
Wprowadzenie
Uczenie maszynowe (ML) to dziedzina nauki, która koncentruje się na opracowywaniu algorytmów do automatycznego uczenia się na podstawie danych, dokonywaniu prognoz i wnioskowaniu wzorców bez wyraźnego mówienia, jak to zrobić. Ma na celu tworzenie systemów, które automatycznie ulepszają się wraz z doświadczeniem i danymi.
Można to osiągnąć poprzez uczenie nadzorowane, w którym model jest szkolony przy użyciu oznaczonych danych w celu przewidywania, lub poprzez uczenie nienadzorowane, w którym model ma na celu odkrycie wzorców lub korelacji w danych bez przewidywania określonych wyników docelowych.
Uczenie maszynowe stało się niezbędnym i szeroko stosowanym narzędziem w różnych dyscyplinach, w tym w informatyce, biologii, finansach i marketingu. Udowodnił swoją przydatność w różnych zastosowaniach, takich jak klasyfikacja obrazów, przetwarzanie języka naturalnego i wykrywanie oszustw.
Zadania uczenia maszynowego
Uczenie maszynowe można ogólnie podzielić na trzy główne zadania:
- Nadzorowana nauka
- Uczenie się bez nadzoru
- Uczenie się przez wzmocnienie
Tutaj skupimy się na dwóch pierwszych przypadkach.
Nadzorowana nauka
Uczenie nadzorowane obejmuje trenowanie modelu na danych oznaczonych etykietami, w których dane wejściowe są parowane z odpowiednią zmienną wyjściową lub docelową. Celem jest nauczenie się funkcji, która może odwzorować dane wejściowe na poprawne dane wyjściowe. Typowe algorytmy uczenia nadzorowanego obejmują regresję liniową, regresję logistyczną, drzewa decyzyjne i maszyny wektorów nośnych.
Przykład nadzorowanego uczenia się kodu przy użyciu Pythona:
from sklearn.linear_model import LinearRegression model = LinearRegression() model.fit(X_train, y_train) predictions = model.predict(X_test)
