 en een werkruimte met de standaardnaam My_First_Workspace. Er wordt een nieuw browsertabblad geopend voor de Studio_1 gebruikersomgeving.
Maak een EMR-serverloze applicatie
Voer de volgende stappen uit om een EMR serverloze applicatie te maken:
- Kies op de EMR Studio-console Toepassingen in het navigatievenster.
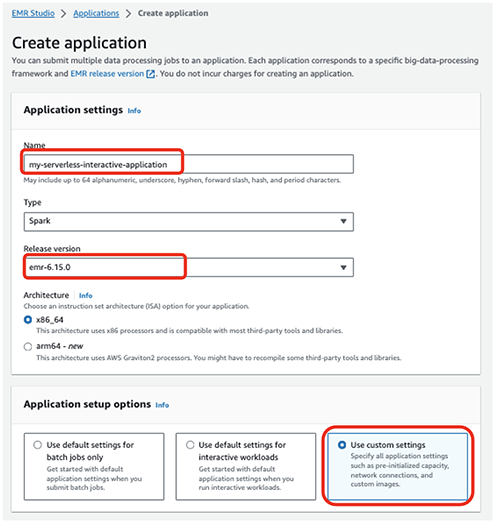
- Maak een Nieuwe Applicatie.
- Voor Naam, voer een naam in (bijvoorbeeld
my-serverless-interactive-application). - Voor Opties voor het instellen van de applicatieselecteer Gebruik aangepaste instellingen voor interactieve werklasten.
Voor interactieve toepassingen raden wij u als best practice aan om het stuurprogramma en de werkrollen vooraf geïnitialiseerd te houden door het vooraf geïnitialiseerde capaciteit op het moment dat de applicatie wordt gemaakt. Dit creëert effectief een warme pool van werknemers voor een applicatie en houdt de bronnen gereed voor gebruik, waardoor de applicatie binnen enkele seconden kan reageren. Voor meer best practices voor het maken van EMR-serverloze toepassingen, zie Definieer resourcelimieten per team voor big data-workloads met behulp van Amazon EMR Serverless.
- In het Interactief eindpunt sectie, selecteer Schakel Interactief eindpunt in.
- In het Netwerk connecties sectie, kies de VPC, privé-subnetten en beveiligingsgroep die u eerder hebt gemaakt.
Als u de CloudFormation-stack uit dit bericht hebt geïmplementeerd, kiest u emr-serverless-sg als beveiligingsgroep.
Er is een VPC nodig om ervoor te zorgen dat de werklast vanuit de EMR Serverless-applicatie toegang tot internet kan krijgen om externe Python-pakketten te downloaden. Met de VPC hebt u ook toegang tot bronnen zoals Amazon relationele databaseservice (Amazon RDS) en Amazon roodverschuiving die zich in de VPC van deze applicatie bevinden. Het koppelen van een serverloze applicatie aan een VPC kan leiden tot IP-uitputting in het subnet. Zorg er dus voor dat er voldoende IP-adressen in uw subnet aanwezig zijn.
- Kies Applicatie maken en starten.

Op de applicatiepagina kunt u controleren of de status van uw serverloze applicatie verandert in Begonnen.
- Selecteer uw toepassing en kies Hoe het werkt.
- Kies Werkruimten bekijken en starten.
- Kies Configureer studio.

