
To jest post gościnny, napisany wspólnie przez Maika Leutholda i Nicka Harmeninga z BMW Group.
Połączenia BMW Group ma siedzibę główną w Monachium w Niemczech, gdzie firma zatrudnia 149,000 30 pracowników i produkuje samochody i motocykle w ponad 15 zakładach produkcyjnych w XNUMX krajach. Ta wielonarodowa strategia produkcyjna opiera się na jeszcze bardziej międzynarodowej i rozległej sieci dostawców.
Podobnie jak wiele firm motoryzacyjnych na całym świecie, BMW Group boryka się z wyzwaniami w swoim łańcuchu dostaw z powodu ogólnoświatowego niedoboru półprzewodników. Zapewnienie przejrzystości w zakresie obecnego i przyszłego zapotrzebowania BMW Group na półprzewodniki jest jednym z kluczowych strategicznych aspektów rozwiązywania niedoborów wraz z dostawcami i producentami półprzewodników. Producenci muszą znać dokładne aktualne i przyszłe informacje o ilości półprzewodników BMW Group, które skutecznie pomogą sterować dostępnymi światowymi dostawami.
Głównym wymaganiem jest zautomatyzowana, przejrzysta i długoterminowa prognoza popytu na półprzewodniki. Ponadto ten system prognozowania musi zapewniać etapy wzbogacania danych, w tym produkty uboczne, służyć jako dane podstawowe dotyczące zarządzania półprzewodnikami i umożliwiać dalsze przypadki użycia w BMW Group.
Aby umożliwić ten przypadek użycia, skorzystaliśmy z natywnej platformy danych BMW Group o nazwie Cloud Data Hub. W 2019 roku BMW Group zdecydowała się na przeprojektowanie i przeniesienie swojego lokalnego jeziora danych do chmury AWS, aby umożliwić innowacje oparte na danych przy jednoczesnym skalowaniu zgodnie z dynamicznymi potrzebami organizacji. Cloud Data Hub przetwarza i łączy anonimowe dane z czujników pojazdów i innych źródeł w całym przedsiębiorstwie, aby były łatwo dostępne dla wewnętrznych zespołów tworzących aplikacje skierowane do klientów i wewnętrzne. Aby dowiedzieć się więcej o Cloud Data Hub, zobacz BMW Group wykorzystuje Data Lake oparte na AWS, aby uwolnić potęgę danych.
W tym poście dzielimy się tym, jak BMW Group analizuje zapotrzebowanie na półprzewodniki za pomocą Klej AWS.
Logika i systemy stojące za prognozą popytu
Pierwszym krokiem w kierunku prognozy popytu jest identyfikacja komponentów typu pojazdu związanych z półprzewodnikami. Każdy komponent jest opisany unikalnym numerem części, który we wszystkich systemach służy jako klucz do identyfikacji tego komponentu. Elementem może być na przykład reflektor lub kierownica.
Ze względów historycznych dane wymagane na tym etapie agregacji są silosowane i reprezentowane w różny sposób w różnych systemach. Ponieważ każdy system źródłowy i typ danych mają swój własny schemat i format, wykonywanie analiz na podstawie tych danych jest szczególnie trudne. Niektóre systemy źródłowe są już dostępne w Cloud Data Hub (na przykład częściowe dane podstawowe), więc korzystanie z nich jest proste z naszego konta AWS. Aby uzyskać dostęp do pozostałych źródeł danych, musimy zbudować określone zadania pozyskiwania, które odczytują dane z odpowiedniego systemu.
Poniższy diagram ilustruje to podejście.
