
Introduksjon
Kunstig intelligens (AI) har gjort betydelige fremskritt i ulike bransjer, og helsevesenet er intet unntak. Et av de mest lovende områdene innen AI i helsevesenet er Natural Language Processing (NLP), som har potensial til å revolusjonere pasientbehandlingen ved å legge til rette for mer effektiv og nøyaktig dataanalyse og kommunikasjon.
NLP har vist seg å være en game changer innen helsevesenet. NLP transformerer måten helsepersonell leverer pasientbehandling på. Fra befolkningshelsebehandling til sykdomsdeteksjon hjelper NLP helsepersonell med å ta informerte beslutninger og gi bedre behandlingsresultater.
Læringsmål
- Forstå og analysere bruken av NLP og AI i helsevesenet
- Få et grep om det grunnleggende i NLP
- Bli kjent med noen ofte brukte NLP-biblioteker i helsevesenet
- Lære om brukstilfeller av NLP i helsevesenet
Denne artikkelen ble publisert som en del av Data Science Blogathon.
Innholdsfortegnelse
- Motivasjonen for å bruke AI og NLP i helsevesenet
- Hva er naturlig språkbehandling?
- Ulike teknikker som brukes i NLP
3.1 Regelbaserte teknikker
3.2 Statistiske teknikker ved bruk av maskinlæringsmodeller
3.3 Overføre læring - Ulike NLP-biblioteker og deres rammer
- Hva er store språkmodeller (LLM)?
- NLP i klinisk tekst – Behovet for en annen tilnærming
- Noen NLP-biblioteker som brukes i helsesektoren
- Forstå de kliniske datasettene
- Hva er ulike typer kliniske data?
- Brukstilfeller og anvendelser av NLP i helsesektoren
- Hvordan bygge NLP-pipeline med klinisk tekst?
11.1 Løsningsdesign
11.2 Trinn-for-trinn-kode - konklusjonen
Motivasjonen for å bruke AI og NLP i helsevesenet
Motivasjonen for å bruke AI og NLP i helsevesenet er forankret i å forbedre pasientbehandling og behandlingsresultater samtidig som de reduserer helsekostnader. Helsesektoren genererer enorme mengder data, inkludert EMR-er, kliniske notater og helserelaterte innlegg i sosiale medier, som kan gi verdifull innsikt i pasienthelse og behandlingsresultater. Mye av disse dataene er imidlertid ustrukturerte og vanskelige å analysere manuelt.
I tillegg står helsevesenet overfor flere utfordringer, som en aldrende befolkning, økende forekomst av kronisk sykdom og mangel på helsepersonell.
Disse utfordringene har ført til et økende behov for mer effektiv og effektiv helsetjenester.
Ved å gi verdifull innsikt fra ustrukturerte medisinske data, kan NLP bidra til å forbedre pasientbehandling og behandlingsresultater og støtte helsepersonell i å ta mer informerte kliniske beslutninger.
Hva er naturlig språkbehandling?
Natural Language Processing (NLP) er et underfelt av kunstig intelligens (AI) som omhandler samspillet mellom datamaskiner og menneskelige språk. Den bruker beregningsteknikker for å analysere, forstå og generere menneskelig språk. NLP brukes i mange applikasjoner, inkludert talegjenkjenning, maskinoversettelse, sentimentanalyse og tekstoppsummering.
Vi vil nå utforske de ulike NLP-teknikkene, bibliotekene og rammeverket.
Ulike teknikker som brukes i NLP
Det er to ofte brukte teknikker som brukes i NLP-industrien.