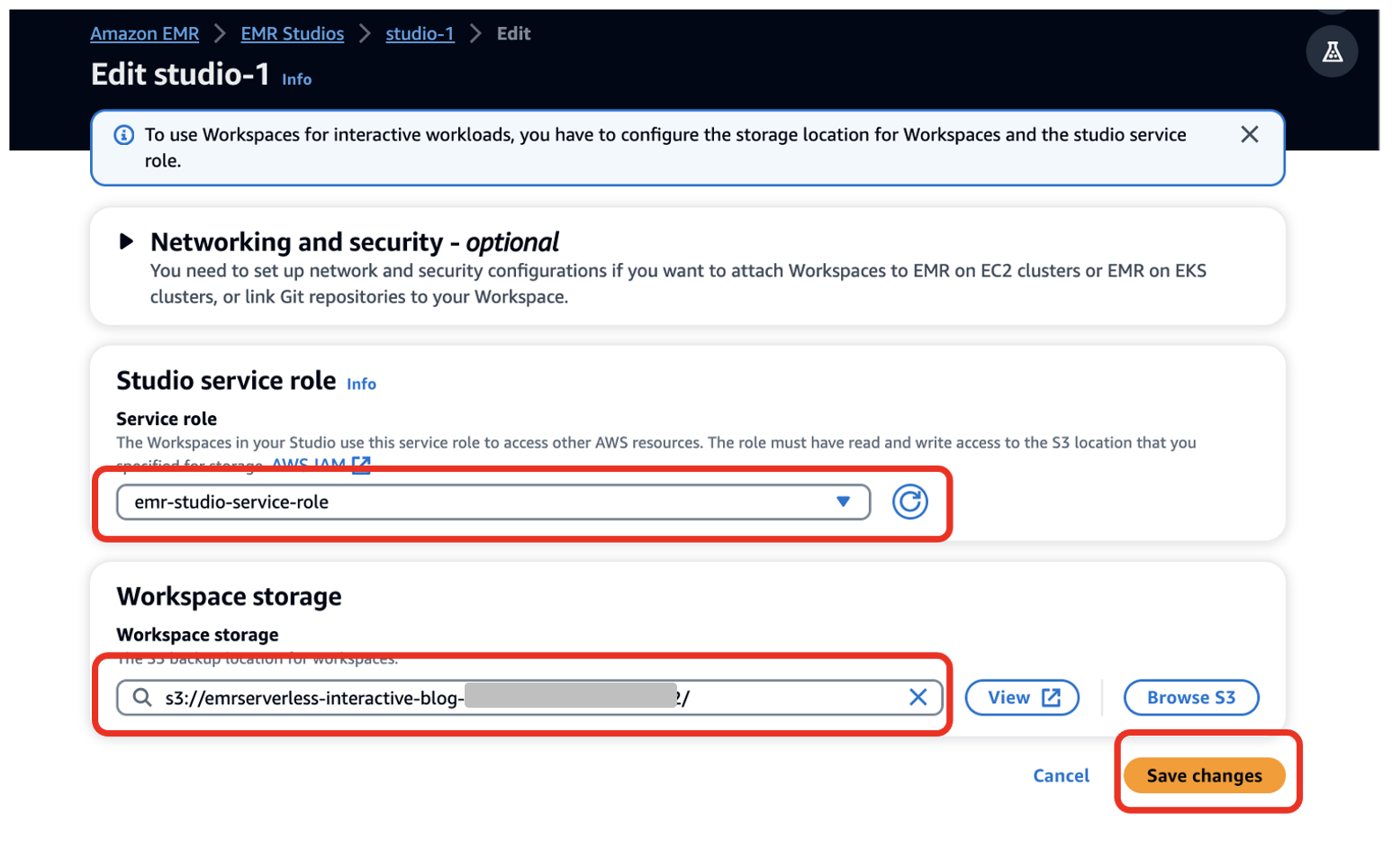
- Voor Dienstverlenende rol¸ geef als vereiste de EMR Studio-servicerol op die u hebt gemaakt (
emr-studio-service-role). - Voor Opslag van werkruimteVoer als voorwaarde het pad in van de S3-bucket die u hebt gemaakt (
emrserverless-interactive-blog-<account-id>-<region-name>). - Kies Wijzigingen opslaan.
14. Navigeer naar de Studios-console door te kiezen Studios in het linkernavigatiemenu in de EMR-studio sectie. Merk op URL voor studiotoegang vanuit de Studios-console en geef deze aan uw ontwikkelaars om hun Spark-applicaties uit te voeren.
Voer uw eerste Spark-toepassing uit
Nadat de EMR Studio-beheerder de Studio-, Workspace- en serverloze applicatie heeft gemaakt, kan de Studio-gebruiker de Workspace en applicatie gebruiken om Spark-workloads te ontwikkelen en te monitoren.
