
Przepływ pracy zarządzany przez Amazon dla Apache Airflow (Amazon MWAA) to usługa zarządzana, która umożliwia korzystanie ze znanego Przepływ powietrza Apache środowisko o zwiększonej skalowalności, dostępności i bezpieczeństwie, umożliwiające usprawnienie i skalowanie przepływów pracy w firmie bez obciążeń operacyjnych związanych z zarządzaniem podstawową infrastrukturą. w przepływie powietrza, Kierowane grafy acykliczne (DAG) są zdefiniowane jako kod Pythona. Dynamiczne DAG odnoszą się do możliwości generowania DAG na bieżąco w czasie wykonywania, zazwyczaj w oparciu o pewne warunki zewnętrzne, konfiguracje lub parametry. Dynamiczne DAG pomagają tworzyć, planować i uruchamiać zadania w ramach DAG w oparciu o dane i konfiguracje, które mogą zmieniać się w czasie.
Istnieją różne sposoby wprowadzenia dynamiki w DAG-ach Airflow (dynamiczna generacja DAG) przy użyciu zmiennych środowiskowych i plików zewnętrznych. Jednym ze sposobów jest użycie tzw Fabryka DAG Metoda pliku konfiguracyjnego oparta na YAML. Ta biblioteka ma na celu ułatwienie tworzenia i konfiguracji nowych DAG za pomocą parametrów deklaratywnych w YAML. Umożliwia domyślne dostosowania i jest oprogramowaniem typu open source, co ułatwia tworzenie i dostosowywanie nowych funkcjonalności.
W tym poście badamy proces tworzenia dynamicznych DAG-ów z plikami YAML przy użyciu Fabryka DAG biblioteka. Dynamiczne DAG oferują kilka korzyści:
- Większa możliwość ponownego wykorzystania kodu – Strukturyzując DAG za pomocą plików YAML, promujemy komponenty wielokrotnego użytku, zmniejszając redundancję w definicjach przepływu pracy.
- Usprawniona konserwacja – Generowanie DAG w oparciu o YAML upraszcza proces modyfikacji i aktualizacji przepływów pracy, zapewniając płynniejsze procedury konserwacji.
- Elastyczna parametryzacja – Dzięki YAML możesz parametryzować konfiguracje DAG, ułatwiając dynamiczne dostosowywanie przepływów pracy w oparciu o różne wymagania.
- Większa wydajność programu planującego – Dynamiczne DAG umożliwiają bardziej efektywne planowanie, optymalizację alokacji zasobów i usprawnianie ogólnych przebiegów przepływu pracy
- Większa skalowalność – Oparte na YAML moduły DAG umożliwiają równoległe przebiegi, umożliwiając skalowalne przepływy pracy, które mogą efektywnie obsługiwać zwiększone obciążenia.
Wykorzystując moc plików YAML i biblioteki DAG Factory, udostępniamy wszechstronne podejście do tworzenia DAG i zarządzania nimi, umożliwiając tworzenie solidnych, skalowalnych i łatwych w utrzymaniu potoków danych.
Przegląd rozwiązania
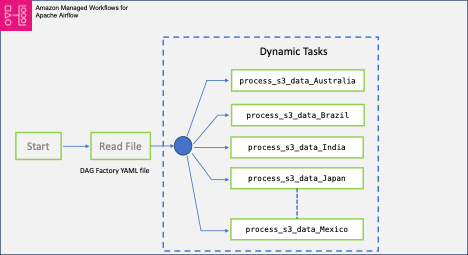
W tym poście wykorzystamy przykładowy plik DAG, który jest przeznaczony do przetwarzania zbioru danych dotyczących COVID-19. Proces przepływu pracy obejmuje przetwarzanie zbioru danych typu open source oferowanego przez WHO-COVID-19-Globalny. Po zainstalowaniu Fabryka DAG Pythona, tworzymy plik YAML, który zawiera definicje różnych zadań. Przetwarzamy liczbę zgonów właściwą dla danego kraju Country jako zmienną, która tworzy indywidualne DAG w danym kraju.
Poniższy diagram ilustruje całe rozwiązanie wraz z przepływami danych w ramach bloków logicznych.
Wymagania wstępne
W tej instrukcji należy spełnić następujące wymagania wstępne:
Dodatkowo wykonaj następujące kroki (uruchom instalację w pliku Region AWS gdzie dostępny jest Amazon MWAA):
- Tworzenie Środowisko Amazon MWAA (jeśli jeszcze go nie masz). Jeśli po raz pierwszy korzystasz z Amazon MWAA, zapoznaj się z sekcją Przedstawiamy przepływy pracy zarządzane przez Amazon dla Apache Airflow (MWAA).