1. Regelbaserte teknikker: stol på forhåndsdefinerte grammatikkregler og ordbøker
2. Statistiske teknikker: bruk maskinlæringsalgoritmer for å analysere og forstå språk
3. Stor språkmodell ved hjelp av Overfør læring
Her er en standard NLP Pipeline med ulike NLP-oppgaver
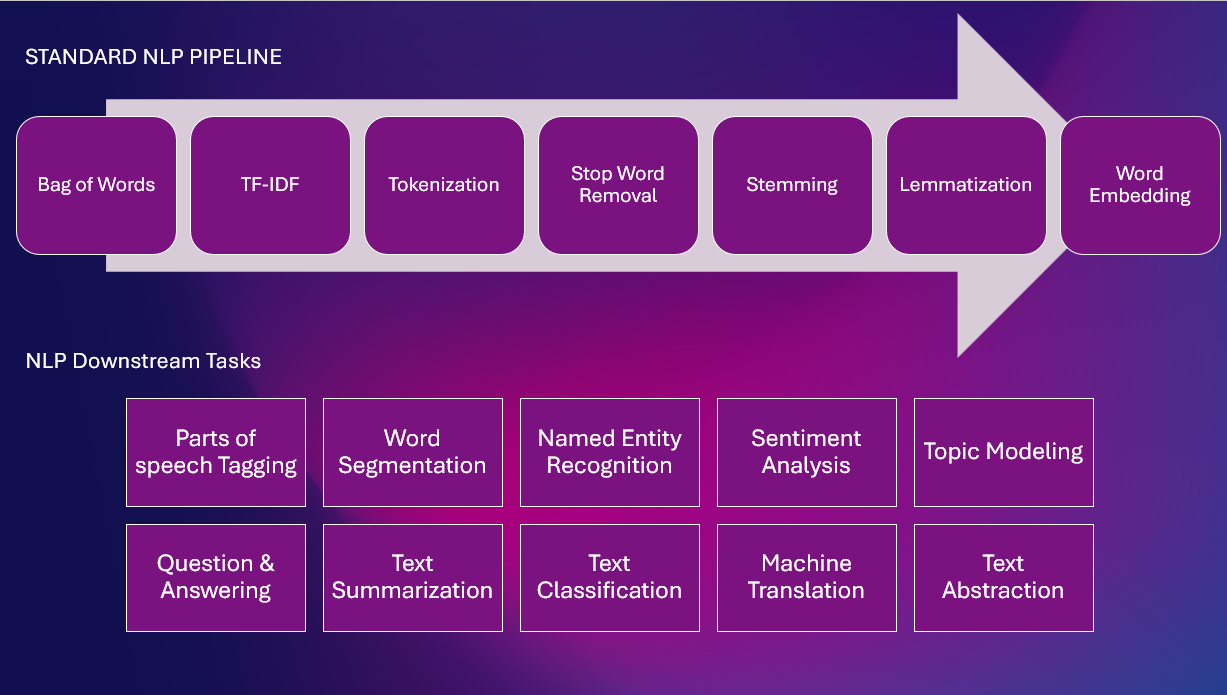
Regelbaserte teknikker
Disse teknikkene innebærer å lage et sett med håndlagde regler eller mønstre for å trekke ut meningsfull informasjon fra tekst. Regelbaserte systemer fungerer vanligvis ved å definere spesifikke mønstre som samsvarer med målinformasjonen, for eksempel navngitte enheter eller spesifikke nøkkelord, og deretter trekke ut den informasjonen basert på disse mønstrene. Regelbaserte systemer er raske, pålitelige og enkle, men de er begrenset av kvaliteten og antallet regler som er definert, og de kan være vanskelige å vedlikeholde og oppdatere.
For eksempel kan et regelbasert system for navngitt enhetsgjenkjenning utformes for å identifisere egennavn i tekst og kategorisere dem i forhåndsdefinerte enhetstyper, for eksempel en person, plassering, organisasjon, sykdom, narkotika osv. Systemet vil bruke en serie av regler for å identifisere mønstre i teksten som samsvarer med kriteriene for hver enhetstype, for eksempel bruk av store bokstaver for personnavn eller spesifikke nøkkelord for organisasjoner.
Statistiske teknikker ved bruk av maskinlæringsmodeller
Disse teknikkene bruker statistiske algoritmer for å lære mønstre i dataene og lage spådommer basert på disse mønstrene. Maskinlæringsmodeller kan trenes på store mengder annoterte data, noe som gjør dem mer fleksible og skalerbare enn regelbaserte systemer. Flere typer maskinlæringsmodeller brukes i NLP, bl.a avgjørelse trær, tilfeldige skoger, støtte vektormaskinerog nevrale nettverk.
For eksempel kan en maskinlæringsmodell for sentimentanalyse trenes på et stort korpus av kommentert tekst, der hver tekst er merket som positiv, negativ eller nøytral. Modellen vil lære de statistiske mønstrene i dataene som skiller mellom positiv og negativ tekst og deretter bruke disse mønstrene til å lage spådommer om ny, usett tekst. Fordelen med denne tilnærmingen er at modellen kan lære å identifisere sentimentmønstre som ikke er eksplisitt definert i reglene.
Overfør læring
Disse teknikkene er en hybrid tilnærming som kombinerer styrkene til regelbaserte og maskinlæringsmodeller. Overføringslæring bruker en forhåndstrent maskinlæringsmodell, for eksempel en språkmodell trent på et stort korpus med tekst, som utgangspunkt for å finjustere en spesifikk oppgave eller domene. Denne tilnærmingen utnytter den generelle kunnskapen som er lært fra den forhåndstrente modellen, reduserer mengden merkede data som kreves for trening og gir mulighet for raskere og mer nøyaktige spådommer for en spesifikk oppgave.
For eksempel kan en overføringslæringstilnærming til navngitt enhetsgjenkjenning finjustere en forhåndstrent språkmodell på et mindre korpus av kommentert medisinsk tekst. Modellen ville starte med den generelle kunnskapen lært fra den forhåndstrente modellen og deretter justere vektene for å matche den medisinske tekstens mønstre bedre. Denne tilnærmingen vil redusere mengden merkede data som kreves for opplæring og resultere i en mer nøyaktig modell for navngitt enhetsgjenkjenning i det medisinske domenet.