Start de werkruimte en sluit de serverloze applicatie aan
Voer de volgende stappen uit:
- Gebruik de Studio-URL die is verstrekt door de EMR Studio-beheerder en log in met behulp van de
emrs-interactive-app-dev-usergebruikersreferenties gedeeld door de AWS-accountbeheerder.
Als u de vereiste bronnen hebt geïmplementeerd met behulp van de meegeleverde CloudFormation-sjabloon, gebruikt u het wachtwoord dat u als invoerparameter hebt opgegeven.
Op de workspaces pagina kunt u de status van uw werkruimte controleren. Wanneer de Werkruimte wordt gestart, ziet u de status veranderen naar Klaar.
- Start de werkruimte door de naam van de werkruimte te kiezen (
My_First_Workspace).
Er wordt een nieuw tabblad geopend. Zorg ervoor dat uw browser pop-ups toestaat.
- Kies in de werkruimte Berekenen (clusterpictogram) in het navigatievenster.
- Voor EMR serverloze applicatie, kies uw toepassing (
my-serverless-interactive-application). - Voor Interactieve runtime-rol, kies een interactieve runtime-rol (voor dit bericht gebruiken we
emr-serverless-runtime-role). - Kies hechten om de serverloze applicatie toe te voegen als het rekentype voor alle notebooks in deze werkruimte.

Voer uw Spark-applicatie interactief uit
Voer de volgende stappen uit:
- Kies de Notitieboekjes voorbeelden (pictogram met drie stippen) in het navigatievenster en open
Getting-started-with-emr-serverlessnotebook. - Kies Opslaan in werkruimte.
Er zijn drie kernelskeuzes voor onze notebook: Python 3, PySpark en Spark (voor Scala).
- Kies wanneer u hierom wordt gevraagd PySpark als de pit.
- Kies kies.

Nu kunt u uw Spark-toepassing uitvoeren. Gebruik hiervoor de %%configure Sparkmagie opdracht, waarmee de parameters voor het maken van een sessie worden geconfigureerd. Interactieve applicaties ondersteunen virtuele Python-omgevingen. We gebruiken een aangepaste omgeving in de werkknooppunten door een pad op te geven voor een andere Python-runtime waar de uitvoerderomgeving gebruik van maakt spark.executorEnv.PYSPARK_PYTHON. Zie de volgende code:
Installeer externe pakketten
Nu u een onafhankelijke virtuele omgeving voor de werknemers heeft, kunt u met EMR Studio-notebooks externe pakketten installeren vanuit de serverloze applicatie met behulp van de Spark install_pypi_package functioneren via de Spark-context. Door deze functie te gebruiken, wordt het pakket beschikbaar voor alle EMR-serverloze werknemers.
Installeer eerst matplotlib, een Python-pakket, van PyPi:
Als de voorgaande stap niet reageert, controleer dan uw VPC-instellingen en zorg ervoor dat deze correct is geconfigureerd voor internettoegang.
Nu kunt u een dataset gebruiken en uw gegevens visualiseren.
Maak visualisaties
Om visualisaties te maken, gebruiken we een openbare dataset over gele taxi's in NYC:
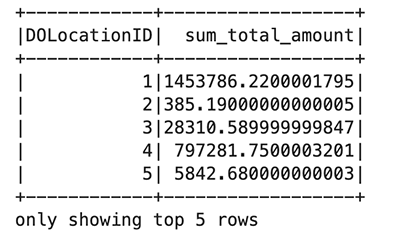
In het voorgaande codeblok lees je het Parquet-bestand vanuit een openbare bucket in Amazon S3. Het bestand heeft headers en we willen dat Spark het schema afleidt. Vervolgens gebruikt u een Spark-dataframe om specifieke kolommen te groeperen en te tellen taxi_df:
Te gebruiken %%display magie om het resultaat in tabelformaat te bekijken:

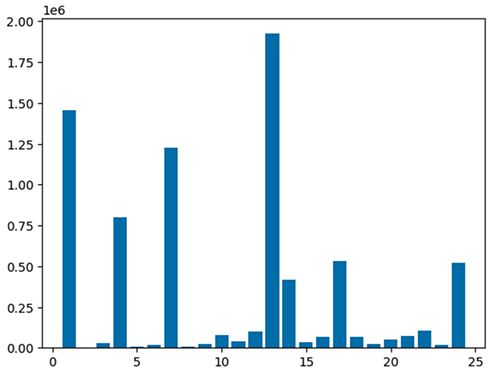
U kunt uw gegevens ook snel visualiseren met vijf soorten diagrammen. U kunt het weergavetype kiezen en de grafiek zal dienovereenkomstig veranderen. In de volgende schermafbeelding gebruiken we een staafdiagram om onze gegevens te visualiseren.