Upewnij się, AWS Zarządzanie tożsamością i dostępem (IAM) użytkownik lub rola używana do konfigurowania środowiska ma dołączone zasady uprawnień dotyczące następujących uprawnień:
Wymienione tutaj zasady dostępu służą jedynie jako przykład w tym poście. W środowisku produkcyjnym zapewnij w drodze ćwiczeń tylko potrzebne szczegółowe uprawnienia zasady najmniejszych przywilejów.
- Utwórz unikalną (w obrębie konta) nazwę segmentu Amazon S3 podczas tworzenia środowiska Amazon MWAA i utwórz foldery o nazwie
dagsirequirements.
- Utwórz i prześlij
requirements.txtplik o następującej zawartości do plikurequirementsteczka. Zastępować{environment-version}z numerem wersji środowiska oraz{Python-version}z wersją Pythona zgodną z twoim środowiskiem:
Pandy są potrzebne tylko w przykładowym przypadku użycia opisanym w tym poście, oraz dag-factory jest jedyną wymaganą wtyczką. Zalecane jest sprawdzenie kompatybilności najnowszej wersji dag-factory z Amazonem MWAA. The boto i psycopg2-binary biblioteki są dołączone do podstawowej instalacji Apache Airflow v2 i nie trzeba ich określać w pliku requirements.txt plik.
- Pobierz Globalny plik danych WHO-COVID-19 na komputer lokalny i prześlij go w folderze
dagsprzedrostek Twojego wiadra S3.
Upewnij się, że wskazujesz najnowszą wersję wiadra AWS S3 requirements.txt plik, aby mogła nastąpić instalacja dodatkowego pakietu. Zwykle powinno to zająć od 15 do 20 minut, w zależności od konfiguracji środowiska.
Zweryfikuj DAG
Gdy środowisko Amazon MWAA wyświetla się jako Dostępny na konsoli Amazon MWAA przejdź do interfejsu użytkownika Airflow, wybierając Otwórz interfejs przepływu powietrza obok swojego otoczenia.

Sprawdź istniejące DAG, przechodząc do karty DAG.
Skonfiguruj swoje DAG-y
Wykonaj następujące kroki:
- Utwórz puste pliki o nazwie
dynamic_dags.yml,example_dag_factory.pyiprocess_s3_data.pyna twojej lokalnej maszynie. - Edytuj
process_s3_data.pyplik i zapisz go z następującą zawartością kodu, a następnie prześlij plik z powrotem do segmentu Amazon S3dagsteczka. Wykonujemy podstawowe przetwarzanie danych w kodzie:- Przeczytaj plik z lokalizacji Amazon S3
- Zmień nazwę pliku
Country_codekolumna odpowiednia dla kraju. - Filtruj dane według podanego kraju.
- Zapisz przetworzone dane końcowe w formacie CSV i prześlij z powrotem do prefiksu S3.
- Edytuj
dynamic_dags.ymli zapisz go z następującą zawartością kodu, a następnie prześlij plik z powrotem dodagsteczka. Szyjemy różne DAG-y w zależności od kraju w następujący sposób:- Zdefiniuj domyślne argumenty przekazywane do wszystkich DAG.
- Utwórz definicję DAG dla poszczególnych krajów, przechodząc
op_args - Mapuj
process_s3_datafunkcja zpython_callable_name. - Zastosowanie Operator Pythona do przetwarzania danych w pliku csv przechowywanych w zasobniku Amazon S3.
- Ustawiliśmy
schedule_intervalmaksymalnie 10 minut, ale w razie potrzeby możesz dostosować tę wartość.
- Edytuj plik
example_dag_factory.pyi zapisz go z następującą zawartością kodu, a następnie prześlij plik z powrotem dodagsteczka. Kod czyści istniejące DAG i generujeclean_dags()metody i tworzenia nowych DAG-ów przy użyciu metodygenerate_dags()metoda zDagFactoryinstancja.
- Po przesłaniu plików wróć do konsoli interfejsu użytkownika Airflow i przejdź do zakładki DAG, gdzie znajdziesz nowe DAG.

