
Fra og med utgivelse 6.14, Amazon EMR Studio støtter interaktive analyser på Amazon EMR-serverløs. Du kan nå bruke EMR-serverløse applikasjoner som beregning, i tillegg til Amazon EMR på EC2-klynger og Amazon EMR på EKS virtuelle klynger, for å kjøre JupyterLab-notatbøker fra EMR Studio Workspaces.
EMR Studio er et integrert utviklingsmiljø (IDE) som gjør det enkelt for dataforskere og dataingeniører å utvikle, visualisere og feilsøke analyseapplikasjoner skrevet i PySpark, Python og Scala. EMR Serverless er et serverløst alternativ for Amazon EMR som gjør det enkelt å kjøre rammeverk for stordataanalyse med åpen kildekode som Apache Spark uten å konfigurere, administrere og skalere klynger eller servere.
I innlegget viser vi hvordan du gjør følgende:
- Opprett et EMR-serverløst endepunkt for interaktive applikasjoner
- Koble endepunktet til et eksisterende EMR Studio-miljø
- Lag en notatbok og kjør en interaktiv applikasjon
- Diagnostiser interaktive applikasjoner sømløst fra EMR Studio
Forutsetninger
I en typisk organisasjon vil en AWS-kontoadministrator sette opp AWS-ressurser som f.eks AWS identitets- og tilgangsadministrasjon (IAM) roller, Amazon enkel lagringstjeneste (Amazon S3) bøtter, og Amazon Virtual Private Cloud (Amazon VPC) ressurser for internettilgang og tilgang til andre ressurser i VPC. De tildeler EMR Studio-administratorer som administrerer oppsett av EMR Studios og tilordner brukere til et spesifikt EMR Studio. Når de er tildelt, kan EMR Studio-utviklere bruke EMR Studio til å utvikle og overvåke arbeidsbelastninger.
Sørg for at du setter opp ressurser som S3-bøtten, VPC-undernett og EMR Studio i samme AWS-region.
Fullfør følgende trinn for å distribuere disse forutsetningene:
- Start følgende AWS skyformasjon stable.

- Angi verdier for AdminPassword og DevPassword og noter deg passordene du oppretter.
- Velg neste.
- Behold innstillingene som standard og velg neste en gang til.
- Plukke ut Jeg erkjenner at AWS CloudFormation kan lage IAM-ressurser med tilpassede navn.
- Velg Send.
Vi har også gitt instruksjoner for å distribuere disse ressursene manuelt med eksempler på IAM-policyer i GitHub repo.
Sett opp EMR Studio og en serverløs interaktiv applikasjon
Etter at AWS-kontoadministratoren har fullført forutsetningene, kan EMR Studio-administratoren logge på AWS-administrasjonskonsoll for å lage en EMR Studio, Workspace og EMR Serverless-applikasjon.
Lag et EMR-studio og arbeidsområde
EMR Studio-administratoren bør logge på konsollen ved å bruke emrs-interactive-app-admin-user brukerlegitimasjon. Hvis du distribuerte de nødvendige ressursene ved å bruke den medfølgende CloudFormation-malen, bruk passordet du oppga som en inngangsparameter.
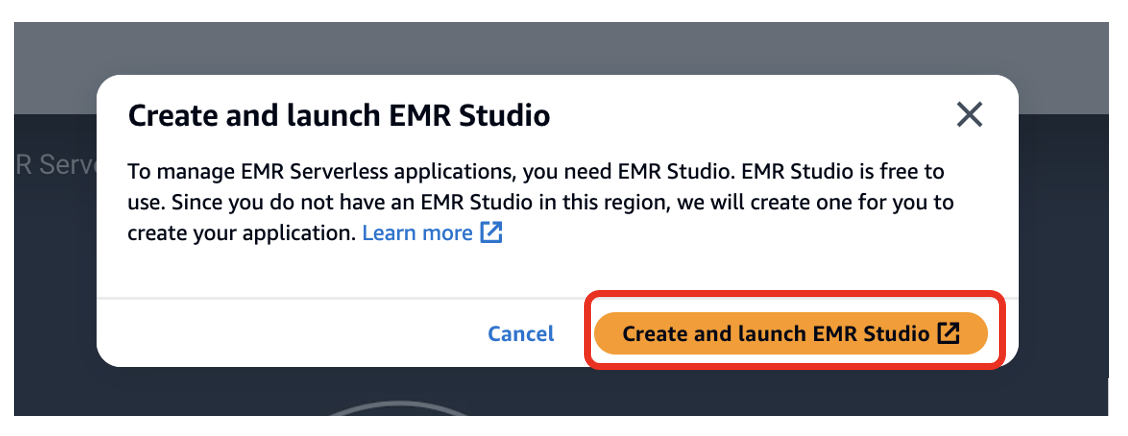
- På Amazon EMR-konsollen velger du EMR-serverløs i navigasjonsruten.

