
W zarządzaniu aktywami zarządzający portfelami muszą uważnie monitorować spółki w swoim środowisku inwestycyjnym, aby identyfikować ryzyko i możliwości oraz kierować decyzjami inwestycyjnymi. Śledzenie bezpośrednich zdarzeń, takich jak raporty o zarobkach lub obniżki wiarygodności kredytowej, jest proste — możesz skonfigurować alerty, aby powiadamiać menedżerów o nowościach zawierających nazwy firm. Jednak wykrywanie wpływów drugiego i trzeciego rzędu wynikających ze zdarzeń u dostawców, klientów, partnerów lub innych podmiotów w ekosystemie firmy jest wyzwaniem.
Na przykład zakłócenie łańcucha dostaw u kluczowego dostawcy prawdopodobnie miałoby negatywny wpływ na producentów na niższym szczeblu łańcucha dostaw. Lub utrata najważniejszego klienta na rzecz dużego klienta stwarza ryzyko popytowe dla dostawcy. Bardzo często takie wydarzenia nie trafiają na pierwsze strony gazet i nie dotyczą bezpośrednio firmy, której dotyczą, a mimo to należy zwrócić na nie uwagę. W tym poście demonstrujemy zautomatyzowane rozwiązanie łączące wykresy wiedzy i generatywna sztuczna inteligencja (AI) aby ujawnić takie ryzyko poprzez powiązanie map relacji z wiadomościami aktualizowanymi w czasie rzeczywistym.
Ogólnie rzecz biorąc, obejmuje to dwa etapy: po pierwsze, zbudowanie skomplikowanych relacji między firmami (klientami, dostawcami, dyrektorami) w formie wykresu wiedzy. Po drugie, wykorzystanie tej graficznej bazy danych wraz z generatywną sztuczną inteligencją do wykrywania skutków wydarzeń informacyjnych drugiego i trzeciego rzędu. Na przykład to rozwiązanie może podkreślić, że opóźnienia u dostawcy części mogą zakłócić produkcję dla dalszych producentów samochodów w portfelu, chociaż żadne z nich nie jest bezpośrednio powiązane.
Dzięki AWS możesz wdrożyć to rozwiązanie w bezserwerowej, skalowalnej i w pełni sterowanej zdarzeniami architekturze. Ten post przedstawia dowód koncepcji zbudowany na dwóch kluczowych usługach AWS, dobrze dostosowanych do graficznej reprezentacji wiedzy i przetwarzania języka naturalnego: Amazon Neptun i Amazońska skała macierzysta. Neptune to szybka, niezawodna, w pełni zarządzana usługa grafowej bazy danych, która ułatwia tworzenie i uruchamianie aplikacji współpracujących z silnie połączonymi zbiorami danych. Amazon Bedrock to w pełni zarządzana usługa oferująca wybór wysokowydajnych modeli podstawowych (FM) od wiodących firm zajmujących się sztuczną inteligencją, takich jak AI21 Labs, Anthropic, Cohere, Meta, Stability AI i Amazon za pośrednictwem jednego interfejsu API, wraz z szerokim zestawem możliwości tworzenia generatywnych aplikacji AI zapewniających bezpieczeństwo, prywatność i odpowiedzialną sztuczną inteligencję.
Ogólnie rzecz biorąc, prototyp ten demonstruje sztukę tworzenia wykresów wiedzy i generatywnej sztucznej inteligencji — uzyskiwania sygnałów poprzez łączenie różnych kropek. Zaletą dla profesjonalistów zajmujących się inwestycjami jest możliwość pozostawania na bieżąco z wydarzeniami bliżej sygnału, unikając jednocześnie szumów.