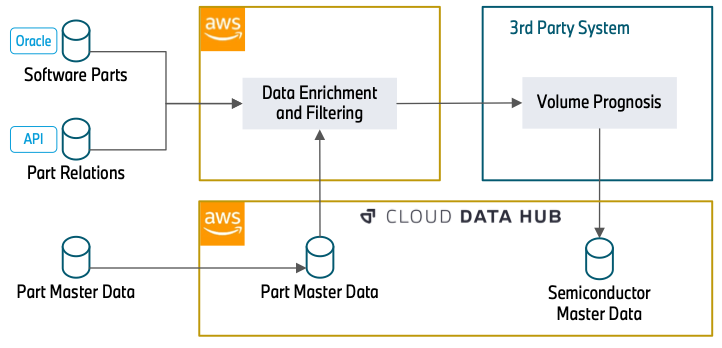
Wzbogacanie danych rozpoczyna się od bazy danych Oracle (części oprogramowania), która zawiera numery części związane z oprogramowaniem. Może to być jednostka sterująca reflektora lub system kamer do zautomatyzowanej jazdy. Ponieważ półprzewodniki są podstawą działania oprogramowania, ta baza danych stanowi podstawę naszego przetwarzania danych.
W kolejnym kroku wykorzystujemy REST API (Part Relations) do wzbogacenia danych o kolejne atrybuty. Obejmuje to, w jaki sposób części są ze sobą powiązane (na przykład konkretna jednostka sterująca, która zostanie zainstalowana w reflektorze) i przez jaki okres czasu numer części zostanie wbudowany w pojazd. Znajomość relacji między częściami jest niezbędna do zrozumienia, w jaki sposób określony półprzewodnik, w tym przypadku jednostka sterująca, ma znaczenie dla bardziej ogólnej części, reflektora. Informacje czasowe dotyczące wykorzystania numerów części pozwalają nam odfiltrować nieaktualne numery części, które nie będą używane w przyszłości i dlatego nie mają znaczenia w prognozie.
Dane (dane podstawowe części) można pobrać bezpośrednio z Cloud Data Hub. Ta baza danych zawiera atrybuty dotyczące statusu i typów materiałów numeru części. Te informacje są wymagane do odfiltrowania numerów części, które zebraliśmy w poprzednich krokach, ale nie mają one znaczenia dla półprzewodników. Dzięki informacjom zebranym z interfejsów API te dane są również przeszukiwane w celu wyodrębnienia dalszych numerów części, które nie zostały pozyskane w poprzednich krokach.
Po wzbogaceniu i przefiltrowaniu danych system innej firmy odczytuje przefiltrowane dane części i wzbogaca informacje o półprzewodnikach. Następnie dodaje informacje o objętości składników. Na koniec przekazuje ogólną prognozę popytu na półprzewodniki centralnie do Cloud Data Hub.
Usługi stosowane
Nasze rozwiązanie korzysta z usług serverless Klej AWS i Usługa Amazon Simple Storage (Amazon S3) do uruchamiania przepływów pracy ETL (wyodrębnianie, przekształcanie i ładowanie) bez zarządzania infrastrukturą. Zmniejsza również koszty, płacąc tylko za czas wykonywania zadań. Podejście bezserwerowe bardzo dobrze pasuje do harmonogramu naszego przepływu pracy, ponieważ uruchamiamy obciążenie tylko raz w tygodniu.
Ponieważ korzystamy z różnych systemów źródeł danych oraz złożonego przetwarzania i agregacji, ważne jest oddzielenie zadań ETL. Dzięki temu możemy przetwarzać każde źródło danych niezależnie. Podzieliliśmy również transformację danych na kilka modułów (agregacja danych, filtrowanie danych i przygotowywanie danych), aby system był bardziej przejrzysty i łatwiejszy w utrzymaniu. Takie podejście pomaga również w przypadku rozbudowy lub modyfikacji istniejących stanowisk.
Chociaż każdy moduł jest specyficzny dla źródła danych lub określonej transformacji danych, w każdym zadaniu wykorzystujemy bloki wielokrotnego użytku. Pozwala to na unifikację każdego typu operacji i upraszcza procedurę dodawania nowych źródeł danych oraz etapów transformacji w przyszłości.