W tym prostym przykładzie kodu uczymy LinearRegression algorytm z scikit-learn na naszych danych treningowych, a następnie zastosować go, aby uzyskać prognozy dla naszych danych testowych.
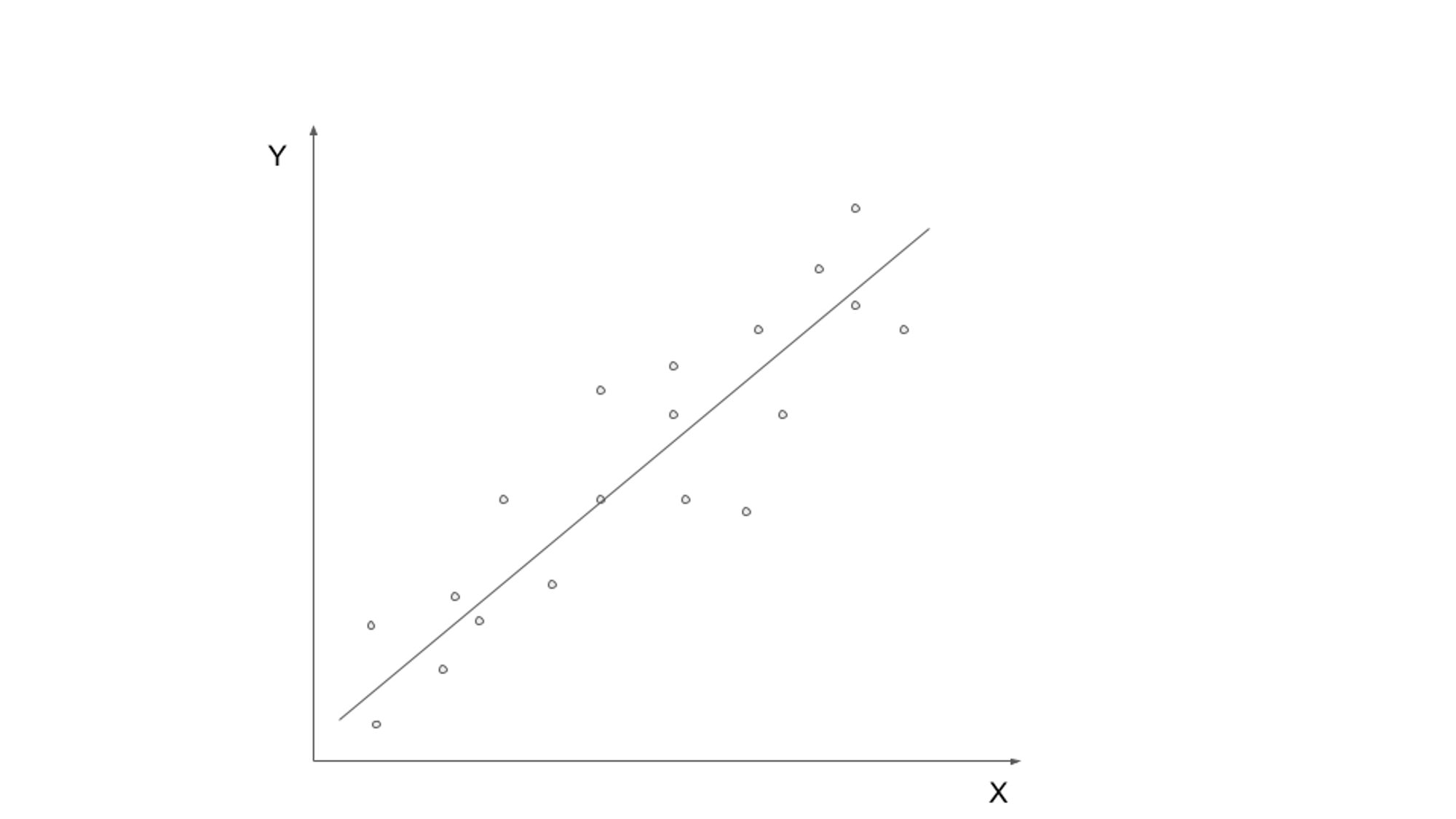
Jednym z rzeczywistych przypadków zastosowania uczenia nadzorowanego jest klasyfikacja spamu e-mail. Wraz z wykładniczym rozwojem komunikacji e-mailowej identyfikacja i filtrowanie spamu stało się kluczowe. Wykorzystując algorytmy uczenia nadzorowanego, możliwe jest wytrenowanie modelu w celu odróżnienia legalnych wiadomości e-mail od spamu na podstawie oznaczonych danych.
Model uczenia nadzorowanego można trenować na zbiorze danych zawierającym wiadomości e-mail oznaczone jako „spam” lub „nie spam”. Model uczy się wzorców i funkcji z danych oznaczonych etykietami, takich jak obecność określonych słów kluczowych, struktura wiadomości e-mail lub informacje o nadawcy wiadomości e-mail. Po przeszkoleniu modelu można go używać do automatycznego klasyfikowania przychodzących wiadomości e-mail jako spam lub niespam, wydajnie filtrując niechciane wiadomości.
Uczenie się bez nadzoru
W uczeniu nienadzorowanym dane wejściowe są nieoznaczone, a celem jest odkrycie wzorców lub struktur w danych. Algorytmy uczenia bez nadzoru mają na celu znalezienie znaczących reprezentacji lub klastrów w danych.
Przykłady algorytmów uczenia się bez nadzoru obejmują k-średnie grupowanie, hierarchiczne grupowanie, analiza głównych składowych (PCA).
Przykład kodu uczenia się bez nadzoru:
from sklearn.cluster import KMeans model = KMeans(n_clusters=3) model.fit(X) predictions = model.predict(X_new)
W tym prostym przykładzie kodu uczymy KMeans algorytm z scikit-learn, aby zidentyfikować trzy klastry w naszych danych, a następnie dopasować nowe dane do tych klastrów.