Ulike NLP-biblioteker og deres rammer
Ulike biblioteker tilbyr et bredt spekter av NLP-funksjoner. Som for eksempel :

Natural Language Processing (NLP) biblioteker og rammeverk er programvareverktøy som hjelper til med å utvikle og distribuere NLP-applikasjoner. Flere NLP-biblioteker og rammeverk er tilgjengelige, hver med styrker, svakheter og fokusområder.
Disse verktøyene varierer med hensyn til kompleksiteten til algoritmene de støtter, størrelsen på modellene de kan håndtere, brukervennligheten og graden av tilpasning de tillater.
Hva er store språkmodeller (LLM)?
Store språkmodeller er trent på enorme mengder data. Kan generere menneskelignende tekst og utføre et bredt spekter av NLP-oppgaver med høy nøyaktighet.
Her er noen eksempler på store språkmodeller og en kort beskrivelse av hver:
GPT-3 (Generative Pretrained Transformer 3): GPT-3 er utviklet av OpenAI, og er en stor transformatorbasert språkmodell som bruker dyplæringsalgoritmer for å generere menneskelignende tekst. Den har blitt trent på et massivt korpus av tekstdata, slik at det kan generere sammenhengende og kontekstuelt passende tekstsvar basert på en forespørsel.
BERTI (Toveis koderepresentasjoner fra transformatorer): BERT er utviklet av Google og er en transformatorbasert språkmodell som har blitt forhåndsopplært på et stort korpus av tekstdata. Den er designet for å yte godt på et bredt spekter av NLP-oppgaver, for eksempel navngitt enhetsgjenkjenning, svar på spørsmål og tekstklassifisering, ved å kode konteksten og relasjonene mellom ord i en setning.
ROBERTA (Robust optimalisert BERT-tilnærming): RoBERTa er utviklet av Facebook AI, og er en variant av BERT som har blitt finjustert og optimalisert for NLP-oppgaver. Den har blitt trent på et større korpus av tekstdata og bruker en annen treningsstrategi enn BERT, noe som fører til forbedret ytelse på NLP-benchmarks.
ELMo (Innbygging fra språkmodeller): Utviklet av Allen Institute for AI, er ELMo en dyp kontekstualisert ordrepresentasjonsmodell som bruker et toveis LSTM (Long Short-Term Memory) nettverk for å lære språkrepresentasjoner fra et stort korpus av tekstdata. ELMo kan finjusteres for spesifikke NLP-oppgaver eller brukes som en funksjonsuttrekker for andre maskinlæringsmodeller.
ULMFiT (Universal Language Model Fine-Tuning): ULMFiT er utviklet av FastAI, og er en overføringslæringsmetode som finjusterer en forhåndstrent språkmodell på en spesifikk NLP-oppgave ved å bruke en liten mengde oppgavespesifikke kommenterte data. ULMFiT har oppnådd state-of-the-art ytelse på et bredt spekter av NLP benchmarks og regnes som et ledende eksempel på overføringslæring i NLP.
NLP i klinisk tekst: The Need for Different Approach
Klinisk tekst er ofte ustrukturert og inneholder mye medisinsk sjargong og akronymer, noe som gjør det vanskelig for tradisjonelle NLP-modeller å forstå og behandle. I tillegg inkluderer klinisk tekst ofte viktig informasjon som sykdom, legemidler, pasientinformasjon, diagnoser og behandlingsplaner, som krever spesialiserte NLP-modeller som nøyaktig kan trekke ut og forstå denne medisinske informasjonen.
En annen grunn til at klinisk tekst trenger forskjellige NLP-modeller, er at den inneholder en stor mengde data spredt over forskjellige kilder, som EPJer, kliniske notater og radiologirapporter, som må integreres. Dette krever modeller som kan behandle og forstå teksten og koble og integrere dataene på tvers av ulike kilder og etablere klinisk akseptable sammenhenger.
Til slutt inneholder klinisk tekst ofte sensitiv pasientinformasjon og må beskyttes av strenge regler som HIPAA. NLP-modeller som brukes til å behandle klinisk tekst må kunne identifisere og beskytte sensitiv pasientinformasjon samtidig som de gir nyttig innsikt.
Noen NLP-biblioteker som brukes i helsesektoren
Tekstdata innen medisin krever et spesialisert Natural Language Processing (NLP) system som er i stand til å trekke ut medisinsk informasjon fra ulike kilder som kliniske tekster og andre medisinske dokumenter.
Her er en liste over NLP-biblioteker og modeller som er spesifikke for det medisinske domenet:
spaCy: Det er et åpen kildekode NLP-bibliotek som gir ut-av-boksen modeller for ulike domener, inkludert det medisinske domenet.
ScispaCy: En spesialisert versjon av spaCy som er trent spesielt på vitenskapelig og biomedisinsk tekst, noe som gjør den ideell for behandling av medisinsk tekst.