Communiceer met EMR Serverless met behulp van Spark SQL
U kunt communiceren met tabellen in de AWS-lijmgegevenscatalogus met behulp van Spark SQL op EMR Serverless. In het voorbeeldnotitieboekje laten we zien hoe u gegevens kunt transformeren met behulp van een Spark-dataframe.
Maak eerst een nieuwe tijdelijke weergave met de naam taxi's. Hierdoor kunt u Spark SQL gebruiken om gegevens uit deze weergave te selecteren. Maak vervolgens een taxidataframe voor verdere verwerking:
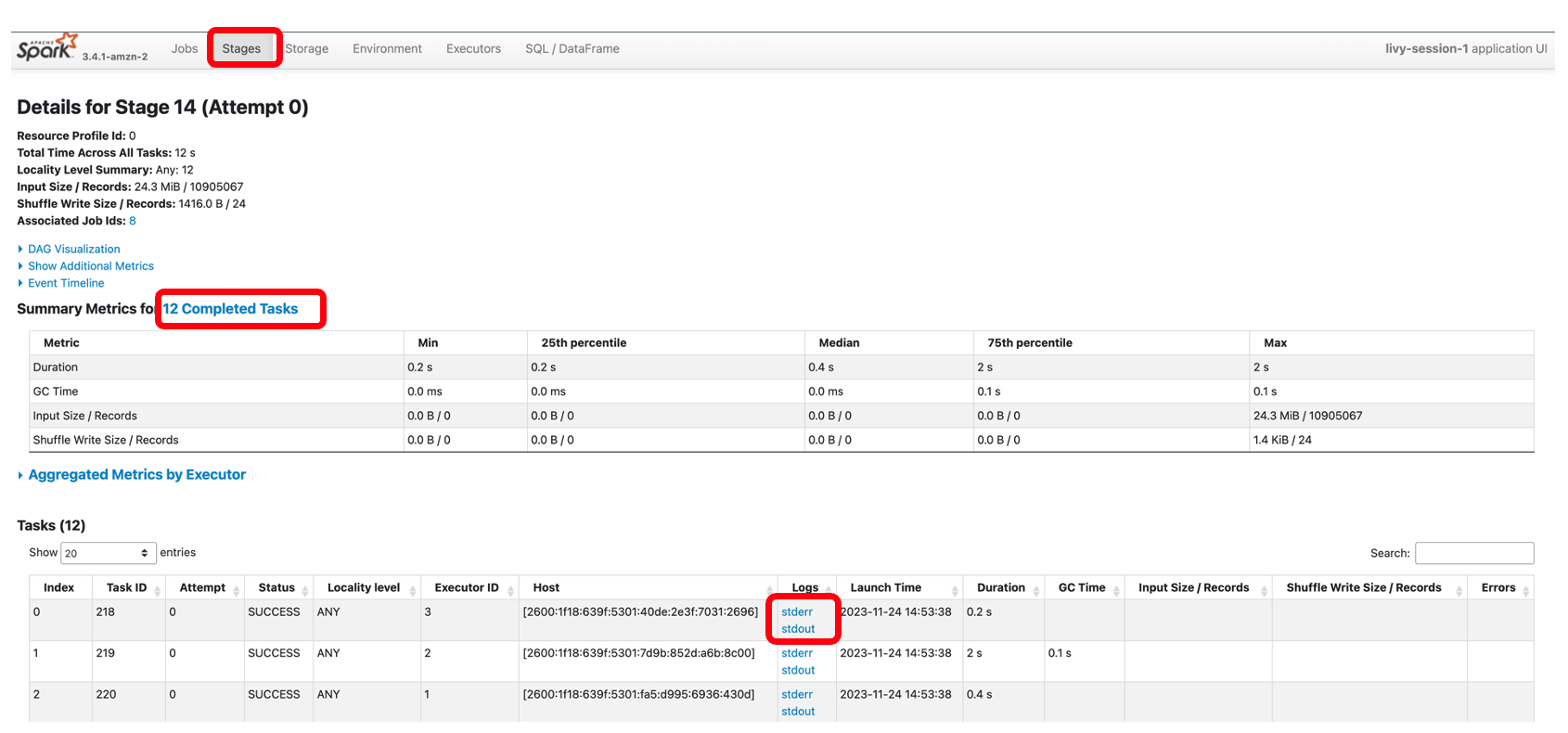
In elke cel van uw EMR Studio-notebook kunt u uitbreiden Spark-taakvoortgang om de verschillende fasen van de taak te bekijken die naar EMR Serverless is verzonden terwijl deze specifieke cel wordt uitgevoerd. U kunt zien hoeveel tijd het kost om elke fase te voltooien. In het volgende voorbeeld heeft fase 14 van de taak 12 voltooide taken. Als er zich een storing voordoet, kunt u bovendien de logboeken bekijken, waardoor het oplossen van problemen naadloos verloopt. We bespreken dit meer in de volgende sectie.