- Po przesłaniu plików wróć do konsoli interfejsu użytkownika Airflow i na karcie DAG zobaczysz, że pojawiają się nowe pliki DAG, jak pokazano poniżej:

Możesz włączyć grupy DAG, czyniąc je aktywnymi i testując je indywidualnie. Po aktywacji dodatkowy plik CSV o nazwie count_death_{COUNTRY_CODE}.csv jest generowany w folderze dags.
Sprzątanie
Korzystanie z różnych usług AWS omówionych w tym poście może wiązać się z kosztami. Aby zapobiec naliczaniu przyszłych opłat, po wykonaniu zadań opisanych w tym poście usuń środowisko Amazon MWAA, a następnie opróżnij i usuń segment S3.
Wnioski
W tym poście na blogu pokazaliśmy, jak używać fabryka dag biblioteka do tworzenia dynamicznych DAG-ów. Dynamiczne DAG charakteryzują się możliwością generowania wyników przy każdym analizowaniu pliku DAG w oparciu o konfiguracje. Rozważ użycie dynamicznych DAG w następujących scenariuszach:
- Automatyzacja migracji ze starszego systemu do Airflow, gdzie kluczowa jest elastyczność w generowaniu DAG
- Sytuacje, w których pomiędzy różnymi DAGami zmienia się tylko parametr, usprawniając proces zarządzania przepływem pracy
- Zarządzanie DAG-ami, które opierają się na ewoluującej strukturze systemu źródłowego, zapewniając możliwość adaptacji do zmian
- Ustanawianie standardowych praktyk dla DAG w całym zespole lub organizacji poprzez tworzenie tych planów, promowanie spójności i wydajności
- Uwzględnienie deklaracji opartych na YAML w porównaniu ze złożonym kodowaniem Pythona, upraszczając procesy konfiguracji i konserwacji DAG
- Tworzenie przepływów pracy opartych na danych, które dostosowują się i ewoluują w oparciu o dane wejściowe, umożliwiając wydajną automatyzację
Włączając dynamiczne DAG do swojego przepływu pracy, możesz zwiększyć automatyzację, możliwości adaptacji i standaryzację, ostatecznie poprawiając wydajność i skuteczność zarządzania potokiem danych.
Aby dowiedzieć się więcej o fabryce Amazon MWAA DAG, odwiedź stronę Warsztaty Amazon MWAA dla analityki: fabryka DAG. Dodatkowe szczegóły i przykłady kodu dotyczące Amazon MWAA można znaleźć na stronie Podręcznik użytkownika Amazon MWAA oraz Przykłady Amazon MWAA GitHub magazyn.
O autorach
 Jayesha Shinde’a jest starszym architektem aplikacji w AWS ProServe India. Specjalizuje się w tworzeniu różnych rozwiązań skupionych w chmurze z wykorzystaniem nowoczesnych praktyk tworzenia oprogramowania, takich jak bezserwerowe, DevOps i analityka.
Jayesha Shinde’a jest starszym architektem aplikacji w AWS ProServe India. Specjalizuje się w tworzeniu różnych rozwiązań skupionych w chmurze z wykorzystaniem nowoczesnych praktyk tworzenia oprogramowania, takich jak bezserwerowe, DevOps i analityka.
 Ostra Yeola to starszy architekt chmury w AWS ProServe India, pomagający klientom w migracji i modernizacji infrastruktury do AWS. Specjalizuje się w budowaniu DevSecOps i skalowalnej infrastruktury z wykorzystaniem kontenerów, AIOP oraz narzędzi i usług deweloperskich AWS.
Ostra Yeola to starszy architekt chmury w AWS ProServe India, pomagający klientom w migracji i modernizacji infrastruktury do AWS. Specjalizuje się w budowaniu DevSecOps i skalowalnej infrastruktury z wykorzystaniem kontenerów, AIOP oraz narzędzi i usług deweloperskich AWS.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- PlatoData.Network Pionowe generatywne AI. Wzmocnij się. Dostęp tutaj.
- PlatoAiStream. Inteligencja Web3. Wiedza wzmocniona. Dostęp tutaj.
- PlatonESG. Węgiel Czysta technologia, Energia, Środowisko, Słoneczny, Gospodarowanie odpadami. Dostęp tutaj.
- Platon Zdrowie. Inteligencja w zakresie biotechnologii i badań klinicznych. Dostęp tutaj.
- Źródło: https://aws.amazon.com/blogs/big-data/dynamic-dag-generation-with-yaml-and-dag-factory-in-amazon-mwaa/