BioBERT: En forhåndsopplært transformatorbasert modell spesielt designet for det biomedisinske domenet. Den er forhåndstrent med Wiki + Books + PubMed + PMC.
ClinicalBERT: En annen forhåndsopplært modell designet for å behandle kliniske notater og utskrivningssammendrag fra MIMIC-III-databasen.
Med7: En transformatorbasert modell som ble trent på elektroniske helsejournaler (EPJ) for å trekke ut syv sentrale kliniske konsepter, inkludert diagnose, medisinering og laboratorietester.
DisMod-ML: Et probabilistisk modelleringsrammeverk for sykdomsmodellering som bruker NLP-teknikker for å behandle medisinsk tekst.
MEDICER: Et regelbasert NLP-system for å trekke ut medisinsk informasjon fra tekst.
Dette er noen av de populære NLP-bibliotekene og -modellene som er spesielt designet for det medisinske domenet. De tilbyr en rekke funksjoner, fra forhåndstrente modeller til regelbaserte systemer, og kan hjelpe helseorganisasjoner med å behandle medisinsk tekst effektivt.
I vår NER-modell vil vi bruke spaCy og Scispacy. Disse bibliotekene er relativt enkle å kjøre på Google colab eller lokal infrastruktur.
De ressurskrevende store språkmodellene BioBERT og ClinicalBERT trenger GPUer og høyere infrastruktur.
Forstå de kliniske datasettene
Medisinske tekstdata kan hentes fra ulike kilder, for eksempel elektroniske helsejournaler (EPJ), medisinske tidsskrifter, kliniske notater, medisinske nettsteder og databaser. Noen av disse kildene gir offentlig tilgjengelige datasett som kan brukes til opplæring av NLP-modeller, mens andre kan kreve godkjenning og etiske vurderinger før de får tilgang til dataene. Kildene til medisinske tekstdata inkluderer:
1. Åpen kildekode medisinske korpus som f.eks MIMIC-III database er en stor, åpent tilgjengelig elektronisk helsejournal (EPJ)-database fra pasienter som mottok behandling ved Beth Israel Deaconess Medical Center mellom 2001 og 2012. Databasen inneholder informasjon som pasientdemografi, vitale tegn, laboratorietester, medisiner, prosedyrer og notater fra helsepersonell, som sykepleiere og leger. I tillegg inneholder databasen informasjon om pasientenes opphold på intensivavdelingen, inkludert type intensivavdeling, liggetid og utfall. Dataene i MIMIC-III er avidentifisert og kan brukes til forskningsformål for å støtte utviklingen av prediktive modeller og kliniske beslutningsstøttesystemer.
2. Nasjonalbiblioteket for medisin ClinicalTrials.gov nettstedet har data fra kliniske utprøvinger og sykdomsovervåkingsdata.
3. National Institutes of Health's National Library of Medicine, National Centers for Biotechnology Information (NCBI), og Verdens helseorganisasjon (HVEM)
4. Helseinstitusjoner og organisasjoner som sykehus, klinikker og farmasøytiske selskaper genererer store mengder medisinsk tekstdata gjennom elektroniske helsejournaler, kliniske notater, medisinsk transkripsjon og medisinske rapporter.
5. Medisinske forskningstidsskrifter og databaser, som PubMed og CINAHL, inneholder enorme mengder publiserte medisinske forskningsartikler og sammendrag.
6. Sosiale medieplattformer som Twitter kan gi sanntidsinnsikt i pasientperspektiver, legemiddelanmeldelser og erfaringer.
For å trene NLP-modeller ved bruk av medisinsk tekstdata, er det viktig å vurdere dataenes kvalitet og relevans og sørge for at de er riktig forhåndsbehandlet og formatert. I tillegg er det viktig å forholde seg til etiske og juridiske hensyn når du arbeider med sensitiv medisinsk informasjon.
Hva er ulike typer kliniske data?
Flere typer kliniske data brukes ofte i helsevesenet:

Kliniske data refererer til informasjon om enkeltpersoners helsetjenester, inkludert pasientens sykehistorie, diagnoser, behandlinger, laboratorieresultater, bildestudier og annen relevant helseinformasjon.
EPJ/EMR-data er knyttet til demografiske data (dette inkluderer personlig informasjon som alder, kjønn, etnisitet og kontaktinformasjon.), Pasientgenererte data (Denne typen data genereres av pasientene selv, inkludert informasjon samlet inn gjennom pasientrapporterte utfallsmål og pasient -genererte helsedata.)
Andre sett med data er:
Genomiske data: Denne typen er relatert til et individs genetiske informasjon, inkludert DNA-sekvenser og markører.
Data for bærbare enheter: Disse dataene inkluderer informasjon samlet inn fra bærbare enheter som treningsmålere og hjertemonitorer.
Hver type kliniske data spiller en unik rolle i å gi et helhetlig syn på en pasients helse og brukes på forskjellige måter av helsepersonell og forskere for å forbedre pasientbehandlingen og informere behandlingsbeslutninger.