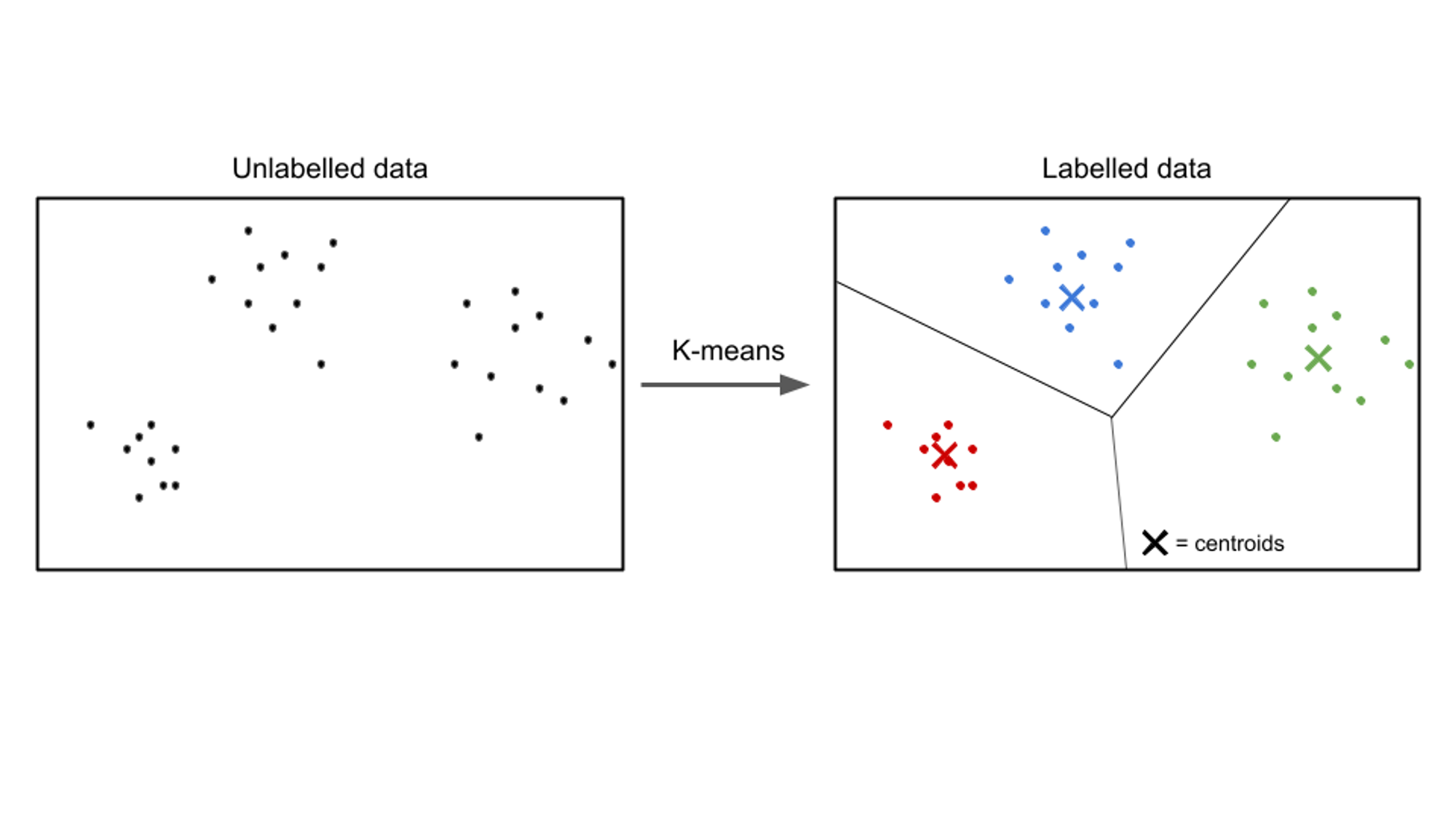
Przykładem przypadku użycia uczenia się bez nadzoru jest segmentacja klientów. W różnych branżach firmy dążą do lepszego zrozumienia swojej bazy klientów, aby dostosować strategie marketingowe, spersonalizować swoje oferty i zoptymalizować doświadczenia klientów. Algorytmy uczenia się bez nadzoru można wykorzystać do podzielenia klientów na odrębne grupy na podstawie ich wspólnych cech i zachowań.
