

Bilde laget av forfatter ved hjelp av Midjourney
Introduksjon til RAG
I den stadig utviklende verden av språkmodeller, er en standhaftig metodikk av spesiell betydning Retrieval Augmented Generation (RAG), en prosedyre som inkluderer elementer av informasjonsgjenvinning (IR) innenfor rammen av en tekstgenerasjonsspråkmodell for å generere menneskelignende tekst med mål om å være mer nyttig og nøyaktig enn den som ville bli generert av standardspråkmodellen alene. Vi vil introdusere de grunnleggende konseptene til RAG i dette innlegget, med et øye for å bygge noen RAG-systemer i påfølgende innlegg.
RAG Oversikt
Vi lager språkmodeller ved å bruke store, generiske datasett som ikke er skreddersydd for dine egne personlige eller tilpassede data. For å møte denne virkeligheten, kan RAG kombinere dine spesifikke data med den eksisterende "kunnskapen" om en språkmodell. For å lette dette, hva som må gjøres, og hva RAG gjør, er å indeksere dataene dine for å gjøre dem søkbare. Når et søk som består av dataene dine utføres, trekkes den relevante og viktige informasjonen ut fra de indekserte dataene, og kan brukes i en spørring mot en språkmodell for å returnere et relevant og nyttig svar laget av modellen. Enhver AI-ingeniør, dataforsker eller utvikler som er interessert i å bygge chatbots, moderne systemer for informasjonsinnhenting eller andre typer personlige assistenter, en forståelse av RAG, og kunnskapen om hvordan du kan utnytte dine egne data, er svært viktig.
Enkelt sagt er RAG en ny teknikk som beriker språkmodeller med funksjonalitet for innhenting av inndata, som forbedrer språkmodeller ved å inkorporere IR-mekanismer i generasjonsprosessen, mekanismer som kan personalisere (forsterke) modellens iboende "kunnskap" brukt til generative formål.
For å oppsummere involverer RAG følgende trinn på høyt nivå:
- Hent informasjon fra dine tilpassede datakilder
- Legg til disse dataene i forespørselen din som ekstra kontekst
- Få LLM til å generere et svar basert på den utvidede ledeteksten
RAG gir disse fordelene fremfor alternativet med modellfinjustering:
- Ingen trening skjer med RAG, så det er ingen finjusteringskostnad eller tid
- Tilpassede data er like ferske som du gjør det, og derfor kan modellen effektivt holde seg oppdatert
- De spesifikke tilpassede datadokumentene kan siteres under (eller etter) prosessen, og dermed er systemet mye mer verifiserbart og pålitelig
En nærmere titt
Ved en mer detaljert undersøkelse kan vi si at et RAG-system vil gå gjennom 5 driftsfaser.
1. Last: Innsamling av rå tekstdata – fra tekstfiler, PDF-er, nettsider, databaser og mer – er det første av mange trinn, å legge tekstdataene inn i prosesseringspipelinen, noe som gjør dette til et nødvendig trinn i prosessen. Uten lasting av data kan RAG rett og slett ikke fungere.
2. Indeks: Dataene du nå har må struktureres og vedlikeholdes for gjenfinning, søking og spørring. Språkmodeller vil bruke vektorinnbygginger opprettet fra innholdet for å gi numeriske representasjoner av dataene, i tillegg til å bruke bestemte metadata for å tillate vellykkede søkeresultater.
3. Lagre: Etter at den er opprettet, må indeksen lagres sammen med metadataene, for å sikre at dette trinnet ikke trenger å gjentas regelmessig, noe som muliggjør enklere RAG-systemskalering.
4. Spørring: Med denne indeksen på plass, kan innholdet krysses ved hjelp av indekserings- og språkmodellen for å behandle datasettet i henhold til ulike spørringer.
5. Evaluere: Det er nyttig å vurdere ytelse kontra andre mulige generative trinn, enten når du endrer eksisterende prosesser eller når du tester den iboende latensen og nøyaktigheten til systemer av denne typen.