Brukstilfeller og anvendelser av NLP i helsesektoren
Natural Language Processing (NLP) har blitt mye brukt i helsesektoren og har flere bruksområder. Noen av de fremtredende inkluderer:
Befolkning Helse: NLP kan brukes til å behandle store mengder ustrukturerte medisinske data som medisinske journaler, undersøkelser og kravdata for å identifisere mønstre, korrelasjoner og innsikt. Dette hjelper med å overvåke befolkningens helse og tidlig oppdagelse av sykdommer.
Pasientbehandling: NLP kan brukes til å behandle pasienters elektroniske helsejournaler (EPJ) for å trekke ut viktig informasjon som diagnose, medisiner og symptomer. Denne informasjonen kan brukes til å forbedre pasientbehandlingen og gi personlig tilpasset behandling.
Sykdomsdeteksjon: NLP kan brukes til å behandle store mengder tekstdata, for eksempel vitenskapelige artikler, nyhetsartikler og innlegg i sosiale medier, for å oppdage utbrudd av infeksjonssykdommer.
Clinical Decision Support System (CDSS): NLP kan brukes til å analysere pasienters elektroniske helsejournaler for å gi sanntids beslutningsstøtte til helsepersonell. Dette bidrar til å gi best mulig behandlingsalternativer og forbedre den generelle kvaliteten på omsorgen.
Klinisk utprøving: NLP kan behandle data fra kliniske forsøk for å identifisere korrelasjoner og potensielle nye behandlinger.
Narkotikabivirkninger: NLP kan brukes til å behandle store mengder medikamentsikkerhetsdata for å identifisere uønskede hendelser og legemiddelinteraksjoner.
Presisjonshelse: NLP kan brukes til å behandle genomiske data og medisinske journaler for å identifisere personlige behandlingsalternativer for individuelle pasienter.
Medisinsk effektivitetsforbedring: NLP kan automatisere rutineoppgaver som medisinsk koding, dataregistrering og kravbehandling, og frigjøre medisinske fagfolk til å fokusere på å gi bedre pasientbehandling.
Dette er bare noen få eksempler på hvordan NLP revolusjonerer helsesektoren. Ettersom NLP-teknologien fortsetter å utvikle seg, kan vi forvente å se mer innovativ bruk av NLP i helsevesenet i fremtiden.
Hvordan bygge NLP-pipeline med klinisk tekst?
Vi vil utvikle en steg-for-steg Spacy-pipeline ved å bruke SciSpacy NER-modellen for klinisk tekst.
Målet: Dette prosjektet har som mål å konstruere en NLP-pipeline som bruker SciSpacy for å utføre tilpasset navngitt enhetsgjenkjenning på kliniske tekster.
Utfallet: Resultatet vil være å trekke ut informasjon om sykdommer, medikamenter og medikamentdoser fra klinisk tekst, som deretter kan brukes i ulike NLP nedstrømsapplikasjoner.
Løsningsdesign:
Her er høynivåløsningen for å trekke ut enhetsinformasjon fra Clinical Text. NER-ekstraksjon er en viktig NLP-oppgave som brukes i de fleste NLP-rørledningene.
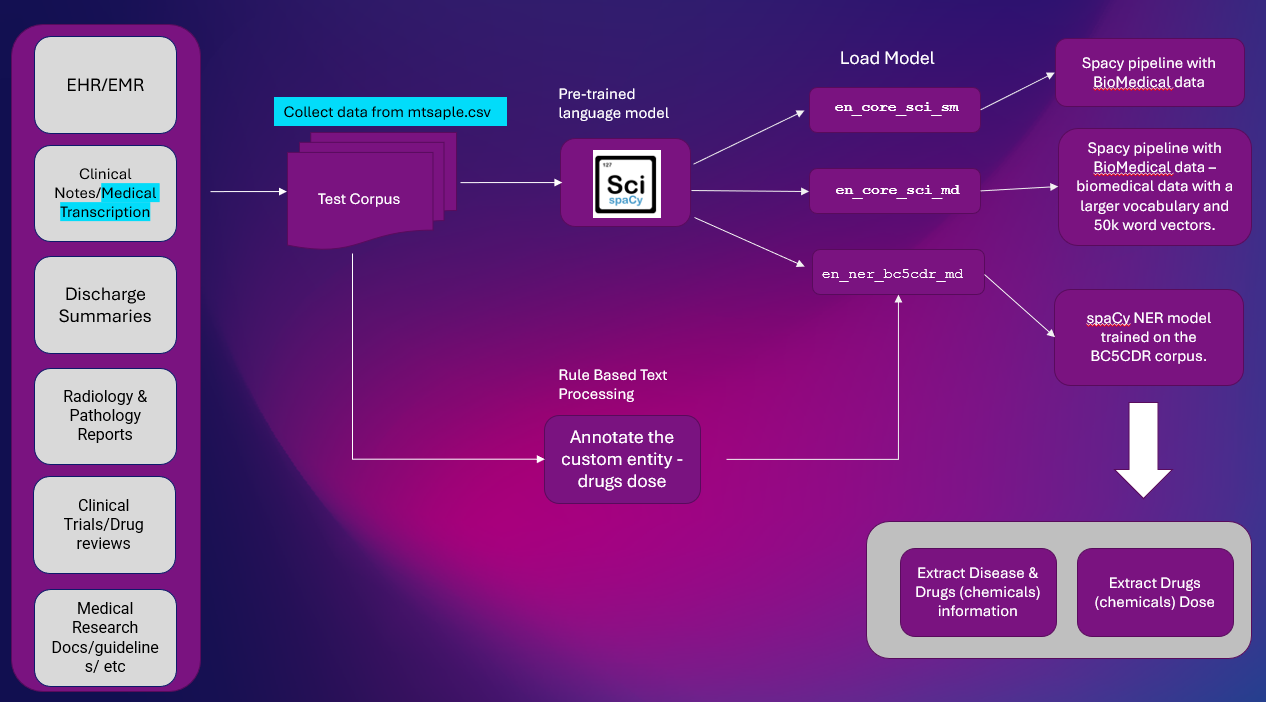
Plattform: Google Colab
NLP biblioteker: spaCy & SciSpacy
Datasett: mtsample.csv (skrapet data fra mtsample).