W naszej konfiguracji postępujemy zgodnie z najlepszą praktyką w zakresie bezpieczeństwa, zgodnie z zasadą najmniejszych uprawnień, aby zapewnić ochronę informacji przed przypadkowym lub niepotrzebnym dostępem. Dlatego każdy moduł ma AWS Zarządzanie tożsamością i dostępem (IAM) role tylko z niezbędnymi uprawnieniami, a mianowicie dostępem tylko do źródeł danych i zasobników, których dotyczy praca. Aby uzyskać więcej informacji na temat najlepszych praktyk w zakresie bezpieczeństwa, zobacz Najlepsze praktyki bezpieczeństwa w IAM.
Omówienie rozwiązania
Poniższy diagram przedstawia ogólny przepływ pracy, w którym kilka zadań AWS Glue wchodzi w interakcję ze sobą sekwencyjnie.

Jak wspomnieliśmy wcześniej, korzystaliśmy z Cloud Data Hub, Oracle DB i innych źródeł danych, z którymi komunikujemy się poprzez REST API. Pierwszym krokiem rozwiązania jest moduł Data Source Ingest, który pozyskuje dane z różnych źródeł danych. W tym celu zadania AWS Glue odczytują informacje z różnych źródeł danych i zapisują je w zasobnikach źródłowych S3. Pozyskane dane są przechowywane w zaszyfrowanych zasobnikach, a klucze są zarządzane przez Usługa zarządzania kluczami AWS (AWS KMS).
Po kroku pozyskiwania źródła danych zadania pośrednie agregują i wzbogacają tabele o inne źródła danych, takie jak wersje i kategorie składników, daty produkcji modeli i tak dalej. Następnie zapisują je w zasobnikach pośrednich w module Data Aggregation, tworząc kompleksową i obfitą reprezentację danych. Dodatkowo, zgodnie z przepływem pracy logiki biznesowej, moduły Filtrowanie danych i Przygotowanie danych tworzą ostateczną tabelę danych podstawowych zawierającą wyłącznie informacje rzeczywiste i istotne dla produkcji.
Przepływ pracy AWS Glue zarządza wszystkimi tymi zadaniami pozyskiwania i filtrowania kompleksowo. Harmonogram przepływu pracy AWS Glue jest konfigurowany co tydzień, aby uruchamiać przepływ pracy w środy. Gdy przepływ pracy jest uruchomiony, każde zadanie zapisuje dzienniki wykonania (informacje lub błędy). Usługa prostego powiadomienia Amazon (Amazon SNS) i Amazon Cloud Watch do celów monitoringu. Amazon SNS przekazuje wyniki wykonania do narzędzi monitorujących, takich jak kanały Mail, Teams czy Slack. W przypadku jakiegokolwiek błędu w zadaniach Amazon SNS ostrzega również słuchaczy o wyniku wykonania zadania, aby podjęli działania.
W ostatnim kroku rozwiązania system innej firmy odczytuje tabelę główną z przygotowanego zasobnika danych za pośrednictwem Amazonka Atena. Po dalszych krokach inżynierii danych, takich jak wzbogacanie informacji o półprzewodnikach i integracja informacji woluminowych, ostateczny zasób danych podstawowych jest zapisywany w Cloud Data Hub. Dzięki danym dostępnym teraz w Cloud Data Hub inne przypadki użycia mogą korzystać z danych podstawowych półprzewodników bez tworzenia kilku interfejsów do różnych systemów źródłowych.
Wynik biznesowy
Wyniki projektu zapewniają BMW Group znaczną przejrzystość zapotrzebowania na półprzewodniki dla całego portfolio pojazdów w teraźniejszości i przyszłości. Utworzenie bazy danych o takiej wielkości umożliwia BMW Group ustanowienie jeszcze dalszych przypadków użycia z korzyścią dla większej przejrzystości łańcucha dostaw oraz jaśniejszej i głębszej wymiany z głównymi dostawcami i producentami półprzewodników. Pomaga nie tylko rozwiązać obecną wymagającą sytuację rynkową, ale także być bardziej odpornym w przyszłości. Dlatego jest to jeden ważny krok w kierunku cyfrowego, przejrzystego łańcucha dostaw.