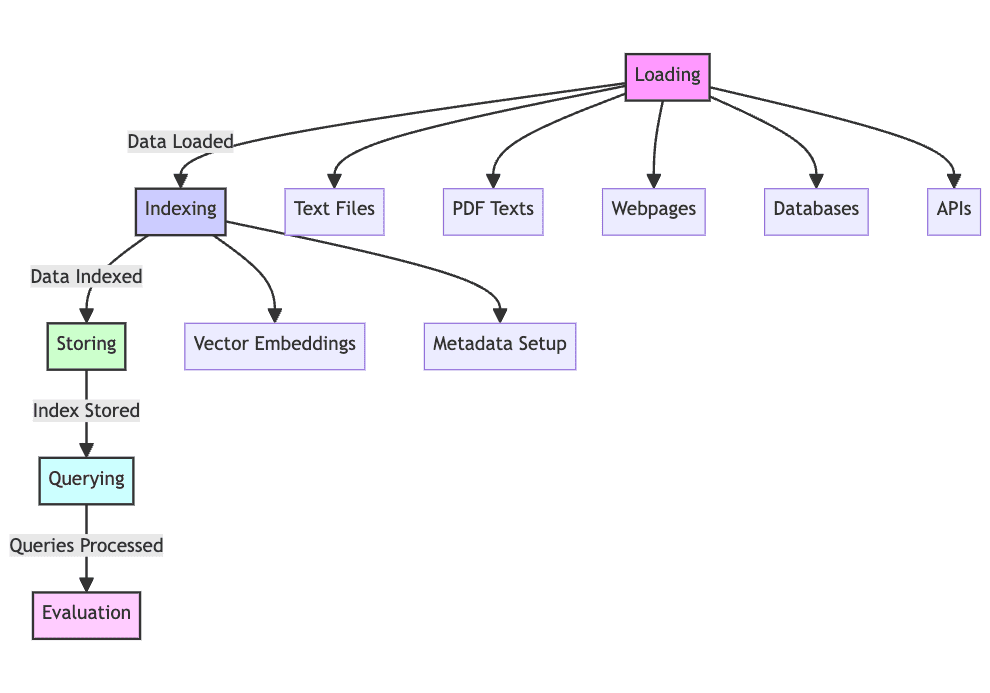
Bilde laget av forfatter
Et kort eksempel
Tenk på følgende enkle RAG-implementering. Tenk deg at dette er et system laget for å sende kundehenvendelser om en fiktiv nettbutikk.
1. Laster: Innhold kommer fra produktdokumentasjon, brukeranmeldelser og kundeinndata, lagret i flere formater som oppslagstavler, databaser og APIer.
2. Indeksering: Du vil produsere vektorinnbygginger for produktdokumentasjon og brukeranmeldelser osv., sammen med indeksering av metadata som er tildelt hvert datapunkt, for eksempel produktkategori eller kundevurdering.
3. Lagring: Indeksen som utvikles på denne måten vil bli lagret i et vektorlager, en spesialisert database for lagring og optimal gjenfinning av vektorer, som er hva innbygginger lagres som.
4. Spørre: Når en kundeforespørsel kommer, vil et vektorlagerdatabaseoppslag bli gjort basert på spørsmålsteksten, og språkmodeller blir deretter brukt for å generere svar ved å bruke opprinnelsen til disse forløperdataene som kontekst.
5. Evaluering: Systemytelsen vil bli evaluert ved å sammenligne ytelsen med andre alternativer, for eksempel gjenfinning av tradisjonelle språkmodeller, måling av beregninger som svarriktighet, svarforsinkelse og generell brukertilfredshet, for å sikre at RAG-systemet kan justeres og finpusses for å levere overlegent resultater.
Denne eksempelgjennomgangen bør gi deg en viss følelse av metodikken bak RAG og bruken av den for å formidle informasjonsinnhentingskapasitet på en språkmodell.
konklusjonen
Å introdusere utvidet generering for gjenfinning, som kombinerer tekstgenerering med informasjonsinnhenting for å forbedre nøyaktigheten og kontekstuell konsistens i språkmodellutdata, var temaet for denne artikkelen. Metoden tillater utvinning og utvidelse av data som er lagret i indekserte kilder, å bli inkorporert i den genererte utgangen av språkmodeller. Dette RAG-systemet kan gi økt verdi i forhold til ren finjustering av språkmodellen.
De neste trinnene i vår RAG-reise vil bestå av å lære bransjens verktøy for å implementere noen egne RAG-systemer. Vi vil først fokusere på å bruke verktøy fra LlamaIndex som datakoblinger, motorer og applikasjonskoblinger for å lette integreringen av RAG og skaleringen. Men vi lagrer dette til neste artikkel.
I kommende prosjekter vil vi bygge komplekse RAG-systemer og se på potensielle bruksområder og forbedringer av RAG-teknologi. Håpet er å avsløre mange nye muligheter innen kunstig intelligens, og å bruke disse forskjellige datakildene til å bygge mer intelligente og kontekstualiserte systemer.
Matthew Mayo (@mattmayo13) har en mastergrad i informatikk og en graduate diplom i data mining. Som administrerende redaktør har Matthew som mål å gjøre komplekse datavitenskapelige konsepter tilgjengelige. Hans profesjonelle interesser inkluderer naturlig språkbehandling, maskinlæringsalgoritmer og å utforske nye AI. Han er drevet av et oppdrag om å demokratisere kunnskap i datavitenskapsmiljøet. Matthew har kodet siden han var 6 år gammel.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk deg selv. Tilgang her.
- PlatoAiStream. Web3 Intelligence. Kunnskap forsterket. Tilgang her.
- PlatoESG. Karbon, CleanTech, Energi, Miljø, Solenergi, Avfallshåndtering. Tilgang her.
- PlatoHelse. Bioteknologisk og klinisk etterretning. Tilgang her.
- kilde: https://www.kdnuggets.com/retrieval-augmented-generation-where-information-retrieval-meets-text-generation?utm_source=rss&utm_medium=rss&utm_campaign=retrieval-augmented-generation-where-information-retrieval-meets-text-generation