![Job[14]: showString bij NativeMethodAccessorImpl.java:0 en Job[15]: showString bij NativeMethodAccessorImpl.java:0](https://xlera8.com/wp-content/uploads/2024/04/run-interactive-workloads-on-amazon-emr-serverless-from-amazon-emr-studio-amazon-web-services-11.png)
Gebruik de volgende code om het verwerkte dataframe te visualiseren met behulp van het matplotlib-pakket. U gebruikt de maptplotlib-bibliotheek om de afleverlocatie en het totale bedrag in een staafdiagram weer te geven.
Diagnose van interactieve toepassingen
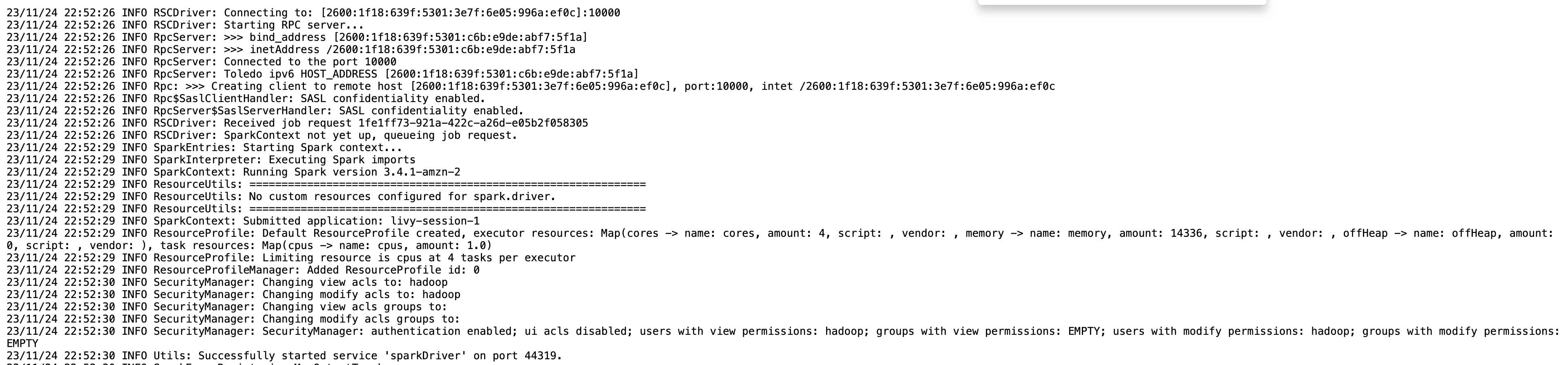
U kunt de sessie-informatie voor uw Livy-eindpunt verkrijgen met behulp van de %%info Sparkmagie. Dit geeft u koppelingen voor toegang tot de Spark-gebruikersinterface en het stuurprogrammalogboek rechtstreeks in uw notebook.