Wnioski
W tym poście opisano, jak analizować zapotrzebowanie na półprzewodniki z wielu źródeł danych za pomocą zadań big data w przepływie pracy AWS Glue. Architektura bezserwerowa z minimalną różnorodnością usług sprawia, że baza kodu i architektura są łatwe do zrozumienia i utrzymania. Aby dowiedzieć się więcej o tym, jak używać przepływów pracy i zadań AWS Glue do orkiestracji bezserwerowej, odwiedź stronę Klej AWS strona serwisowa.
O autorach
 Maika Leutholda jest kierownikiem projektu w BMW Group w zakresie zaawansowanych analiz w obszarze biznesowym łańcucha dostaw i zamówień oraz kieruje strategią cyfryzacji zarządzania półprzewodnikami.
Maika Leutholda jest kierownikiem projektu w BMW Group w zakresie zaawansowanych analiz w obszarze biznesowym łańcucha dostaw i zamówień oraz kieruje strategią cyfryzacji zarządzania półprzewodnikami.
 Nicka Harmeninga jest kierownikiem projektu IT w BMW Group i certyfikowanym architektem rozwiązań AWS. Tworzy i obsługuje aplikacje natywne w chmurze, koncentrując się na inżynierii danych i uczeniu maszynowym.
Nicka Harmeninga jest kierownikiem projektu IT w BMW Group i certyfikowanym architektem rozwiązań AWS. Tworzy i obsługuje aplikacje natywne w chmurze, koncentrując się na inżynierii danych i uczeniu maszynowym.
 Göksel Sarikaya jest starszym architektem aplikacji chmurowych w AWS Professional Services. Umożliwia klientom projektowanie skalowalnych, opłacalnych i konkurencyjnych aplikacji poprzez innowacyjną produkcję platformy AWS. Pomaga im przyspieszyć wyniki biznesowe klientów i partnerów podczas cyfrowej transformacji.
Göksel Sarikaya jest starszym architektem aplikacji chmurowych w AWS Professional Services. Umożliwia klientom projektowanie skalowalnych, opłacalnych i konkurencyjnych aplikacji poprzez innowacyjną produkcję platformy AWS. Pomaga im przyspieszyć wyniki biznesowe klientów i partnerów podczas cyfrowej transformacji.
 Aleksander Celikow jest architektem danych w AWS Professional Services i jest pasjonatem pomagania klientom w tworzeniu skalowalnych danych, rozwiązań analitycznych i ML, aby umożliwić szybki wgląd i podejmowanie krytycznych decyzji biznesowych.
Aleksander Celikow jest architektem danych w AWS Professional Services i jest pasjonatem pomagania klientom w tworzeniu skalowalnych danych, rozwiązań analitycznych i ML, aby umożliwić szybki wgląd i podejmowanie krytycznych decyzji biznesowych.
 Rahul Shaurya jest starszym architektem Big Data w Amazon Web Services. Pomaga i ściśle współpracuje z klientami budującymi platformy danych i aplikacje analityczne na AWS. Poza pracą Rahul uwielbia długie spacery ze swoim psem Barneyem.
Rahul Shaurya jest starszym architektem Big Data w Amazon Web Services. Pomaga i ściśle współpracuje z klientami budującymi platformy danych i aplikacje analityczne na AWS. Poza pracą Rahul uwielbia długie spacery ze swoim psem Barneyem.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- PlatoAiStream. Analiza danych Web3. Wiedza wzmocniona. Dostęp tutaj.
- Wybijanie przyszłości w Adryenn Ashley. Dostęp tutaj.
- Źródło: https://aws.amazon.com/blogs/big-data/how-the-bmw-group-analyses-semiconductor-demand-with-aws-glue/