Vi har brukt ScispaCy ferdigtrent NER-modell en_ner_bc5cdr_md-0.5.1 å utvinne sykdommer og medikamenter. Legemidler utvinnes som kjemikalier.
en_ner_bc5cdr_md-0.5.1 er en spaCy-modell for navngitt enhetsgjenkjenning (NER) i det biomedisinske domenet.
"bc5cdr" refererer til BC5CDR corpus, et biomedisinsk tekstkorpus som brukes til å trene modellen. "md" i navnet refererer til det biomedisinske domenet. "0.5.1" i navnet refererer til versjonen av modellen.
Vi vil bruke prøveteksten for "transkripsjon" fra mtsample.csv og kommentere ved å bruke et regelbasert mønster for å trekke ut medikamentdoser.
Trinn-for-trinn-kode:
Installer spacy & scispacy-pakker. spaCy-modeller er designet for å utføre spesifikke NLP-oppgaver, som tokenisering, orddelsmerking og navngitt enhetsgjenkjenning.
!pip install -U spacy !pip install scispacy
Installer scispacy-basemodeller og NER-modeller
En_ner_bc5cdr_md-0.5.1-modellen er spesielt utviklet for å gjenkjenne navngitte enheter i biomedisinsk tekst, som sykdommer, gener og medikamenter, som kjemikalier.
Denne modellen kan være nyttig for NLP-oppgaver i det biomedisinske domenet, for eksempel informasjonsutvinning, tekstklassifisering og spørsmålssvar.
!pip install https://s3-us-west-2.amazonaws.com/ai2-s2-scispacy/releases/v0.5.1/en_core_sci_sm-0.5.1.tar.gz !pip install https://s3-us-west-2.amazonaws.com/ai2-s2-scispacy/releases/v0.5.1/en_core_sci_md-0.5.1.tar.gz !pip install https://s3-us-west-2.amazonaws.com/ai2-s2-scispacy/releases/v0.5.1/en_ner_bc5cdr_md-0.5.1.tar.gz
Installer andre pakker
pip install render
Importer pakker
import scispacy import spacy #Core models import en_core_sci_sm import en_core_sci_md
#NER spesifikke modeller import en_ner_bc5cdr_md #Verktøy for å trekke ut og vise data fra romslige importdisplacy importer pandaer som pd
Python-kode:
Test modellene med eksempeldata
# Velg en spesifikk transkripsjon som skal brukes (rad 3, kolonne "transkripsjon") og test NER-modellteksten for scispacy = mtsample_df.loc[10, "transcription"]

Last inn spesifikk modell: en_core_sci_sm og send tekst gjennom
nlp_sm = en_core_sci_sm.load() doc = nlp_sm(tekst)
#Vis resultatet
enhetsutvinning displacy_image = displacy.render(doc, jupyter=True,style='ent')

Merk at enheten er merket her. Mest medisinske termer. Dette er imidlertid generiske enheter.
Last nå den spesifikke modellen: en_core_sci_md og send tekst gjennom
nlp_md = en_core_sci_md.load() doc = nlp_md(tekst)
#Vis resulterende enhetsutvinning
displacy_image = displacy.render(doc, jupyter=True,style='ent')

Denne gangen er tallene også merket som entiteter av en_core_sci_md.
Last nå spesifikk modell: importer en_ner_bc5cdr_md og send tekst gjennom
nlp_bc = en_ner_bc5cdr_md.load() doc = nlp_bc(tekst) #Display resulterende enhetsekstraksjon displacy_image = displacy.render(doc, jupyter=True,style='ent')

Nå er to medisinske enheter merket: sykdom og kjemisk (narkotika).