- Velg KOM I GANG.
- Plukke ut Opprett og start EMR Studio.
Dette oppretter et studio med standardnavnet studio_1 og et arbeidsområde med standardnavnet My_First_Workspace. En ny nettleserfane åpnes for Studio_1 brukergrensesnitt.
Opprett en EMR-serverløs applikasjon
Fullfør følgende trinn for å lage en EMR-serverløs applikasjon:
- På EMR Studio-konsollen velger du applikasjoner i navigasjonsruten.
- Opprett et nytt program.
- Til Navn, skriv inn et navn (for eksempel,
my-serverless-interactive-application). - Til Alternativer for programoppsett, plukke ut Bruk egendefinerte innstillinger for interaktive arbeidsmengder.
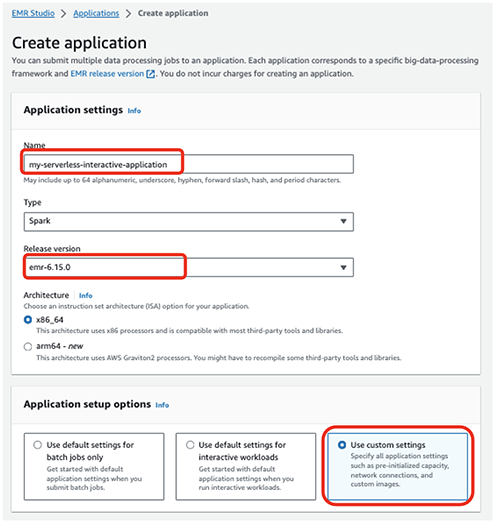
For interaktive applikasjoner, som en beste praksis, anbefaler vi å holde sjåføren og arbeiderne forhåndsinitialisert ved å konfigurere forhåndsinitialisert kapasitet på tidspunktet for søknadsoppretting. Dette skaper effektivt en varm pool av arbeidere for en applikasjon og holder ressursene klare til å bli konsumert, slik at applikasjonen kan svare på sekunder. For ytterligere beste praksis for å lage EMR-serverløse applikasjoner, se Definer ressursgrenser per team for big data-arbeidsbelastninger ved å bruke Amazon EMR Serverless.
- på Interaktivt endepunkt seksjon, velg Aktiver interaktivt endepunkt.
- på Nettverkstilkoblinger velger du VPC, private undernett og sikkerhetsgruppen du opprettet tidligere.
Hvis du distribuerte CloudFormation-stakken som er gitt i dette innlegget, velger du emr-serverless-sg som sikkerhetsgruppe.
En VPC er nødvendig for at arbeidsbelastningen skal kunne få tilgang til internett fra EMR Serverless-applikasjonen for å laste ned eksterne Python-pakker. VPC lar deg også få tilgang til ressurser som f.eks Amazon Relational Database Service (Amazon RDS) og Amazon RedShift som er i VPC fra denne applikasjonen. Å koble en serverløs applikasjon til en VPC kan føre til IP-utmattelse i subnettet, så sørg for at det er tilstrekkelig med IP-adresser i subnettet.
- Velg Opprett og start applikasjonen.

På applikasjonssiden kan du bekrefte at statusen til den serverløse applikasjonen endres til startet.
- Velg applikasjonen din og velg Hvordan fungerer det.
- Velg Se og start arbeidsområder.
- Velg Konfigurer studio.