De volgende schermafbeelding is een driverlogfragment voor onze applicatie, dat we hebben geopend via de link in ons notitieboekje.
Op dezelfde manier kunt u de onderstaande link kiezen Spark-gebruikersinterface om de gebruikersinterface te openen. De volgende schermafbeelding toont de Beulen tabblad, dat toegang biedt tot de logboeken van het stuurprogramma en de uitvoerder.

De volgende schermafbeelding toont fase 14, die overeenkomt met de Spark SQL-stap die we eerder zagen, waarin we de locatiegewijze som van het totale aantal taxicollecties berekenden, opgesplitst in 12 taken. Via de Spark UI biedt de interactieve applicatie gedetailleerd taakniveau-status, I/O en shuffle-details, evenals links naar overeenkomstige logboeken voor elke taak voor deze fase, rechtstreeks vanaf uw notebook, waardoor een naadloze probleemoplossingservaring mogelijk wordt.
Opruimen
Als je de bronnen die in dit bericht zijn gemaakt niet langer wilt behouden, voer dan de volgende opschoonstappen uit:
- Verwijder de EMR Serverless-applicatie.
- Verwijder de EMR Studio en de bijbehorende werkruimten en notitieboekjes.
- Om de rest van de bronnen te verwijderen, navigeert u naar de CloudFormation-console, selecteert u de stapel en kiest u Verwijder.
Alle bronnen worden verwijderd, behalve de S3-bucket, waarvoor het verwijderingsbeleid is ingesteld om te behouden.
Conclusie
Het bericht liet zien hoe u interactieve PySpark-workloads kunt uitvoeren in EMR Studio met behulp van EMR Serverless als rekenkracht. U kunt Spark-applicaties ook bouwen en monitoren in een interactieve JupyterLab Workspace.
In een komende post bespreken we aanvullende mogelijkheden van EMR Serverless Interactive-applicaties, zoals:
- Werken met bronnen zoals Amazon RDS en Amazon Redshift in uw VPC (bijvoorbeeld voor JDBC/ODBC-connectiviteit)
- Het uitvoeren van transactionele workloads met behulp van serverloze eindpunten
Als dit de eerste keer is dat u EMR Studio verkent, raden we u aan de Amazon EMR-workshops en verwijzen naar Een EMR-studio maken.
Over de auteurs
 Sekar Srinivasan is een Principal Specialist Solutions Architect bij AWS, gericht op Data Analytics en AI. Sekar heeft meer dan 20 jaar ervaring met het werken met data. Hij heeft een passie voor het helpen van klanten bij het bouwen van schaalbare oplossingen, het moderniseren van hun architectuur en het genereren van inzichten uit hun data. In zijn vrije tijd werkt hij graag aan non-profit projecten, gericht op onderwijs voor kansarme kinderen.
Sekar Srinivasan is een Principal Specialist Solutions Architect bij AWS, gericht op Data Analytics en AI. Sekar heeft meer dan 20 jaar ervaring met het werken met data. Hij heeft een passie voor het helpen van klanten bij het bouwen van schaalbare oplossingen, het moderniseren van hun architectuur en het genereren van inzichten uit hun data. In zijn vrije tijd werkt hij graag aan non-profit projecten, gericht op onderwijs voor kansarme kinderen.
 Disha Umarwani is een Sr. Data Architect bij Amazon Professional Services binnen Global Health Care en LifeSciences. Ze heeft met klanten samengewerkt om datastrategie op schaal te ontwerpen, te ontwerpen en te implementeren. Ze is gespecialiseerd in het ontwerpen van Data Mesh-architecturen voor Enterprise-platforms.
Disha Umarwani is een Sr. Data Architect bij Amazon Professional Services binnen Global Health Care en LifeSciences. Ze heeft met klanten samengewerkt om datastrategie op schaal te ontwerpen, te ontwerpen en te implementeren. Ze is gespecialiseerd in het ontwerpen van Data Mesh-architecturen voor Enterprise-platforms.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/big-data/run-interactive-workloads-on-amazon-emr-serverless-from-amazon-emr-studio/