Zbuduj wykres wiedzy
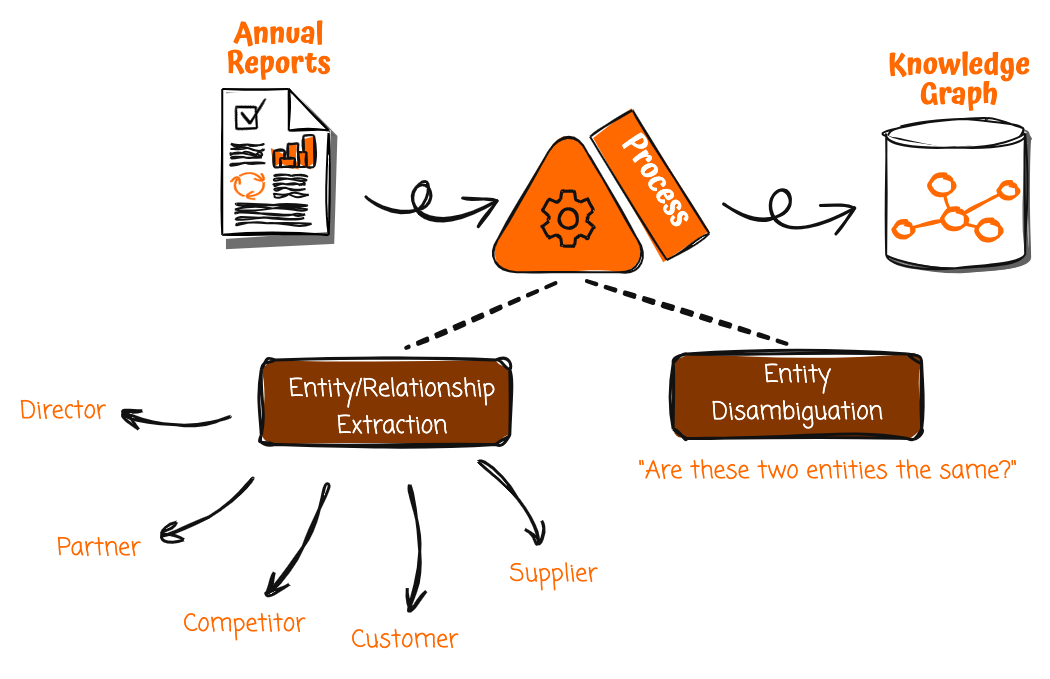
Pierwszym krokiem w tym rozwiązaniu jest zbudowanie wykresu wiedzy, a cennym, choć często pomijanym źródłem danych do wykresów wiedzy, są roczne raporty firm. Ponieważ oficjalne publikacje korporacyjne poddawane są kontroli przed publikacją, zawarte w nich informacje są prawdopodobnie dokładne i wiarygodne. Jednakże raporty roczne są pisane w nieustrukturyzowanym formacie, przeznaczonym do czytania przez ludzi, a nie do konsumpcji maszynowej. Aby uwolnić ich potencjał, potrzebny jest sposób na systematyczne wydobywanie i porządkowanie bogactwa zawartych w nich faktów i relacji.
Dzięki generatywnym usługom AI, takim jak Amazon Bedrock, masz teraz możliwość zautomatyzowania tego procesu. Możesz sporządzić raport roczny i uruchomić potok przetwarzania, aby przetworzyć raport, podzielić go na mniejsze części i zastosować zrozumienie języka naturalnego, aby wydobyć najważniejsze jednostki i relacje.
Na przykład zdanie stwierdzające, że „[Firma A] rozszerzyła swoją europejską flotę dostawczych pojazdów elektrycznych zamawiając 1,800 elektrycznych samochodów dostawczych od [Firmy B]” umożliwiłoby firmie Amazon Bedrock zidentyfikowanie następujących kwestii:
- [Firma A] jako klient
- [Firma B] jako dostawca
- Relacja z dostawcą pomiędzy [Firmą A] a [Firmą B]
- Szczegóły relacji „dostawcy elektrycznych samochodów dostawczych”
Wyodrębnianie takich ustrukturyzowanych danych z dokumentów bez struktury wymaga dostarczenia starannie przygotowanych podpowiedzi do dużych modeli językowych (LLM), aby mogły one analizować tekst w celu wyciągnięcia takich podmiotów, jak firmy i osoby, a także relacji, takich jak klienci, dostawcy i nie tylko. Monity zawierają jasne instrukcje dotyczące tego, na co należy zwrócić uwagę, oraz struktury, w jakiej należy zwracać dane. Powtarzając ten proces w całym raporcie rocznym, można wyodrębnić odpowiednie encje i relacje w celu skonstruowania bogatego wykresu wiedzy.