- Til Tjenesterolle¸ oppgi EMR Studio-tjenesterollen du opprettet som en forutsetning (
emr-studio-service-role). - Til Oppbevaring av arbeidsplass, skriv inn banen til S3-bøtten du opprettet som en forutsetning (
emrserverless-interactive-blog-<account-id>-<region-name>). - Velg lagre endringer.
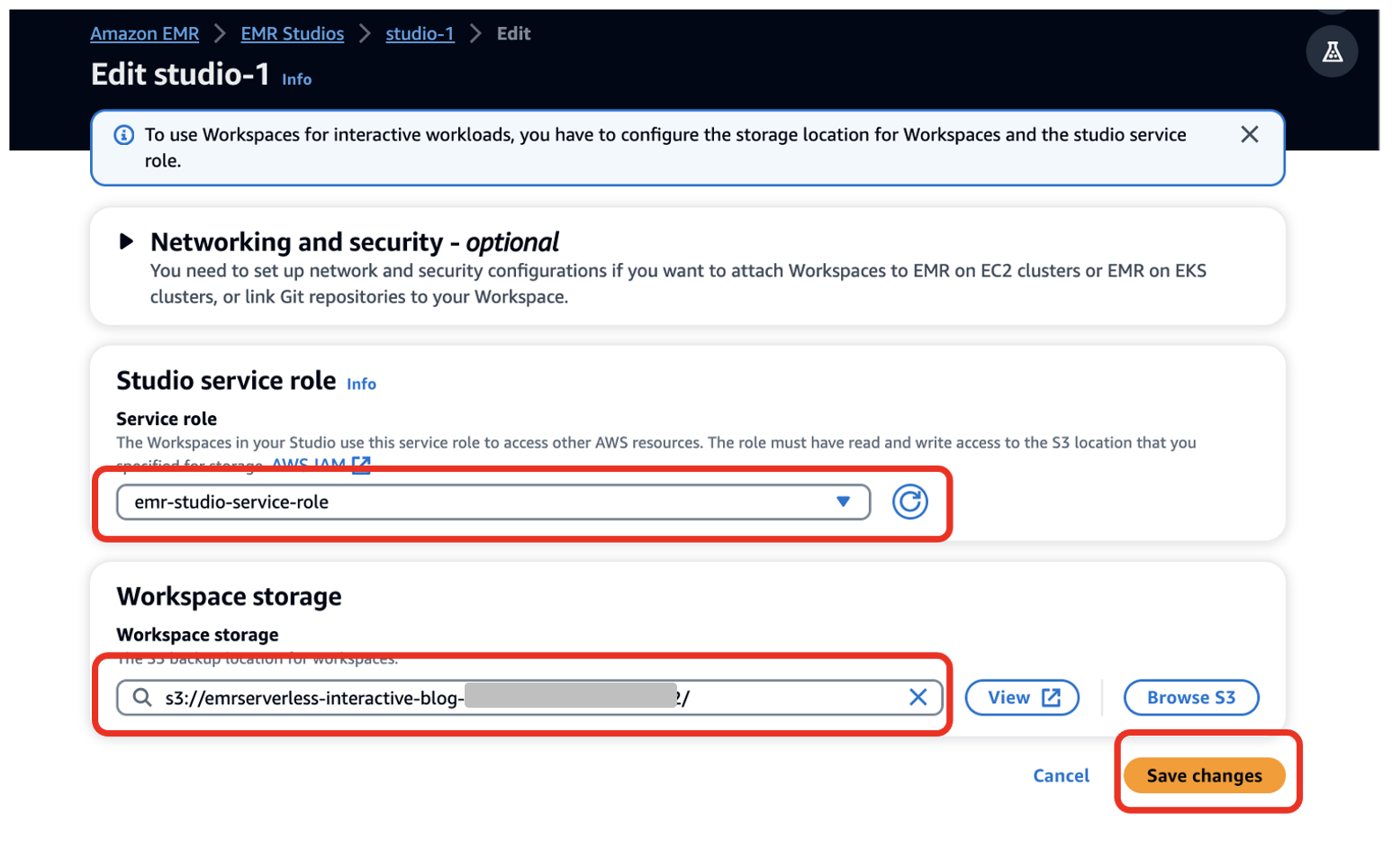
14. Naviger til Studios-konsollen ved å velge Studios i venstre navigasjonsmeny i EMR Studio seksjon. Legg merke til Nettadresse for studiotilgang fra Studios-konsollen og gi den til utviklerne dine for å kjøre deres Spark-applikasjoner.