Vis enheten
print("TEXT", "START", "END", "ENTITY TYPE") for ent i doc.ents: print(ent.text, ent.start_char, ent.end_char, ent.label_)
TEKST START SLUTT ENHETSTYPE
Sykelig overvekt 26 40 SYKDOM
Sykelig overvekt 70 84 SYKDOM
vekttap 400 411 SYKDOM
Marcaine 1256 1264 KJEMISK
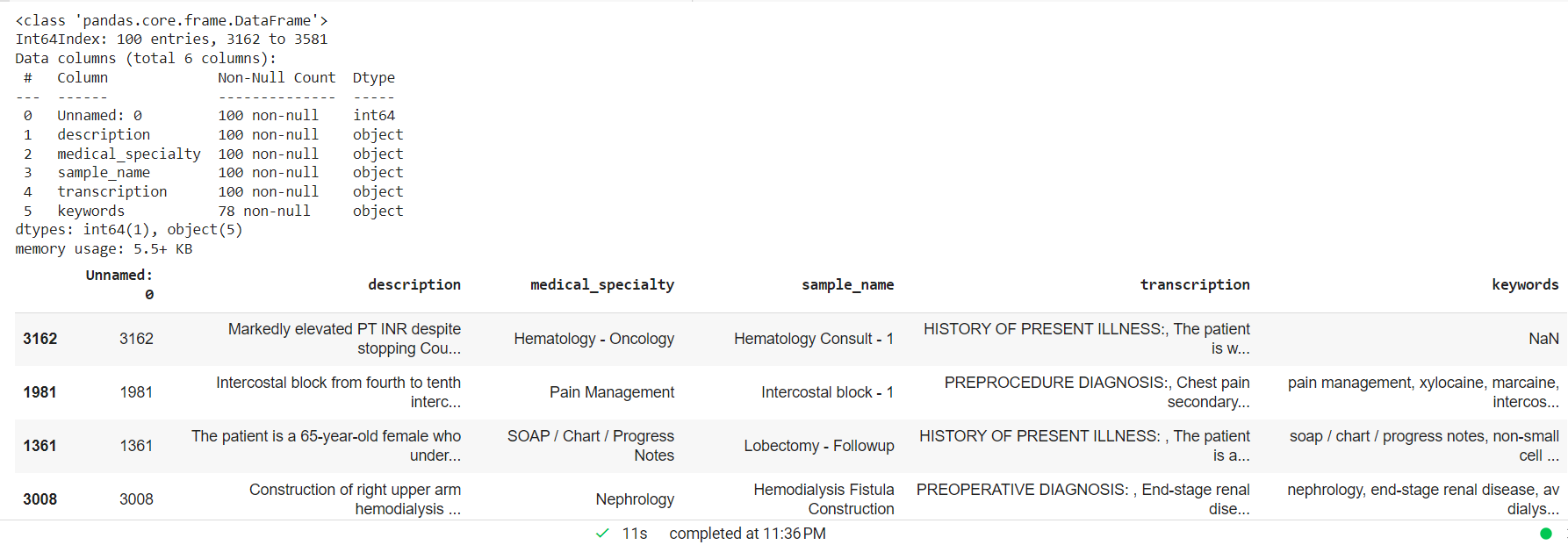
Behandle den kliniske teksten og slippe NAN-verdier og lage et tilfeldig mindre utvalg for den tilpassede enhetsmodellen.
mtsample_df.dropna(subset=['transcription'], inplace=True) mtsample_df_subset = mtsample_df.sample(n=100, replace=False, random_state=42) mtsample_df_subset.info() mtsample.head()_subset
spaCy matcher – Den regelbaserte matchingen ligner bruken av regulære uttrykk, men spaCy gir ekstra muligheter. Ved å bruke symbolene og relasjonene i et dokument kan du identifisere mønstre som inkluderer enheter ved hjelp av NER-modeller. Målet er å finne legemiddelnavn og deres doseringer fra teksten, noe som kan bidra til å oppdage medisineringsfeil ved å sammenligne dem med standarder og retningslinjer.
Målet er å finne legemiddelnavn og deres doseringer fra teksten, noe som kan bidra til å oppdage medisineringsfeil ved å sammenligne dem med standarder og retningslinjer.
fra spacy.matcher import Matcher
mønster = [{'ENT_TYPE':'CHEMICAL'}, {'LIKE_NUM': True}, {'IS_ASCII': True}] matcher = Matcher(nlp_bc.vocab) matcher.add("DRUG_DOSE", [pattern])
for transkripsjon i mtsample_df_subset['transcription']: doc = nlp_bc(transkripsjon) matcher = matcher(doc) for match_id, start, end in matches: string_id = nlp_bc.vocab.strings[match_id] # get string representation span = doc[start :slutt] # det matchede spennet legger til legemiddeldoser print(span.text, start, end, string_id,) #Legg til sykdom og legemidler for ent in doc.ents: print(ent.text, ent.start_char, ent.end_char, ent .merkelapp_)
Utdataene vil vise enhetene hentet fra den kliniske tekstprøven.