Jednak przed zatwierdzeniem wyodrębnionych informacji w grafie wiedzy należy najpierw ujednoznacznić jednostki. Na przykład na wykresie wiedzy może już znajdować się inna jednostka „[Firma A]”, ale może ona reprezentować inną organizację o tej samej nazwie. Amazon Bedrock może analizować i porównywać atrybuty, takie jak obszar zainteresowania działalności, branża i branże generujące przychody oraz powiązania z innymi podmiotami, aby ustalić, czy te dwa podmioty rzeczywiście się różnią. Zapobiega to błędnemu łączeniu niepowiązanych ze sobą spółek w jeden podmiot.
Po zakończeniu ujednoznacznienia możesz rzetelnie dodawać nowe podmioty i relacje do swojego wykresu wiedzy o Neptunie, wzbogacając go o fakty wydobyte z raportów rocznych. Z biegiem czasu pozyskiwanie wiarygodnych danych i integracja bardziej wiarygodnych źródeł danych pomoże w zbudowaniu kompleksowego wykresu wiedzy, który będzie mógł pomóc w wyciąganiu wniosków za pomocą zapytań i analiz dotyczących grafów.
Ta automatyzacja, którą umożliwia generatywna sztuczna inteligencja, umożliwia przetwarzanie tysięcy rocznych raportów i odblokowuje nieoceniony atut w zakresie przeglądania wykresów wiedzy, który w przeciwnym razie pozostałby niewykorzystany ze względu na zbyt duży wysiłek ręczny.
Poniższy zrzut ekranu pokazuje przykład wizualnej eksploracji, która jest możliwa w bazie danych wykresów Neptuna przy użyciu Eksplorator wykresów narzędziem.

Artykuły z wiadomościami procesowymi

Kolejnym krokiem rozwiązania jest automatyczne wzbogacanie aktualności zarządzających portfelami i wyróżnianie artykułów istotnych dla ich zainteresowań i inwestycji. W przypadku kanału aktualności zarządzający portfelem mogą subskrybować dowolnego zewnętrznego dostawcę wiadomości Wymiana danych AWS lub inny wybrany przez siebie interfejs API wiadomości.
Kiedy artykuł informacyjny trafia do systemu, wywoływany jest potok pozyskiwania w celu przetworzenia treści. Stosując techniki podobne do przetwarzania raportów rocznych, usługa Amazon Bedrock służy do wyodrębniania jednostek, atrybutów i relacji z artykułu prasowego, które są następnie wykorzystywane do ujednoznacznienia wykresu wiedzy w celu zidentyfikowania odpowiedniego elementu na wykresie wiedzy.
Wykres wiedzy zawiera powiązania pomiędzy firmami i osobami, a łącząc elementy artykułów z istniejącymi węzłami, można określić, czy jakiekolwiek tematy znajdują się w promieniu dwóch przeskoków od firm, w które zarządzający portfelem zainwestował lub którymi jest zainteresowany. Znalezienie takiego powiązania oznacza, że artykuł może być istotny dla zarządzającego portfelem, a ponieważ podstawowe dane są przedstawione na wykresie wiedzy, można je zwizualizować, aby pomóc zarządzającemu portfelem zrozumieć, dlaczego i w jaki sposób ten kontekst jest istotny. Oprócz identyfikowania powiązań z portfelem, możesz także użyć Amazon Bedrock do przeprowadzenia analizy nastrojów w odniesieniu do wskazanych podmiotów.
Efektem końcowym jest wzbogacony kanał informacyjny zawierający artykuły, które mogą mieć wpływ na obszary zainteresowań i inwestycji zarządzającego portfelem.
Omówienie rozwiązania
Ogólna architektura rozwiązania wygląda jak na poniższym schemacie.

Przepływ pracy składa się z następujących kroków:
- Użytkownik przesyła oficjalne raporty (w formacie PDF) do pliku Usługa Amazon Simple Storage Łyżka (Amazon S3). Raporty powinny być raportami oficjalnie publikowanymi, aby zminimalizować umieszczanie niedokładnych danych na wykresie wiedzy (w przeciwieństwie do wiadomości i tabloidów).