Kjør din første Spark-applikasjon
Etter at EMR Studio-administratoren har opprettet Studio-, Workspace- og serverløs-applikasjonen, kan Studio-brukeren bruke Workspace og applikasjonen til å utvikle og overvåke Spark-arbeidsbelastninger.
Start Workspace og legg ved den serverløse applikasjonen
Fullfør følgende trinn:
- Bruk Studio-URL-en som er gitt av EMR Studio-administratoren, logg på med
emrs-interactive-app-dev-userbrukerlegitimasjon som deles av AWS-kontoadministratoren.
Hvis du distribuerte de nødvendige ressursene ved å bruke den medfølgende CloudFormation-malen, bruk passordet du oppga som en inngangsparameter.
På arbeidsområder siden, kan du sjekke statusen til arbeidsområdet ditt. Når arbeidsområdet er lansert, vil du se statusendringen til Klar.
- Start arbeidsområdet ved å velge arbeidsområdets navn (
My_First_Workspace).
Dette åpner en ny fane. Sørg for at nettleseren tillater popup-vinduer.
- Velg i arbeidsområdet Beregn (klyngeikon) i navigasjonsruten.
- Til EMR Serverløs applikasjon, velg søknaden din (
my-serverless-interactive-application). - Til Interaktiv kjøretidsrolle, velg en interaktiv kjøretidsrolle (for dette innlegget bruker vi
emr-serverless-runtime-role). - Velg Fest for å legge ved den serverløse applikasjonen som beregningstype for alle notatbøkene i dette arbeidsområdet.

Kjør Spark-applikasjonen din interaktivt
Fullfør følgende trinn:
- Velg Eksempler på notatbok (ikon med tre prikker) i navigasjonsruten og åpne
Getting-started-with-emr-serverlessnotisbok. - Velg Lagre til Workspace.
Det er tre valg av kjerner for notatboken vår: Python 3, PySpark og Spark (for Scala).
- Når du blir bedt om det, velg PySpark som kjernen.
- Velg Plukke ut.

Nå kan du kjøre Spark-applikasjonen din. For å gjøre det, bruk %%configure Sparkmagic kommando, som konfigurerer parametere for opprettelse av økter. Interaktive applikasjoner støtter virtuelle Python-miljøer. Vi bruker et tilpasset miljø i arbeidernodene ved å spesifisere en bane for en annen Python-kjøretid for eksekveringsmiljøet ved å bruke spark.executorEnv.PYSPARK_PYTHON. Se følgende kode:
Installer eksterne pakker
Nå som du har et uavhengig virtuelt miljø for arbeiderne, lar EMR Studio bærbare datamaskiner deg installere eksterne pakker fra den serverløse applikasjonen ved å bruke Spark install_pypi_package fungere gjennom Spark-konteksten. Ved å bruke denne funksjonen blir pakken tilgjengelig for alle EMR-serverløse arbeidere.
Installer først matplotlib, en Python-pakke, fra PyPi:
Hvis det foregående trinnet ikke svarer, sjekk VPC-oppsettet ditt og sørg for at det er riktig konfigurert for internettilgang.
Nå kan du bruke et datasett og visualisere dataene dine.
Lag visualiseringer
For å lage visualiseringer bruker vi et offentlig datasett på NYC gule taxier:
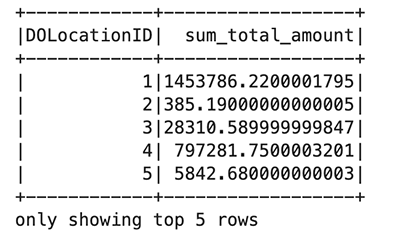
I den foregående kodeblokken leser du Parkett-filen fra en offentlig bøtte i Amazon S3. Filen har overskrifter, og vi vil at Spark skal utlede skjemaet. Du bruker deretter en Spark-dataramme til å gruppere og telle spesifikke kolonner fra taxi_df:
Bruk %%display magisk for å se resultatet i tabellformat:

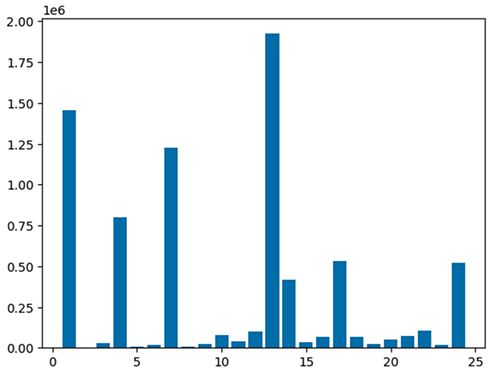
Du kan også raskt visualisere dataene dine med fem typer diagrammer. Du kan velge visningstype og diagrammet vil endres tilsvarende. I det følgende skjermbildet bruker vi et stolpediagram for å visualisere dataene våre.