Zapoznaj się z naszym praktycznym, praktycznym przewodnikiem dotyczącym nauki Git, zawierającym najlepsze praktyki, standardy przyjęte w branży i dołączoną ściągawkę. Zatrzymaj polecenia Google Git, a właściwie uczyć się to!
Stosując techniki uczenia się bez nadzoru, takie jak tworzenie klastrów, firmy mogą odkryć znaczące wzorce i grupy w swoich danych klientów. Na przykład algorytmy grupowania mogą identyfikować grupy klientów o podobnych nawykach zakupowych, danych demograficznych lub preferencjach. Informacje te można wykorzystać do tworzenia ukierunkowanych kampanii marketingowych, optymalizacji rekomendacji produktów i poprawy zadowolenia klientów.
Główne klasy algorytmów
Algorytmy uczenia nadzorowanego
-
Modele liniowe: używane do przewidywania zmiennych ciągłych na podstawie liniowych relacji między cechami a zmienną przewidywaną.
-
Modele oparte na drzewach: skonstruowane przy użyciu serii decyzji binarnych w celu przewidywania lub klasyfikacji.
-
Modele zespołowe: Metoda, która łączy wiele modeli (opartych na drzewie lub liniowych) w celu uzyskania dokładniejszych prognoz.
-
Modele sieci neuronowych: metody luźno oparte na ludzkim mózgu, w którym wiele funkcji działa jako węzły sieci.
Algorytmy uczenia się bez nadzoru
-
Hierarchiczne grupowanie: buduje hierarchię klastrów poprzez iteracyjne łączenie lub dzielenie.
-
Grupowanie niehierarchiczne: dzieli dane na odrębne klastry na podstawie podobieństwa.
-
Redukcja wymiarowości: Zmniejsza wymiarowość danych przy jednoczesnym zachowaniu najważniejszych informacji.
Ocena modelu
Nadzorowana nauka
Aby ocenić wydajność modeli uczenia nadzorowanego, stosuje się różne wskaźniki, w tym dokładność, precyzję, przypominanie, wynik F1 i ROC-AUC. Techniki walidacji krzyżowej, takie jak k-krotna walidacja krzyżowa, mogą pomóc oszacować wydajność generalizacji modelu.
Uczenie się bez nadzoru
Ocena algorytmów uczenia się bez nadzoru jest często trudniejsza, ponieważ nie ma żadnej podstawowej prawdy. Metryki, takie jak wynik sylwetki lub bezwładność, mogą być wykorzystane do oceny jakości wyników grupowania. Techniki wizualizacji mogą również zapewnić wgląd w strukturę klastrów.
Sztuczki i kruczki
Nadzorowana nauka
- Przetwarzaj wstępnie i normalizuj dane wejściowe, aby poprawić wydajność modelu.
- Odpowiednio obsługuj brakujące wartości, albo przez imputację, albo przez usunięcie.
- Inżynieria cech może zwiększyć zdolność modelu do uchwycenia odpowiednich wzorców.
Uczenie się bez nadzoru
- Wybierz odpowiednią liczbę klastrów w oparciu o wiedzę domenową lub stosując techniki takie jak metoda łokcia.
- Rozważ różne metryki odległości, aby zmierzyć podobieństwo między punktami danych.
- Regularyzuj proces grupowania, aby uniknąć przeuczenia.
Podsumowując, uczenie maszynowe obejmuje wiele zadań, technik, algorytmów, metod oceny modeli i pomocnych wskazówek. Dzięki zrozumieniu tych aspektów praktycy mogą skutecznie zastosować uczenie maszynowe do rzeczywistych problemów i uzyskiwać istotne informacje z danych. Podane przykłady kodu pokazują wykorzystanie algorytmów uczenia nadzorowanego i nienadzorowanego, podkreślając ich praktyczną implementację.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- EVM Finanse. Ujednolicony interfejs dla zdecentralizowanych finansów. Dostęp tutaj.
- Quantum Media Group. Wzmocnienie IR/PR. Dostęp tutaj.
- PlatoAiStream. Analiza danych Web3. Wiedza wzmocniona. Dostęp tutaj.
- Źródło: https://stackabuse.com/supervised-learning-vs-unsupervised-learning-algorithms/