- Powiadomienie o zdarzeniu S3 wywołuje plik AWS Lambda funkcja, która wysyła segment S3 i nazwę pliku do Usługa Amazon Simple Queue (Amazon SQS) w kolejce. Kolejka „pierwsze weszło, pierwsze wyszło” (FIFO) gwarantuje, że proces pozyskiwania raportu jest wykonywany sekwencyjnie, aby zmniejszyć prawdopodobieństwo wprowadzenia zduplikowanych danych do grafu wiedzy.
- An Most zdarzeń Amazona zdarzenie oparte na czasie jest uruchamiane co minutę, aby rozpocząć bieg Funkcje kroków AWS maszyna stanu asynchronicznie.
- Maszyna stanu Step Functions wykonuje serię zadań w celu przetworzenia przesłanego dokumentu poprzez wyodrębnienie kluczowych informacji i wstawienie ich do wykresu wiedzy:
- Odbierz wiadomość z kolejki z Amazon SQS.
- Pobierz plik raportu PDF z Amazon S3, podziel go na wiele mniejszych fragmentów tekstu (około 1,000 słów) w celu przetworzenia i zapisz fragmenty tekstu w Amazon DynamoDB.
- Użyj narzędzia Anthropic Claude v3 Sonnet na platformie Amazon Bedrock, aby przetworzyć kilka pierwszych fragmentów tekstu w celu określenia głównego podmiotu, do którego odnosi się raport, wraz z odpowiednimi atrybutami (takimi jak branża).
- Pobierz fragmenty tekstu z DynamoDB i dla każdego fragmentu tekstu wywołaj funkcję Lambda, aby wyodrębnić jednostki (takie jak firma lub osoba) i ich relację (klient, dostawca, partner, konkurent lub dyrektor) z jednostką główną za pomocą Amazon Bedrock .
- Konsoliduj wszystkie wyodrębnione informacje.
- Odfiltruj szum i nieistotne podmioty (na przykład terminy ogólne, takie jak „konsumenci”), korzystając z usługi Amazon Bedrock.
- Użyj Amazon Bedrock, aby przeprowadzić ujednoznacznienie, rozumując na podstawie wyodrębnionych informacji w porównaniu z listą podobnych podmiotów z grafu wiedzy. Jeśli encja nie istnieje, wstaw ją. W przeciwnym razie użyj encji, która już istnieje na grafie wiedzy. Wstaw wszystkie wyodrębnione relacje.
- Wyczyść, usuwając komunikat kolejki SQS i plik S3.
- Użytkownik uzyskuje dostęp do aplikacji internetowej opartej na React, aby wyświetlić artykuły informacyjne uzupełnione o informacje o encji, tonacji i ścieżce połączenia.
- Za pomocą aplikacji internetowej użytkownik określa liczbę przeskoków (domyślnie N=2) na ścieżce połączenia do monitorowania.
- Korzystając z aplikacji webowej użytkownik określa listę podmiotów do śledzenia.
- Użytkownik wybiera, czy chcesz wygenerować fikcyjne wiadomości Wygeneruj przykładowe wiadomości wygenerować 10 przykładowych artykułów z wiadomościami finansowymi z losową treścią, które zostaną wprowadzone do procesu przetwarzania wiadomości. Treść jest generowana przy użyciu Amazon Bedrock i jest czysto fikcyjna.
- Aby pobrać aktualne wiadomości, użytkownik wybiera Pobierz najnowsze wiadomości aby pobrać najważniejsze wiadomości z dzisiejszego dnia (obsługiwane przez NewsAPI.org).
- Plik wiadomości (format TXT) jest przesyłany do segmentu S3. Kroki 8 i 9 automatycznie przesyłają wiadomości do segmentu S3, ale możesz także zbudować integrację z preferowanym dostawcą wiadomości, takim jak AWS Data Exchange lub dowolny zewnętrzny dostawca wiadomości, aby upuszczać artykuły z wiadomościami jako pliki do segmentu S3. Zawartość pliku danych wiadomości powinna być sformatowana jako
<date>{dd mmm yyyy}</date><title>{title}</title><text>{news content}</text>. - Powiadomienie o zdarzeniu S3 wysyła segment S3 lub nazwę pliku do Amazon SQS (w standardzie), który wywołuje wiele funkcji Lambda w celu równoległego przetwarzania danych wiadomości:
- Użyj Amazon Bedrock, aby wyodrębnić podmioty wspomniane w wiadomościach wraz z wszelkimi powiązanymi informacjami, relacjami i nastrojami dotyczącymi wspomnianego podmiotu.