Samhandle med EMR Serverless ved hjelp av Spark SQL
Du kan samhandle med tabeller i AWS Lim Data Catalog bruker Spark SQL på EMR Serverless. I eksempelnotisboken viser vi hvordan du kan transformere data ved hjelp av en Spark-dataramme.
Først oppretter du en ny midlertidig visning kalt taxis. Dette lar deg bruke Spark SQL til å velge data fra denne visningen. Lag deretter en taxidataramme for videre behandling:
I hver celle i EMR Studio-notisboken din kan du utvide Spark Job Progress for å se de ulike stadiene av jobben som sendes til EMR Serverless mens du kjører denne spesifikke cellen. Du kan se tiden det tar å fullføre hvert trinn. I det følgende eksempelet har trinn 14 av jobben 12 fullførte oppgaver. I tillegg, hvis det er noen feil, kan du se loggene, noe som gjør feilsøking til en sømløs opplevelse. Vi diskuterer dette mer i neste avsnitt.
![Job[14]: showString på NativeMethodAccessorImpl.java:0 og Job[15]: showString på NativeMethodAccessorImpl.java:0](https://xlera8.com/wp-content/uploads/2024/04/run-interactive-workloads-on-amazon-emr-serverless-from-amazon-emr-studio-amazon-web-services-11.png)
Bruk følgende kode for å visualisere den behandlede datarammen ved å bruke matplotlib-pakken. Du bruker maptplotlib-biblioteket til å plotte avleveringsstedet og den totale mengden som et stolpediagram.
Diagnostiser interaktive applikasjoner
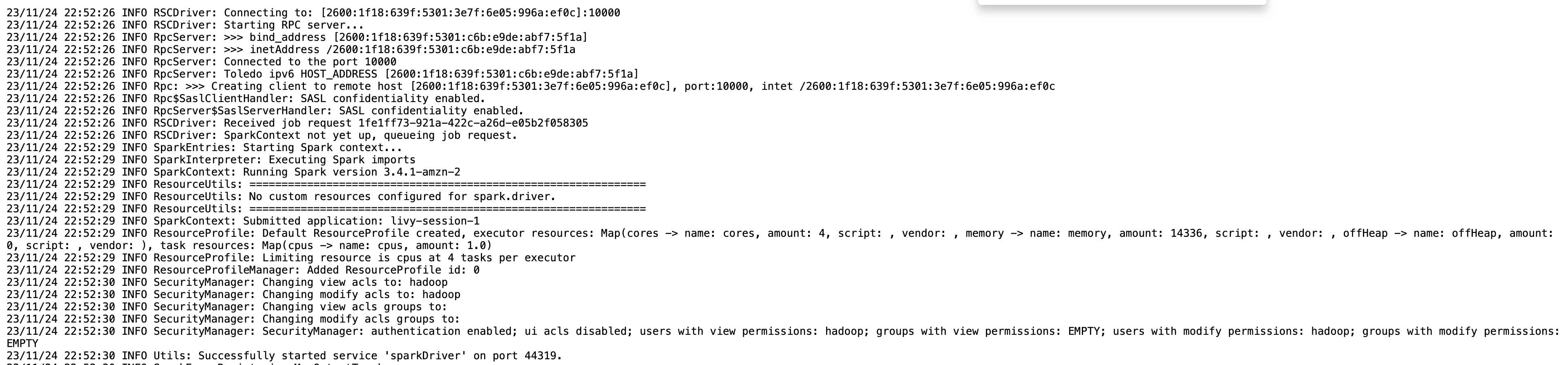
Du kan få øktinformasjonen for Livy-endepunktet ditt ved å bruke %%info Sparkmagic. Dette gir deg lenker for å få tilgang til Spark-grensesnittet samt driverloggen rett i den bærbare datamaskinen.