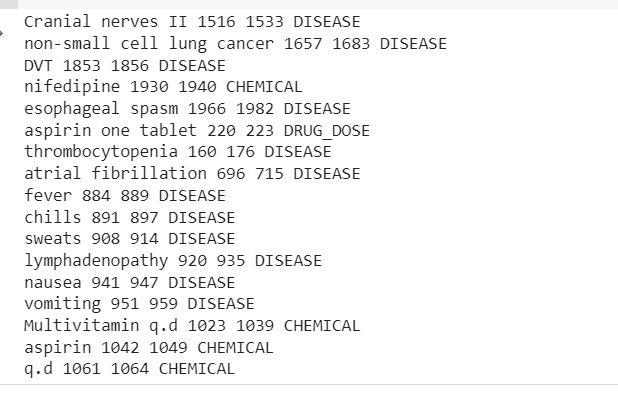
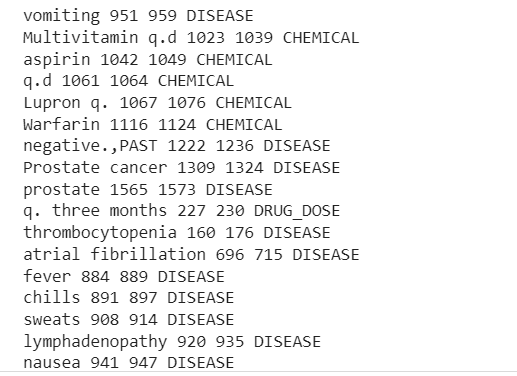
Nå kan vi se rørledningen trukket ut Sykdom, legemidler (kjemikalier) og legemidler-doser informasjon fra den kliniske teksten.
Det er noe feilklassifisering, men vi kan øke modellens ytelse ved å bruke mer data.
Vi kan nå bruke disse medisinske enhetene i ulike oppgaver som sykdomsdeteksjon, prediktiv analyse, klinisk beslutningsstøttesystem, medisinsk tekstklassifisering, oppsummering, spørsmålssvar og mange flere.
konklusjonen
1. I denne artikkelen har vi utforsket noen av nøkkelfunksjonene til NLP i helsevesenet, som vil bidra til å forstå komplekse helsetekstdata.
Vi implementerte også scispaCy og spaCy og konstruerte en enkel tilpasset NER-modell gjennom en forhåndstrent NER-modell og regelbasert matcher. Mens vi bare har dekket én NER-modell, er mange andre tilgjengelige, og en enorm mengde tilleggsfunksjonalitet å oppdage.
2. Innenfor scispaCy-rammeverket er det mange tilleggsteknikker å utforske, inkludert metoder for å oppdage forkortelser, utføre avhengighetsanalyse og identifisere individuelle setninger.
3. De siste trendene innen NLP for helsetjenester inkluderer utvikling av domenespesifikke modeller som BioBERT og ClinicalBert og bruk av store språkmodeller som GPT-3. Disse modellene tilbyr et høyt nivå av nøyaktighet og effektivitet, men bruken av dem øker også bekymringer om skjevheter, personvern og kontroll over data.
ChatGPT (en avansert konversasjons-AI-modell utviklet av OpenAI) gjør allerede en enorm innvirkning i NLP-verdenen. Modellen er trent på en enorm mengde tekstdata fra internett og har evnen til å generere menneskelignende tekstsvar basert på input den mottar. Den kan brukes til ulike oppgaver som svar på spørsmål, oppsummering, oversettelse og mer. Modellen er også finjustert for spesifikke brukstilfeller, for eksempel å generere kode eller skrive artikler, for å forbedre ytelsen på de spesifikke områdene.
5. Til tross for de mange fordelene er NLP i helsevesenet imidlertid ikke uten utfordringer. Å sikre nøyaktigheten og rettferdigheten til NLP-modeller og å overvinne bekymringer om personvern er noen av utfordringene som må løses for fullt ut å realisere potensialet til NLP i helsevesenet.
6. Med sine mange fordeler er det viktig for helsepersonell å omfavne og innlemme NLP i arbeidsflytene sine. Selv om det er mange utfordringer å overvinne, er NLP i helsevesenet absolutt en trend verdt å se og investere i.
Mediene vist i denne artikkelen eies ikke av Analytics Vidhya og brukes etter forfatterens skjønn.
I slekt
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- Platoblokkkjede. Web3 Metaverse Intelligence. Kunnskap forsterket. Tilgang her.
- kilde: https://www.analyticsvidhya.com/blog/2023/02/extracting-medical-information-from-clinical-text-with-nlp/