- Sprawdź wykres wiedzy i użyj Amazon Bedrock, aby przeprowadzić ujednoznacznienie, rozumując, korzystając z informacji dostępnych w wiadomościach i na wykresie wiedzy, aby zidentyfikować odpowiedni podmiot.
- Po zlokalizowaniu podmiotu wyszukaj i zwróć wszelkie ścieżki połączeń łączące się z podmiotami oznaczonymi znakiem
INTERESTED=YESna wykresie wiedzy, które znajdują się w odległości N=2 przeskoków.
- Aplikacja internetowa automatycznie odświeża się co 1 sekundę, aby pobrać najnowszy zestaw przetworzonych wiadomości do wyświetlenia w aplikacji internetowej.
Wdróż prototyp
Możesz wdrożyć prototypowe rozwiązanie i samodzielnie rozpocząć eksperymentowanie. Prototyp dostępny jest m.in GitHub i zawiera szczegółowe informacje na temat:
- Warunki wstępne wdrożenia
- Etapy wdrażania
- Kroki czyszczenia
Podsumowanie
W tym poście zaprezentowano rozwiązanie weryfikujące koncepcję, które pomaga menedżerom portfeli wykrywać ryzyka drugiego i trzeciego rzędu na podstawie wydarzeń informacyjnych, bez bezpośrednich odniesień do śledzonych przez nich spółek. Łącząc wykres wiedzy na temat skomplikowanych relacji firmowych z analizą wiadomości w czasie rzeczywistym przy użyciu generatywnej sztucznej inteligencji, można uwydatnić skutki na dalszych etapach, takie jak opóźnienia w produkcji spowodowane czkawką u dostawców.
Chociaż jest to tylko prototyp, rozwiązanie to daje nadzieję na stworzenie wykresów wiedzy i modeli językowych umożliwiających łączenie punktów i uzyskiwanie sygnałów z szumu. Technologie te mogą pomóc specjalistom ds. inwestycji, szybciej ujawniając ryzyko poprzez mapowanie relacji i rozumowanie. Ogólnie rzecz biorąc, jest to obiecujące zastosowanie grafowych baz danych i sztucznej inteligencji, które gwarantuje eksplorację w celu usprawnienia analizy inwestycji i podejmowania decyzji.
Jeśli ten przykład generatywnej sztucznej inteligencji w usługach finansowych zainteresuje Twoją firmę lub masz podobny pomysł, skontaktuj się ze swoim menedżerem konta AWS, a z przyjemnością przeprowadzimy z Tobą dalsze badania.
O autorze
 Xana Huanga jest starszym architektem rozwiązań w AWS i mieszka w Singapurze. Współpracuje z największymi instytucjami finansowymi przy projektowaniu i budowaniu bezpiecznych, skalowalnych i wysoce dostępnych rozwiązań w chmurze. Poza pracą Xan większość wolnego czasu spędza z rodziną i podporządkowuje się swojej 3-letniej córce. Możesz znaleźć Xana na LinkedIn.
Xana Huanga jest starszym architektem rozwiązań w AWS i mieszka w Singapurze. Współpracuje z największymi instytucjami finansowymi przy projektowaniu i budowaniu bezpiecznych, skalowalnych i wysoce dostępnych rozwiązań w chmurze. Poza pracą Xan większość wolnego czasu spędza z rodziną i podporządkowuje się swojej 3-letniej córce. Możesz znaleźć Xana na LinkedIn.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- PlatoData.Network Pionowe generatywne AI. Wzmocnij się. Dostęp tutaj.
- PlatoAiStream. Inteligencja Web3. Wiedza wzmocniona. Dostęp tutaj.
- PlatonESG. Węgiel Czysta technologia, Energia, Środowisko, Słoneczny, Gospodarowanie odpadami. Dostęp tutaj.
- Platon Zdrowie. Inteligencja w zakresie biotechnologii i badań klinicznych. Dostęp tutaj.
- Źródło: https://aws.amazon.com/blogs/machine-learning/uncover-hidden-connections-in-unstructured-financial-data-with-amazon-bedrock-and-amazon-neptune/