Følgende skjermbilde er en sjåførloggbit for applikasjonen vår, som vi åpnet via lenken i notatboken vår.
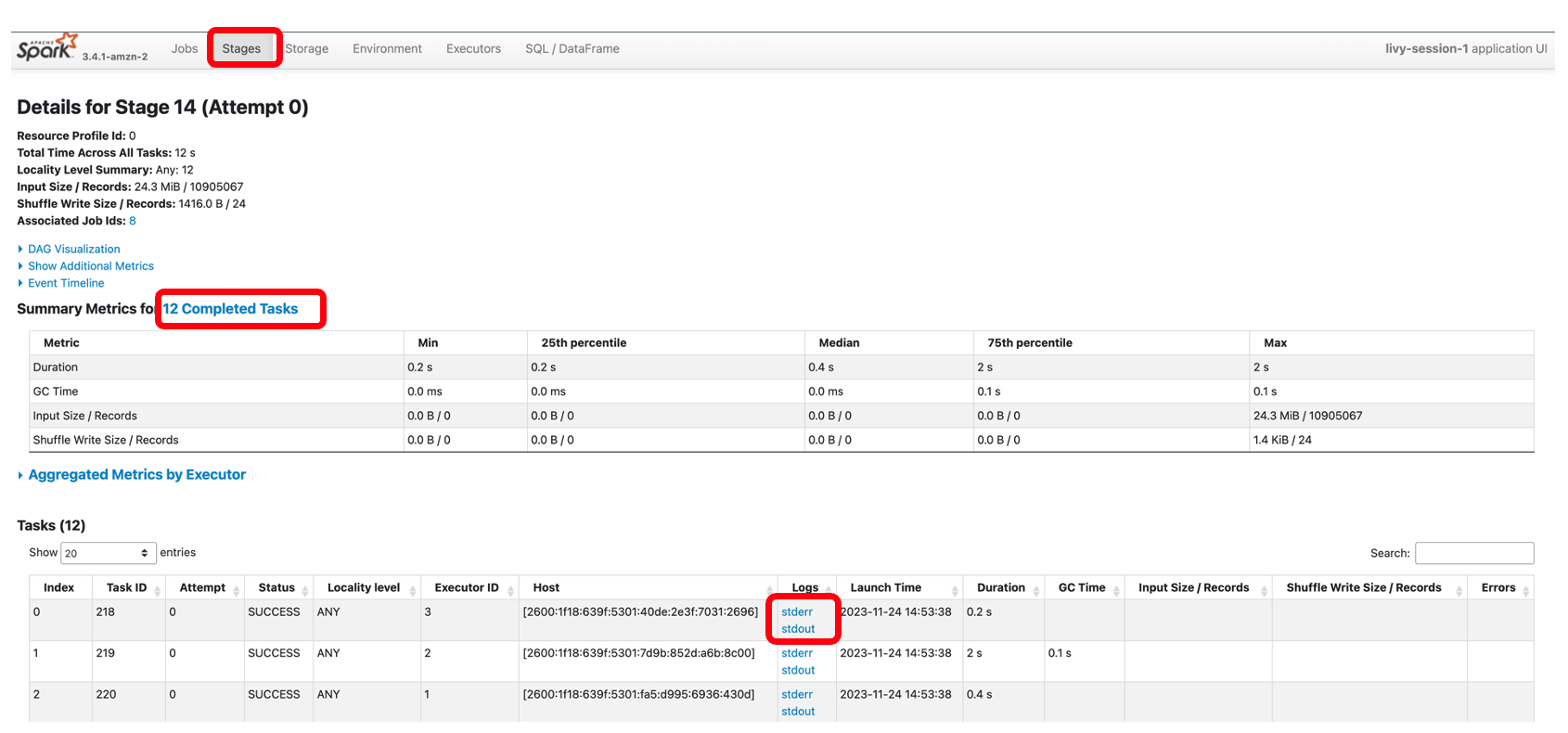
På samme måte kan du velge lenken nedenfor Spark UI for å åpne brukergrensesnittet. Følgende skjermbilde viser Henrettere fanen, som gir tilgang til driver- og eksekveringsloggene.

Følgende skjermbilde viser trinn 14, som tilsvarer Spark SQL-trinnet vi så tidligere, der vi beregnet den stedmessige summen av totale taxisamlinger, som var delt opp i 12 oppgaver. Gjennom Spark-brukergrensesnittet gir den interaktive applikasjonen finmasket status på oppgavenivå, I/O og tilfeldig rekkefølge, samt lenker til tilsvarende logger for hver oppgave for dette stadiet rett fra den bærbare datamaskinen, noe som muliggjør en sømløs feilsøkingsopplevelse.
Rydd opp
Hvis du ikke lenger vil beholde ressursene som er opprettet i dette innlegget, fullfør følgende oppryddingstrinn:
- Slett EMR Serverless-applikasjonen.
- Slett EMR Studio og de tilknyttede arbeidsområdene og notatbøkene.
- For å slette resten av ressursene, naviger til CloudFormation-konsollen, velg stabelen og velg Delete.
Alle ressursene vil bli slettet bortsett fra S3-bøtten, som har en slettepolicy satt til å beholde.
konklusjonen
Innlegget viste hvordan du kjører interaktive PySpark-arbeidsbelastninger i EMR Studio ved å bruke EMR Serverless som beregning. Du kan også bygge og overvåke Spark-applikasjoner i et interaktivt JupyterLab-arbeidsområde.
I et kommende innlegg vil vi diskutere tilleggsfunksjonene til EMR Serverless Interactive-applikasjoner, for eksempel:
- Arbeide med ressurser som Amazon RDS og Amazon Redshift i din VPC (for eksempel for JDBC/ODBC-tilkobling)
- Kjører transaksjonelle arbeidsbelastninger ved hjelp av serverløse endepunkter
Hvis dette er første gang du utforsker EMR Studio, anbefaler vi å sjekke ut Amazon EMR-verksteder og refererer til Lag et EMR-studio.
Om forfatterne
 Sekar Srinivasan er en hovedspesialistløsningsarkitekt hos AWS med fokus på dataanalyse og AI. Sekar har over 20 års erfaring med å jobbe med data. Han brenner for å hjelpe kunder med å bygge skalerbare løsninger som moderniserer arkitekturen deres og genererer innsikt fra dataene deres. På fritiden liker han å jobbe med ideelle prosjekter, med fokus på underprivilegerte barns utdanning.
Sekar Srinivasan er en hovedspesialistløsningsarkitekt hos AWS med fokus på dataanalyse og AI. Sekar har over 20 års erfaring med å jobbe med data. Han brenner for å hjelpe kunder med å bygge skalerbare løsninger som moderniserer arkitekturen deres og genererer innsikt fra dataene deres. På fritiden liker han å jobbe med ideelle prosjekter, med fokus på underprivilegerte barns utdanning.
 Disha Umarwani er en senior dataarkitekt med Amazon Professional Services innen Global Health Care og LifeSciences. Hun har jobbet med kunder for å designe, arkitekte og implementere datastrategi i stor skala. Hun spesialiserer seg på arkitektur av Data Mesh-arkitekturer for Enterprise-plattformer.
Disha Umarwani er en senior dataarkitekt med Amazon Professional Services innen Global Health Care og LifeSciences. Hun har jobbet med kunder for å designe, arkitekte og implementere datastrategi i stor skala. Hun spesialiserer seg på arkitektur av Data Mesh-arkitekturer for Enterprise-plattformer.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk deg selv. Tilgang her.
- PlatoAiStream. Web3 Intelligence. Kunnskap forsterket. Tilgang her.
- PlatoESG. Karbon, CleanTech, Energi, Miljø, Solenergi, Avfallshåndtering. Tilgang her.
- PlatoHelse. Bioteknologisk og klinisk etterretning. Tilgang her.
- kilde: https://aws.amazon.com/blogs/big-data/run-interactive-workloads-on-amazon-emr-serverless-from-amazon-emr-studio/